 基于Cascade R-CNN的布匹检测算法提高目标检测性能
基于Cascade R-CNN的布匹检测算法提高目标检测性能
作者:许胜宝,郑飂默,袁德成
布匹缺陷检测任务的难点可能有以下几个方面:小目标问题,缺陷具有极端的宽高比,样本不均衡。在MS COCO数据集[1]中,面积小于32×32像素的物体被认为是小目标。小目标具有分辨率低,图像模糊,携带的信息少的特点,导致其特征表达能力弱,也就是在提取特征过程中,能提取到的特征非常少,不利于其检测;布匹疵点由于生产工艺的原因常常具有极端的宽高比,例如断经、断纬等,给其边界框的预测增添了难度;样本不均衡是指部分疵点拥有大量的训练样本,而另一部分疵点则只有少数的样本,让分类器学习起来很困难。 针对小目标问题,Hu等[2]认为小目标在ROI池化之后会破坏小尺度目标的结构,导致物体结构失真,于是提出了新的场景感知ROI池化层,维持场景信息和小目标的原始结构,可以在不增加额外时间复杂度的前提下提升检测精度;Li等[3]提出了Perceptual GAN网络来生成小目标的超分表达,Perceptual GAN利用大小目标的结构相关性来增强小目标的表达,使其与其对应大目标的表达相似,从而提升小目标检测的精度。 针对布匹缺陷极端的长宽比,陈康等[4]提出了通过增加锚定框的尺寸和比例来增加锚定框的数量,最终提升了对多尺度目标的检测。孟志青等[5]提出基于快速搜索密度顶点的聚类算法的边框生成器,结合真实框的分布特征分区间对聚类中心进行加权融合,使区域建议网络生成的边界框更符合布匹疵点特征。 针对样本不均衡,Chawla等[6]提出了人工少数类过采样法,非简单地对少数类别进行重采样,而是通过设计算法来人工合成一些新的少数样本,减少随机过采样引起的过度拟合问题,因为生成的是合成示例,而不是实例的复制,也不会丢失有用的信息;Yang等[7]通过半监督和自监督这两个不同的视角去尝试理解和利用不平衡的数据,并且验证了这两种框架均能提升类别不均衡的长尾学习问题。 针对布匹疵点小目标多,极端长宽比的问题,本文提出一种改进的Cascade R-CNN[8]布匹疵点检测方法,为适应布匹疵点的极端长宽比,在特征提取网络的后三个阶段采用了可变形卷积(DCN)v2[9],在RCNN部分采用了在线难例挖掘(OHEM)[10]来提高小目标的检测效果,并采用完全交并比损失函数(CIoU Loss)[11]进一步提升目标边界框的回归精度。
