 逻辑推理MRC的两个数据集和对应方法
逻辑推理MRC的两个数据集和对应方法
1.背景
机器阅读理解(Machine Reading Comprehension, MRC)作为自然语言处理领域中的一个基本任务,要求模型就给定的一段文本和与文本相关的问题进行作答。正如同我们使用阅读理解测验来评估人类对于一段文本的理解程度一样,阅读理解同样可以用来评估一个计算机系统对于人类语言的理解程度。近年来,随着预训练语言模型在NLP领域的成功,许多预训练语言模型在流行的MRC数据集上的表现达到甚至超过了人类,例如:BERT、RoBERTa、XLNet、GPT3等。因此,为了促进更深层次的语言理解,许多更加具有挑战的MRC数据集被提出,它们从不同的角度考察模型能力,例如:多文档证据整合能力[1]、离散数值推理能力[2]、常识推理能力[3]等。
逻辑推理(Logical Reasoning)指对于日常语言中的论点进行检查、分析和批判性评价的能力,其是人类智能的关键组成部分,在谈判、辩论、写作等场景中发挥着重要作用。然而,流行的MRC数据集中没有或仅有很少的数据考察逻辑推理能力,例如,根据Sugawara和Aizawa[4]的研究,MCTest数据集中0%的数据和SQuAD中1.2%的数据需要逻辑推理能力作答。因此,ReClor[5]和LogiQA[6]这两个侧重考察逻辑推理能力的MRC数据集被提出。与逻辑推理MRC任务相关的一个任务是自然语言推理(Natural Language Inference, NLI),其要求模型对给定句对的逻辑关系分类,NLI任务仅仅考虑了句子级别的三种简单的逻辑关系(蕴含、矛盾、无关),而逻辑推理MRC需要综合篇章级别的多种复杂逻辑关系预测答案,因此更加具有挑战性。
本文介绍了目前逻辑推理MRC的两个数据集和对应方法。
2.数据集简介
2.1 LogiQA
LogiQA[5]是一个四选一的单项选择问答数据集,针对输入的问题、篇章和四个选项,模型需要根据问题和篇章找出唯一正确的选项作为答案。LogiQA的数据来自于中国的国家公务员考试题目,其旨在考察公务员候选人的批判性思维和解决问题的能力。原始数据经过筛选、过滤后得到8678条数据,这些数据被五名专业的英文使用者由中文翻译到英文,数据集的中文版本Chinese LogiQA也被同时发布。LogiQA的例子如图1所示,这些数据按照81的比例随机划分为训练集、开发集和测试集。
