 宏观算力建设实现芯片规模化
宏观算力建设实现芯片规模化
1、算力由性能、规模和利用率三部分组成
算力 = (单芯片)性能 x 规模(即数量) x 利用率。
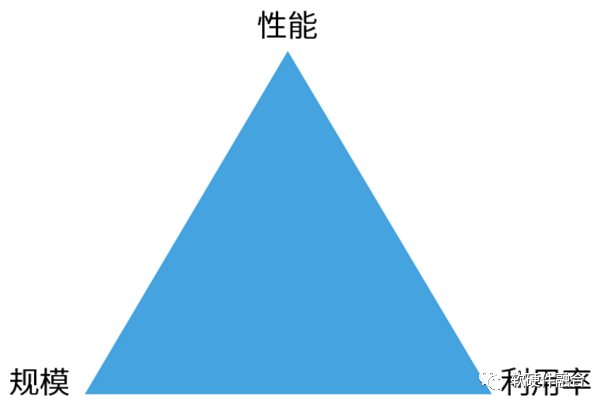
算力是由性能、规模、利用率三部分共同组成的,相辅相成,缺一不可:
有的算力芯片,可能可以做到性能狂飙,但较少考虑芯片的通用性易用性,然后芯片销量不高落地规模小,那就无法做到宏观算力的真正提升。
有的算力提升方案,重在规模投入,摊大饼有一定作用,但不是解决未来算力需求数量级提升的根本。
有的解决方案,通过各种资源池化和跨不同的边界算力共享,来提升算力利用率,但改变不了目前算力芯片性能瓶颈的本质。
性能、规模、利用率,宏观微观,牵一发而动全身。管中窥豹终有偏,既要考虑多种因素协同设计,更要宏观的统筹算力问题。
2、最核心的,通过超异构实现芯片性能的数量级提升
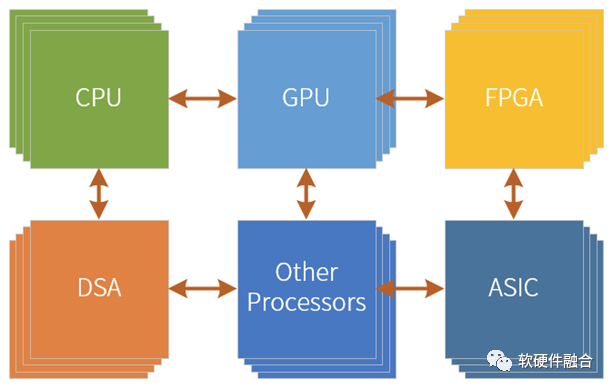
一方面,超异构可以通过集成更多的加速引擎来实现相比CPU、GPU的性能的数量级提升,但更多的计算是在DSA架构引擎完成的,从单位晶体管资源的性能效率视角看,是和DSA在一个量级的。
工艺进步、3D封装、Chiplet封装等各种创新,支持数量级提升的设计规模。但要想充分利用这些价值,就需要创新的系统架构。超异构计算,通过分布式系统设计,可以驾驭数量级提升的更大的设计规模。因此,可以做到相比传统DSA再继续10倍甚至100倍的性能提升。
3、在超异构的约束下,实现规模化落地
3.1 芯片要更好地支持规模化
从微服务的视角,云计算是由不同的服务组成的分层服务体系:每一层就是一个服务族,然后不同层次的服务族组成整个云计算服务体系,这就是我们所熟悉的云计算三层服务IaaS、PaaS和SaaS。
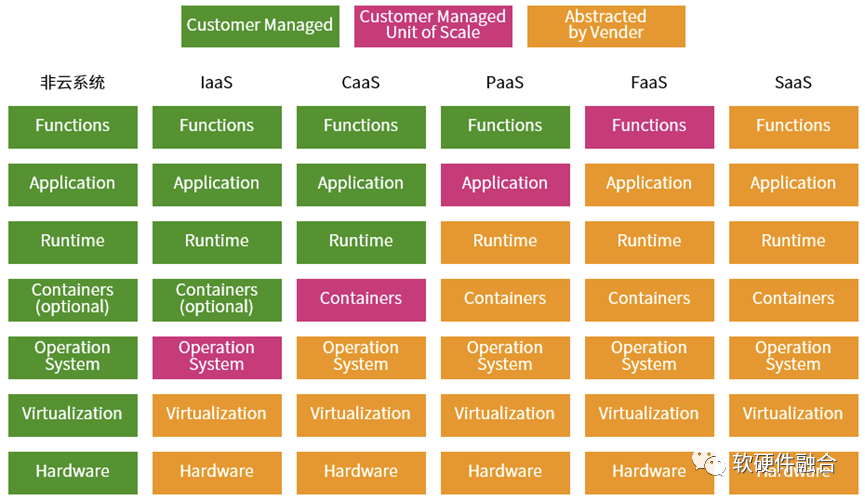
更详细的软件堆栈如上图所示,从非云系统所有的“服务”堆栈都需要用户自己拥有并维护,经过IaaS、CaaS、PaaS、FaaS,再到最后的SaaS,一切都由供应商运营维护。从左到右的过程,就是“服务”堆栈的下层layer不断地由云运营商接管的过程。
这是一个鲜明的“二八定律”案例:80%的任务由云运营商负责,20%的任务由用户负责;站在用户的角度,20%自己负责的任务价值占到80%,而运营商负责的部分只占到到20%的价值。