改进Cascade R-CNN的面料疵点检测方法
Faster R-CNN[12]的单一阈值训练出的检测器效果有限,本文采用了Cascade R-CNN网络结构,如图1所示。其在Faster R-CNN的基础上通过级联的方式逐阶段提高IoU的阈值,从而使得前一阶段重新采样过的建议框能够适应下一个有更高阈值的阶段。工业场景下目标面积小,特征微弱,通过多级调整,可以使网络集中于低占比的缺陷目标,最终获得更为精确的检测框。
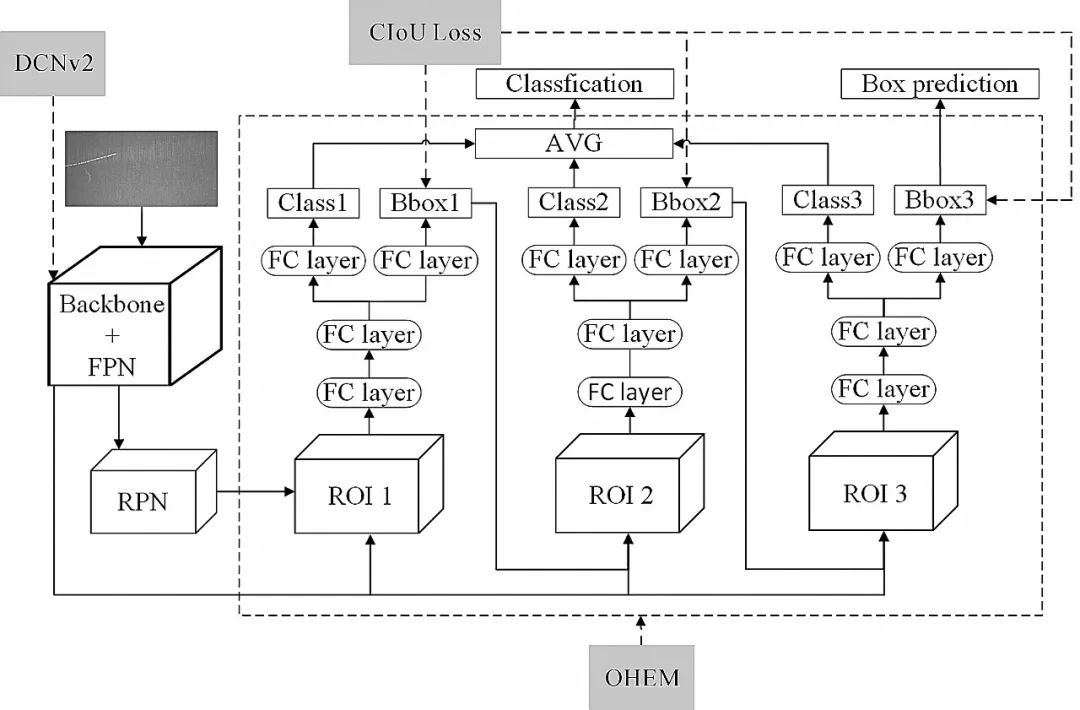
图1 Cascade R-CNN网络结构
Fig.1 Architecture of the Cascade R-CNN network
考虑到实验环境的显存和算力,骨干网络主要采用了ResNet50[作为特征提取网络来进行对比实验,并接入特征金字塔网络进行多尺度的特征融合,提升对小目标的检测效果。
1.1 在线难例挖掘采样
在两阶段的目标检测模型中,区域建议网络会产生大量的建议框,但一张图片的目标数量有限,绝大部分建议框是没有目标的,为了减少计算量,避免网络的预测值少数服从多数而向负样本靠拢,需要调整正负样本之间的比例。 目前常规的解决方式是对两种样本进行随机采样,以使正负样本的比例保持在1∶3,这一方式缓解了正负样本之间的比例不均衡,也被大多数两阶段目标检测方法所使用,但随机选出来的建议框不一定是易出错的框,这就导致对易学样本产生过拟合。 在线难例挖掘就是多找一些困难负样本加入负样本集进行训练,如图2所示,b部分是a部分的复制,a部分只用于寻找困难负例,b部分用来反向传播,然后把更新的参数共享到a部分,a部分正常的前向传播后,获得每个建议框的损失值,在非极大值抑制后对剩下的建议框按损失值进行排序,然后选用损失较大的前一部分当作输入再进入b部分进行训练。
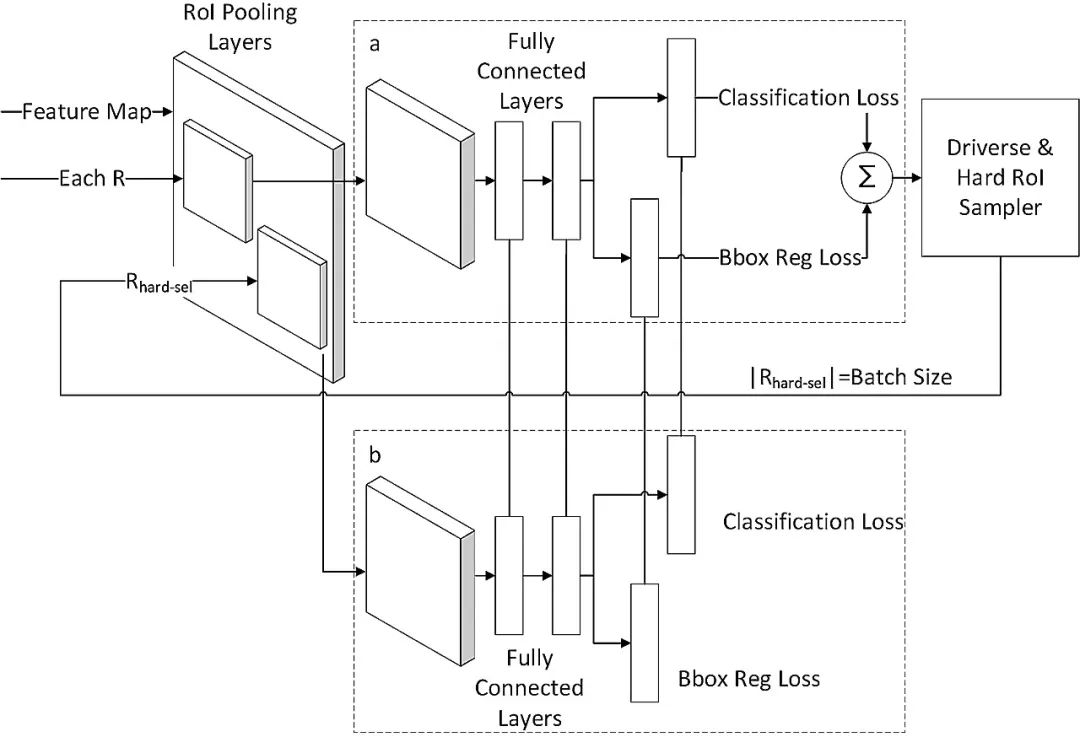
图2 在线难例挖掘结构
Fig.2 Architecture of online hard example mining
布匹疵点中的小目标疵点往往难以检测,小目标常常被划分为难例,在Cascade R-CNN的每个级联层引入在线难例挖掘采样之后,提高了整个网络的短版,防止了网络针对大量易学样本过拟合,有利于提升面料疵点的检测精度。训练集越大越困难,在线难例挖掘在训练中所选择的难例就越多,训练就更有针对性,效果就越好。而布匹疵点恰好小目标多,宽高比方差大,难例较多,更适合在线难例挖掘的应用,通过让网络花更多的精力学习难样本,进一步提高了检测的精度。
