 无人机视觉导航国内外研究现状以及存在的问题
无人机视觉导航国内外研究现状以及存在的问题
导语
目前国内外都在致力于针对无人机的GNSS拒止条件下的定位导航研究。其中视觉导航(Vision-Based Navigation,VBN)因抗干扰能力强、功耗低、成本低、体积小、设备结构简单、被动式、定位精度高等优点得到了广泛关注。近几年随着AI在计算机视觉领域的爆发,不仅突破了之前很多难以解决的视觉难题,更极大提升了对图像认知的水平,因此VBN迅速成为导航领域的研究热点。但是目前的技术还存在哪些问题需要解决呢?
1
引言
目前的组合导航系统基本上是以INS为主GNSS等为辅的导航方式。INS存在误差积累,因此需要GNSS进行修正,但GNSS卫星信号落地功率仅-130dbm,频段公开,极易被干扰,当GNSS信号被干扰时,一般情况下可以利用IMU进行航位推算,但随着时间的推移,误差累计严重,无人机无法完成预定任务,甚至难以返航。因此在GPS拒止区域(如室内、水下、丛林、城市楼群间、高山峡谷、作战敌方干扰区等)如何完成无人机在自主飞行、定位、执行任务是一个迫切的挑战。
美国于2014年开始发展5项不依赖于GPS的导航技术,包括Micro-PNT、ANS等项目。美国的诺斯罗普•格鲁曼公司提出的Assured PNT(ASSURED POSITIONING, NAVIGATION AND TIMING)系统中,包含了对GPS拒止条件下的各类辅助导航方式,包括天文导航、地形匹配、激光测距/激光雷达、磁力计、里程计等方式。
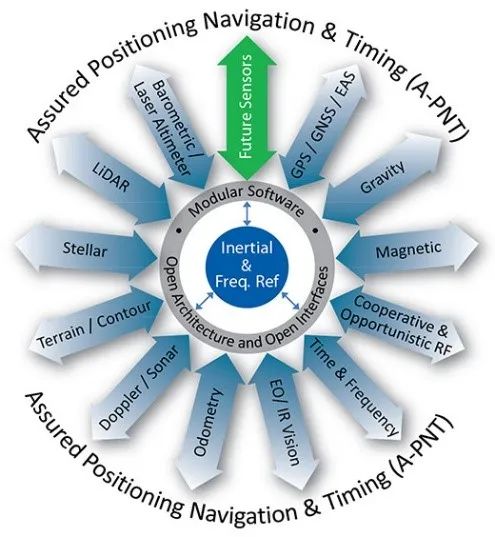
图1 诺格公司的Assured PNT系统
视觉导航主要是指通过飞行器机载的视觉成像设备(可见光、红外、SAR 等)对地拍照的图像进行各种导航参数的测量。视觉导航定位技术是通过图像匹配算法结合含有地理位置信息的基准图实现的。
目前视觉导航按照是否需要导航地图(即数字景象基准数据库)可分为地图型导航和无地图导航。地图型导航需要使用预先存储包含精确地理信息的导航地图,利用一帧实拍图像与导航地图匹配即可实现飞行器的绝对定位。当导航地图采用景象图或地形图时,地图导航可分为景象匹配导航和地形匹配导航。由于景象匹配制导的精度比地形匹配制导的精度高一个数量级,因此地形匹配制导一般用于中制导,景象匹配制导一般用于末制导。
2
国内外研究现状以及存在的问题
景象匹配系统
国外对景象匹配系统的研究始于巡航导弹的制导。景象匹配制导利用目标区的图像信息进行制导,主要攻击目标为机场、交通枢纽、军事基地等等。导弹的制导精度取决于实时图质量、基准图精度和匹配方法性能等。该方法实质上是一种基于模板匹配的目标定位方法。
景象匹配辅助导航系统具有自主性和高精度的突出优点,然而该技术仍未达到完全成熟的程度。景象匹配一般结合卫星导航、惯性导航和地形匹配导航使用,其作用区域一般为数百平方米或数平方公里且存在以下问题:
(1) 严重依赖于离线基准图,是否能够获得高精度地图也是景象匹配问题的关键因素之一,目前其制图难度较大;
(2) 对于低空飞行、大起伏地形情况下时造成的视角变化,目前的算法效果较差;
(3) 由于基准图的制作往往较机载图像传感提前很长时间,地图和机载图像信息往往可能是在不同日期、不同传感器、不同观测点/角度、不同气象条件下获得的,因此需要景象匹配算法具备很强的光照、季节、角度不变性,而目前的传统算法基本无法应对不同传感器、时间、季节、角度差下地理面貌发生的改变;
