 英伟达地位不保?BERT训练吞吐量提升4.7倍
英伟达地位不保?BERT训练吞吐量提升4.7倍
电子发烧友网报道(文/周凯扬)推理和训练作为AI/ML关键的一环,无论是通用的GPU,还是专用的推理/训练加速器,都想在各大流行模型和机器学习库上跑出优秀的成绩,以展示自己的硬件实力。业界需要一个统一的跑分标准,为此,各大厂商在2018年根据业内指标联合打造的MLPerf就承担了这一重任。
不过随着时间的推移,MLPerf几乎已经成了英伟达一家独大的跑分基准,这家GPU厂商凭借自己的产品几乎统治着整个AI硬件市场。这不,近日公布的MLPerf Training 2.0,就将这些AI硬件公司和服务器厂商提交的具体AI训练成绩公布了出来,其中既有一些新晋成员,也有一些出人意料的结果。
谷歌的反超这次跑分结果中,最惊艳的还是谷歌的TPU v4系统,谷歌凭借这一架构的系统,在五个基准测试中都打破了性能记录,平均训练速度比第二名的英伟达A100系统快了1.42倍左右,哪怕是与自己在1.0测试下的成绩相比,也提升了1.5倍。
能实现这样的成绩自然离不开谷歌自己的TPU芯片设计,谷歌的每个TPU v4 Pod都由4096个芯片组成,且带宽做到了6Tbps。除此之外,谷歌有着丰富的用例经验,相较其他公司而言,谷歌是唯一一个在搜索和视频领域都已经大规模普及AI/ML应用的。
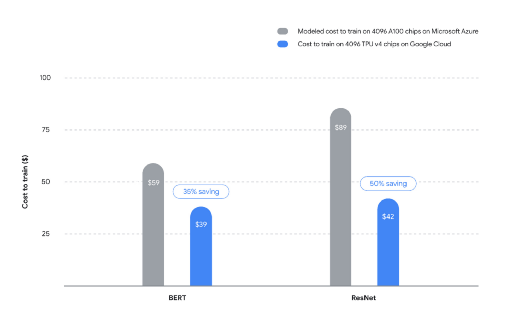
TPU v4与A100的对比 / 谷歌
不过谷歌与英伟达并不是直接竞争关系,他们对标的还是使用英伟达GPU系统的云服务公司,比如微软的Azure,谷歌也为此特地做了成本对比。如上图所示,在BERT模型的训练中,4096个TPU v4芯片与Azure 4096个A100芯片对比,谷歌的方案可以节省35%,ResNet模型的训练下更是可以节省近50%。
不过以上的成绩在所有8项测试中也只是和英伟达平分秋色,而且随着系统规模的不同,其结果或许会有更多的变化。再者,谷歌的TPU仅限于其自己的云服务,所以总的来说并不算一个通用方案,至少微软和亚马逊这样的竞争对手肯定是用不上。
英伟达地位不保?除了谷歌之外,还取得了不错的成绩的就是英特尔旗下Habana Labs的Gaudi2训练加速器。这款今年5月推出的处理器,从上一代的16nm换成了台积电7nm,Tensor处理器内核的数量因此增加了两倍,使其在ResNet-50的训练吞吐量上实现了3倍提升,BERT的训练吞吐量提升了4.7倍。
在与英伟达提交的A100-80GB GPU系统成绩相比,Gaudi2在ResNet-50上的训练时间缩短了36%;与戴尔提交的A100-40GB GPU系统成绩相比,Gaudi2在BERT上的训练时间缩短了45%。
从结果来看,已经有不少厂商的AI硬件已经可以在训练上对标甚至超过英伟达的GPU生态了,但这并不代表全部机器学习训练领域。比如在测试中,厂商是不需要将每个项目的测试结果都提交上去的。从这个角度来看,RetinaNet轻量型目标检测、COCO重型目标检测、语音识别数据集Librispeech和强化学习Minigo这几个项目中,只有基于英伟达GPU的系统提交了成绩。