1.2 可变形卷积v2
可变形卷积v2由可变形卷积[15]演变而来。可变形卷积顾名思义就是卷积的位置是可变形的,并非在传统的N×N的网格上做卷积,传统卷积仅仅只能提取到矩形框的特征,可变形卷积则能更准确地提取到复杂区域内的特征。以N×N卷积为例,每个输出y(p0),都要从中心位置x(p0)上采样9个位置,(-1,-1)代表x(p0)的左上角,(1,1)代表x(p0)的右下角。传统的卷积输出如式(2),R为规格网格,而可变形卷积如式(3),在传统卷积操作上加入了一个偏移量Δpn,使采样点扩散成非网格的形状。
R={(-1,-1),(-1,0)...,(0,1),(1,1)}(1)
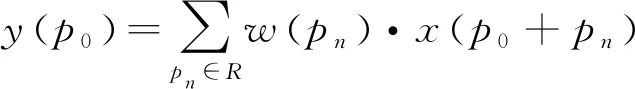 (2)
(2)
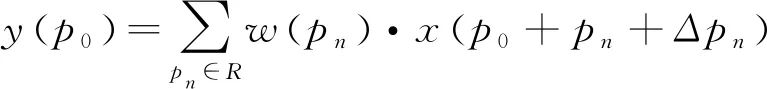 (3)
(3)
而可变形卷积v2如式(4),在可变形卷积的基础上加上了每个采样点的权重Δmn,这样增加了更大的变形自由度,对于某些不想要的采样点可以将权重设置为0,提高了网络适应几何变化的能力。
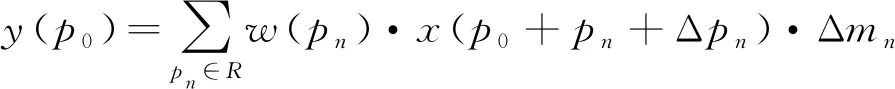 (4)
(4)
ResNet网络共有5个阶段,如图3所示,第一阶段为对图像的预处理,结构较为简单,后4个阶段结构类似,包含不可串联的Conv Block和可串联的Identity Block。本文在ResNet50骨干网络的最后3个阶段采用可变形卷积v2,能够计算每个点的偏移和权重,从最合适的地方取特征进行卷积,以此来适应不同形状的瑕疵,缓解了传统卷积规格格点采样无法适应目标的几何形变问题,如图4所示,改进后的骨干网络更能适应布匹疵点的极端长宽比,有利于疵点的精确检测。
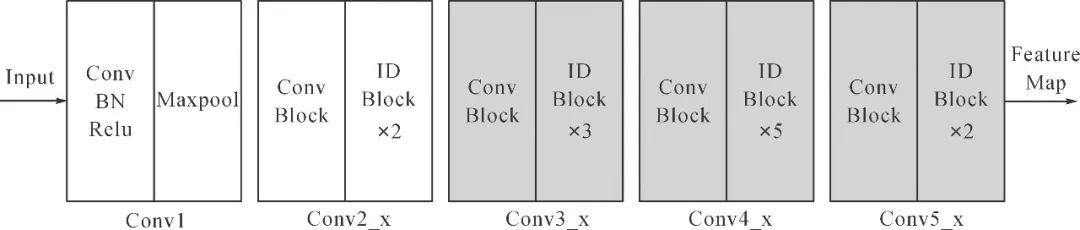
图3 Resnet骨干网络结构
Fig.3 Architecture of Resnet backbone network
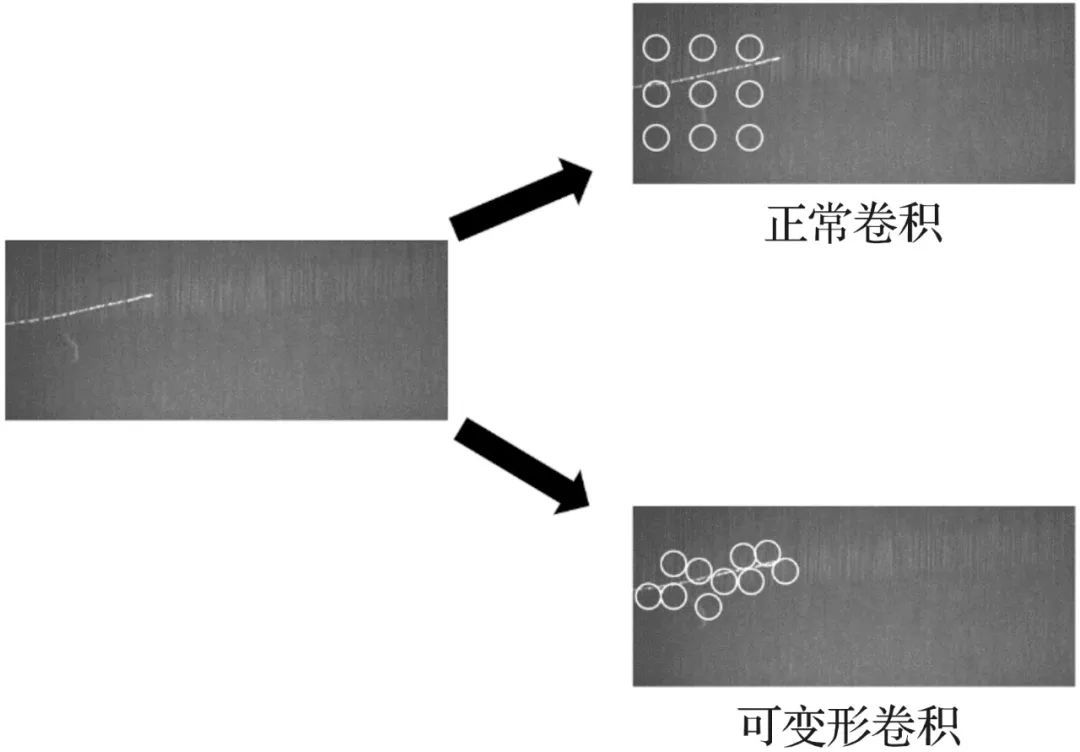
图4 可变形卷积示意
Fig.4 Diagram of deformable convolution
1.3 完全交并比损失函数