(4) 景象匹配技术可以为无人机提供实时的位置信息,因此应具备高精度、实时计算等特性。而高精度和实时性受景象的特征点集合大小、匹配算法、搜索范围、地图大小等多方面的制约,因此基本只适用于小范围内定位导航。
地形匹配导航
地形匹配导航技术需要飞行路线上的地形数据作为基础,在飞行器飞行过程中,将实际飞行过程中测量到的地形高程数据与基准地形数据进行不断比较来实现匹配定位,并对飞行器进行导航修正。地形匹配主要利用雷达高度表和气压高度表等设备测量沿航线的地形高程数据,按最佳匹配确定飞行器的地理位置。
地形匹配一般用于巡航导弹飞越特定地区,可以修正INS的导航信息,消除INS的累计误差,提高导航精度,但存在以下问题:
(1) 需要地形数据作为基础,对地形要求严格,使用中尽量回避地形特征贫乏的平坦地区和地形高程变剧烈的山区;
(2) 需要高度表连续获取地形高程序列,算法处理属于后验证估计,实时性差,一般用于修正导航误差;
(3) 对航向误差敏感,定位过程中无法机动。
视觉SLAM技术
视觉SLAM为代表的技术在视觉导航领域主要以回环检测(Loop Detection)、视觉重定位(Visual Re-localization)、视觉场景识(Visual Place Recognition)、视觉相对地形导航(visual terrain relative navigation)或地理配准、图像检索为代表,近年随着SLAM、深度学习和计算机视觉技术的发展有极大进步,尤其以众多海内外高校、无人机/自动驾驶公司为主。
视觉的导航因采集信息丰富、成本低廉,在针对商用和工业无人机的自主降落、避障和跟飞应用等特定条件下的研究取得了较大进展。在商业无人机领域,美国的Skydio 2使用NVIDIA Jetson TX2的嵌入式AI计算设备,计算6个4K摄像头采集到的图像信息,实现了全自动避障功能。大疆无人机提出的Flight Autonomy是依靠由6个视觉传感器、主相机、2组红外传感器、1组超声波传感器、GPS/GLONASS双模卫星定位系统、IMU和指南针双冗余传感器等实现的。当GPS信号丢失时,无人机利用视觉传感器与其他传感器融合,可具备一定的全局定位和导航能力。
虽然目前商用和工业无人机、自动驾驶领域,暂时还没有完全依赖视觉导航的产品,但已有不少高校和公司正在开展了基于视觉的全局定位导航系统,如特斯拉的FSD(Full Self-Driving),目前发布的10.1版本抛弃了高精地图和激光雷达,主要依靠纯视觉和AI可实现部分复杂场景下的自动驾驶能力,其路测结果显示了视觉的巨大潜力。
定位地图通常是使用Structure-from-Motion (SfM) 从一组数据库图像预先构建3D场景点组成的,每个3D地标可以与一组局部图像描述符对应。当无人机获取一张新的观测即图像后,系统可以利用从图像特征和地标之间2D-3D匹配中计算出相对或绝对位置。但是在无人机SLAM这类应用中,因为地标描述符的高内存要求,将完整场景模型保留在设备上的定位方法通常仅限于较小的探索空间,如200m*200m。
在大场景(Large Scale)中,一般会将图像回传至地面服务器去执行大规模的实时地图重建、姿态估计、定位和跟踪,并将结果回传至无人机。但一般情况下如果GPS被干扰时,链路的可靠性也难以保证。
