 通过并行处理和异构SoC超越摩尔定律
通过并行处理和异构SoC超越摩尔定律
2021 年嵌入式处理器报告:随着晶体管扩展的可靠每瓦性能增益接近尾声,未来几代处理器将如何访问有效执行要求苛刻的工作负载所需的计算?我的答案来自异构 SoC 上的并行处理。
“我们已经在 7 nm 上工作了很长时间,在那段时间里,我们不仅看到了摩尔定律的终结,而且还看到了阿姆达尔定律和丹纳德缩放的终结,”硅营销总监 Manuel Uhm 说在赛灵思。“这意味着,如果我们所做的只是采用 FPGA 并将这些晶体管从我们之前的节点(即 16 纳米)缩小到 7 纳米,然后收工,许多试图迁移完全相同的设计的客户可能很可能最终得到的设计坦率地说没有任何性能提升,实际上可能会增加功耗。
“很明显,这是完全错误的方式。”
需要明确的是,将硅晶体管缩小到 7 nm 以下并非不可能;5nm 器件已经投入生产。这是因为底层金属没有更快地运行,并且电流泄漏正在上升。
同时,在另一个方向上,传统的多核设备自身也遇到了扩展限制。当然,这些并行处理器在历史上一直是同质的,“而现实情况是,没有一个处理器架构可以优化地完成每项任务,”Uhm 争辩道。“不是 FPGA,不是 CPU,不是 GPU。”
这并不是说并行性在处理现代应用程序呈现的复杂处理任务方面没有优势。事实上,除了摩尔定律和丹纳德定标之外,并行计算可能是我们在高性能计算 (HPC) 和其他要求苛刻的用例中的最佳选择。
是的,我们仍然需要并行处理。但属于异类。
异构处理:不仅适用于数据中心
如前所述,异构并行处理技术的前沿是对高端应用中性能壁垒的回应。但这些架构在嵌入式计算环境中也变得越来越普遍。
VDC Research 高级分析师 Dan Mandell 指出,虽然“许多异构处理架构确实专注于高端应用,特别是数据中心和 HPC……FPGA SoC 和其他异构加速芯片的小型化是最重要的。让 Microsemi 和 Xilinx 等公司将更多此类设备带入智能边缘基础设施,如边缘/工业服务器和物联网网关。”
根据 Mandell 的说法,嵌入式市场中通用异构计算平台的一个关键驱动因素“是当今 OEM 和其他厂商对硬件架构的承诺犹豫不决。” 他说,这种犹豫是专用加速芯片快速发展的产物,以及未来几年边缘软件和人工智能生态系统将产生的框架和工作负载的不确定性。
他预计所有这些情况都会“对未来的半导体采购产生重大影响”,以及芯片供应商如何处理他们的处理器路线图。
“当今大多数 FPGA SoC 的价格和功率范围将迫使供应商最初专注于相对高端、资源丰富的嵌入式和边缘应用,”Mandell 假设。“然而,正在积极努力使 FPGA SoC ‘尺寸不可知’,最终甚至支持电池供电的连接设备。”
因此,随着异构并行处理变得越来越多常见的问题是,嵌入式工程师是否应该为系统设计的范式转变做好准备?英伟达副总裁兼嵌入式与边缘计算总经理 Deepu Talla 不这么认为。
“如果你仔细想想,嵌入式处理器总是使用加速器,”Talla 说。“即使在 20 年前,也有 Arm CPU,有 DSP,然后在特定硬件中完成视频编码/解码,对吧?它们在某种意义上是固定功能的,但它们都在并行处理事物。
“你需要这样做的原因是成本、功率、尺寸,”他继续说道。“并行处理器的效率比 CPU 高出几个数量级。”
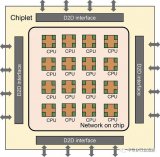
Nvidia 的 Xavier SoC 是其 Jetson Xavier 嵌入式平台的核心设备,以及公司将于 2021 年底或 2022 年推出的下一代 Orin 架构,均配备 GPU、Arm CPU、深度学习加速器、视觉加速器、编码器/解码器和其他专门的处理模块(图 3)。