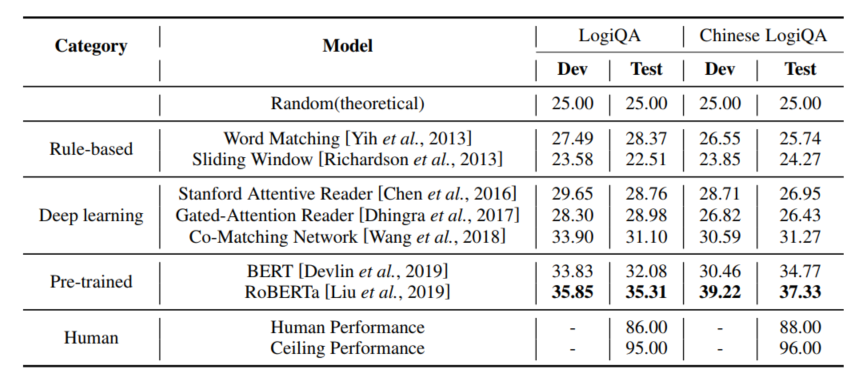
作者评估了基于规则的方法、深度学习方法以及基于预训练语言模型的方法在LogiQA上的表现,实验结果如表1所示,可以看到人类(研究生)在LogiQA上可以取得86%的平均准确率,这说明该数据集的难度对于人类受试者来说并不高,而另一方面,被测试的所有方法的表现均显著低于人类,即便是表现最好的RoBERTa模型也仅能取得35.31%的准确率,这说明目前的预训练语言模型的逻辑推理能力还相当弱。

图1 LogiQA中的例子(正确选项使用红色标出)
表1 各类方法在LogiQA上的实验结果(accuracy%)
2.2 ReClor
ReClor[6]与LogiQA一样,是一个四选一的单项选择问答数据集,其来自于美国的两个标准化研究生入学考试:研究生管理科入学考试(GMAT)和法学院入学考试(LSAT),经过筛选、过滤得到6138条考察逻辑推理能力的数据,这些数据被随机划分为4638,500,1000条来分别用作训练集、开发集和测试集。ReClor数据集的一个具体例子如图2所示,可以看到只有基于篇章、问题和选项进行逻辑推理和分析才能得到正确的答案。
正如上面介绍的那样,ReClor来自侧重考察逻辑推理的考试,由人类的专家构建,这意味着biases有可能被引入,这导致模型可能无需真正理解文本,仅仅利用这些biases就可以在任务上取得很好的表现。而将这些biased数据与unbiased数据区分开可以更加全面的评价模型在ReClor上的表现。为此,作者去除掉问题和篇章,仅仅将选项作为预训练语言模型的输入,如果模型仅仅依赖选项就可以成功预测出正确选项,那么这样的biased数据就被归为EASY-SET,其余数据被归为HARD-SET,这样,ReClor的测试集被分为了EASY-SET和HARD-SET两部分。
作者在ReClor的EASY-SET和HARD-SET上分别评估了预训练语言模型和人类的表现,实验结果如图3所示,实验结果显示:预训练语言模型在EASY-SET上可以取得很好的表现,但是在HARD-SET上表现很差,而人类则在两个集合上取得了相当的表现,这说明目前的模型虽然擅长利用数据集中存在的biases,但是还远远做不到真正的逻辑推理。