目标检测中常用的边界框回归损失函数有L1 Loss,L2 Loss,Smooth L1 Loss,上述3种损失在计算时,先独立地求出边界框4个顶点的损失,然后相加得到最终的边界框回归损失,这种计算方法的前提是假设4个点是相互独立的,但实际它们是相关的。而评价边界框的指标是IoU,如式(5)所示,即预测边界框和真实边界框的交并比。
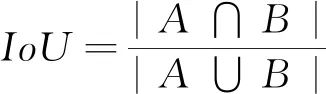 (5)
(5)
但上述3种损失和IoU并不等价,多个边界框可能损失大小相同,但IoU差异较大,因此就有了IoU Loss[16],如式(6)所示。
IoU Loss=-ln(IoU)(6)
IoU Loss直接把IoU作为损失函数,但它无法解决预测框和真实框不重合时IoU为0的问题,由此产生了GIoU Loss[17],GIoU如式(7),对于两个边界框A和B,要找到一个最小的封闭形状C,让C将A和B包围在里面,然后计算C中没有覆盖A和B的面积占C总面积的比例,最后用A和B的IoU值减去这个比值。
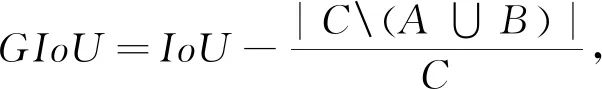 (7)
(7)
但是当目标框完全包含预测框时,GIoU退化为IoU,IoU和GIoU的值相等,无法区分其相对位置关系,由此产生了DIoU和CIoU。DIoU将真实框与预测框之间的距离,重叠率以及尺度都考虑进去,如式(8):
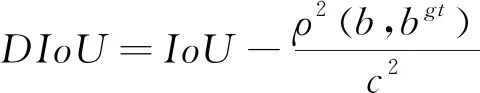 (8)
(8)
式中:b,bᵍᵗ分别代表预测框和真实框的中心点,ρ表示计算两个中心点之间的欧式距离,c表示包含预测框和真实框的最小外界矩形的对角线长度。 CIoU考虑到边界框回归中的长宽比还没被考虑到计算中,在DIoU惩罚项的基础上添加了影响因子αv,如式(9):
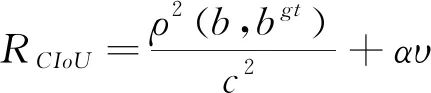 (9)
(9)
式中:α是权重函数, v表示长宽比的相似性,如式(10):
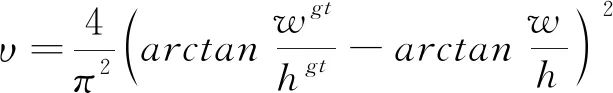 (10)
(10)
式中:w、wᵍᵗ分别代表预测框和真实框的宽度,h、hgt分别代表预测框和真实框的高度。 最终CIoU的损失定义如式(11):
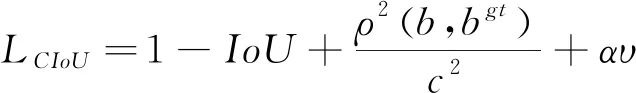 (11)
(11)