因此,基于二八定律,我们可以把整个系统分为三部分:
基础设施层。基础设施层的任务都相对确定,适合DSA和ASIC处理引擎处理。
应用层可加速部分任务。基础设施层是CSP使用,而应用层则是给到用户应用。用户的应用多种多样,因此应用层的加速也需要一定程度的弹性。这样,GPU和FPGA就相对比较合适。
应用层的不可加速部分。主要是一些通用的处理,如控制以及一些细粒度的计算。协处理器是CPU的一部分。因此,CPU适合各类通用任务处理,CPU负责兜底。
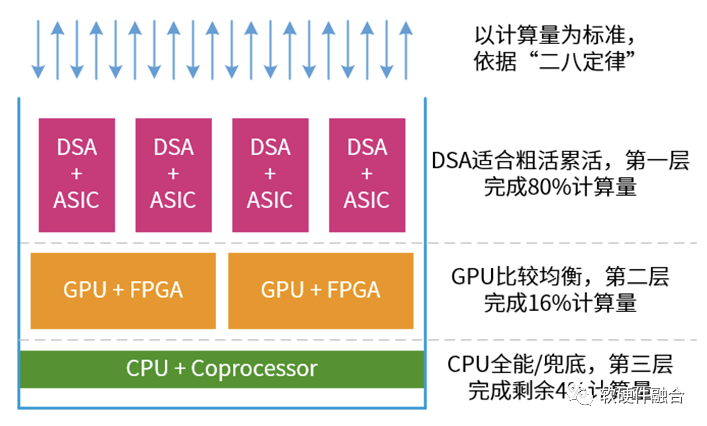
如上图所示,整个系统的处理有点像塔防游戏:DSA负责干粗活累活,大量的计算任务在DSA中完成;GPU是性能和灵活性折中一些,负责一些弹性加速的计算任务;CPU啥都能干,但性能较差,因此负责兜底,也就是其他处理引擎都干不了的,都放在CPU。
这样,CPU+GPU+DSA+etc.的超异构计算架构就可以实现“包治百病”的、相对通用的计算架构和平台,就可以实现在云、网、边、端等大算力场景以及用户的绝大部分覆盖。
更多场景和更多用户的覆盖,这样才能真正实现芯片的规模化落地。芯片的大规模落地之后,又进一步摊薄一次性研发成本,进一步降低成本,形成良性循环。
3.2 宏观算力建设实现芯片规模化
要想持续不断地增加算力,不可避免的就是建设更多的数据中心。2022年2月,国家发改委、中央网信办、工业和信息化部、国家能源局联合印发通知,同意在京津冀、长三角、粤港澳大湾区、成渝、内蒙古、贵州、甘肃、宁夏等8地启动建设国家算力枢纽节点,并规划了10个国家数据中心集群。至此,全国一体化大数据中心体系完成总体布局设计,“东数西算”工程正式全面启动。
“东数西算”通过构建数据中心、云计算、大数据一体化的新型算力网络体系,将东部算力需求有序引导到西部,优化数据中心建设布局,促进东西部协同联动。“东数西算”工程有三个总体思路:一是推动全国数据中心适度集聚、集约发展。通过在全国布局8个算力枢纽,引导大型、超大型数据中心向枢纽内集聚,形成数据中心集群。二是促进数据中心由东向西梯次布局、统筹发展。三是实现“东数西算”循序渐进、快速迭代。
除了大型云数据中心建设之外,也需要更多的边缘数据中心和服务器、更多的超高算力的智慧终端,以及更智慧的网络核心设备,来共同提升宏观总算力。
4、在超异构的约束下,提升算力利用率
4.1 提升算力利用率的手段
