 机器学习、深度学习面试过程中会遇到的问题
机器学习、深度学习面试过程中会遇到的问题
导读
本文总结了一些秋招面试中会遇到的问题和一些重要的知识点,适合面试前突击和巩固基础知识。
前言
最近这段时间正临秋招,这篇文章是老潘在那会找工作过程中整理的一些重要知识点,内容比较杂碎,部分采集于网络,简单整理下发出来,适合面试前突击,当然也适合巩固基础知识。另外推荐大家一本叫做《百面机器学习》的新书,2018年8月份出版的,其中包括了很多机器学习、深度学习面试过程中会遇到的问题,比较适合需要准备面试的机器学习、深度学习方面的算法工程师,当然也同样适合巩固基础~有时间一定要需要看的书籍:
- 程序员的数学系列,适合重温知识,回顾一些基础的线性代数、概率论。
- 深度学习花书,总结类书,有基础知识的讲解,比较全面。
- 统计学习方法,总结类书,篇幅不长,都是核心。
- Pattern Recognition and Machine Learning,条理清晰,用贝叶斯的方式来讲解机器学习。
- 机器学习西瓜书,适合当教材,内容较广但是不深。
常见的常识题
- L1正则可以使少数权值较大,多数权值为0,得到稀疏的权值;L2正则会使权值都趋近于0但非零,得到平滑的权值;
- 在AdaBoost算法中,被错分的样本的权重更新比例的公式相同;
- Boosting和Bagging都是组合多个分类器投票的方法,但Boosting是根据单个分类器的正确率决定其权重,Bagging是可简单地设置所有分类器权重相同;
- EM算法不能保证找到全局最优值;
- SVR中核函数宽度小欠拟合,宽度大容易过拟合
- PCA和LDA都是经典的降维算法。PCA是无监督的,也就是训练样本不需要标签;LDA是有监督的,也就是训练样本需要标签。PCA是去除掉原始数据中冗余的维度,而LDA是寻找一个维度,使得原始数据在该维度上投影后不同类别的数据尽可能分离开来。
PCA是一种正交投影,它的思想是使得原始数据在投影子空间的各个维度的方差最大。假设我们要将N维的数据投影到M维的空间上(M
关于K近邻算法的知识有很多,比如算法执行的步骤、应用领域以及注意事项,不过相信很多人对K近邻算法的使用注意事项不是很清楚。在这篇文章中我们针对这个问题进行解答,带大家来好好了解一下k近邻算法的注意事项以及K近邻算法的优点与缺点。
K近邻算法的使用注意事项具体就是使用距离作为度量时,要保证所有特征在数值上是一个数量级上,以免距离的计算被数量级大的特征所主导。在数据标准化这件事上,还要注意一点,训练数据集和测试数据集一定要使用同一标准的标准化。其中的原因总的来说就有两点内容,第一就是标准化其实可以视为算法的一部分,既然数据集都减去了一个数,然后除以一个数,这两个数对于所有的数据来说,就要一视同仁。第二就是训练数据集其实很少,在预测新样本的时候,新样本就更少得可怜,如果新样本就一个数据,它的均值就是它自己,标准差是0,这根本就不合理。
K近邻算法的优点具体体现在四方面。第一就就是k近邻算法是一种在线技术,新数据可以直接加入数据集而不必进行重新训练,第二就是k近邻算法理论简单,容易实现。第三就是准确性高,对异常值和噪声有较高的容忍度。第四就是k近邻算法天生就支持多分类,区别与感知机、逻辑回归、SVM。
K近邻算法的缺点,基本的 k近邻算法每预测一个“点”的分类都会重新进行一次全局运算,对于样本容量大的数据集计算量比较大。而且K近邻算法容易导致维度灾难,在高维空间中计算距离的时候,就会变得非常远;样本不平衡时,预测偏差比较大,k值大小的选择得依靠经验或者交叉验证得到。k的选择可以使用交叉验证,也可以使用网格搜索。k的值越大,模型的偏差越大,对噪声数据越不敏感,当 k的值很大的时候,可能造成模型欠拟合。k的值越小,模型的方差就会越大,当 k的值很小的时候,就会造成模型的过拟合。
如果让你写一个高斯模糊的函数,你该怎么写呢?
kmeans的收敛性?
