 在开发平台上使用VITIS AI加速AI应用
在开发平台上使用VITIS AI加速AI应用
VITIS 是一个用于开发软件和硬件的统一软件平台,使用 Vivado 和其他用于 Xilinx FPGA SoC 平台(如 ZynqMP UltraScale+ 和 Alveo 卡)的组件。VITIS SDK 的关键组件 VITIS AI 运行时 (VART) 为在边缘和云上部署终端 ML/AI 应用程序提供了统一的接口。
机器学习中的推理是计算密集型的,需要高内存带宽和高性能计算,以满足各种终端应用程序的低延迟和高吞吐量要求。
Vitis AI 工作流程
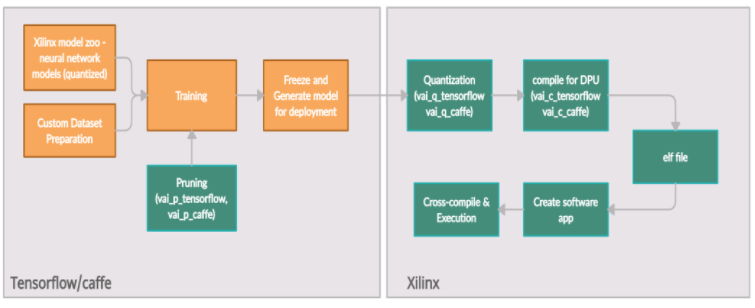
Xilinx Vitis AI 提供了一个工作流,可使用简单的流程在 Xilinx 深度学习处理单元 (DPU) 上部署深度学习推理应用程序:
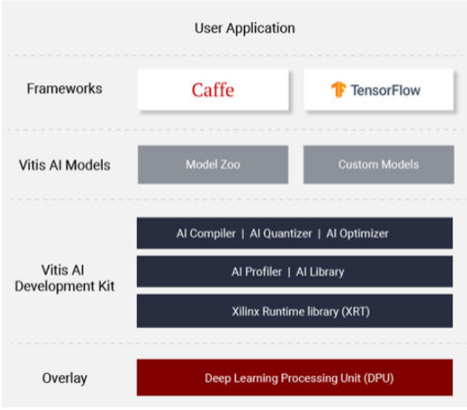
深度处理单元 (DPU) 是一种可配置的计算引擎,针对深度学习推理应用的卷积神经网络进行了优化,并置于可编程逻辑 (PL) 中。DPU 包含高效且可扩展的 IP 内核,可进行定制以满足许多不同应用的需求。DPU 定义自己的指令集,Vitis AI 编译器生成指令。
VITIS AI 编译器以优化的方式调度指令以获得可能的最大性能。
在 Xilinx ZynqMP UltraScale+ SoC 平台上运行任何 AI 应用程序的典型工作流程包括以下内容:
模型量化
模型编译
模型优化(可选)
构建 DPU 可执行文件
构建软件应用程序
集成 VITIS AI 统一 API
编译和链接混合 DPU 应用程序
在 FPGA 上部署混合 DPU 可执行文件
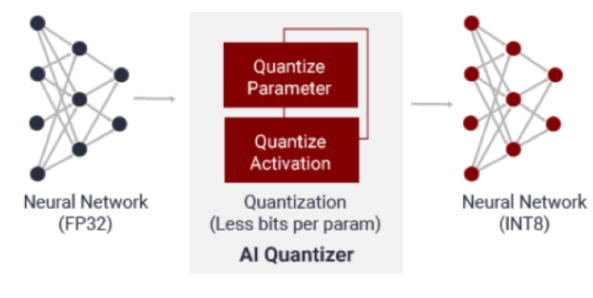
人工智能量化器
AI Quantizer 是一种用于量化过程的压缩工具,通过将 32 位浮点权重和激活转换为定点 INT8。它可以在不丢失模型准确信息的情况下降低计算复杂度。定点模型需要更少的内存,因此比浮点实现提供更快的执行和更高的功率效率。
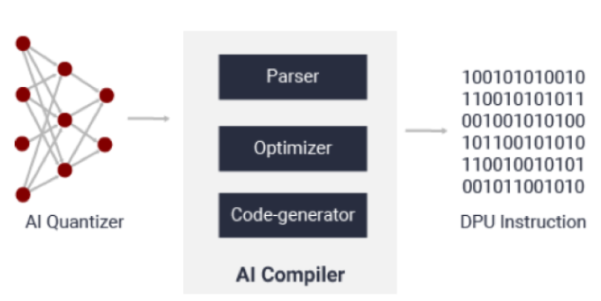
人工智能编译
AI 编译器将网络模型映射到高效的指令集和数据流。编译器的输入是量化的 8 位神经网络,输出是 DPU 内核 - 可执行文件将在 DPU 上运行。在这里,不支持的层需要部署在 CPU 中,或者可以自定义模型来替换和删除那些不支持的操作。它还执行复杂的优化,例如层融合、指令调度和片上存储器的重用。
一旦我们能够执行 DPU,我们需要使用 Vitis AI 统一 API 来初始化数据结构,初始化 DPU,在 CPU 上实现 DPU 不支持的层,并在 CPU 上添加预处理和后处理PL/PS 的需求基础。
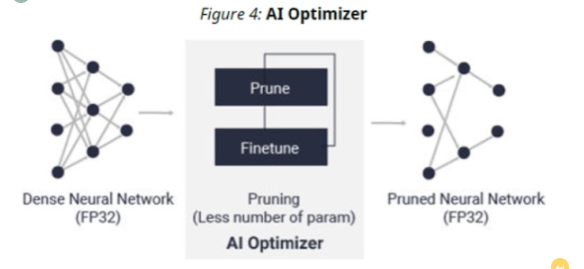
人工智能优化器
借助其模型压缩技术,AI Optimizer 可以将模型复杂度降低 5-50 倍,而对准确性的影响最小。这种深度压缩将推理性能提升到一个新的水平。我们可以实现所需的稀疏性并将运行时间减少 2.5 倍。
人工智能分析器
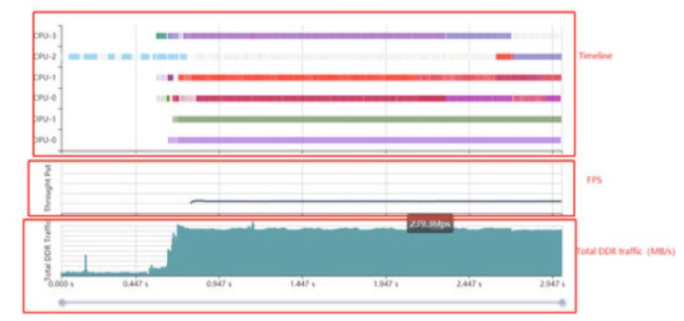