云计算出现之前,部署一套互联网系统,一般有两种方式:小规模的时候,自己购买物理的服务器,然后租用运营商的机房;超过一定规模的时候,就需要自己建机房,租用运营商的网络,自己运维数据中心的软件和硬件。这个时候的算力资源是一个个孤岛,整个业务的模式也非常之重,成本很高而且弹性不足。如果算力资源配置比较多,就意味着资源浪费和利用率低;如果算力资源配置比较少,就意味着无法支撑业务的发展,丢失关键的商业机会。
云计算通过互联网按需提供IT资源,并且采用按使用量付费的方式。用户可以根据需要从云服务商那里获得技术服务,例如计算能力、存储和数据库,而无需购买、拥有和维护物理数据中心及服务器。云服务使用多少支付多少,可以帮助用户降低运维成本,用户可以根据业务需求的变化快速调整服务的使用。
其他如基于分布式云的边缘计算、跨不同云厂家的MSP、算力网络以及云网边端融合等,都是尽可能的把算力资源整合成一个巨大的资源池,然后可以灵活的根据各种完全动态变化的需求来提供合适的算力。
我们分析一下,要想提升算力利用率,肯定不能是算力的孤岛:
第一个阶段,所有的设备是孤岛,各自要实现各自的所有功能。软件应用也是单机版,算力利用率很低,应用的规模受单个硬件规格的限制;
第二阶段,有了互联网,不同的设备可以进行协作。可以通过C/S架构实现跨设备的软件应用协作。这样,应用的规模就突破了单个设备的约束。
第三阶段,所有的算力资源形成一个整体。可以自动的、任意的切分算力资源。软件也升级成了MicroService架构。这样可以根据设备的规格大小,运行合适大小合适数量的微服务。只有资源形成巨大的资源池,然后通过各种运营管理,才能真正提高算力的利用率。
4.2 芯片视角看算力利用率
资源池化是提升算力利用率的根本途径,但资源要想池化,对硬件有很高的要求:
不同设备架构/接口一致。比如CPU等引擎架构一致(比如都是x86架构平台),那么软件可以运行在任何一个设备上,硬件也可以支持各种不同的软件运行。比如NVMe SSD,可以被不同的用户访问,也可以同时或分时地支持多种用户的工作。
支持虚拟化。一方面是资源粒度的问题,另一方面是资源自由和动态分配的问题,都可以通过虚拟化技术解决。虚拟化还可以实现不同架构/接口的抽象,屏蔽硬件差异。
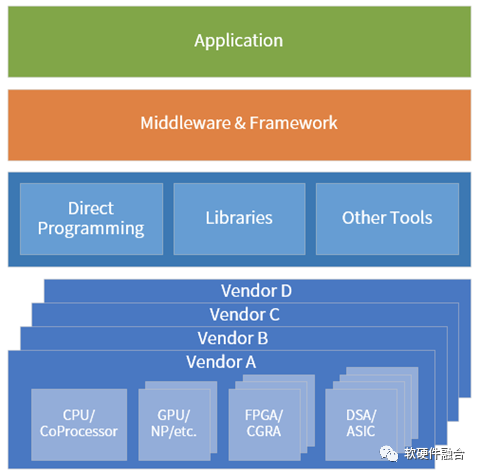
通常,算力的平台都是CPU,而且目前x86架构CPU占据了绝大部分市场份额,并且x86 CPU对虚拟化的支持也非常的好。CPU对资源池化的支持,或者说对算力更高利用率的支持,是相当的友好。
