 面向实体对象的文本描述情感极性及色彩强度分析
面向实体对象的文本描述情感极性及色彩强度分析
之前没认真打过炼丹的比赛,这次机缘巧合碰上了三个牛逼又靠谱的队友,就坚持把这次比赛打完了。刚开始的时候没想到这次能拿下第一,趁着刚答辩完就顺带把这次NLP赛道的方案开源出来,欢迎各位同学参考和讨论。
赛题分析
赛题介绍
这次的比赛由NLP和推荐两部分组成,推荐的特征工程实在是做不明白,这次主要还是做NLP的部分。
抄一下官网的NLP赛题介绍:面向实体对象的文本描述情感极性及色彩强度分析。情感极性和强度分为五种情况:极正向、正向、中立、负向、极负向。选手需要针对给定的每一个实体对象,从文本描述的角度,分析出对该实体的情感极性和强度。
NLP任务的评价指标为macro-F1,在计算准确和召回的时候,是按照分析的实体数进行计数的,而非样本数。
拿一条数据来举例子(截取部分文本):
{ "content": "离婚之后的林庆昆本以为会有一番更大的天地,没想到离开了吴敏自己什么都不是......", "entity": {"吴敏": 1, "林庆昆": -1} }
这条数据里有一段文本和两个实体,需要预测出这两个实体在文本中的情感极性,情感标签为-2, -1, 0, 1, 2五个。
简单分析可以知道这题可以定义为Aspect-level Sentiment Classification。
数据分析
在正式建模之前需要进行一些简单的数据分析来挖掘赛题的特点。在这里截取一张和队友一起做的PPT的图:
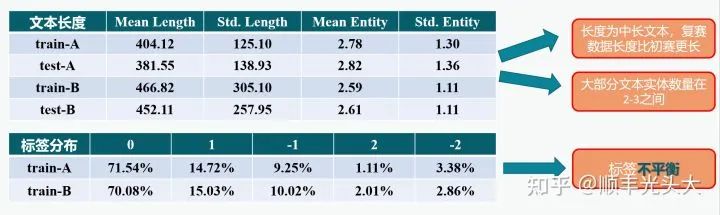
数据分析
我们对数据中的文本长度、实体数量和标签分布进行了简单的分析,这提示我们:
有部分文本长度超过BERT的512最大长度,或许可以考虑长文本处理的常用技巧;
实体的情感标签分布不平衡,最少的类只有2%左右,或许可以考虑不平衡分类问题的技巧。
但实验证明上面这些考虑最后都只会成为掉分点,具体的思考在后文论述。
模型构建
Baseline
官方公布了赛题的Baseline,NLP赛道的Baseline大致是如下思路:将一段文本和文本中的一个实体拼成一条数据,一段文本对应N个实体就会有N条数据。将一条数据输入BERT-based分类器后输出一个实体。
仍然以上一节的case为例,按Baseline的做法这条数据会被拆成两条数据输入到BERT:
[CLS] 吴敏 [SEP] 离婚之后的林庆昆本以为会有一番更大的天地,没想到离开了吴敏自己什么都不是... [SEP] [CLS] 林庆昆 [SEP] 离婚之后的林庆昆本以为会有一番更大的天地,没想到离开了吴敏自己什么都不是... [SEP]
然后以BERT输出的[CLS]位置的语义向量通过MLP分类器得到情感极性。
实际上我想思路的时候我还没看到Baseline,看到Baseline的做法之后我就摇头。
这里再截一张PPT的图说明Baseline有什么问题:

就是说,一方面预期效果不好,因为Baseline构造数据的方式使分布发生了变化(有一个实体的文本模型会看它一次,有30个实体的文本模型就会看它30次,但是这点也存疑,因为答辩过程中有选手表示发现了数据的leak,后续的方法可能是使用了这个leak所以效果才会好的);另一方面把一段文本复制了好多遍显然会导致效率大大下降;还有一点在PPT里没说的是没有考虑到实体之间可能存在的潜在关系。
设计思路
再从PPT里截一张图:

