 TinyML设备的设备上持续学习
TinyML设备的设备上持续学习
随着现代人工智能技术的兴起,对设备上模型训练的需求已成为一个重要的研究领域。任务复杂性和工作量的增加强调了将 AI 模型训练带到边缘的必要性。
在边缘进行推理之后,需要在边缘的设备上持续训练 AI 模型,以处理具有非平稳输入的不确定情况。深度学习模型在部署到嵌入式设备之前在远程服务器上进行训练。但是已经发生了向持续学习的转变,设备上的个性化可以通过新获取的数据增加基于用户交互的自适应功能。
在设备上更新和重新训练已经训练过的模型可能需要很长时间,这对于实时输入来说几乎是不可能完成的任务。即使只是简单地更新预测模型,新的传入数据也会导致灾难性的遗忘,其中人工神经网络在学习新信息时会完全突然地忘记先前学习的信息。
持续学习 (CL) 是随着不断变化的外部环境、动态传入数据而增量学习的能力,以及泛化分布外和执行迁移和元学习的能力。由于内存和计算量的增加,神经网络仅在部署到嵌入式设备之前进行推理训练。直到最近,对超低功耗设备的深度学习模型的研究仍基于训练后部署假设,其中静态模型无法在不断变化的环境中采用。为了改变动态,在基于 Latent Replay 的 CL 技术上开展的工作,超低功耗 TinyML 设备对计算和内存的需求一直是个问题。
实时持续学习的潜在回放
持续学习的 Latent Replay 方法实际上意味着可以从上面的架构图中理解的几个方面。在潜在重放中,不是将过去数据的一部分存储在输入空间中,而是将数据存储在某个中间层的激活卷中。这反过来又解决了计算和存储问题,为此在复杂的视频上进行了基准测试,例如 CORe50 NICv2 和 OpenLORIS。
查看 Latent Replay 的架构图,离输入层更近的层,通常称为表示层,通常会执行低级特征提取。预训练模型的权重是稳定的,可以跨应用程序重复使用,而更高级别的模型提取特定于类的特征,对于最大限度地提高准确性至关重要。为了保持稳定性,所提出的方法在 Latent Replay 之下的层采用减慢学习速度,并让上面的层以自己的速度学习。
即使较低层的速度减慢到零,也可以节省计算和存储,因为需要在网络中向前和向后流动的模式的一小部分。但在表示层未冻结为零的正常情况下,存储在外部存储器中的激活会经历老化效应。如果层的训练很慢,老化效应不会破坏,因为外部记忆有时间恢复新的模式。
具有量化潜在重放的设备上持续学习
在最近基于 Pellegrini 所做工作的研究中,研究人员致力于开发一个 TinyML 平台,用于通过量化的潜在回放进行设备上的持续学习。这项工作采用 VEGA,这是一个基于 PULP 的深度学习 TinyML 平台,它是一种采用 22nm 工艺技术制造的端节点片上系统原型。CL 的 Latent Replay 已经在智能嵌入式设备上进行了测试,包括在 Snapdragon-845 CPU 上运行的智能手机。但这项工作更侧重于超低功耗 TinyML 设备,以节省与之相关的计算和内存限制。
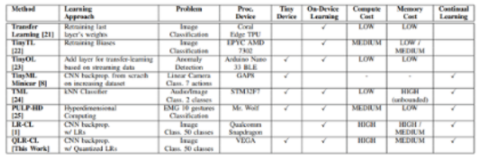
该研究提出了扩展 Latent Replay 算法以使用 8 位量化和冻结前端的想法。这不会影响 CL 过程并支持带有量化的 Latent Replay 压缩,从而将内存需求减少多达 4.5 倍。这被称为持续学习的量化潜在重放。CL 原语包括常见层的前向和后向传播,如卷积、深度卷积和全连接层,它们经过调整以在 VEGA 上优化执行。
可以根据应用程序和可用资源定义的计算和存储精度之间始终存在权衡。用于持续学习的潜在重放是适用于从嵌入式设备到智能小工具的各种系统的最有效方式。
审核编辑:郭婷
-
嵌入式
+关注
关注
5085文章
19138浏览量
305708 -
cpu
+关注
关注
68文章
10872浏览量
211999 -
深度学习
+关注
关注
73文章
5504浏览量
121222
发布评论请先 登录
相关推荐
在边缘设备上设计和部署深度神经网络的实用框架
AI编程在工业自动化设备上应用趋势
PLC设备的数据采集上云解决方案

焊接设备维护技巧
第二届大会回顾第25期 | OpenHarmony上的Python设备应用开发

2024工业设备上云产业调研报告:谁在乘“云”而上?
把好事办好:工业设备更新上云难题与破解
工业机床CNC设备如何上云?
工业平板电脑雕刻机设备上的应用

工业平板电脑在印刷机械设备上的应用
手持设备上使用的扫码模组






 工商网监
工商网监
评论