其实是这样的,先分布到n台机器上,要保证k个初始化相同,经过一次迭代后,拿到k*n个新的mean,放到一台新的机器上,因为初始化相同,所以mean的排列相同,然后对属于每个类的n个mean做加权平均,再放回每台机器上做下一步迭代。
K值的选择:
KNN中的K值选取对分类的结果影响至关重要,K值选取的太小,模型太复杂。K值选取的太大,导致分类模糊。那么K值到底怎么选取呢?有人用Cross Validation,有人用贝叶斯,还有的用bootstrap。而距离度量又是另外一个问题,比较常用的是选用欧式距离。可是这个距离真的具有普适性吗?《模式分类》中指出欧式距离对平移是敏感的,这点严重影响了判定的结果。在此必须选用一个对已知的变换(比如平移、旋转、尺度变换等)不敏感的距离度量。书中提出了采用切空间距离(tangent distance)来替代传统的欧氏距离。
有监督:
无监督:
生成式模型:LDA KNN 混合高斯 贝叶斯 马尔科夫 深度信念 判别式模型:SVM NN LR CRF CART
逻辑回归即LR。LR预测数据的时候,给出的是一个预测结果为正类的概率,这个概率是通过sigmoid函数将wTx映射到[0,1]得到的,对于wTx正的很大时(可以认为离决策边界很远),得到为正类的概率趋近于1;对于wTx负的很大时(可以认为离决策边界很远),得到为正类的概率趋近于0。在LR中,跟“与决策边界距离”扯得上关系的仅此而已。在参数w求解过程中完全没有与决策边界距离的影子,所有样本都一视同仁。和感知机的不同之处在于,LR用到与决策边界的距离,是用来给预测结果一个可以看得到的置信区间。感知机里面没有这一考虑,只根据符号来判断。而SVM更进一步,在参数的求解过程中,便舍弃了距离决策边界过远的点。LR和感知机都很容易过拟合,只有SVM加入了L2范数之后的结构化风险最小化策略才解决了过拟合的问题。总结之:
逻辑回归只能解决二分类问题,多分类用softmax。相关参考链接
Bagging和Boosting的区别:
Bagging 是 Bootstrap Aggregating 的简称,意思就是再取样 (Bootstrap) 然后在每个样本上训练出来的模型取平均,所以是降低模型的 variance. Bagging 比如 Random Forest 这种先天并行的算法都有这个效果。Boosting 则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行加权,所以随着迭代不断进行,误差会越来越小,所以模型的 bias 会不断降低High variance 是model过于复杂overfit,记住太多细节noise,受outlier影响很大;high bias是underfit,model过于简单,cost function不够好。boosting是把许多弱的分类器组合成一个强的分类器。弱的分类器bias高,而强的分类器bias低,所以说boosting起到了降低bias的作用。variance不是boosting的主要考虑因素。bagging是对许多强(甚至过强)的分类器求平均。在这里,每个单独的分类器的bias都是低的,平均之后bias依然低;而每个单独的分类器都强到可能产生overfitting的程度,也就是variance高,求平均的操作起到的作用就是降低这个variance。Bagging算法的代表:RandomForest随机森林算法的注意点:
咱们机器学习升级版的随机森林章节,我用白板写了写这个公式:p = 1 - (1 - 1/N)^N,其意义是:一个样本在一次决策树生成过程中,被选中作为训练样本的概率,当N足够大时,约等于63.2%。简言之,即一个样本被选中的概率是63.2%,根据二项分布的的期望,这意味着大约有63.2%的样本被选中。即有63.2%的样本是不重复的,有36.8%的样本可能没有在本次训练样本集中。随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。随机森林的随机性体现在每颗树的训练样本是随机的,树中每个节点的分裂属性集合也是随机选择确定的。有了这2个随机的保证,随机森林就不会产生过拟合的现象了。随机森林是用一种随机的方式建立的一个森林,森林是由很多棵决策树组成的,每棵树所分配的训练样本是随机的,树中每个节点的分裂属性集合也是随机选择确定的。
相关的notebook除了cs231n也可以看这里。
面试见得比较少,感兴趣的可以看下:
降采样是手段不是目的:
降采样的理论意义,我简单朗读一下,它可以增加对输入图像的一些小扰动的鲁棒性,比如图像平移,旋转等,减少过拟合的风险,降低运算量,和增加感受野的大小。相关链接:为什么深度学习中的图像分割要先编码再解码?