在做这题的时候我就会思考如何做得优雅,最好方法是simple yet effective的。最好就是使用以预训练BERT为backbone的分类器,不对模型结构做太大修改,而且还要能在一次输入之内就并行分类所有实体。
除了BERT还考虑使用XLNet,因为XLNet使用了相对位置编码,可以原生支持超长文本的输入,而且XLNet的Tokenizer是字词结合的,可以适应本次比赛文本长度较长的情况。
模型架构
大概想了不到一个小时,想到了如下的方案:
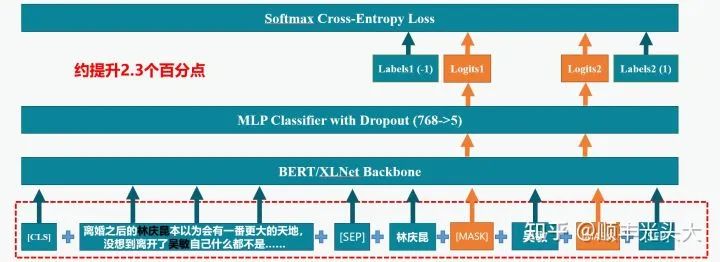
如图所示,模型的整体架构就是一个普通的分类模型,在预训练的BERT或XLNet模型基础上增加了简单的MLP分类器。这个思路的要点在于改变数据输入的方式,利用BERT和XLNet作为Masked Language Model的性质,以[SEP]符号为界,第一段为文本输入,第二段按顺序输入所有实体,实体之间以[MASK]进行分隔,这个[MASK]标签通过BERT Encoder得到的语义向量就代表对应实体的情感极性。将所有[MASK]位置的语义向量通过分类器即可并行对所有的实体进行分类。
这套思路不加Trick的情况下线上F1就可以到69+,让我在比赛前期就能超过大部分使用Baseline的团队。
另外根据线下指标推测最终Accuracy在90+,说明这题训练和测试集基本上同分布。
一些补充的思考
要说这个方法为什么会有用,我一开始推测是因为考虑了实体之间的潜在关系,而且对数据分布的假设更加合理。
后来决赛答辩的时候听到有选手提到这个数据存在leak,也就是在数据中标签非0的实体会被排在前面,标签为0的实体会被排在后面。我突然就觉得这可能就是这个方法提升巨大的真正原因,用了这个方法之后,相当于模型从中学到了一个bias,就是靠近文本末尾的实体,标签为0的可能性更大。
另外,在比赛中期,“灵境”组在讨论区公开了一个方案,我们发现该方案的核心思路和我们不谋而合。在该方案公开后很多队伍的分数都追上来了,在决赛答辩过程中我也发现很多高分团队都搬运了这套方案。公开的方案和我们做法基本一致,不过使用了一个含有MLM的全套BERT类模型,第二段文本(在该方案中被称为Prompt)的形式为:“在这句话中,<实体1>是[MASK],<实体2>是[MASK]......”,然后MLM头输出词表大小维度(21128)的向量,取五个Token作为Verbalizer(坏、差、平、行、好),分别对应五个情感极性标签,忽略其他的Token。
然而,这套方案和我们的做法还存在一定差别,这也是我认为该方案在这个任务上存在的一些问题:
我们不称输入的第二段文本为"Prompt",因为这容易和Prompt Tuning概念中的Prompt混淆。该任务并不适合Prompt Tuning范式,而仍然是采用普通的对全模型进行参数更新的Full Tuning范式。因此在该题中,“Prompt”的形式如何并不重要,增加一些没什么用的词反而会挤占第一段文本的输入长度。
该方案使用了BERT的MLM头进行分类,21128维的词表中只有五个Token映射到有效标签,其余Token都被忽略。这和我们的方案在结构上基本等价,唯一的区别是该方案有MLM头的参数初始化而我们的分类层为随机初始化,这个区别是否会带来性能提升不知道,但是直观的是模型增加了至少768*21123=16M(或者1024*21123=22M)的无用参数量,在题目有模型总大小限制的情况下这意味着可以融合的模型变少了。
模型优化
针对上述提出的模型,我们进行了很多优化尝试,下面主要讨论上分较多的技巧,没什么用的东西就在最后放一小节补充说明。很多优化技巧都会导致训练或测试阶段时空开销大大提升,比赛时还是应该视情况使用。
线下数据划分方式
队友发现,初赛阶段使用前90%数据训练,后10%验证,可以取得最好的线上效果,随机10%效果会变差一些,增加训练数据也不能使效果变好。复赛阶段使用了同样的数据划分方式。
对抗训练(FGM)
