 AI/ML应用和处理器的架构探索
AI/ML应用和处理器的架构探索
行业背景
人工智能 (AI) 应用程序考虑了计算、存储、内存、管道、通信接口、软件和控制。此外,人工智能应用程序处理可以分布在处理器内的多核、PCIe 主干上的多个处理器板、分布在以太网网络中的计算机、高性能计算机或跨数据中心的系统中。此外,人工智能处理器还具有巨大的内存大小要求、访问时间限制、模拟和数字分布以及硬件-软件分区。
问题
人工智能应用的架构探索很复杂,涉及多项研究。首先,我们可以针对单个问题,例如内存访问,或者可以查看完整的处理器或系统。大多数设计都是从内存访问开始的。有很多选择——SRAM 与 DRAM、本地与分布式存储、内存计算以及缓存反向传播系数与丢弃。
第二个评估部门是总线或网络拓扑。虚拟原型可以具有用于处理器内部的片上网络、TileLink 或 AMBA AXI 总线、用于连接多处理器板和机箱的 PCIe 或以太网,以及用于访问数据中心的 Wifi/5G/Internet 路由器。
使用虚拟原型的第三项研究是计算。这可以建模为处理器内核、多处理器、加速器、FPGA、Multi-Accumulate 和模拟处理。最后一部分是传感器、网络、数学运算、DMA、自定义逻辑、仲裁器、调度器和控制功能的接口。
此外,人工智能处理器和系统的架构探索具有挑战性,因为它将数据密集型任务图应用于硬件的全部功能。
模型构建
在 Mirabilis,我们使用 VisualSim 对 AI 应用程序进行架构探索。VisualSim 的用户在具有大量 AI 硬件和软件建模组件的图形离散事件仿真平台中非常快速地组装虚拟原型。该原型可用于进行时间、吞吐量、功耗和服务质量的权衡。提供超过 20 种 AI 处理器和嵌入式系统模板,以加速开发新的 AI 应用程序。
为 AI 系统的权衡而生成的报告包括响应时间、吞吐量、缓冲区占用率、平均功率、能耗和资源效率。
ADAS模型构建
首先,让我们考虑自动驾驶 (ADAS) 应用程序,这是图 1 中的一种人工智能部署形式。ADAS 应用程序与计算机或电子控制单元 (ECU) 和网络上的许多应用程序共存。 ADAS 任务的正确运行还依赖于现有系统的传感器和执行器。
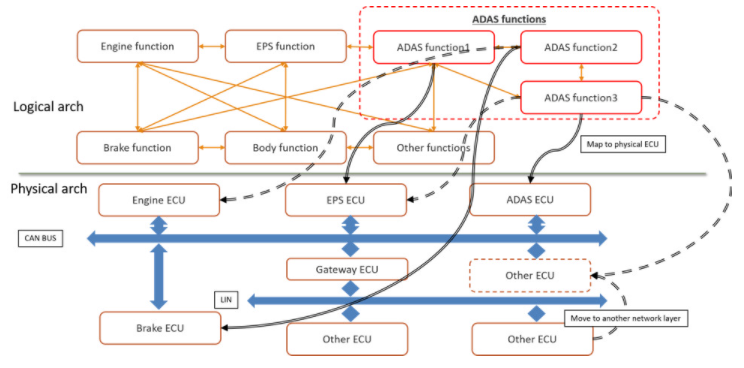
图 1. 汽车设计中 AI 应用程序的逻辑到物理架构
早期的架构权衡可以测试和评估假设以快速识别瓶颈,并优化规范以满足时序、吞吐量、功率和功能要求。在图 1 中,您将看到体系结构模型需要硬件、网络、应用程序任务、传感器、衰减器和流量激励来获得对整个系统操作的可见性。图 2 显示了映射到物理架构的 ADAS 逻辑架构的实现。