最大池化提取边缘等“最重要”的特征,而平均池化提取的特征更加smoothly。对于图像数据,你可以看到差异。虽然两者都是出于同样的原因使用,但我认为max pooling更适合提取极端功能。平均池有时不能提取好的特征,因为它将全部计入并计算出平均值,这对于对象检测类型任务可能不好用但使用
在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hxw的全局卷积,h和w分别为前层卷积结果的高和宽使用 global average pooling 全局平均池化来代替卷积
那么,1*1卷积的主要作用有以下几点:
看这个问题的回答https://www.zhihu.com/question/56024942/answer/369745892
看这个问题的回答https://www.zhihu.com/question/41037974/answer/150522307
对于两路输入来说,如果是通道数相同且后面带卷积的话,add等价于concat之后对应通道共享同一个卷积核。下面具体用式子解释一下。由于每个输出通道的卷积核是独立的,我们可以只看单个通道的输出。假设两路输入的通道分别为X1, X2, ..., Xc和Y1, Y2, ..., Yc。那么concat的单个输出通道为(*表示卷积):
而add的单个输出通道为:
因此add相当于加了一种prior,当两路输入可以具有“对应通道的特征图语义类似”(可能不太严谨)的性质的时候,可以用add来替代concat,这样更节省参数和计算量(concat是add的2倍)。FPN[1]里的金字塔,是希望把分辨率最小但语义最强的特征图增加分辨率,从性质上是可以用add的。如果用concat,因为分辨率小的特征通道数更多,计算量是一笔不少的开销。https://www.zhihu.com/question/306213462/answer/562776112
SSD是直接分类,而FasterRcnn是先判断是否为背景再进行分类。一个是直接细分类,一个是先粗分类再细分类。
反向传播原理看CS231n中的BP过程,以及Jacobian的传播。
在百面深度学习中有相应的章节。
有一篇文章比较好的介绍了,还有在那本电子版CNNbook中也有。
多层神经网络通常存在像悬崖一样的结构,这是由于几个较大的权重相乘导致的。遇到斜率很大的悬崖结构,梯度更新会很大程序地改变参数值,通常会完全跳过这类悬崖的结构。花书P177.
http://ai.51cto.com/art/201710/555389.htm
https://blog.csdn.net/xs11222211/article/details/82931120#commentBox
这个讲的比较好(TP与FP和ROC曲线):
精确率是指分类正确的正样本个数占分类器判定为正样本的样本个数的比例。召回率是指分类正确的正样本个数占真正的正样本个数的比例。Precision值和Recall值是既矛盾又统一的两个指标,为了提高Precision值,分类器需要尽量在“更有把握”时才把样本预测为正样本,但此时往往会因为过于保守而漏掉很多“没有把握”的正样本,导致Recall值很低。如何权衡这两个值,所以出现了PR曲线、ROC曲线以及F1 score等更多的标准来进行判断。https://www.cnblogs.com/xuexuefirst/p/8858274.html
Yolov2相比Yolov1因为采用了先验框(Anchor Boxes),模型的召回率大幅提升,同时map轻微下降了0.2。
https://segmentfault.com/a/1190000014829322
https://www.cnblogs.com/eilearn/p/9071440.html
https://blog.csdn.net/zdh2010xyz/article/details/54293298
空洞卷积一般都伴有padding,如果dilation=6,那么padding也等于6。通过空洞卷积后的卷积特征图的大小不变,但是这个卷积的感受野比普通同等大小的卷积大。不过通道数是可以改变的。
但是要注意,由于空洞卷积本身不会增大运算量,但是后续的分辨率没有减小,后面的计算量就间接变大了。https://zhuanlan.zhihu.com/p/52476083
具体问题具体分析。
如果模型的实际容量比较大,那么可以说模型可以完全学习到整个数据集,会发生过拟合。这时候再添加新的数据进去,模型的性能会进一步提升,说明模型还没有被撑死。期望风险是模型关于联合分布的期望损失,经验风险是模型关于训练数据集的平均损失。根据大树定律,当样本容量N趋于无穷时,经验风险趋于期望风险。但是当样本的容量比较小的的时候,经验风险最小化学习的效果未必就会很好,会产生“过拟合”的现象。结构风险最小化是为了防止过拟合而提出的策略。