在各类文本分类任务中,常用的提升NLP模型训练鲁棒性和泛化能力的有效方法。简单来说是在Embedding层的参数有一定程度扰动时也尽量保证模型能分类正确。事后估计初赛线上提升1%左右。
参考了这篇知乎文章的实现方法:Nicolas:【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现
模型平均 (SWA)
对训练过程中的多个checkpoint进行权重平均,或许可以有助于模型收敛到loss landscape平坦区域的中心,提升模型的泛化能力。具体而言,我们在验证指标的最高点开始,将这一轮和到Early Stopping之前的各轮验证时,验证指标与最高点差值小于一定值的模型权重放进来平均。事后估计初赛线上提升1%左右。
模型融合
没什么好说的,几个模型预测的logits平均得到最终结果。值得注意的是这题有2G的模型总大小限制,因此我们需要考虑融合模型的异构度不能盲目做K折,最后融合了2个稍微异构的XLNet-Mid + 1个MacBERT-Large + 1个RoBERTa-Large,全部保存为FP16格式,模型文件总大小2043M正好小于2G。估计初赛提升大约1%,复赛提升大约2%。
伪标签
在模型融合的基础上,使用融合模型预测的测试集标签作为伪标签,将测试集数据加入训练集中再次训练模型。在复赛中,我们为了避免多模型在测试集上的预测结果失去异构性,我们没有把全部测试数据都加入训练集,而是四个模型预测结果投票,大于等于三个模型预测一致的数据才会被加入训练集。这个训练集会重新被用于训练四个模型,然后重新进行融合。复赛在模型融合基础上还有1%左右的提升。
复赛数据适配
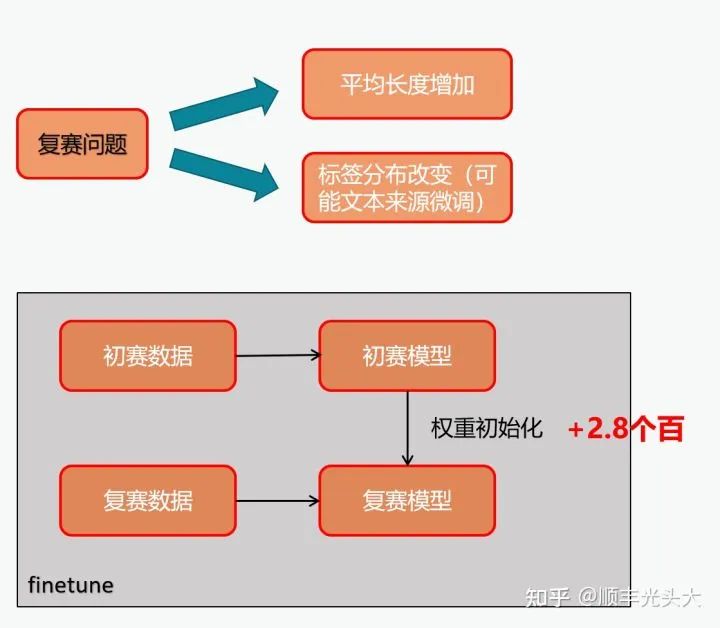
如图所示。在复赛开始的时候,起初我们使用初赛训练集+复赛训练集的全量训练数据对模型进行训练,结果发现效果不好。后来发现复赛数据相比初赛数据的分布可能发生了较大的偏移,因此我们考虑用初赛训练好的模型的权重来对模型进行初始化,然后只在复赛数据集上训练。相比全量数据训练提升近3%,验证了我们的猜想。
没什么用的
R-Drop:在有了FGM,SWA等东西的情况下没有什么提升,而且还慢。
PGD:慢而且相比FGM没什么提升。
EMA:有了SWA之后也显得没用。
数据增强:尝试了EDA和AEDA,本来以为会有用实际上没用。
长文本处理:估计是没有什么用,某次偶然发现设置最大长度512的XLNet和最大长度800的XLNet相比效果基本没有差别,用MacBERT和RoBERTa训的模型和XLNet比效果也相差不大。推测可能是因为前半段文本的信息量已经足够对绝大多数实体正确分类了。
标签不平衡处理:尝试过Focal Loss和类别重加权,也没有什么用。猜测可能是因为数据中2和-2的数据量也相对充足(各有几千个实体),在普通Cross Entropy下充分学习也可以对这些类大部分样本正确分类了,而修改Loss反而会扭曲模型学习到的分布,对于训练和测试同分布的情况下反而不利。
评测结果
初赛、复赛和决赛评测均为NLP赛道第一。
审核编辑 :李倩
-
数据分析
+关注
关注
2文章
1464浏览量
34340 -
nlp
+关注
关注
1文章
489浏览量
22228
原文标题:竞赛 | Aspect-based的情感分析任务第一名方法解读 -- 2022搜狐校园算法大赛
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
高精度焊接强度分析仪的应用与优势探析
超级电容是极性电容还是无极性电容

超级电容是极性电容还是无极性电容?

如何使用自然语言处理分析文本数据
图纸模板中的文本变量
如何在文本字段中使用上标、下标及变量

浅谈永磁电机与磁感应强度的关系
反极性Buck-Boost电路分析
有极性电容怎么变成无极性电容
有极性电容和无极性电容可以通用吗
spwm单极性和双极性的区别是什么
【《大语言模型应用指南》阅读体验】+ 基础知识学习
极性电容可以用无极性电容代替吗
如何学习智能家居?8:Text文本实体使用方法






 工商网监
工商网监
评论