 AI编译器的逐底竞争
AI编译器的逐底竞争
创造智能需要大量数据。所有这些数据都需要能够支持它的技术。
就人工智能 (AI) 而言,这些技术包括大量直接访问的高速内存;能够同时处理同一数据集的不同部分的并行计算架构;并且有点令人惊讶的是,与许多其他应用程序相比,计算精度更低。数据中心可以提供几乎无穷无尽的这种技术组合。
因此,人工智能开发工具是为互联网查询、语音搜索和在线面部识别等应用程序背后的数据中心基础设施而设计的。但随着人工智能技术的进步,在各种用例中利用它的愿望也在增加——包括那些在小型、资源受限、基于 MCU 的边缘平台上运行的用例。因此,例如,编译器等工具还必须能够针对占用空间更小的设备优化 AI 数据和算法,而不是仅仅关注运行基于云的推荐系统的高端硬件加速器。
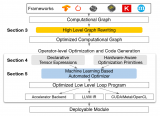
Facebook 的开源机器学习编译器 Glow 就是这种工具演变的一个例子。它使用两阶段中间表示 (IR) “降低”神经网络图,该中间表示生成针对各种嵌入式和服务器级硬件目标的特性和内存进行专门调整的机器代码(图 1)。它还执行提前 (AOT) 编译,最大限度地减少运行时开销,以节省磁盘空间、内存、启动时间等。
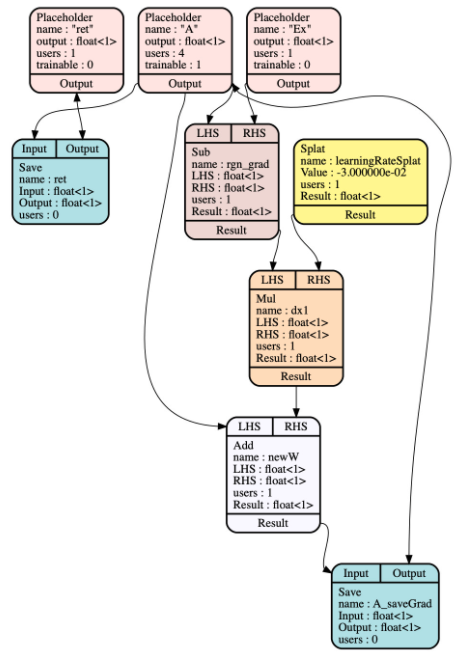
图 1. Glow 高级中间表示中的降低计算图表示 A 的回归,该回归由 Glow 自动区分。
“我们拥有这个非常高性能的运行时,但很多项目并不关心,因为它们不在数据中心内,”Facebook 的研究科学家 Jordan Fix 解释道。“他们需要做 AOT 编译,尽可能地缩小,使用量化和并行化,并且没有太多的依赖关系。
“AOT 编译在数据中心并不那么重要,但我们可以将 LLVM 后端连接到 Glow 并针对 x86、Arm、RISC-V 和专用架构,”Fix 继续说道。“Glow 的工作方式是你有几个级别的 IR,它们使用高级优化和量化来限制内存。那时,编译器后端可以接受基于指令的 IR,并根据需要对其进行优化和编译。”
Glow 的另一大优势,特别是在多样化的嵌入式技术领域,是能够在简单的 C 包装器中编译模型。这意味着嵌入式 AI 工程师可以针对他们选择的编译器后端和架构优化 Glow。它本机支持来自流行 AI 框架和库(如 PyTorch 和 Arm 的 CMSIS-NN)的输入,还可以通过 ONNX 神经网络交换接受来自 TensorFlow 等环境的图形。
AI 编译器的竞争
当然,Glow 并不是唯一可用的神经网络编译器。Google 的多级中间表示 (MLIR) 是一种编译器基础架构,专注于张量处理器,已被 LLVM 吸收。Microsoft 的嵌入式学习库 (ELL) 是另一个用于资源受限的 AI 设备的交叉编译工具链。
然而,Glow 比任何一个都更成熟,已于 2018 年开源。它也比许多现有的 AI 编译器选项更高效。
在 i.MX 跨界 MCU 的性能测试中,恩智浦系统工程师使用 TensorFlow Lite 和 Glow 编译了 32 x 32 CIFAR-10 数据集,并将它们输入 RT1060、RT1170 和 RT685 设备。Glow 编译的输入表现出至少 3 倍帧/秒的性能提升,而图 2 让您了解 AOT 编译与 TensorFlow/TensorFlow Lite 框架中使用的即时 (JIT) 编译相比的效率如何。
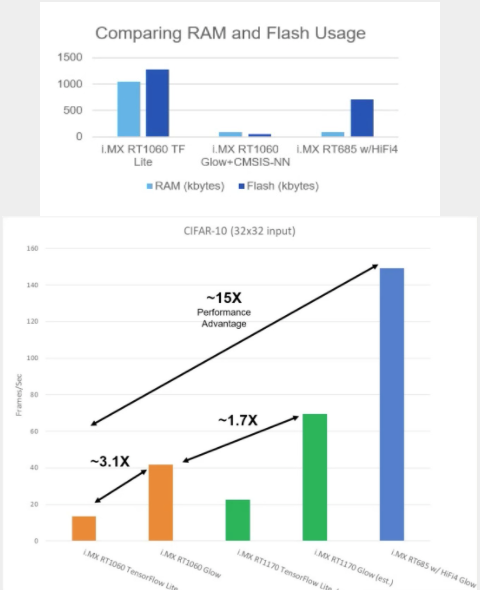
图 2a 和 2b。与 TensorFlow Lite 等即时 (JIT) 编译器相比,Glow 的提前 (AOT) 编译器可节省大量 RAM 和闪存,同时还具有显着的每秒帧数性能优势。
请记住,i.MX1060 具有高达 1 MB 的片上 RAM。NXP 的 eIQ 软件开发环境支持 Glow。
开源人工智能:看不到终点线
人工智能技术市场瞬息万变,这使得开发组织很难致力于任何技术。这可能是 Glow 最引人注目的方面之一,它甚至与技术没有直接关系。
作为一个拥有 130 多个活跃贡献者的开源项目,Facebook、英特尔等大型组织继续对 Glow 主线做出承诺,因为它们现在依赖于其通用基础设施来访问指令、操作符、内核等。
然后,很明显,开源具有内在价值。
“我们经常看到我们关心的外部用户的贡献,比如更通用的并行化框架,我们有很多他们正在运行的机器学习模型,”Fix 说。“所以也许它可以让他们在我们无需做任何事情的情况下获得对运营商的支持。“我认为您正在研究这个特定的计算机视觉模型”或者,“我认为这是您所说的操作员。” 他们只是审查它并移植它并登陆它。
“我们都可以从彼此在传统开源框架中的工作中受益,”他补充道。
审核编辑:郭婷
-
Facebook
+关注
关注
3文章
1429浏览量
54648 -
人工智能
+关注
关注
1791文章
46859浏览量
237571 -
编译器
+关注
关注
1文章
1618浏览量
49051
发布评论请先 登录
相关推荐

人工智能编译器与传统编译器的区别
Meta发布基于Code Llama的LLM编译器
SEGGER编译器优化和安全技术介绍 支持最新C和C++语言

C语言:嵌入式开发中的关键编译器角色
怎么在NanoEdge AI Studio设定交叉编译器呢?

Triton编译器的原理和性能

TVM编译器的整体架构和基本方法





 工商网监
工商网监
评论