本文将原始模型中的边界框回归损失选为CIoU Loss,CIoU能够将重叠面积,中心点距离,长宽比这3个几何因素都考虑进去,相比其他边界框损失函数,其收敛的精度更高,从而可以提升布匹疵点检测时的定位准确度。
实验结果与对比分析
2.1 实验数据集
本文使用天池布匹疵点数据集,包含约9 600张大小为2 446×1 000的纯色布匹图像,其中正常图片约3 600张,瑕疵图片约6 000张,每张图片包含一种或多种瑕疵的一个或几个,共9 523个疵点,包含了纺织业中常见的34类布匹瑕疵,将某些类别合并后,最终分为20个类别。各类疵点的分类及数量见表1,其中6百脚、9松经、10断经、11吊经、14浆斑等属于宽高比比较极端的疵点,3三丝、4结头、7毛粒、12粗纬、13纬缩等属于小目标的疵点。
表1 布匹瑕疵的分类与数量
Tab.1 Classification and quantity of fabric defects
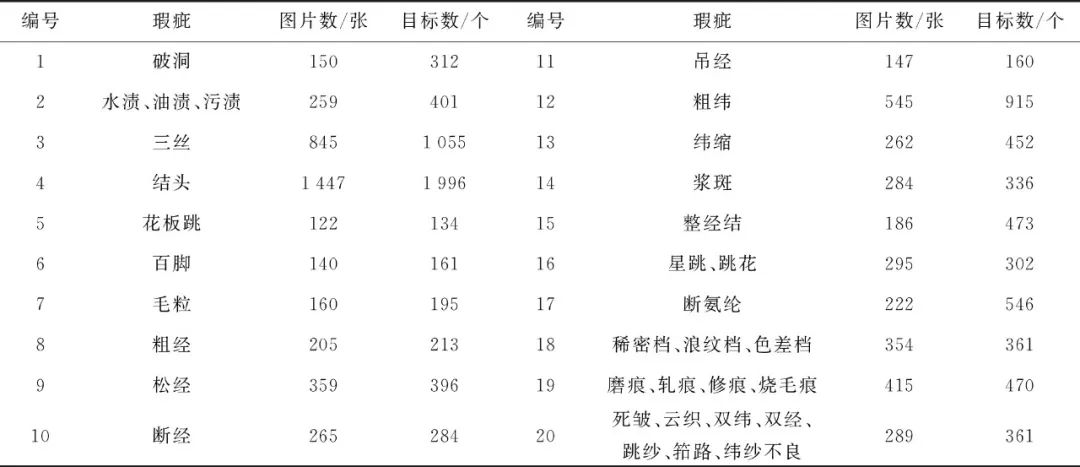
图5为数据集中不同类型疵点的目标数统计,不同疵点间数目差异巨大,种类分布严重不均,例如结头近2 000个样本,而花板跳只有134个样本,这容易产生过拟合,使训练出的模型泛化能力较差;图6 展示了不同类型疵点的宽高比,从零点零几到五十,疵点尺寸差异较大;图7展示了典型的宽高比悬殊的疵点;图8为不同面积目标的数量占比,其中小目标占比较高,约四分之一,这些都给布匹疵点的检测带来了困难。
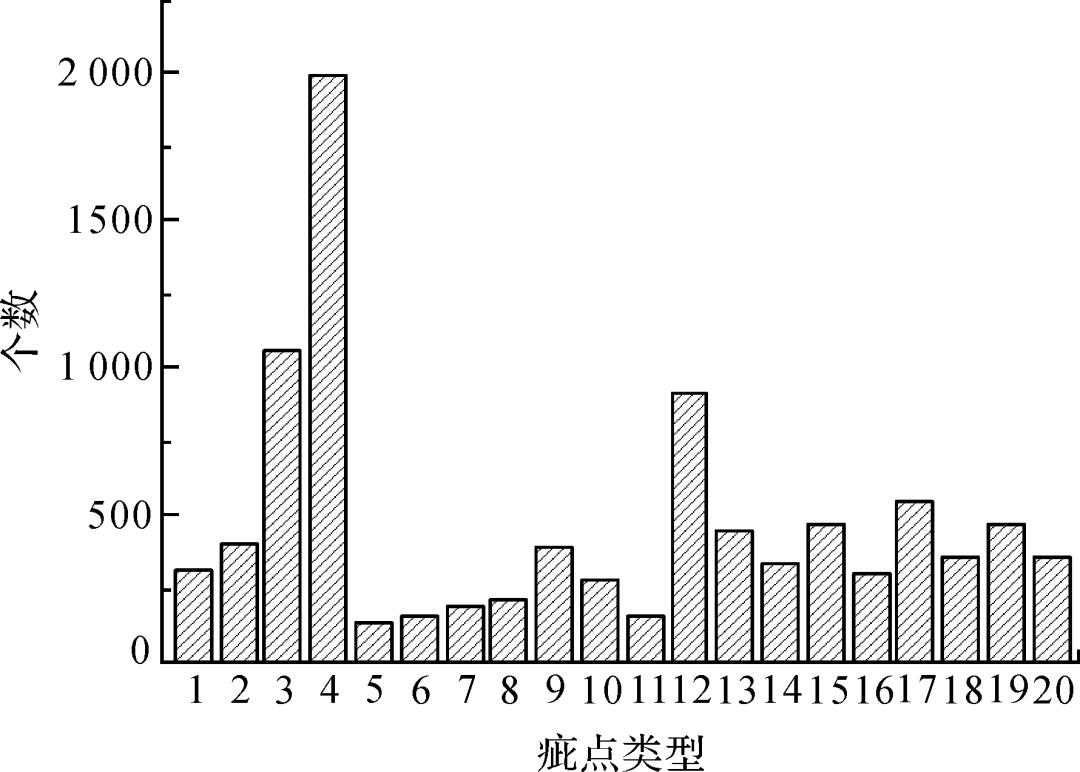
图5 不同类别目标数统计
Fig.5 Statistics of target number of different categories
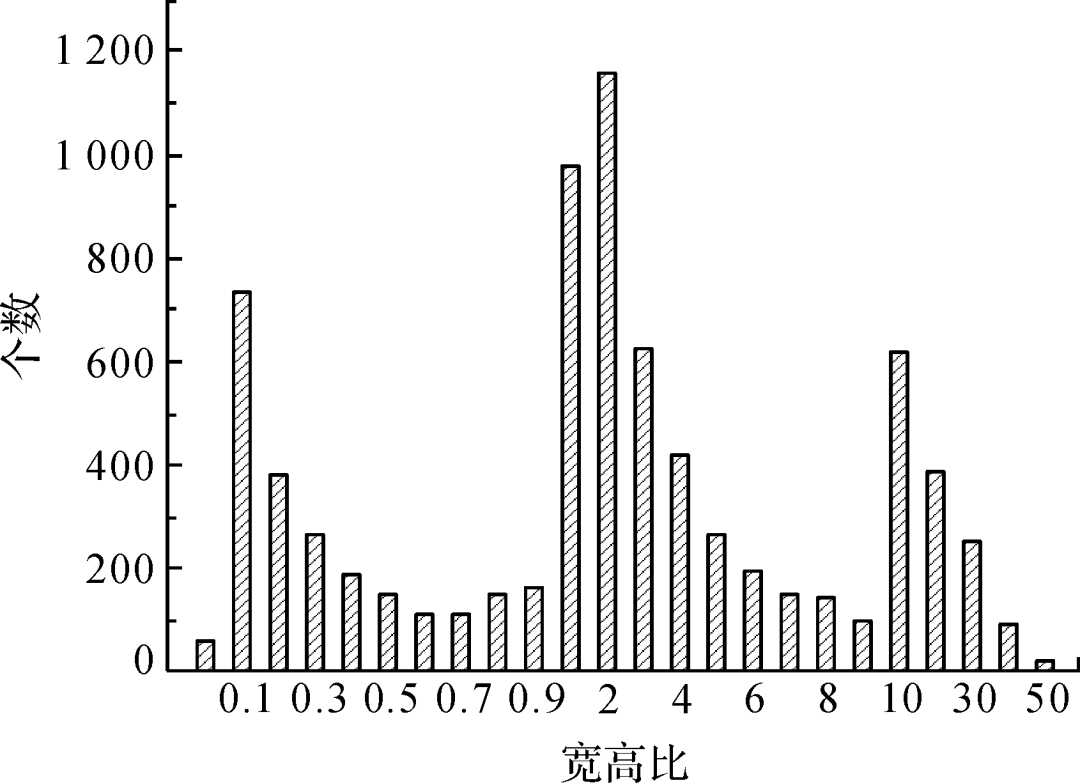
图6 目标宽高比统计
Fig.6 Statistics of target aspect ratio

图7 典型疵点
Fig.7 Typical defects
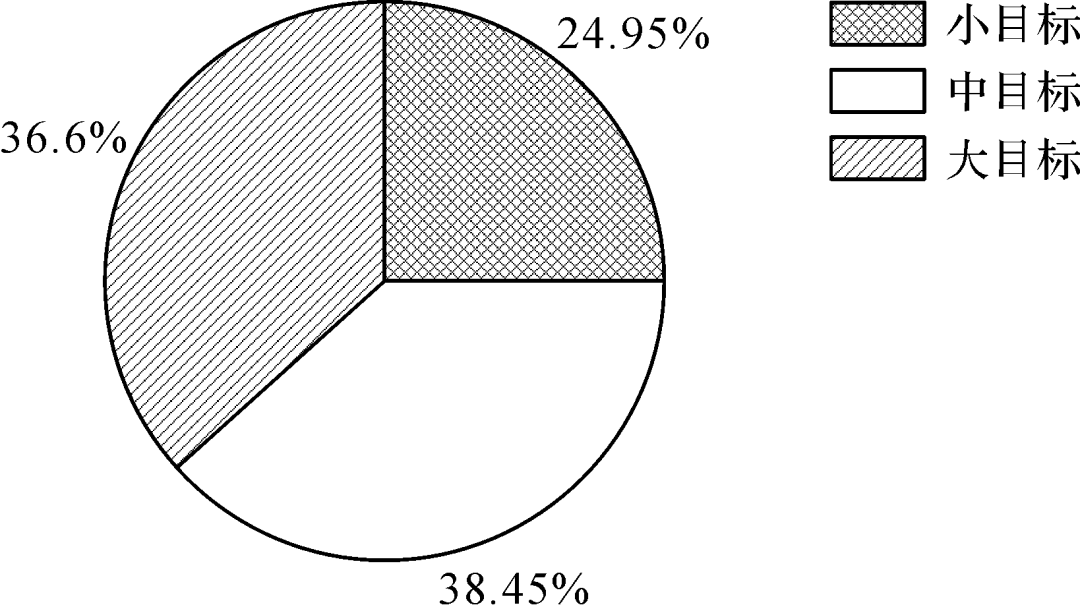
图8 目标面积统计
Fig.8 Statistics of target area
由于数据尺度固定,也不涉及自然场景,非常适合通过上下反转等操作来进行数据增强。为减少过拟合,降低疵点种类分布不均的影响,本文对样本数小于200的四类疵点进行了水平翻转和垂直翻转的线下增强,对样本数在200~300之间的三类疵点进行了水平翻转的线下增强,最终将数据集扩充到约 10 000 张瑕疵图片。