SeqSLAM利用连续帧序列图像的相似度判断地点匹配,是目前最成功的闭环检测算法之一,能够处理重大的环境条件变化,包括由于照明、天气和一天中不同的时段等。但此方法多用于路边驾驶等情况,对无人机在不同高度、角度飞行,且存在空中自由机动的情况还需要继续补充研究。
另一方面,当场景扩大后,环境的复杂性会急剧增加,容易造成感知混淆。感知混淆是一种在不同的地方中产生相似的视觉区域现象,这通常会导致错误的定位,如图2所示,同一个场景可能会检索定位到地图中不同的位置,从而造成定位错误。
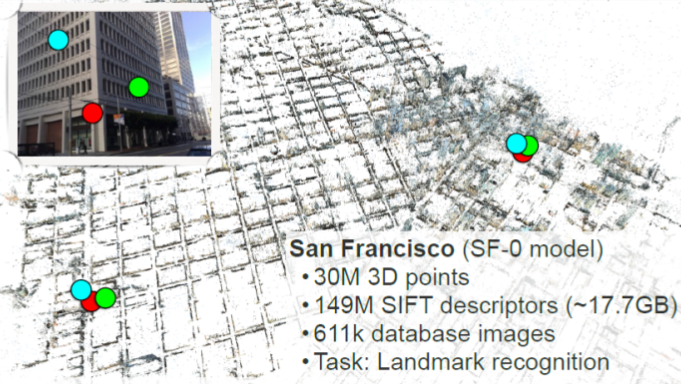
图2 大规模场景下的(城市级别)感知混淆
典型无人机自主视觉感知定位算法多见于地面无人车、机器人和小型商业无人机,一般适用于小尺度规模场景。而传统的景象匹配算法一般结合其他导航方式应用于末制导等场合,使用条件受限。
GNSS拒止条件下当无人机进行长航程自主飞行时,需要研究解决长航时导航地图的压缩、存储瓶颈问题,提升不同季节、光照、视角下的特征的稳健性,提高图像检索和匹配算法的泛化性、准确性,解决大规模地图下的实时快速的搜索问题等。近年来AI技术的兴起为VBN问题的解决提供了新的方式。
3
GNSS拒止环境下
VBN待解决的问题和措施
在GNSS信号受到干扰时可靠的视觉辅助导航应具备高度的条件(季节、结构、光照、异源传感器等)和视角(不同视角、飞行高度)不变性,能够部署在无人机的边缘终端。
视角和外观不变性的稳健图像/地图表征
视觉导航某种程度上可以被视为一个图像检索任务,必须使用相同的特征类型进行模型构建和匹配。当无人机达到一定飞行高度,可以假设平面单应性,但对地形变化较大的地区依然具备一定透视效果。机载图像与地图基准图像的成像时间、成像条件不同,即使经过预处理校正后,依然可能会存在不同程度的光照差别、旋转与角度变化、季节变化、植被变化等,如果地图表征不当,极易导致错误匹配,需要提取稳健的成像条件不变性和视角、尺度不变性的地图场景表征。同时,考虑到机载计算平台有限的存储资源和计算资源,因此地图场景表征同时也要具备高效、低冗余描述等特点。
场景和地图的描述通常分为局部特征描述子(例如SIFT和SURF特征)以及全局描述子(如Gist等)。局部特征描述在像素级别上使用固定的局部空间邻域进行优化描述,具备视角旋转不变性且可实现高精度的定位;而全局描述子对位置进行了优化,通常在直接对外观和光照变化方面鲁棒性更强,但增加视角不变性将不可避免地降低一定程度的外观不变性。
因此需要采用基于深度学习将核心的局部特征纳入全局描述符形成新的表征,学习过程采用基于注意力机制,例如Transformers和图神经网络(Graph Neural Networks)。这其中,网络的底层输出对外观变化更具备稳健性,而高层输出对视角变换更具备稳健性,因此学习到的特征能够有效地应对环境以及视角的变化。比如SuperPoint、D2、R2D2等深度学习特征代替传统SIFT、SURF等局部特征,具备更好的视角不变性;采用如NetVLAD、CALC等用神经网络模拟传统特征提取策略,可获得更好的鲁棒性。
实时可靠的高精度视觉导航匹配
当GNSS信号丢失时间较长时,惯导的定位误差累积,需要视觉导航在较大范围内进行搜索,这样会极大增加匹配算法的计算量。虽然利用语义和传统图像检索技术,可以粗筛出一组与当前机载图像相似的地图图像,供后续精细搜索,但随着地图和搜索规模的扩大,视觉导航的感知混叠现象越来越严重,粗筛的结果会含有越来越多的不相关。因此需要研究快速的图像检索和图像匹配技术。