图2 ReClor中的一个例子(修改自2019年的LSAT)
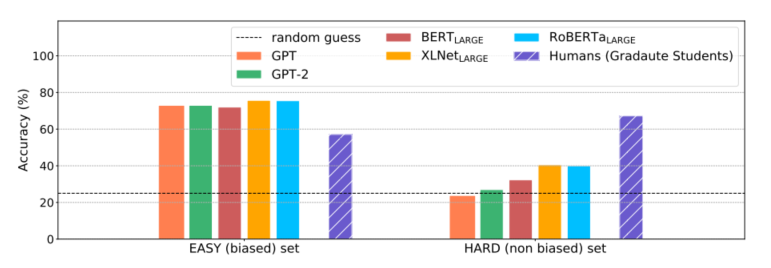
图3 预训练语言模型与人类(研究生)在ReClor测试集的EASY-SET和HARD-SET上的表现对比
3.方法
下面将介绍几篇近两年逻辑推理MRC的相关工作,目前的已有方法可以大致分为两类:一类方法是利用预定义的规则基于篇章、选项构建图结构,图中节点对应文本中的逻辑单元(这里的逻辑单元指有意义的句子、从句或文本片段),而图中的边则表示逻辑单元间的关系,然后利用GNN、Graph Transformer等方法建模逻辑推理过程,从而增强模型的逻辑推理能力。另一类则是从预训练角度出发,基于一些启发式规则捕捉大规模文本语料中存在的逻辑关系,针对其设计相应的预训练任务,对已有的预训练语言模型进行二次预训练,从而增强预训练语言模型的逻辑推理能力。
3.1 基于图的精调方法
3.1.1 DAGN
针对逻辑推理MRC篇章中复杂的逻辑关系,仅仅关注句子级别tokens之间的交互是不够的,需要在篇章级别对句子之间的关系进行建模。但是逻辑结构隐式存在与文本中,难以直接抽取,大多数数据集也并不包含对文本中逻辑结构的标注。因此,DAGN提出使用语篇关系(discourse relation)来表示文本中的逻辑信息,语篇关系分为显式和隐式两类,显式语篇关系指文本中的语篇状语(如“instead”)、从属连词(如“because”),而隐式语篇关系则指连接文本片段的标点符号(句号、逗号、分号等)。语篇关系一定程度上对应着文本中的逻辑关系,例如:“because”指示因果关系,“if”指示假设关系等。
DAGN[7]使用来自PDTB2.0[8]中的语篇关系中作为分隔符,将文本划分为多个基本语篇单元(Elementary Discourse Units, EDUs),以EDUs作为节点、EDUs间的语篇关系作为边就得到了语篇图结构,语篇图的构建过程实例如图4的左半部分所示。然后,作者利用图网络来从语篇图中学习篇章的语篇特征,该特征与由预训练语言模型得到的上下文表示合并,共同预测问题的答案。
DAGN使用EDUs作为基本的推理单元,利用学习得到的基于语篇的特征增强预训练语言模型上下文表示,在ReClor和LogiQA两个数据集上取得了有竞争力的表现。
