 《基于时间序列数据进行有效报警》的实践总结
《基于时间序列数据进行有效报警》的实践总结
本文可以看做是对《SRE》一书第10章《基于时间序列数据进行有效报警》的实践总结。 Prometheus是一款开源的业务监控软件,可以看作是Google内部监控系统 Borgmon 的一个(非官方)实现。 本文会介绍我近期使用Prometheus构建的一套完整的,可用于中小规模(小于500节点)的半自动化(少量人工操作)监控系统方案。
主动监控
监控是运维系统的基础,我们衡量一个公司/部门的运维水平,看他们的监控系统就可以了。 监控手段一般可以分为三种:
主动监控:业务上线前,按照运维制定的标准,预先埋点。具体的实现方式又有多种,可能通过日志、向本地 Agent 上报、提供 REST API 等。
被动监控:通常是对主动监控的补充,从外围进行黑盒监控,通过主动探测服务的功能可用性来进行监控。比如定期ping业务端口。
旁路监控:主动监控和被动监控,通常还是都在内部进行的监控,内部运行平稳也不能保证用户的体验都是正常的(比如用户网络出问题),所以仍然需要通过舆情监控、第三方监控工具等的数据来间接的监控真实的服务质量。
主动监控是最理想的方案,后两种主要用作补充,本文只关注主动监控。 监控实际是一个端到端的体系(基础设施-服务器-业务-用户体验),本文只关注业务级别的主动监控。
Prometheus
为什么选择Prometheus而不是其它TSDB实现(如InfluxDB)?主要是因为Prometheus的核心功能,查询语言 PromQL,它更像一种可编程计算器,而不是其那么像 SQL,也意味着 PromQL 可以近乎无限之组合出各种查询结果。 比如,我们有一个http服务,监控项http_requests_total用于统计请求次数。某一组监控数据可能是这个样子:
http_requests_total{instance="1.1.1.1:80",job="cluster1",location="/a"} 100http_requests_total{instance="1.1.1.1:80", job="cluster1", location="/b"} 110http_requests_total{instance="1.1.1.2:80", job="cluster2", location="/b"} 100http_requests_total{instance="1.1.1.3:80", job="cluster3", location="/c"} 110 这里有3个标签,分别对应抓取的实例,所属的 Job(一般我用集群名),访问路径(你可以理解为Nginx的location),Prometheus多维数据模型意味着我们可以在任意一个或多个维度进行计算:
如果你想统计单机qps,sum(rate(http_requests_total[1m])) by (instance)
如果想用统计每个集群每个不同 location 的 path 的 qps,sum(rate(http_requests_total[1m])) by (job, path),PromQL会依据标签job-path的值聚合出结果。
除了PromQL,丰富的数据类型可以提供更有意义的监控项:
Counter(计数器):标识单调递增的数据,比如接口访问次数。
Gauge(刻度):当前瞬时的一个状态,可能增加,也可能减小,比如CPU使用率,平均延时等等。
Historgram(直方图):用于统计数据的分布,比如95 percentile latency。
大部分监控项都可以使用Counter来实现,少部分使用Gauge和Histogram,其中Histogram在服务端计算是相当费CPU的,所以也没要导出太多Histogram数据。 最后,Prometheus采用PULL模型的实时抓取存储计算,主动去抓取监控实例数据,相比于PUSH模型对业务侵入更低,相比于基于log的离线统计则更实时,而监控实例只需提供一个文本格式的/metrics接口也更容易debug。
服务框架的改造