https://lilianweng.github.io/lil-log/2019/03/14/are-deep-neural-networks-dramatically-overfitted.html
https://www.jianshu.com/p/97aafe479fa1(重要)
在Pytorch中只能在optim中设置weight_decay,目前只支持L2正则,而且这个正则是针对模型中所有的参数,不论是w还是b,也包括BN中的W和b。
就是因为 batch norm 过后, weight 影响没那么重了,所以 l2 weight decay 的效果就不明显了。证明了L2正则化与归一化相结合时没有正则化效应。相反,正则化会影响权重的范围,从而影响有效学习率。
https://www.cnblogs.com/makefile/p/batch-norm.html?utm_source=debugrun&utm_medium=referral
空间金字塔池化(SSP)可以使不同尺寸的图像产生固定的输出维度。借题也问个问题,为什么fast rcnn的roi pooling是一个max pooling呢?roi pooling后面也是做单个roi的classification,为啥不和classification的pooling不同?我直觉是看feature map中的一个channel,提取全局特征(如,做classification)用average pooling,提取提取全局信息;提取局部特征(如,roi pooling)应该用max pooling,提取局部最明显的特征,成为7×7的grid后交给后面的fc来做classification。相关介绍:
https://zhuanlan.zhihu.com/p/71231560
因为作者提出了一种方案,同时改变了多个条件/参数,他在接下去的消融实验中,会一一控制一个条件/参数不变,来看看结果,到底是哪个条件/参数对结果的影响更大。下面这段话摘自知乎,@人民艺术家:你朋友说你今天的样子很帅,你想知道发型、上衣和裤子分别起了多大的作用,于是你换了几个发型,你朋友说还是挺帅的,你又换了件上衣,你朋友说不帅了,看来这件衣服还挺重要的。
https://oldpan.me/archives/write-hard-nms-c
线性回归:通过均方误差来寻找最优的参数,然后通过最小二乘法来或者梯度下降法估计:
注意:
来源文章:
对于凸函数来说,局部最优就是全局最优,相关链接:http://sofasofa.io/forum_main_post.php?postid=1000329
http://sofasofa.io/forum_main_post.php?postid=1000322Logistic classification with cross-entropy
https://zhuanlan.zhihu.com/p/61440116
https://www.zhihu.com/question/65044831/answer/227262160
不看必进坑~不论是训练还是部署都会让你踩坑的Batch Normalization
Batch size过小会使Loss曲线振荡的比较大,大小一般按照2的次幂规律选择,至于为什么?没有答出来,面试官后面解释是为了硬件计算效率考虑的,海哥后来也说GPU训练的时候开的线程是2的次幂个神经网络的本质是学习数据的分布,如果训练数据与测试数据的分布不同则会大大降低网络的泛化能力。随着网络训练的进行,每个隐层的变化使得后一层的输入发生变化,从而每一批训练的数据的分布也会变化,致使网络在每次迭代过程中都需要拟合不同的数据分布,增加数据训练的复杂度和过拟合的风险。
对数据的剧烈变化有抵抗能力。
要注意BN在卷积网络层中,因为参数的共享机制,每一个卷积核的参数在不同位置的神经元当中是共享的,因此也应该被归一化。(具体看一下实现过程)https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/batch_norm_layer.html但是在训练过程中如果batch-size不大的话,可以不使用BN(MaskRcnn这样说的)。至此,关于Batch Normalization的理论与实战部分就介绍道这里。总的来说,BN通过将每一层网络的输入进行normalization,保证输入分布的均值与方差固定在一定范围内,减少了网络中的Internal Covariate Shift问题,并在一定程度上缓解了梯度消失,加速了模型收敛;并且BN使得网络对参数、激活函数更加具有鲁棒性,降低了神经网络模型训练和调参的复杂度;最后BN训练过程中由于使用mini-batch的mean/variance作为总体样本统计量估计,引入了随机噪声,在一定程度上对模型起到了正则化的效果。