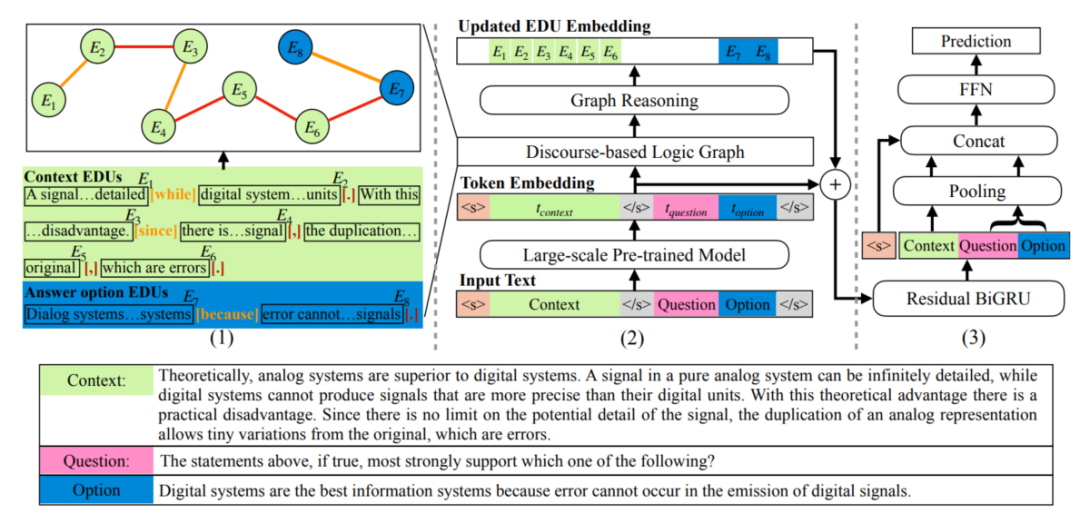
图4 DAGN结构
3.1.2 AdaLoGN
传统的神经模型无法很好地建模逻辑推理,而能够进行逻辑推理的符号推理器却无法直接应用于文本。同时,前面介绍的DAGN模型虽然基于语篇关系构建了语篇图结构,但是语篇关系能否充分表示基于逻辑关系的符号推理仍然有待商榷,且该图结构十分稀疏,由长路径组成,这限制了GNN模型中节点与节点间的消息传递,导致篇章和选项间的交互不够充分。
为了解决上述挑战,AdaLoGN[9]这一神经-符号方法被提出,其整体框架与DAGN类似,由图构建和基于图的推理两部分组成,区别在于采用有向的文本逻辑图(Text Logic Graph,TLG)代替DAGN中的语篇图,TLG仍然将EDUs作为节点,边则采用了六种预定义的逻辑关系,其中合取(conj)、析取(disj)、蕴含(impl)、否定(neg)是命题逻辑中的标准逻辑连接词,而rev表示反向的蕴含关系,unk表示未知的关系。作者首先使用Graphene[10]这一信息抽取工具抽取EDUs之间的修辞关系,然后将部分修辞关系映射为逻辑关系,具体映射如表2所示。
表2 Graphene中修辞关系到TLG中逻辑关系的映射

使用TLG相比起语篇图的优势在于可以使用符号化的推理规则对原始语篇图进行扩展,基于已知推理得到未知的逻辑关系,AdaLoGN中作者使用的推理规则如图5所示,包括命题逻辑中的假言三段论、置换规则以及作者自定义的一条规则。上述符号化推理过程得到的新关系可能对于后续GNN消息传递过程提供关键连接,帮助正确答案的预测,即符号推理增强了神经推理。而对基于推理规则得到的演绎闭包全盘接受也可能会引入不相关的连接,误导后续的消息传递过程,因此,作者提出使用神经推理计算得到的信号来自适应地接纳相关扩展,即神经推理增强了符号推理。
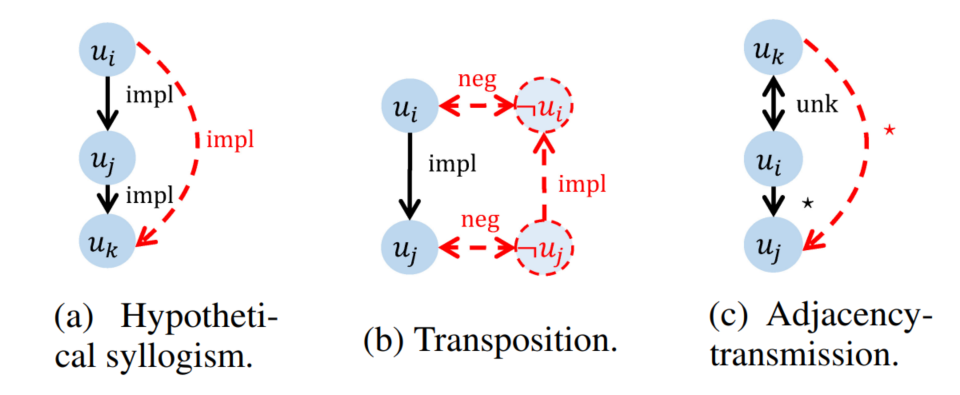
图5 AdaLoGN中使用的推理规则,推理得到的新的节点与关系用红色虚线表示
AdaLoGN的整体结构如图6所示,可以看到自适应地扩展TLG、消息传递过程通过迭代多轮来使得符号推理和神经推理彼此充分交互。最终每一轮得到的扩展TLG表示和由RoBERTa得到的上下文token特征共同用于答案预测。AdaLoGN在LogiQA和ReClor数据集上取得了比DAGN更好的表现。