AI Profiler 可以帮助分析推理找到导致端到端管道瓶颈的警告。分析器为设计人员提供了 DPU/CPU/内存的通用时间线。此过程不会更改任何代码,并且可以跟踪功能并进行分析。
人工智能运行时
VITIS AI 运行时 (VART) 允许应用程序使用统一的高级运行时 API 进行边缘和云部署,使其无缝且高效。一些关键功能包括:
异步作业提交
异步作业收集
多线程和多进程执行
Vitis AI 还提供 DSight、DExplorer、DDump 和 DLet 等,用于执行各种任务。
DSight & DExplorer
DPU IP 为特定内核提供了多种配置,以根据网络模型进行选择。DSight 告诉我们每个 DPU 核心的百分比利用率。它还提供了调度程序的效率,以便我们可以调整用户线程。还可以查看每一层和每个 DPU 节点的性能数据,例如 MOPS、运行时间和内存带宽。
Softnautics选择赛灵思 ZynqMP UltraScale+ 平台进行高性能和计算部署。它提供最佳的应用程序处理、高度可配置的 FPGA 加速功能和 VITIS SDK,以加速高性能 ML/AI 推理。我们针对的此类应用之一是用于 Covid-19 筛查的面罩检测。其目的是为戴口罩的人的 Covid-19 筛查部署多流推理,并根据各国政府对 Covid-19 预防措施指南的要求,实时识别违规行为。
我们准备了一个数据集并选择了预训练的权重来设计一个用于掩码检测和筛选的模型。我们通过 TensorFlow 框架训练和修剪我们的自定义模型。这是面部检测和面具检测的两阶段部署。如此获得的训练模型通过前面章节中介绍的 VITIS AI 工作流程传递。与 CPU 相比,我们观察到推理时间的 10 倍速度。Xilinx 提供了不同的调试工具和实用程序,它们在初始开发和部署期间非常有用。在我们最初的部署阶段,我们没有检测到掩码和非掩码类别。我们尝试将基于 PC 的推理输出与名为 Dexplorer 的调试实用程序之一的输出相匹配。但是,调试模式和根本原因导致问题进一步调试。在运行量化器时,我们可以使用更大的校准图像、迭代和检测来调整输出,视频输入的准确率约为 96%。我们还尝试使用 AI 分析器识别管道中的瓶颈,然后采取纠正措施以通过各种方式消除瓶颈,例如使用 HLS 加速来计算后处理中的瓶颈。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10854浏览量
211567 -
Xilinx
+关注
关注
71文章
2167浏览量
121290 -
AI
+关注
关注
87文章
30728浏览量
268871
发布评论请先 登录
相关推荐
Arm推出GitHub平台AI工具,简化开发者AI应用开发部署流程
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
NVIDIA IGX平台加速实时边缘AI应用
开发者手机 AI - 目标识别 demo
Vitis2023.2使用之—— classic Vitis IDE
【ALINX 技术分享】AMD Versal AI Edge 自适应计算加速平台之 Versal 介绍(2)






 工商网监
工商网监
评论