架构模型的一个很好的特性是能够分离设计的所有部分,这样就可以研究单个操作的性能。在图 2 中,您会注意到现有任务被单独列出,网络与 ECU、传感器生成和 ADAS 逻辑任务组织。ADAS 任务图中的每个功能都映射到一个 ECU。
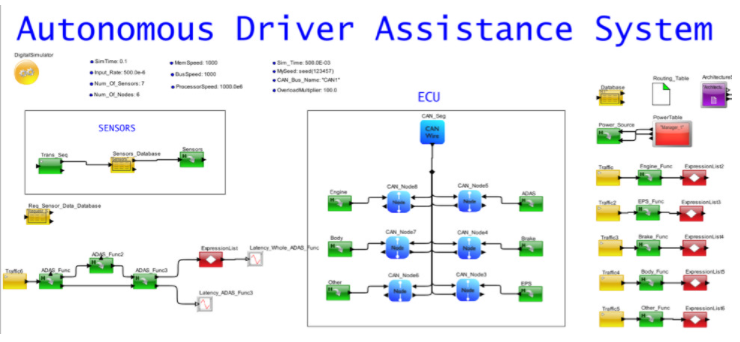
图 2. ADAS 映射到 ECU 网络的汽车系统系统模型
ADAS分析
当模拟图2中的ADAS模型时,可以得到各种报告。在图 3 中,显示了完成 ADAS 任务的延迟以及电池为此任务耗散的相关热量。其他感兴趣的图可以是测量的功率、网络吞吐量、电池消耗、CPU 利用率和缓冲区占用。
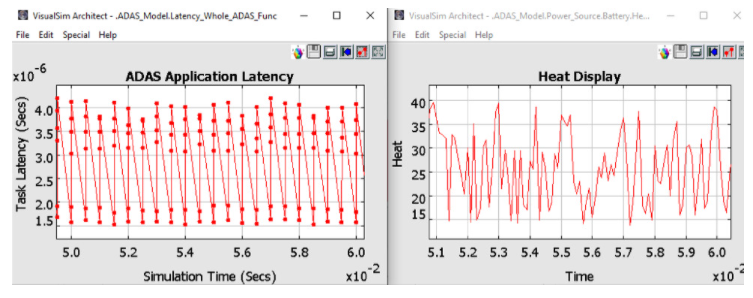
图 3. ADAS 架构模型的分析报告
处理器模型构建
AI 处理器和系统的设计人员针对应用程序类型、训练与推理、成本点、功耗和尺寸限制进行实验。例如,设计人员可以将子网络分配到流水线阶段,权衡深度神经网络 (DNN) 与传统机器学习算法,测量 GPU、TPU、AI 处理器、FPGA 和传统处理器上的算法性能,评估融合计算和内存的好处在芯片上计算类似于人脑功能的模拟技术对功率的影响,并构建具有针对单个应用程序的部分功能集的 SoC。
从 PowerPoint 到新 AI 处理器的第一个原型的时间非常短,第一个生产样品不能有任何瓶颈或错误。因此,建模成为强制性的。
图 4 显示了 Google 张量处理器的内部视图。框图已转换为图 5 中的架构模型。处理器通过 PCIe 接口接收来自主机的请求。MM、TG2、TG3 和 TG4 是来自独立主机的不同请求流。权重存储在片外 DDR3 中并被调用到权重 FIFO。到达的请求在统一本地缓冲区中存储和更新,并发送到矩阵多单元进行处理。当请求通过 AI 管道处理完毕后,将其返回到统一缓冲区以响应主机。
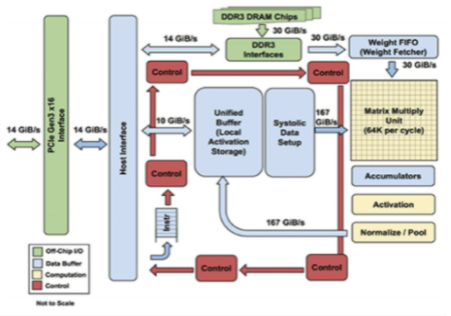
图 4. 来自 Google 的 TPU-1
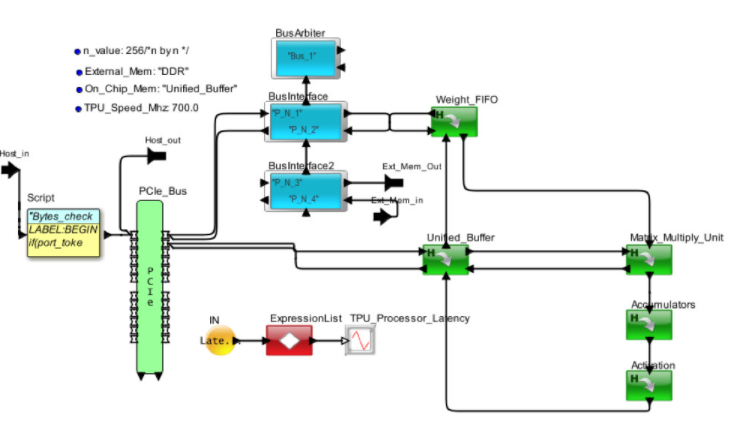
图5. AI 硬件架构的 VisualSim 模型顶视图
处理器模型分析
在图 6 中,您可以查看片外 DDR3 中的延迟和反向传播权重管理。延迟是从主机发送请求到接收响应的时间。您将看到 TG3 和 TG4 能够分别保持低延迟,直到 200 us 和 350 us。MM 和 TG2 在模拟的早期就开始缓冲。由于这组流量配置文件存在大量缓冲并且延迟增加,因此当前的 TPU 配置不足以处理负载和处理。TG3 和 TG4 的更高优先级有助于维持更长的运营时间。