2.2 实验环境及配置
实验运行的环境为英特尔i9 10900X,GeForce RTX3080,32G内存,Ubuntu18.04操作系统。 为尽可能地利用实验数据,训练集中只使用瑕疵图片,随机选1000张正常图片进行两等分,分别放于验证集和测试集,并向验证集和测试集中加入瑕疵图片,最终训练集、验证集和测试集比例约为60%、20%和20%。对于所提出的Cascade R-CNN卷积神经网络,选择交叉熵作为分类损失函数。为了加快收敛速度,使用了COCO的预训练权重,并设置了梯度裁剪来稳定训练过程,避免产生梯度爆炸或梯度消失。 考虑到样本的宽高比差异较大,而Cascade R-CNN 网络原始的边界框比例是根据COCO数据集设计的,原始的[0.5,1.0,2.0]的比例并不能满足布匹疵点的需要,因此将边界框比例设计为[0.02,0.05,0.1,0.5,1.0,2.0,10.0,20.0,50.0]来提高检测精度。 用Soft-NMS[18]代替了原模型中NMS[19],Soft-NMS没有将其重合度较高的边界框直接删除,而是通过重合度对边界框的置信度进行衰减,最终得到的结果并非一定是全局最优解,但比NMS更泛化,能有效避免面料疵点丢失,且不会增加算法的复杂度[20]。
2.3 实验结果对比
在进行数据扩增前,数量多的样本能够最先被识别出来,而且最终的平均精确度较高,而数量少的样本,识别出来的较晚,且最终的平均精确度较低,模型明显过拟合,偏向于数量较多的样本,通过对类别少的数据进行数据扩增,有效的缓解了这一问题,且最终的检测精度也有提升。 模型改进前后的检测效果对比如图9所示,改进前后的效果按照上下分布,改进后的模型对目标的边界识别更加精准,对小目标的检出能力更强,疵点检测效果更好。

图9 模型改进前后的检测效果对比
Fig.9 The Comparison of detection effect before and after model improvement
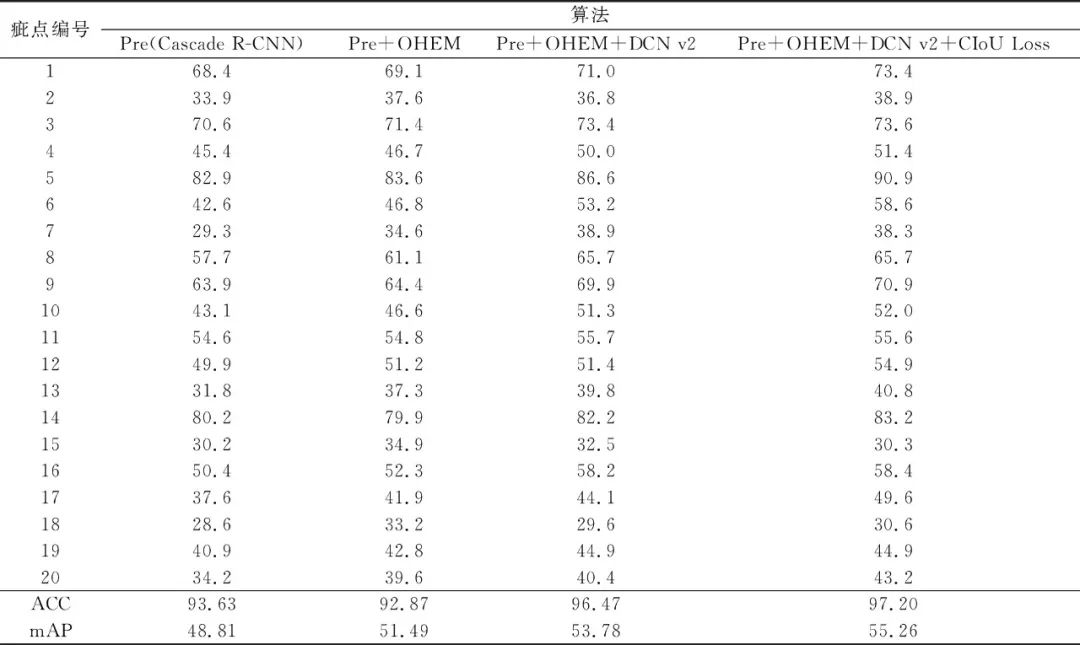
