 通过Token实现多视角文档向量表征的构建
通过Token实现多视角文档向量表征的构建
写在前面
今天给大家带来一篇ACL2022论文MVR,「面向开放域检索的多视角文档表征」,主要解决同一个文档向量与多个语义差异较大问题向量语义不匹配的问题。通过「插入多个特殊Token」实现多视角文档向量表征的构建,并为了防止多种视角间向量的趋同,引入了「退火温度」的全局-局部损失,论文全称《Multi-View Document Representation Learning for Open-Domain Dense Retrieval》。
该篇论文与前两天分享的DCSR-面向开放域段落检索的句子感知的对比学习一文有异曲同工之妙,都是在检索排序不引入额外计算量的同时,通过插入特殊Token构建长文档的多语义向量表征,使得同一文档可以与多种不同问题的向量表征相似。

并且目前的检索召回模型均存在一些缺陷:
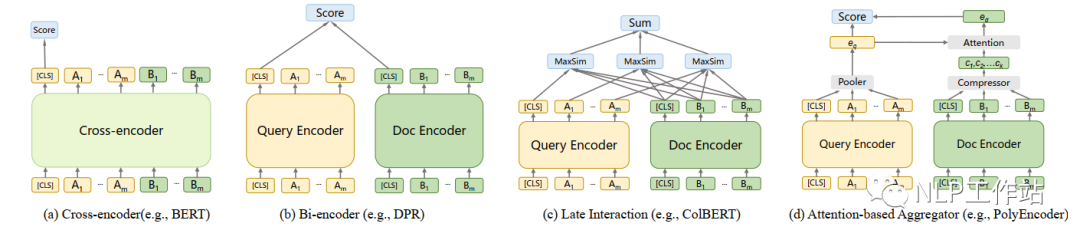
Cross-encoder类模型(BERT)由于计算量太大,无法在召回阶段使用;
Bi-encoder类模型(DPR)无法很好地表现长文档中的多主题要素;
Late Interaction类模型(ColBERT)由于使用sum操作,无法直接使用ANN进行排序;
Attention-based Aggregator类模型(PolyEncoder)增加了额外运算并且无法直接使用ANN进行排序。
模型
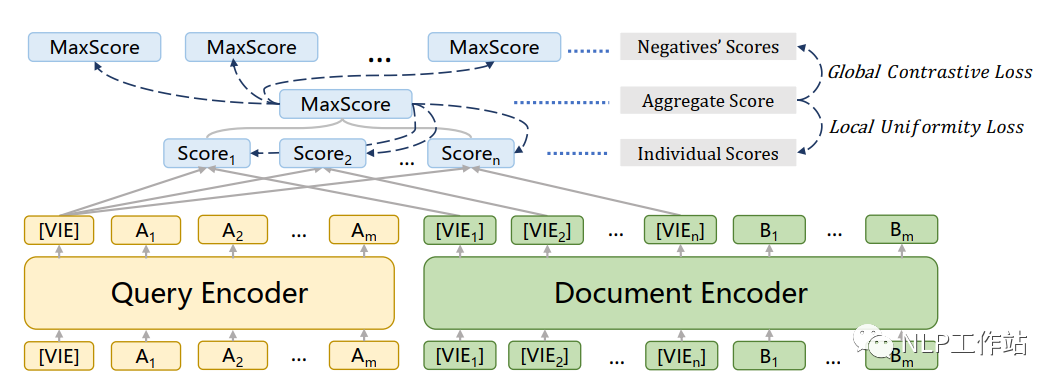
通常向量表征时,采用特殊字符[CLS]对应的向量表征作为文本的向量表征。为了获取文档中更细粒度的语义信息,MVR引入多个特殊字符[VIE]替代[CLS]。