不仅如此,如果你看所有提交成绩的服务器和云服务公司来看,他们用到的CPU或是AMD的EPYC处理器,或是英特尔的Xeon处理器,但加速器却是几乎清一色的英伟达A100。这也证明了在百度、戴尔、H3C、浪潮和联想这些厂商的眼中,英伟达的GPU依然是最具竞争力的那个。
不可小觑的软件还有一点需要指出,那就是以上都是封闭组的成绩,他们所用到的都是标准的机器学习库,比如TensorFlow 2.8.0和Pytorch 22.04等。而开放组则不受此限制,可以用到他们自己定制的库或优化器,这一组中三星和Graphcore都根据不同的软件配置提交了成绩,但最亮眼的还是MosaicML。
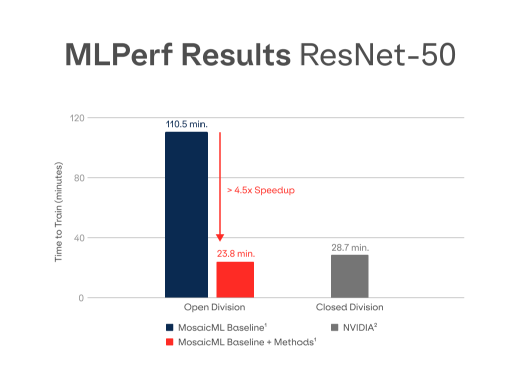
Composer在ResNet-50下的训练时间对比 / MosaicML
这家公司所用的加速器硬件同样是和诸多提交者一样的英伟达A100-SXM-80GB GPU,但他们用到的是自己用Pytorch编写的库Composer。这家公司于今年4月推出了Composer,并声称可让模型训练速度提升2到4倍。在MLPerf Training 2.0的跑分中,使用MosaicML Composer的对比组在ResNet训练速度上实现了近4.6倍的提升。不过Composer虽说支持任何模型,但这个提速的表现目前还是体现在ResNet上比较明显,所以本次也并没有提交其他模型下的成绩。
考虑到英特尔等公司为了提升其软件开发实力,已经在收购Codeplay这样的软件开发公司,MosaicML作为刚公开不久的初创公司,创始人又是英特尔的前AI实验室骨干,如果能在未来展现出更优秀的成绩,说不定也会被英伟达这样的公司看中。
结语英伟达常年在MLPerf上霸榜,也有不少人认为MLPerf跑分成了英伟达的宣传工具,然而事实是英特尔、谷歌等同样重视AI的公司也将其视为一个公平的基准测试,而且MLPerf还有同行评审环节,进一步验证测试结果。从以上结果来看,AI训练硬件上的创新仍未停止,无论是GPU、TPU还是IPU都在推陈出新,但跑分结果并不代表任何用例都能达到高性能,还需要厂商自己去调校模型和软件才能达成最好的成绩。
原文标题:AI硬件反超英伟达?跑分来看尚不现实
文章出处:【微信公众号:电子发烧友网】欢迎添加关注!文章转载请注明出处。
-
谷歌
+关注
关注
27文章
6168浏览量
105391 -
机器学习
+关注
关注
66文章
8418浏览量
132643 -
TPU
+关注
关注
0文章
141浏览量
20730 -
英伟达
+关注
关注
22文章
3776浏览量
91110
原文标题:AI硬件反超英伟达?跑分来看尚不现实
文章出处:【微信号:elecfans,微信公众号:电子发烧友网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
数据吞吐量提升!面向下一代音频设备,蓝牙HDT、星闪、Wi-Fi、UWB同台竞技
英伟达推出归一化Transformer,革命性提升LLM训练速度
TMS320C6472/TMS320TCI6486的吞吐量应用程序报告






 工商网监
工商网监
评论