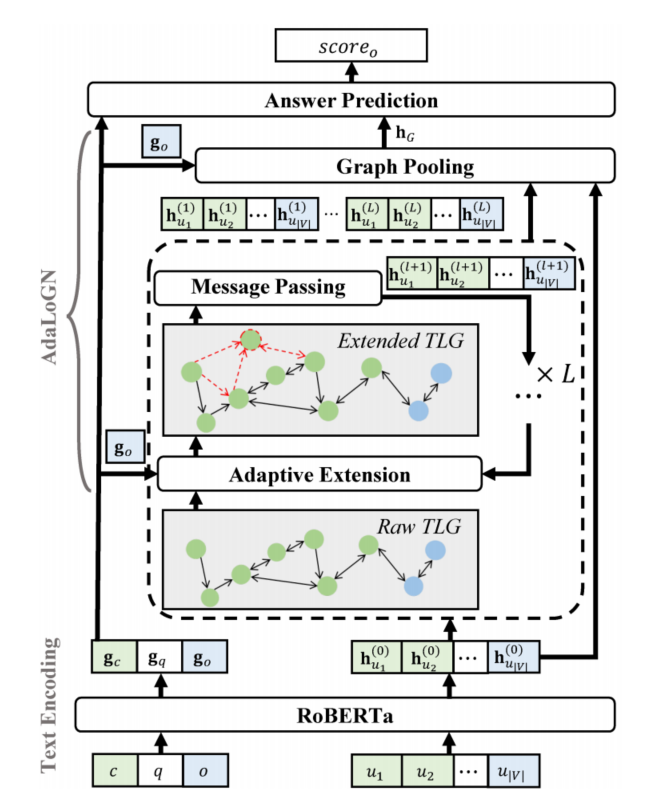
图6 AdaLoGN结构
3.1.3 Loigformer
Logiformer[11]的作者认为,对于逻辑推理MRC任务来说,除了需要从文本中抽取逻辑单元外,还需要对逻辑单元间的长距离依赖进行建模,如图7中展示的一个来自ReClor数据集的具体例子,从中可以看到因果关系与否定、共现关系普遍存在于逻辑推理任务中,针对这一点,作者提出基于篇章分别构建逻辑图和句法图,对上述的因果关系以及共现关系分别进行表示,然后使用一个两支的graph transformer网络来从两个角度建模长距离依赖。

图7 来自ReClor的具体例子及上下文中逻辑单元间的关系
Logiformer的结构如图8所示,与之前的方法类似其首先基于文本中表示因果关系的逻辑单词(如:if、unless、because等)以及标点符号构建逻辑图,并基于因果关系为条件节点到结果节点间插入边。句法图则以文本中的句子作为节点,然后基于句子之间的token级别的重叠度来判断句子之间的共现关系,为具有共现关系的节点插入边。接着,作者使用两个独立的graph transformer分别对逻辑图和句法图中的依赖关系进行建模,并通过将图对应的邻接矩阵引入attention计算过程从而将图的结构信息引入。逻辑图的graph transformer示意图如图9所示。最后使用得到的token级别表示、句法节点表示和逻辑节点表示共同预测答案。Logiformer在LogiQA和ReClor数据集上取得了目前单模型的SOTA表现。
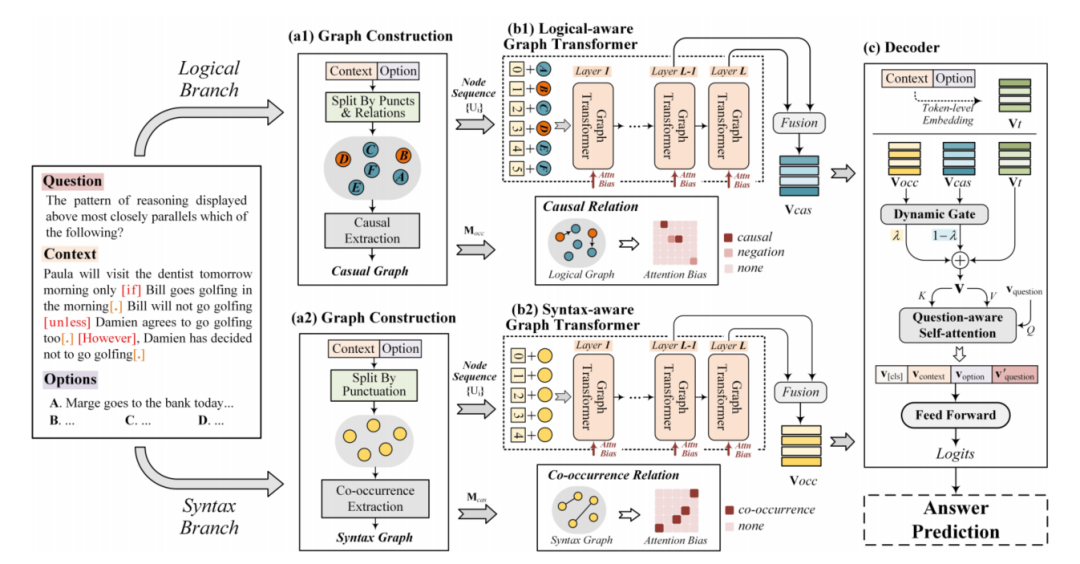
图8 Logiformer结构
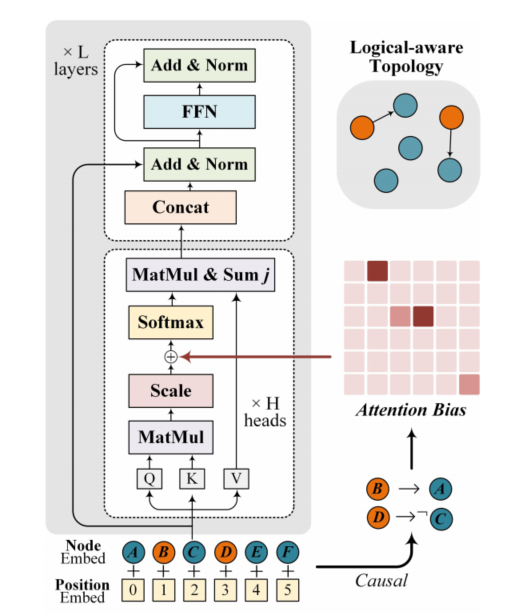
图9 逻辑图对应的graph transformer示意图(句法图对应的计算过程类似)
3.2 预训练方法
3.2.1 MERIt