【图3 | Nvidia Xavier SoC 配备了基于 Arm 的 Carmel CPU、Volta GPU、深度学习和视觉加速器以及其他可以并行处理工作负载的固定功能计算模块。]
然而,随着高级异构 SoC 变得越来越普遍,嵌入式开发人员可以期待的一个变化是使用片上网络 (NoC) 互连,在过去十年中,这种互连从传统的片上总线(如 AMBA 接口)发展而来。这提供了“控制如何连接 CPU、GPU、视频编码器、深度学习加速器、显示处理器、相机处理器、安全处理器,所有这些东西,”Talla 说。
NoC 有助于加速和优化跨 SoC 的块到块的数据流,这有助于尽可能高效地执行工作负载。例如,NXP 在其多功能 i.MX SoC 系列中利用了 NoC 和传统总线架构。
“异构计算是我们多年来一直在实施的东西。NXP Semiconductors, Inc. 边缘处理业务和技术战略主管 Gowrishankar Chindalore 博士说,我相信现在是我们真正开始达到最佳使用点的地方。机器学习,因为我们今天使用的是 CPU、GPU、DSP 和神经处理单元 (NPU)。
“但优化的一部分,不仅仅是计算元素。系统周围的一切都需要发生,”他继续说道。“因此,除了异构计算之外,我们专注于提高效率的地方,正在关注芯片分割流水线、视频流水线、图形流水线中整个流程的浪费。
“因为我们做得越多,我们在性能方面获得的效率就越高,显然,用于执行相同功能的能量就越少,”他补充道。
(编者按:阅读《异构多核实现十倍嵌入式内存性能的三种方法》)
走向异质世界
Mandell引用 VDC Research 的 2020 年物联网、嵌入式和移动处理器技术报告,预计嵌入式 SoC 的全球市场将“在未来几年继续超过 MPU、MCU、GPU 等分立半导体的商业市场”,因为 OEM 看起来整合计算资源和多芯片实现。他说,从长远来看,对工作负载加速和处理器优化的需求只会“推动进一步增长”。
与此同时,我们衡量性能和功耗的方式将不得不改变。正如 The Linley Group 的高级分析师 Mike Demler 在其公司的《深度学习处理器指南》中所说,即使是像 TOPS/W 这样的以 AI 为中心的新基准测试也“具有误导性,因为真正的 AI 工作负载从未达到接近 100% 的利用率。”
他说,我们将不得不用“一个真实的工作负载,比如 Bert NLP 模型,而不是一个基于理论的、基于架构的规范”来衡量诸如电源效率之类的东西。
但是,孤立地测量处理器复合体是否有意义?它真的很重要吗?一如既往,重点将放在它在您的系统环境中提供的内容上。
“在使用每个流程节点之前,就像‘哦,太好了。我得到两倍的性能,一半的功耗!‘”Uhm 说。“那些日子已经一去不复返了。那些日子对每个人来说都已经一去不复返了。在 7 nm 时,这些晶体管现在开始泄漏。你只会遇到其他类型的问题在许多情况下,我们认为这是无法克服的。
“因此,在意识到这一点后,我们现在正在研究系统级问题,”他继续说道,“我们将所有这些东西放在一起,了解所有这些权衡,并确保我们能够涵盖以允许满足性能和功率预算的方式进行尽可能多的处理。再说一次,这些不再是容易的事情了。我们意识到我们将能够提供更高的性能或降低功耗,在某些情况下它是非此即彼的。你会得到两者并不总是给定的。
“再说一次,没有任何处理器是最适合所有事情的。您不能总是提高性能并降低功耗,”Uhm 继续说道。“但专注于这种新架构,一种异构处理器,基本上可以让他们做到这一点。”
审核编辑:郭婷
-
处理器
+关注
关注
68文章
19296浏览量
230007 -
晶体管
+关注
关注
77文章
9698浏览量
138291 -
AI
+关注
关注
87文章
30980浏览量
269264
发布评论请先 登录
相关推荐
击碎摩尔定律!英伟达和AMD将一年一款新品,均提及HBM和先进封装

“芯合”异构混合并行训练系统1.0发布
后摩尔定律时代,提升集成芯片系统化能力的有效途径有哪些?
异构集成封装类型详解
高算力AI芯片主张“超越摩尔”,Chiplet与先进封装技术迎百家争鸣时代

浅谈国产异构双核RISC-V+FPGA处理器AG32VF407的优势和应用场景
“自我实现的预言”摩尔定律,如何继续引领创新
封装技术会成为摩尔定律的未来吗?

为什么使用FPGA?FPGA为什么比GPU的延迟低这么多?

电源解决方案跟摩尔定律有何关系?它如何跟上摩尔定律的步伐?

功能密度定律是否能替代摩尔定律?摩尔定律和功能密度定律比较
摩尔定律的终结:芯片产业的下一个胜者法则是什么?

摩尔定律的未来:CMOS技术的挑战与机遇
中国团队公开“Big Chip”架构能终结摩尔定律?





 工商网监
工商网监
评论