为了对比模型的性能,本文以准确率ACC和平均精确度均值mAP[21]作为评价指标,ACC是有瑕疵或无瑕疵的二分类指标,评估瑕疵检出能力。mAP是所有类别的平均精确度的均值,参照PASCALVOC的评估标准[22]进行计算。模型改进前后的评价参数如表2所示,在线难例挖掘采样对2、7、13、15、17、18、20等类别的提升较大,这些类型本身的AP较低,可以归为难例,证明了在线难例挖掘采样的有效性。引入OHEM后,虽然模型准确率略微下降,但平均精确度均值还是有较为明显的提升。综合来看,改进后的模型在准确率和平均精确度均值上分别提升了3.57%和6.45%,证明了上述3种方法的有效性。
表2 模型改进前后的评价参数
Tab.2 Evaluation parameter before and after model improvement %
影响小目标检测效果的因素有输入图像的尺度、小目标的数量、特征融合、边界框的设计和光照强度等,为了获得更好的检测效果,在训练出模型后,再在不同的光强下对测试集进行测试,本文使用了mmdetection框架的线上调整亮度的方式,将亮度划分为0~10之间的小数范围,对比实验结果如表3所示,不同光强下的平均精确度均值差异较大,验证了光强对布匹疵点的识别影响较大,但本文未能找到统一的最佳的光照强度,后通过比较数据集发现,本文数据源于实际工业场景,不同数据已有明显不同的光强,且布匹颜色并不一致,不同颜色的布匹最合适的光强可能并不一致,因此本文的后续实验不再调整统一的光照强度,采用原始数据集的亮度。
表3 不同光照强度下测试集的对比
Tab.3 The comparison of the proposed algorithm under different light intensities on test sets
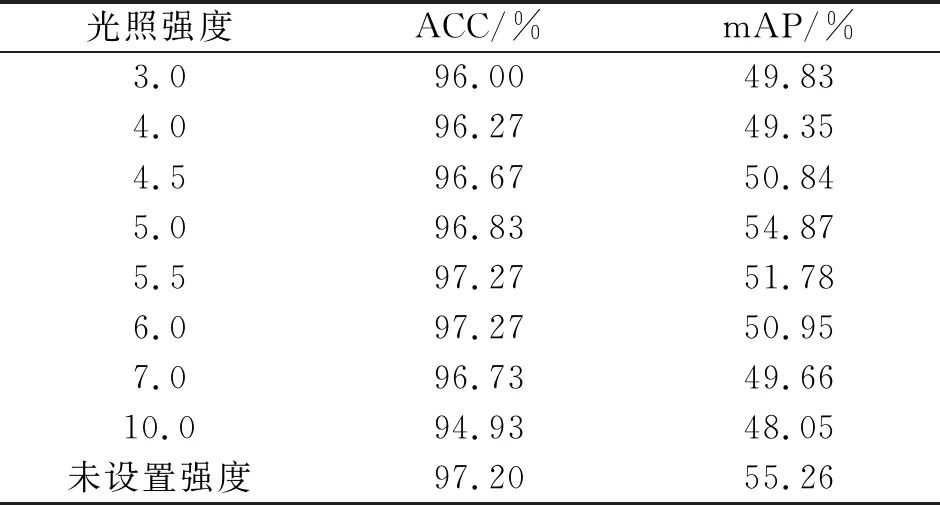
表4为引入在线难例挖掘采样前后的模型性能对比,在引入在线难例挖掘之后,测试集上的性能明显提升,而训练集上的性能反而下降,证明了在线难例挖掘采样能够减轻模型的过拟合,同时对于模型的性能提升也是有效的。
表4 引入OHEM前后的对比
Tab.4 The comparison before and after the introduction of OHEM

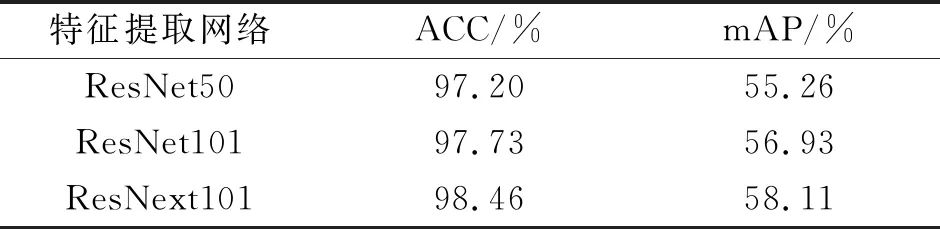
除ResNet50外,本文还选用了不同的特征提取网络进行对比实验,如表5所示,改进后的算法分别采用了ResNet50,ResNet101,ResNext101骨干网络进行对比,结果表明本文算法对这几种骨干网络都适用,在相同算法下,ResNext101的性能优于ResNet101和ResNet50,准确率和平均精确度均值分别达到了98.46%和58.11%,相比原来的ResNet50分别提升了1.26%和2.74%,平均精确度均值相比准确率有着更为明显的提升。