但是,随着性能需求越来越高,不得不通过超异构计算来数量级提升算力的时候,问题出现了。在超异构的架构下,如何实现更高的灵活性,如何实现更高的扩展性,如何实现各类资源的轻松便捷地池化和共享,则是一个全新的挑战:
处理引擎要支持虚拟化和高可扩展性;
软件可以跨不同厂家的、不同架构处理引擎;
软件可以跨跨CPU、GPU、DSA等不同类型处理引擎;
软件可以跨云网边端。
5、展望,云网边端大融合
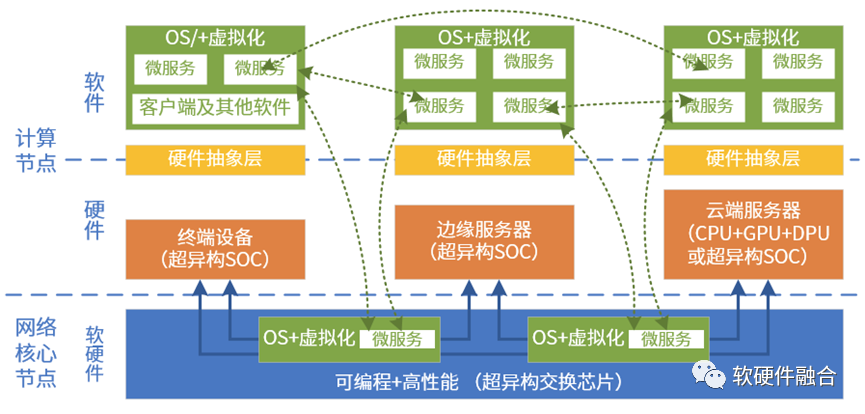
在虚拟化的加持下,软件可以实现完全高可用:软件可以脱离硬件实体,随意的寻找合适的平台运行,自适应的在云、网、边、端运行。
随着CPU的性能瓶颈,I/O虚拟化技术完全硬件化的情况下,硬件接口直接暴露给软件,这就需要云数据中心内部,以及跨云边端的硬件平台一致性。
要想实现跨云网边端、跨不同厂家的芯片平台、跨不同类型不同架构的处理引擎,就需要芯片、系统、框架和库、以及上层应用的多方协同,就需要开源开放的超异构计算生态。
万物互联,当所有的设备算力资源汇集成一个大的共享资源池,算力资源将取之不尽用之不竭。
原文标题:再来聊聊大家都经常聊的算力话题
文章出处:【微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
-
处理器
+关注
关注
68文章
19358浏览量
230402 -
芯片
+关注
关注
456文章
50984浏览量
425153 -
cpu
+关注
关注
68文章
10885浏览量
212323 -
算力
+关注
关注
1文章
996浏览量
14874
原文标题:再来聊聊大家都经常聊的算力话题
文章出处:【微信号:Imgtec,微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

江波龙自研主控芯片实现规模化导入
OCTC发布"算力工厂"!力促智算中心高效规划建设投运

IaaS+on+DPU(IoD)+下一代高性能算力底座技术白皮书
东土科技自主研发的人工智能交通服务器实现规模化应用
IBM陈旭东:携手IBM加速 AI 规模化应用,解锁企业新质生产力

助力全国一体化算力网建设,神州鲲泰以算力构建新质生产力

北京:规划建设支撑万亿级参数大模型训练需求的超大规模智算集群

广东:到2025年,算力规模38E,智算50%,国产算力70%

声通科技:高标准化及可扩展的产品能力,助力公司实现规模化经营
晶晟微纳发布N800超大规模AI算力芯片测试探针卡
智能算力规模超通用算力,大模型对智能算力提出高要求






 工商网监
工商网监
评论