3.1节中介绍的基于图的方法将关于逻辑关系的先验知识引入模型,依赖于标注好的训练数据,导致其在标注数据不足的情况下存在过拟合以及泛化性差的问题。MERIt[12]提出利用规则基于大量无标签的文本数据仿照逻辑推理MRC任务形式构造用于对比学习自监督预训练的数据,MERIt整体框架如图10所示,其主要基于这样一个直觉:文本中逻辑结构可以被由一系列关系三元组构成的推理路径表示,而实体之间的元路径(meta-path)先天地提供了表示逻辑一致性的手段。
MERIt的目标是基于大规模无标签文本,构建上下文和选项,正确选项应当与上下文逻辑一致,而错误选项与上下文逻辑相悖,模型借助对比学习作为预训练目标。MERIt首先识别文本中的实体,并基于实体在文本中的共现关系构建图,对于该图结构中直接相邻任意两个节点,如果它们之间具有其他元路径,则将该节点这两个节点之间的边对应的句子作为正确选项,将元路径上边对应的句子作为上下文,这样就得到了正例。负例的构建则是通过对已有正例进行修改完成的,为了防止模型在预训练过程中基于自身掌握的常识知识而非逻辑一致性做出判断,作者还采用了反事实的数据增强对文本中的实体进行替换,迫使模型基于逻辑进行预测。基于MERIt构造的数据二次预训练得到的模型在下游任务上取得了相较于原预训练模型更好的表现,且模型可以与3.1节中的方法同时使用来取得更优的结果。
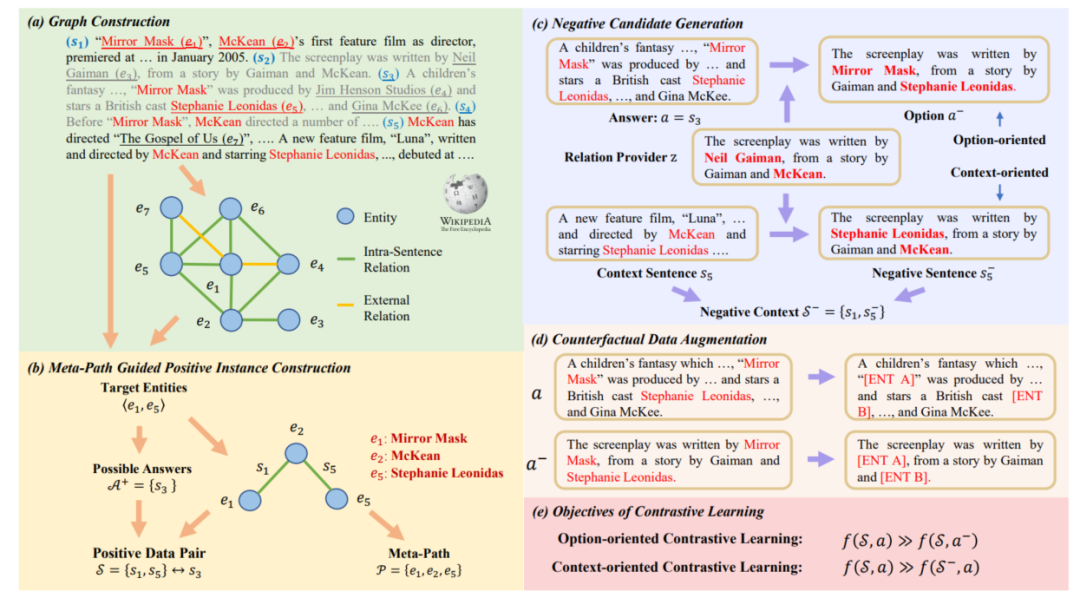
图10 MERIt框架
3.2.2 LogiGAN
LogiGAN[13]将视线转向了生成式模型(T5)以及包括逻辑推理MRC在内的多种需要推理能力任务上,旨在通过对MLM预训练任务进行改进来强化模型的逻辑推理能力,并引入验证器(verifier)来为生成式模型提供额外反馈,同时其通过简单的策略规避了序列GAN中beam search带来的不可导问题。
LogiGAN首先使用预先指定的逻辑指示器(例如:“therefore”、“due to”、“we may infer that”)来从大规模无标签文本中识别逻辑推理现象,然后对逻辑指示器后面的表达进行mask,训练生成式模型对被mask的表达(statement)进行恢复。例如对于“Bob made up his mind to lose weight. Therefore, he decides to go on a diet.”这段话中Therefore就是一个逻辑指示器,因此其后面的表达“he decides to go on a diet.”就会被mask然后交给模型预测。这种基于已知推出未知的训练目标相比起随机的MLM更能增强模型的逻辑推理能力。