表5 算法在不同特征提取网络上的对比
Tab.5 The comparison of algorithms on different feature extraction networks
结论
针对布匹疵点具有极端的宽高比,而且小目标较多的问题,提出了基于Cascade R-CNN的布匹检测算法,根据布匹疵点的形状特点,用可变形卷积v2替代传统的卷积方式进行特征提取,并使用在线难例挖掘采样的方法提升对小目标疵点的检测效果,用CIoU Loss提升边界框的精度。结果表明,本文提出的方法比原始模型拥有更高的准确率和平均精确度均值,疵点检出能力更强,精度更高。此外,由于实验环境算力的限制,本文未采用更多的扩增数据,也并没有进行模型融合去提升最终的模型评价指标。实验过程中发现,边界框宽高比,NMS阈值,IoU阈值等一些超参数的设置,对模型的性能有极大的影响。例如小目标尺度小,边界框的交并比更低,在相同阈值下难以得到足够的正样本[23],因此,如何更深的理解布匹疵点数据特性,选择最适合布匹疵点特性的超参数列表,以此来提高目标检测的性能,将是未来的一个研究方向。
审核编辑:郭婷
-
检测器
+关注
关注
1文章
864浏览量
47698 -
数据集
+关注
关注
4文章
1208浏览量
24712
原文标题:基于改进级联R-CNN的面料疵点检测方法
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于深度学习的目标检测算法解析
PowerPC小目标检测算法怎么实现?
基于YOLOX目标检测算法的改进

介绍目标检测工具Faster R-CNN,包括它的构造及实现原理

什么是Mask R-CNN?Mask R-CNN的工作原理
手把手教你操作Faster R-CNN和Mask R-CNN
一种新的带有不确定性的边界框回归损失,可用于学习更准确的目标定位

基于改进Faster R-CNN的目标检测方法
常见经典目标检测算法:R-CNN、SPP-Ne
PyTorch教程-14.8。基于区域的 CNN (R-CNN)

无Anchor的目标检测算法边框回归策略






 工商网监
工商网监
评论