对于文档来说,在文本前插入多个字符[],为了防止干扰原始文本的位置信息,我们将[]的所有位置信息设置为0,文档语句位置信息从1开始。
对于问题来说,由于问题较短且通常表示同一含义,因此仅使用一个特殊字符[VIE]。
模型采用双编码器作为骨干,分别对问题和文档进行编码,如下:
其中,表示链接符,[VIE]和[SEP]为BERT模型的特殊字符,和分别为问题编码器和文档编码器。
如上图所示,首先计算问题向量与每个视角的文档向量进行点积,获取每一个视角的得分,然后通过max-pooler操作,获取视角中分值最大的作为问题向量与文档向量的得分,如下:
为了防止多种视角间向量的趋同,引入了带有退火温度的Global-Local Loss,包括全局对比损失和局部均匀损失,如下:
其中,全局对比损失为传统的对比损失函数,给定一个问题、一个正例文档以及多个负例文档,损失函数如下:
为了提高多视角向量的均匀性,提出局部均匀性损失,强制将选择的查询向量与视角向量更紧密,原理其他其视角向量,如下:
为了进一步区分不同视角向量间的差异,采用了退火温度,逐步调整不同视角向量的softmax分布,如下:
其中,为控制退火速度的超参,为模型训练轮数,每训练一轮,温度更新一次。注意:在全局对比损失和局部均匀损失中,均使用了退火温度。
实验
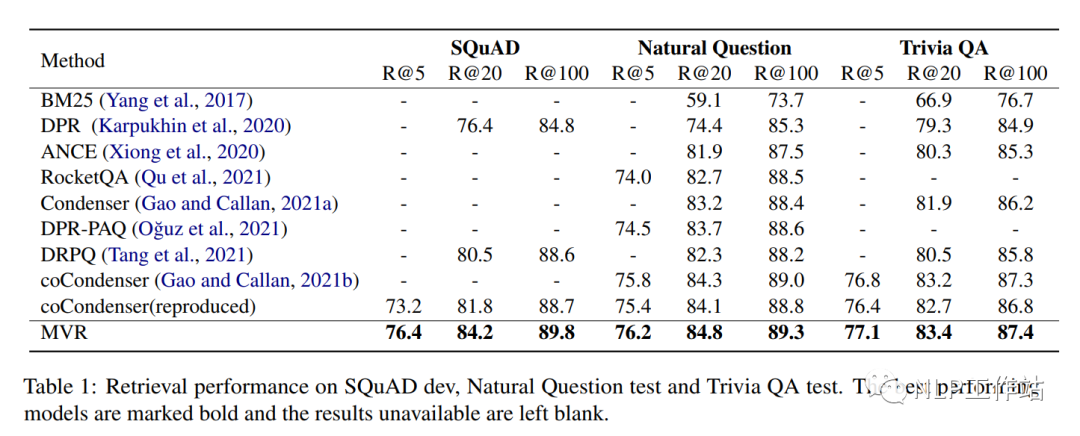
如下表所示,MVR方法对比于其他模型,获取了更好的效果。
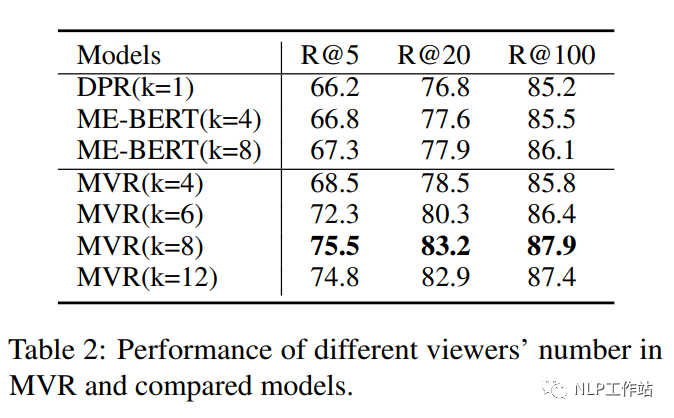
并且,通过实验发现,当视角个数选择8时,MVR模型效果最佳。
针对Global-Local Loss进行消融实验,发现当没有局部均匀损失和退火温度时,会使得效果下降;当两者都没有时,效果下降更加明显;并且一个合适退火速度,对训练较为重要。