BN与贝叶斯的关系:
在实践中,我发现,跨卡同步的BN对于performance相当有用。尤其是对于detection,segmentation任务,本来Batch size较小。如果Batch Norm能跨卡同步的话,就相当于增大了Batch Norm的batch size 这样能估计更加准确的mean和variance,所以这个操作能提升performance。
跨卡同步BN的关键是在前向运算的时候拿到全局的均值和方差,在后向运算时候得到相应的全局梯度。最简单的实现方法是先同步求均值,再发回各卡然后同步求方差,但是这样就同步了两次。实际上只需要同步一次就可以,我们使用了一个非常简单的技巧,改变方差的公式(公式是图片,具体大家自己网上搜一下SyncBN)。这样在前向运算的时候,我们只需要在各卡上算出与,再跨卡求出全局的和即可得到正确的均值和方差, 同理我们在后向运算的时候只需同步一次,求出相应的梯度与。我们在最近的论文Context Encoding for Semantic Segmentation 里面也分享了这种同步一次的方法。有了跨卡BN我们就不用担心模型过大用多卡影响收敛效果了,因为不管用多少张卡只要全局的批量大小一样,都会得到相同的效果。
出现因素:
原因,误差传播公式可以写成参数W和导数F连乘的形式,当误差由第L层传播到输入以外的第一个隐含层的时候,会涉及到很多很多的参数和导数的连乘,这时误差很容易产生消失或者膨胀,导致不容易学习,拟合能力和泛化能力较差。残差层中的F层只需要拟合输入x与目标输出H的残差H-x即可,如果某一层的输出已经较好地拟合了期望结果,那么多一层也不回使得模型变得更差,因为该层的输出直接被短接到两层之后,相当于直接学习了一个恒等映射,而跳过的两层只需要拟合上层输出和目标之间的残差即可。
resnet其实无法真正的实现梯度消失,这里面有很强的先验假设,并且resnet真正起作用的层只在中间,深层作用比较小(到了深层就是恒等映射了),feature存在利用不足的现象,add的方式阻碍了梯度和信息的流通。
L1正则可以使少数权值较大,多数权值为0,得到稀疏的权值;L2正则会使权值都趋近于0但非零,得到平滑的权值;https://zhuanlan.zhihu.com/p/35356992
目前的权重初始化分为三类:
初始化,说白了就是构建一个平滑的局部几何空间从而使得优化更简单xavier分布解析:
假设使用的是sigmoid函数。当权重值(值指的是绝对值)过小,输入值每经过网络层,方差都会减少,每一层的加权和很小,在sigmoid函数0附件的区域相当于线性函数,失去了DNN的非线性性。当权重的值过大,输入值经过每一层后方差会迅速上升,每层的输出值将会很大,此时每层的梯度将会趋近于0. xavier初始化可以使得输入值x 方差经过网络层后的输出值y方差不变。
在pytorch中默认的权重初始化方式是何凯明的那个,举个例子:
差不多这几个懂了就OK。
可以看老潘的这篇文章:
那么,如何用softmax和sigmoid来做多类分类和多标签分类呢?
1、如何用softmax做多分类和多标签分类 现假设,神经网络模型最后的输出是这样一个向量logits=[1,2,3,4], 就是神经网络最终的全连接的输出。这里假设总共有4个分类。用softmax做多分类的方法:
2、如何用sigmoid做多标签分类 sigmoid一般不用来做多类分类,而是用来做二分类的,它是将一个标量数字转换到[0,1]之间,如果大于一个概率阈值(一般是0.5),则认为属于某个类别,否则不属于某个类别。那么如何用sigmoid来做多标签分类呢?其实就是针对logits中每个分类计算的结果分别作用一个sigmoid分类器,分别判定样本是否属于某个类别。同样假设,神经网络模型最后的输出是这样一个向量logits=[1,2,3,4], 就是神经网络最终的全连接的输出。这里假设总共有4个分类。
为了消除数据特征之间的量纲影响在实际应用中,通过梯度下降法求解的模型通常是需要数据归一化的,包括线性回归、逻辑回归、支持向量机、神经网络等,但是决策模型不是很适用。
首先,假设你知道训练集和测试集的关系。简单来讲是我们要在训练集上学习一个模型,然后拿到测试集去用,效果好不好要根据测试集的错误率来衡量。但很多时候,我们只能假设测试集和训练集的是符合同一个数据分布的,但却拿不到真正的测试数据。这时候怎么在只看到训练错误率的情况下,去衡量测试错误率呢?