视觉辅助导航系统的核心是图像匹配算法的选择,该算法要解决的关键问题是异源图像之间的实时可靠匹配。大多数最先进的图像描述和表征都是高维的(维度从512到70,000不等)。随着无人机飞行时间的增加,视觉导航搜索的空间急剧变大,而且当无人机长期自主时,通常必须使用多个地图参考集。若匹配算法过于复杂,搜索效率将会降低,会导致整个匹配过程耗时过长,影响导航效果。
因此,设计分层的实时可靠视觉导航匹配技术。首先利用,对高维的描述符空间进行投影、量化和聚类,以最小的精度损失提高了最近邻 (NN)搜索的效率采,用反向索引加速图像检索速度,选择出最佳的候选地点集合(如排名前20个地点)。然后在候选地图集合中,利用航拍成像条件和地图信息,利用几何信息,实时解算出飞机的绝对位置和姿态。
此外,场景的语义线索不像像素强度那样容易受到条件变化的影响,因此可以采用基于深度学习的物体检测和语义信息分割技术,对场景进行识别、跟踪和语义的标记,可以剔除部分场景中的无效区域(如空中云彩等),重点利用外观不变的对象如标志性建筑形成稳定的图像描述符,可加速地图匹配和搜索的过程。同时利用环境的动/静分割加强无人机对地图场景的理解,可以适应地图一定程度的动态变化。
视觉导航在有限计算资源机载平台的部署
传统的视觉辅助导航技术难以突破在不同场景下的可靠定位瓶颈,基于深度学学习的技术在场景光照变化大,相机视野变化大等方面对传统方法形成碾压性优势,是未来基于视觉无人机导航发展的必然趋势。但是深度学习技术计算量大,参数动辄百万级,现有的CPU、FPGA等传统机载计算平台难以满足实时性的计算要求。随着低成本低功耗的AI加速芯片的推出,可将深度学习模型部署到无人机平台,利用AI芯片的异构加速技术,降低视觉导航流程的时延,不仅可以实现态势感知、目标识别跟踪等任务,更可以利用图像语义分析的信息,无人机视觉导航定位,使其更适用与动态环境下的自主飞行。
·
总结
视觉导航但因成像时存在不同季节、光照、视角、传感器等原因,其使用收到较大限制。同时,如何处理大规模地图的建图和搜索也是部署到无人机终端一个亟待解决的问题。近年来,随着AI技术的发展,国内外各研究机构陆续开展了VBN问题的研究,并进行了各种实际数据采集和应用挑战赛,如近年来ICCV等会议陆续推出场景识别比赛等。后续可充分借鉴自动驾驶、商用无人机、机器人等先进技术,结合长航程自主飞行的传感器特点、使用需求、计算资源等进行研究和测试。
审核编辑 :李倩
-
无人机
+关注
关注
230文章
10453浏览量
180667 -
图像传感
+关注
关注
0文章
18浏览量
14615 -
自动驾驶
+关注
关注
784文章
13835浏览量
166519
原文标题:无人机视觉导航,还有哪些问题需要解决?
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
无人机干扰器干扰手机信号吗
无人机干扰器对网络的影响
反制无人机的技术进展:国内外先进系统与技术概览

反无人机系统发展现状:应对无人机入侵威胁的利器|特信电子

无人机遭遇“神秘杀手”:揭秘反无人机技术的崛起

第四集 知语云智能科技无人机反制技术与应用--无人机的组成与工作原理
第三集 知语云智能科技无人机反制技术与应用--无人机的应用领域
第二集 知语云智能科技无人机反制技术与应用--无人机的发展历程
第一集 知语科技无人机反制技术与应用--无人机的定义与分类
无人机蜂群作战概念及国内外发展现状






 工商网监
工商网监
评论