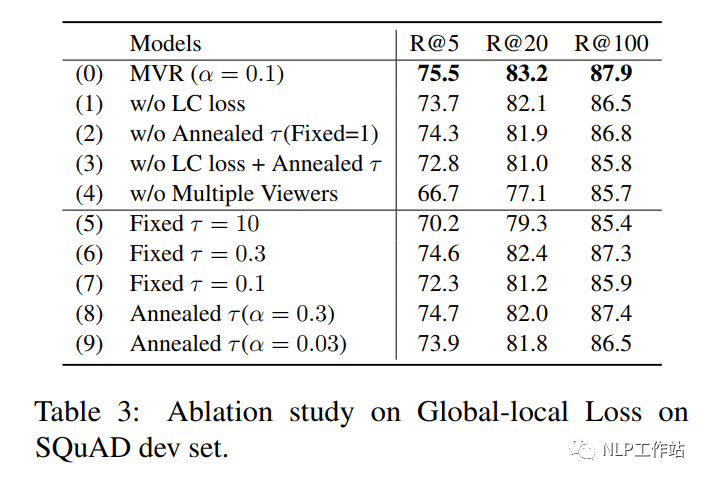
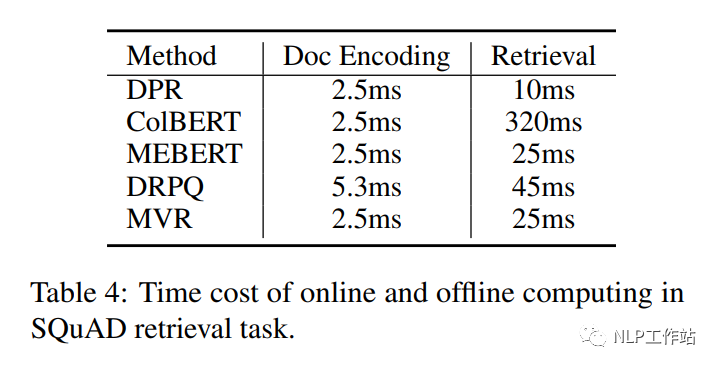
相比于其他模型来说,在文档编码阶段和检索召回阶段的速度基本没有影响,但由于需要存储多个视角向量,因此造成存储空间变大。
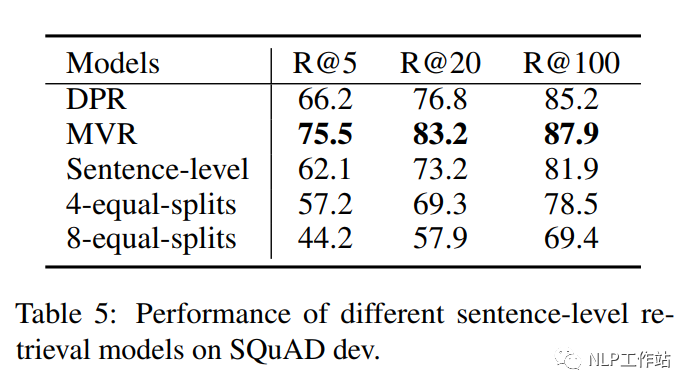
并且,对比了简单的句子切割或者等片段截断方法获取一个文本的多个向量表征,发现其效果均不理想,与DCSR一文观点一致。
总结
该论文为了对长文档更好地进行向量表征,引入多个特殊字符,使其生成「多种不同视角的向量表征」,解决了同一个文档向量与多个语义差异较大问题向量语义不匹配的问题。
审核编辑:郭婷
-
编码器
+关注
关注
45文章
3645浏览量
134564
原文标题:ACL2022 | MVR:面向开放域检索的多视角文档表征
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
通过工业智能网关实现中间变量表达式的快速配置
热量表接入能源监测平台实现远程监控节能管理
通过工业智能网关实现CJ188水表数据采集
请问STM8L052R8的USART2中断向量在哪?
先楫6880如何实现bootload + APP应用跳转
STM32F103CB将中断向量表放到RAM后就不正常了,为什么?
请问中断向量重复定义怎么处理?
stm32cubeide更改ld文件中的Flash偏移和中断向量表的宏VECT_TAB_OFFSET后,编译出来的bin文件与之前不同为什么?
鸿蒙开发【编译构建】讲解
利用知识图谱与Llama-Index技术构建大模型驱动的RAG系统(上)
什么是中断向量偏移,为什么要做中断向量偏移?





 工商网监
工商网监
评论