LogiGAN的框架如图11所示,模型由生成器和验证器两部分组成,验证器执行一个文本分类任务:以上下文和表达作为输入,判断该表达来自于原文的真实表达还是构造得到伪表达,判别器本质上就是在判断上下文和表达的逻辑一致性。伪表达有两个来源:从生成器中通过beam search得到的生成概率较高的句子(self-sampling)和基于真实表达从语料库中检索得到的近似表达(retrieved)。生成器除了需要学习生成真实表达外,还要让自己生成伪表达的似然得分分布与判别器给出逻辑一致性得分分布尽可能一致。LogiGAN在包括LogiQA和ReClor在内的12个需要推理的下游任务上相较于vanilla T5都取得了明显的提升。
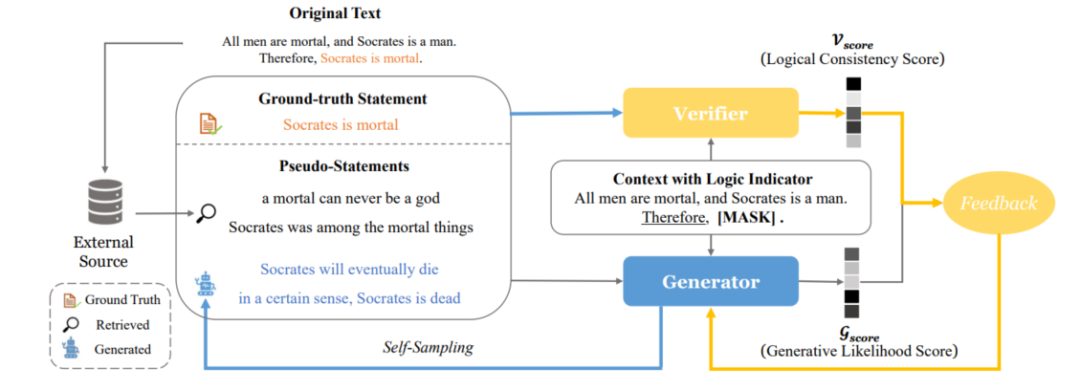
图11 LogiGAN框架
4.总结
目前针对逻辑推理MRC任务主要从精调和预训练两个角度出发,精调阶段的方法主要围绕图的构建与使用展开,如何将文本划分为逻辑单元,指定逻辑单元之间的逻辑关系,引入符号化的推理规则是这类工作的重点。而预训练阶段的方法则侧重于如何发掘大规模无标签文本中蕴含的逻辑推理现象,设计合理的预训练任务。已有方法在两个逻辑推理MRC数据集上的表现距离人类仍有较大差距,期待未来能有更大规模的新数据集和更有效的新方法被提出。
审核编辑:郭婷
-
数据集
+关注
关注
4文章
1205浏览量
24648 -
深度学习
+关注
关注
73文章
5493浏览量
120987
原文标题:逻辑推理阅读理解任务及方法
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
逻辑异或和逻辑或的比较分析
CISC(复杂指令集)与RISC(精简指令集)的区别
两个PLC之间如何交互信号
【大语言模型:原理与工程实践】大语言模型的评测

传感器之外—两个数据库之间的“连接”查询
arcgis中如何关联两个属性表
PSOC同时使用两个Em_EEPROM,有一个数据会丢失的原因?
二进制与逻辑电平的变化范围

百川智能发布角色大模型,零代码复刻角色





 工商网监
工商网监
评论