由于训练样本很少(至少不足够多),所以通过训练集得到的模型,总不是真正正确的。(就算在训练集上正确率100%,也不能说明它刻画了真实的数据分布,要知道刻画真实的数据分布才是我们的目的,而不是只刻画训练集的有限的数据点)。而且,实际中,训练样本往往还有一定的噪音误差,所以如果太追求在训练集上的完美而采用一个很复杂的模型,会使得模型把训练集里面的误差都当成了真实的数据分布特征,从而得到错误的数据分布估计。这样的话,到了真正的测试集上就错的一塌糊涂了(这种现象叫过拟合)。但是也不能用太简单的模型,否则在数据分布比较复杂的时候,模型就不足以刻画数据分布了(体现为连在训练集上的错误率都很高,这种现象较欠拟合)。过拟合表明采用的模型比真实的数据分布更复杂,而欠拟合表示采用的模型比真实的数据分布要简单。
在统计学习框架下,大家刻画模型复杂度的时候,有这么个观点,认为Error = Bias + Variance。这里的Error大概可以理解为模型的预测错误率,是有两部分组成的,一部分是由于模型太简单而带来的估计不准确的部分(Bias),另一部分是由于模型太复杂而带来的更大的变化空间和不确定性(Variance)。
所以,这样就容易分析朴素贝叶斯了。它简单的假设了各个数据之间是无关的,是一个被严重简化了的模型。所以,对于这样一个简单模型,大部分场合都会Bias部分大于Variance部分,也就是说高偏差而低方差。
在实际中,为了让Error尽量小,我们在选择模型的时候需要平衡Bias和Variance所占的比例,也就是平衡over-fitting和under-fitting。
https://zhuanlan.zhihu.com/p/42122107
https://zhuanlan.zhihu.com/p/59640437
传统的目标检测一般分为以下几个步骤:
经典的结构:
传统方法的缺点:
可以看学习OpenCV第三版中的相关内容,搜索erode、dilation
在网络结构进行特征融合的时候,双线性插值的方式比转置卷积要好一点。因为转置卷积有一个比较大的问题就是如果参数配置不当,很容易出现输出feature map中带有明显棋盘状的现象。
双线性插值也分为两类:
一般来说,使用align_corners=True可以保证边缘对齐,而使用align_corners=False则会导致边缘突出的情况。这个讲的非常好:
代码实现的讲解:
为了避免梯度爆炸而做出的改进,注意要和提前终止区别开来。(提前终止是一种正则化方法,因为当训练有足够能力表示甚至会过拟合的大模型时,训练误差会随着时间的推移逐渐降低但验证集的误差会再次上升。这意味着只要我们返回使验证集误差最低的参数设置即可)第一种做法很容易理解,就是先设定一个 gradient 的范围如 (-1, 1), 小于 -1 的 gradient 设为 -1, 大于这个 1 的 gradient 设为 1.
实现卷积一般用的是im2col的形式,但是面试中我们简单实现一个滑窗法就行了。比如:用3x3的卷积核(滤波盒)实现卷积操作。NCNN中在PC端卷积的源码也是这样的。
参考:
看看Pytorch的源码与caffe的源码,都是将卷积计算转化为矩阵运算,im2col,然后gemm。https://blog.csdn.net/mrhiuser/article/details/52672824
https://cloud.tencent.com/developer/article/1363619
1x1卷积可以改变上一层网络的通道数目。卷积核大于1x1,意味着提特征需要邻域信息。
所以对懒人来说,最优核的尺寸的期望是正方形。至于
注意,resnet中是先降维再升维,而mobilenetv2中是先升维后降维(所以称之为inversed)。
很简单但是也很容易错的问题:
依据采用动态计算或是静态计算的不同,可以将这些众多的深度学习框架划分成两大阵营,当然也有些框架同时具有动态计算和静态计算两种机制(比如 MxNet 和最新的 TensorFlow)。动态计算意味着程序将按照我们编写命令的顺序进行执行。这种机制将使得调试更加容易,并且也使得我们将大脑中的想法转化为实际代码变得更加容易。而静态计算则意味着程序在编译执行时将先生成神经网络的结构,然后再执行相应操作。从理论上讲,静态计算这样的机制允许编译器进行更大程度的优化,但是这也意味着你所期望的程序与编译器实际执行之间存在着更多的代沟。这也意味着,代码中的错误将更加难以发现(比如,如果计算图的结构出现问题,你可能只有在代码执行到相应操作的时候才能发现它)。尽管理论上而言,静态计算图比动态计算图具有更好的性能,但是在实践中我们经常发现并不是这样的。