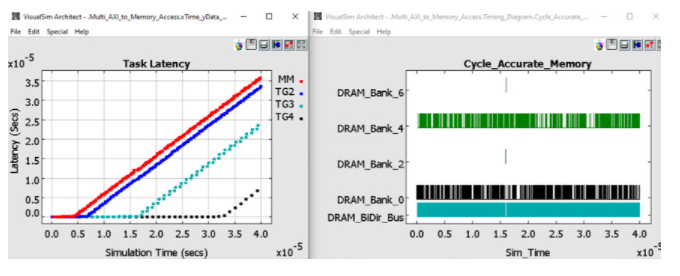
图 6. 架构探索权衡的统计数据
汽车设计施工
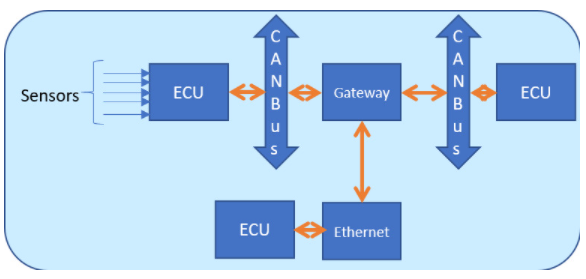
图 7. 带有 CAN 总线、传感器和 ECU 的汽车网络
当今的汽车设计包含许多需要大量机器学习和推理的安全和自动驾驶功能。可用的时间表将决定处理是在 ECU 完成还是发送到数据中心。例如,可以在本地进行制动决策,同时可以将空调温度的变化发送到远程处理。两者都需要一些基于输入传感器和摄像头的人工智能。
图 7 是包含 ECU、CAN-FD、以太网和网关的网络框图。
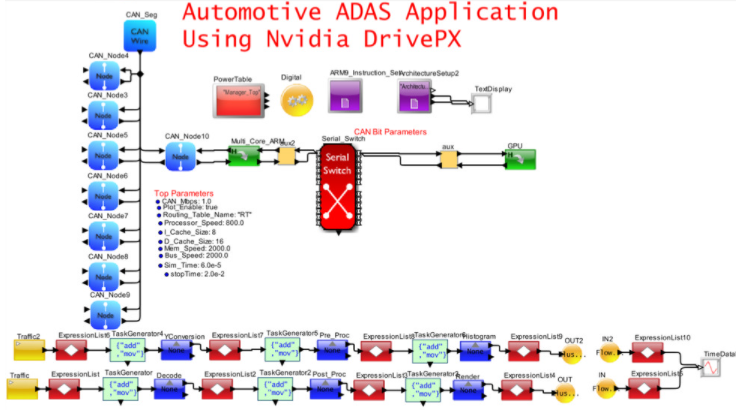
图 8. 自动驾驶和 E/E 架构的 VisualSim 模型
图 8 捕获了图 7 的一部分,它将 CAN-FD 网络与包含多个 ARM 内核和一个 GPU 的高性能 Nvidia DrivePX 集成。以太网/TSN/AVB 和网关已从模型中移除以简化视图。在此模型中,重点是了解 SoC 的内部行为。该应用程序是由车辆上的摄像头传感器触发的 MPEG 视频捕获、处理和渲染。
汽车设计分析
图 9 显示了 AMBA 总线和 DDR3 内存的统计数据。您可以看到跨多个主服务器的工作负载分布。可以评估应用程序管道的瓶颈,确定最高周期时间的任务、内存使用情况以及每个单独任务的延迟。
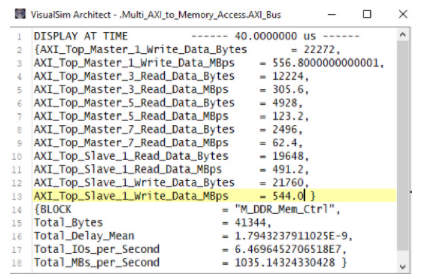
图 9. 总线和内存活动报告
用例和流量模式应用于作为硬件、RTOS 和网络组合的架构模型。周期性流量配置文件用于对雷达、激光雷达和摄像头进行建模,而用例可以是自动驾驶、聊天机器人、搜索、学习、推理、大数据处理、图像识别和疾病检测。用例和流量可以根据输入速率、数据大小、处理时间、优先级、依赖性、先决条件、反向传播循环、系数、任务图和内存访问而变化。通过改变属性在系统模型上模拟用例。这会生成各种统计数据和图表,包括缓存命中率、流水线利用率、拒绝的请求数、每条指令或任务的瓦特数、吞吐量、缓冲区占用率和状态图。
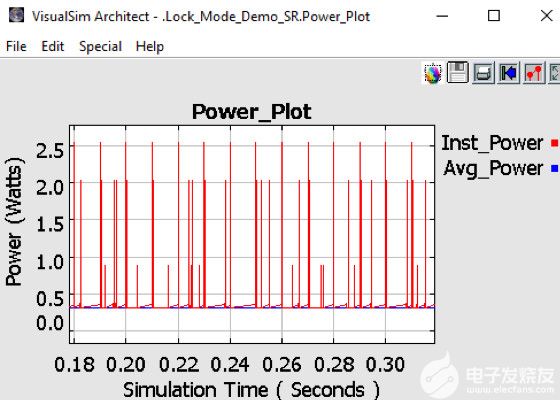
图 10. 实时测量 AI 处理器的功耗
图 10 显示了系统和芯片的功耗。除了散热、电池充电消耗率和电池生命周期变化外,该模型还可以捕捉动态功率变化。该模型绘制了每个设备的状态活动、相关的瞬时峰值和系统的平均功率。获得有关功耗的早期反馈有助于热和机械团队设计外壳和冷却方法。大多数机箱对每个板都有最大功率限制。这种早期的功耗信息可用于执行架构与性能的权衡,从而寻找降低功耗的方法。
进一步的探索场景