笔者所在团队使用统一的服务框架来规范项目开发并有效降低了开发难度。 这里先介绍下我们的服务框架:
类似于 Nginx 的多进程架构(master/worker),但同时也支持多线程的事件循环编程模型
支持多种接入协议(HTTP,Thrift,PB等),但主流是HTTP
业务通过 Module 来加载进框架执行(类似 Nginx 的 module,但更简单)
提供纯异步的下游访问 API
为了使服务框架可以导出内部监控项,主要涉及几方面的工作:
提供基础数据类型
目前并没有官方的Prometheus Client Library,几种开源实现也都不太符合框架的需求。目前实现了支持多线程多进程的Counter和Histogram(除了初始化之外,更新操作都是无锁的),而Gauge由于多进程场景有的情况是无法聚合监控数据的(没用统一的聚合方法,并不一定都可以相加),所以没有提供具体实现
基础数据要有类似注册表的功能,方便自动导出数据到/metrics接口
在服务框架埋点
要足够灵活,将容易变化的信息通过标签来表达。 比如一个web服务可能有echo,date两个location,如果要统计它们qps,不要定义echo_requests_total,date_requests_total两个不同名字的 metrics,而应该定义一个名为http_requests_total的 metrics,通过标签location(分别为echo/date)来区分,这样再增加/减少接口是不需要改代码的
理想情况是业务几乎为各种通信功能自行埋点,所以内置埋点要将常用监控项都要覆盖到(QPS,Latency,Error Ratio)
数据的抓取与展现
具备导出能力后,就可以通过Prometheus 进行抓取了,但还有几个小坑: 用户定义的metrics名字,可能是不符合Prometheus规范的,而遇到一条不合法的数据,Prometheus就会停止抓取,所以导出数据时要先做一遍过滤和改写 要控制导出数据规模,一些只对单机监控有意义的数据可以不导出(框架有针对单机的监控页面) 在使用 Prometheus 时,也有几个地方要注意: Prometheus即是一个CPU密集型(查询)也是一个IO密集型(数据落地)的,CPU数量是多多益善,内存越大越好(来缓存抓取的数据,所以应该减少不必要的业务数据导出),尽量要使用SSD(这个很关键!),因为一旦Prometheus的内存使用量达到阈值会停止抓取数据!这个停止抓取的时间,至少是分钟级,甚至是无法恢复!所以只要有条件就要用SSD。 Prometheus号称支持 reload,但目测不是很好用,比如你修改了告警规则文件,重载之后,新旧告警规则似乎会一起计算执行…. Prometheus本身也提供图形界面,但是很简陋:
通常还是使用Grafana来展示监控数据。
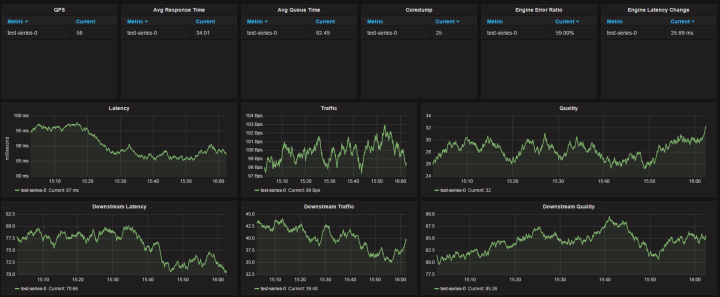
因为是统一的业务框架,统一的监控指标,所以 Grafana 的 Dashboard 很容易统一配置:
我没有找到将默认模板打包进 Grafana 的方法,只能迂回的创建了一个新的Grafana Plugin,在启动之后,每个业务实例只需要启动下这个插件,然后配置一个默认的 Prometheus 数据源,就可以使用统一的监控 Dashboard
Dashboard 分为3行
第一行展示实时的 QPS,平均延时,平均排队时间,Coredump 数量,下游引擎失败率,下游引擎延时变化
第二行展示业务的延迟(50%和95%延迟),流量,吞吐(按照不同错误码)
第三行展示下游引擎的延迟(50%和95%延迟),流量,吞吐(按照不同错误码)
能够展示 Prometheus 强大威力的是,这里面每一个图表,都可以同时展示所有机房的监控指标,而每一个指标的计算只需要一条 Query 语句。比如第一行第五列,各个机房的各个下游的失败率统计并排序,只用了一条语句:
topk(5, 100*sum(rate(downstream_responses{error_code!="0"}[5m])) by (job, server)/sum(rate(downstream_responses[5m])) by (job, server)) 注意这里的Range Vector Selector - [5m],意味着我们是基于过去5分钟的数据来计算rate,这个值取的越小,得到的监控结果波动越大,越大则越平滑,选择多大的值,取决于你想要什么结果。建议图表使用5m,而告警规则计算采用1m。如果业务不是很重要,可以适当增大这个值。 这一套监控模板基本覆盖了业务对可用性监控的需求,同时业务也可以自己定义监控指标并进行监控。
AlertManager
Prometheus 周期性进行抓取数据,完成抓取后会检查是否有告警规则并进行计算,满足告警规则就会触发告警,发送到 alertmanager。基于这个流程,当你在监控图表看到异常时,告警已经先行触发了。
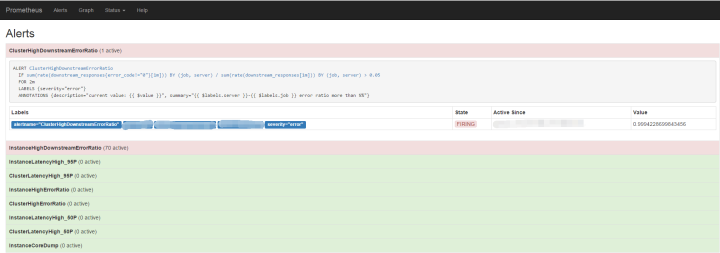
默认情况我们配置了不到10条告警规则,要注意的是周期的选择,过长的话会产生较大延迟,太短的话一个小的流量波动都会导致大量报警出现。 Prometheus 的设计是产生报警,但报警的汇总、分发、屏蔽则在 AlertManager 服务完成。
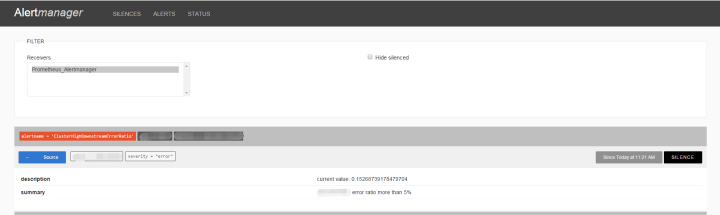
AlertManager 目前还是非常简单的,但它可以将告警继续分发到其他接收者:
可以通过webhook机制,发送告警到一个中间服务转换格式再发送到内部告警接口
如果使用第三方告警管理平台,如PageDuty、OneAlert,可以直接用内置的 pageduty 支持或 webhook 发送告警过去
如果是一穷二白的团队,建议配置 email + slack,实现告警归档和手机 Push
更复杂告警分级管理,AlertManager 还是有很长的路要走,这个话题也值得今后单独讲下。
Prometheus + Grafana + Mesos
Prometheus + Grafana 的方案,加上统一的服务框架,可以满足大部分中小团队的监控需求。我们将这几个组件打包一起部署在 Mesos 之上,统一的安装包进一步降低监控系统部署的难度,用户需要配置一些简单的参数即可。但还需要注意几点:
目前并没有将 Prometheus 和 Grafana 容器化部署,因为这两者本身就没有什么特殊依赖;安装包存储在 minio 中。
由于 Prometheus 系统的特殊性,我们通常将其指定在一台固定的机器上执行,且将数据落地到一个固定的目录,这样重启 Prometheus 的影响会非常低
Grafana 是展示给用户的,需要尽可能的保持固定入口,所以我们通过HAPROXY_CONSUL给其配置了代理

结 论
Prometheus 是相当强大并快速成长的一个监控系统实现,虽然在稳定性、性能、文档上仍有很大提升空间,但对于中小团队是一个很棒的选择,通过定制服务框架,设计完善的埋点,统一的Prometheus/Grafana配置模板,再加上Mesos平台,可以半自动化的部署实时业务监控系统。
审核编辑 :李倩
-
监控系统
+关注
关注
21文章
3949浏览量
177662 -
时间序列
+关注
关注
0文章
31浏览量
10460
原文标题:无监控,不运维!Prometheus 在线服务的监控实操指南
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
使用BP神经网络进行时间序列预测
时空引导下的时间序列自监督学习框架

如何使用RNN进行时间序列预测
LSTM神经网络在时间序列预测中的应用
请问PCM4220复位之后多长时间输出数据有效?
【《时间序列与机器学习》阅读体验】+ 时间序列的信息提取
【「时间序列与机器学习」阅读体验】+ 鸟瞰这本书
【「时间序列与机器学习」阅读体验】+ 简单建议
【《时间序列与机器学习》阅读体验】+ 了解时间序列
深度学习中的时间序列分类方法
名单公布!【书籍评测活动NO.35】如何用「时间序列与机器学习」解锁未来?
时间序列分析的异常检测综述
深度学习在时间序列预测的总结和未来方向分析






 工商网监
工商网监
评论