这个可以看CS231n中的第九课以及
正式总结下:
shufflenet:https://blog.csdn.net/u011974639/article/details/79200559
正太分布:https://blog.csdn.net/yaningli/article/details/78051361
MaxPool导致的训练震荡(通过在MaxPool之后加上L2Norm)//mp.weixin.qq.com/s/QR-KzLxOBazSbEFYoP334Q
https://zhuanlan.zhihu.com/p/64510297
感受野计算有两个公式,一个普通公式一个通项公式:
需要注意,卷积和池化都可以增加感受野。
http://zike.io/posts/calculate-receptive-field-for-vgg-16/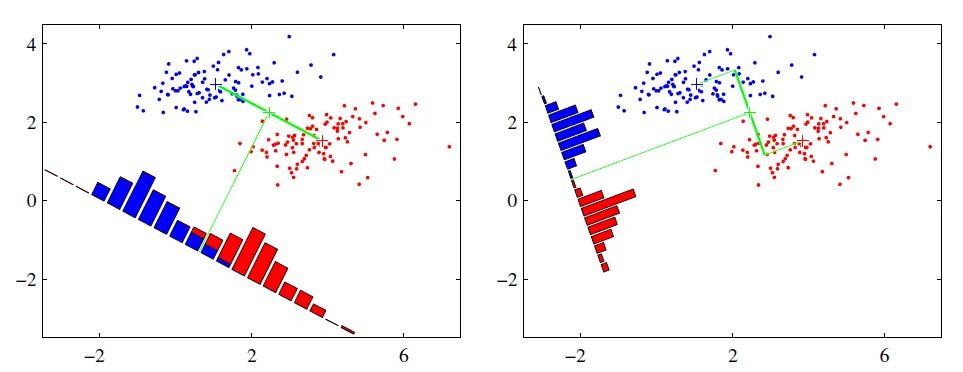 PCA和LDA
PCA和LDA
KNN K近邻
二维高斯核函数
`def gaussian_2d_kernel(kernel_size = 3,sigma = 0):kernel = np.zeros([kernel_size,kernel_size]) center = kernel_size // 2
if sigma == 0: sigma = ((kernel_size-1)*0.5 - 1)*0.3 + 0.8
s = 2*(sigma**2) sum_val = 0 for i in range(0,kernel_size): for j in range(0,kernel_size): x = i-center y = j-center kernel[i,j] = np.exp(-(x**2+y**2) / s) sum_val += kernel[i,j] #/(np.pi * s) sum_val = 1/sum_val return kernel*sum_val
`
训练采样方法
Kmean和GMM原理、区别、应用场景
如何在多台计算机上做kmeans
KNN算法以及流程
无监督学习和有监督学习的区别
逻辑回归与SVM区别
bagging boosting 和 提升树
SVM
凸集、凸函数、凸优化
为什么深度学习中的图像分割要先编码后解码
(全局)平均池化average pooling和(全局)最大池化max pooling的区别
平均池化的一个动机是每个空间位置具有用于期望特征的检测器,并且通过平均每个空间位置,其行为类似于平均输入图像的不同平移的预测(有点像数据增加)。Resnet不是采用传统的完全连通层进行CNN分类,而是直接从最后一个mlp转换层输出特征图的空间平均值,作为通过全局平均合并层的类别置信度,然后将得到的矢量输入到 softmax层。相比之下,Global average更有意义且可解释,因为它强制实现了feature和类别之间的对应关系,这可以通过使用网络的更强大的本地建模来实现。此外,完全连接的层易于过拟合并且严重依赖于 dropout 正则化,而全局平均池化本身就是起到了正则化作用,其本身防止整体结构的过拟合。
全连接的作用,与1x1卷积层的关系
1*1的卷积,那么结果的大小为500*500*20。
concat与add(sum)的区别
SSD怎么改动变成FasterRCNN
反向传播的原理
GD、SGD、mini batch GD的区别
偏差、方差
为什么会梯度爆炸,如何防止
分布式训练,多卡训练
精确率和召回率以及PR曲线
空洞卷积
数据不好怎么办,数据不均衡怎么处理、只有少量带标签怎么处理
训练过程中需要过拟合情况怎么办
正则化
BN层和L2正则化一起有什么后果
ROIPooling和ROIAlign的区别
自己实现图像增强算法
图像分类的tricks
消融实验(Ablation experiment)
手撸NMS与soft-NMS
逻辑回归和线性回归
 而逻辑回归的原型:对数几率回归:逻辑回归和对数几率回归是一样的,通过变形就可以得到,另外逻辑回归使用极大似然概率进行估计。简单总结:
而逻辑回归的原型:对数几率回归:逻辑回归和对数几率回归是一样的,通过变形就可以得到,另外逻辑回归使用极大似然概率进行估计。简单总结:
什么是attention,有哪几种
深度学习的线性和非线性
梯度消失和梯度爆炸的问题

Batch-norm层的作用


BN跨卡训练怎么保证相同的mean和var
如何实现SyncBN
ResNet为什么好用
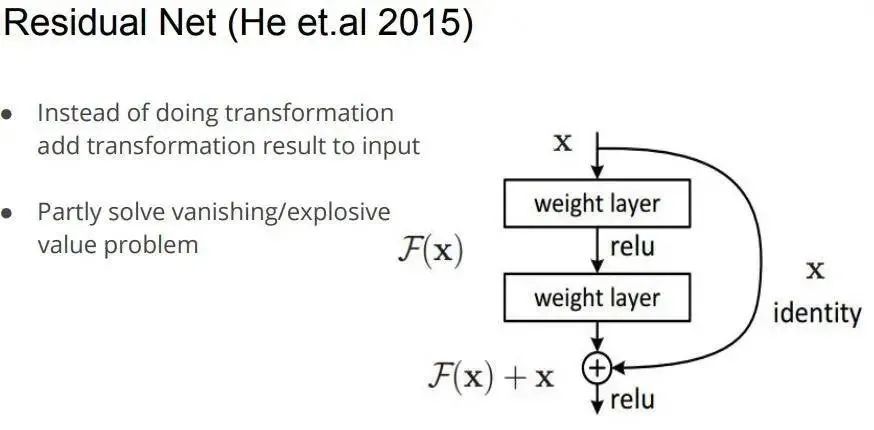