以下是一些突出使用 AI 架构模型和分析的附加示例。
1. 360度激光扫描仪、立体摄像头、鱼眼摄像头、毫米波雷达、声纳或激光雷达的自动驾驶系统,通过网关连接到多个IEEE802.1Q网络上的20个ECU。该原型用于测试 OEM 硬件配置的功能包,以确定硬件和网络要求。主动安全行动的响应时间是主要标准。
2. 用于学习和推理任务的人工智能处理器是使用由 32 个内核、32 个加速器、4 个 HBM2.0、8 个 DDR5、多个 DMA 和完整缓存一致性构建的片上网络骨干定义的。该模型使用 RISC-V、ARM Z1 和专有内核的变体进行了试验。实现的目标是链路上的 40Gbps,同时保持较低的路由器频率并重新训练网络路由。
3. 需要一个 32 层的深度神经网络,将内存从 40GB 降低到 7GB 以下。数据吞吐量和响应时间没有改变。该模型设置有用于处理和反向传播的内存访问行为的功能流程图。对于不同的数据大小和任务图,该模型确定了数据的丢弃量以及各种片外 DRAM 大小和 SSD 存储选项。任务图随任意数量的图和几个输入和输出而变化。
4. 使用ARM处理器和AXI总线进行低成本AI处理的通用SoC。目标是获得最低的每瓦功率,从而最大限度地提高内存带宽。乘法累加函数被卸载到向量指令,加密到 IP 核,以及自定义算法到加速器。构建该模型的明确目的是评估不同的高速缓存存储器层次结构以提高命中率和总线拓扑以减少延迟。
5. 模数 AI 处理器需要对功耗进行彻底分析,并对所达到的吞吐量进行准确分析。在该模型中,非线性控制在离散事件模拟器中建模为一系列线性函数,以加快模拟时间。在这种情况下,对功能进行了测试以检查行为并衡量真正的节能效果。
审核编辑:郭婷
-
存储器
+关注
关注
38文章
7428浏览量
163506 -
神经网络
+关注
关注
42文章
4733浏览量
100410 -
soc
+关注
关注
38文章
4092浏览量
217753
发布评论请先 登录
相关推荐
简述微处理器的指令集架构
AMD推出全新锐龙AI 300系列处理器
ARM处理器和CISC处理器的区别
微处理器的指令集架构介绍

联发科或将与英伟达开发Arm架构AI PC处理器
嵌入式微处理器架构可分为
Alif Semiconductor宣布推出先进的BLE和Matter无线微控制器,搭载适用于AI/ML工作负载的神经网络协同处理器

Achronix新推出一款用于AI/ML计算或者大模型的B200芯片

全新发布的AMD锐龙8000G系列台式机处理器,为个人AI处理赋能!
英特尔新处理器,掀AI PC战火
简单认识MIPS架构处理器
简单认识POWER系列架构处理器






 工商网监
工商网监
评论