Resnet的缺点
L1范数和L2范数 应用场景
网络初始化有哪些方式,他们的公式初始化过程
resnet中权重的初始化
for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') elif isinstance(m, nn.BatchNorm2d): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,# so that the residual branch starts with zeros, and each residual block behaves like an identity.# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677if zero_init_residual: for m in self.modules(): if isinstance(m, Bottleneck): nn.init.constant_(m.bn3.weight, 0) elif isinstance(m, BasicBlock): nn.init.constant_(m.bn2.weight, 0)
求解模型参数量
def model_info(model): # Plots a line-by-line description of a PyTorch model n_p = sum(x.numel() for x in model.parameters()) # number parameters n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients print('
%5s %50s %9s %12s %20s %12s %12s' % ('layer', 'name', 'gradient', 'parameters', 'shape', 'mu', 'sigma')) for i, (name, p) in enumerate(model.named_parameters()): name = name.replace('module_list.', '') print('%5g %50s %9s %12g %20s %12.3g %12.3g' % ( i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std())) print('Model Summary: %d layers, %d parameters, %d gradients' % (i + 1, n_p, n_g))print('ModelSize:%fMBparameters,%fMBgradients
'%(n_p*4/1e6,n_g*4/1e6))
卷积计算量
多标签和多分类
tf.argmax(tf.softmax(logits))首先用softmax将logits转换成一个概率分布,然后取概率值最大的作为样本的分类,这样看似乎,tf.argmax(logits)同样可以取得最大的值,也能得到正确的样本分类,这样的话softmax似乎作用不大.那么softmax的主要作用其实是在计算交叉熵上,首先样本集中y是一个one-hot向量,如果直接将模型输出logits和y来计算交叉熵,因为logits=[1,2,3,4],计算出来的交叉熵肯定很大,这种计算方式不对,而应该将logits转换成一个概率分布后再来计算,就是用tf.softmax(logits)和y来计算交叉熵,当然我们也可以直接用tensorflow提供的方法sofmax_cross_entropy_with_logits来计算 这个方法传入的参数可以直接是logits,因为这个根据方法的名字可以看到,方法内部会将参数用softmax进行处理,现在我们取的概率分布中最大的作为最终的分类结果,这是多分类。我们也可以取概率的top几个,作为最终的多个标签,或者设置一个阈值,并取大于概率阈值的。这就用softmax实现了多标签分类。tf.sigmoid(logits)sigmoid应该会将logits中每个数字都变成[0,1]之间的概率值,假设结果为[0.01, 0.05, 0.4, 0.6],然后设置一个概率阈值,比如0.3,如果概率值大于0.3,则判定类别符合,那这里,样本会被判定为类别3和类别4都符合。
数据的输入为什么要归一化
为什么说朴素贝叶斯是高偏差低方差?
Canny边缘检测,边界检测算法有哪些
传统的目标检测
腐蚀膨胀、开运算闭运算
一些滤波器
Resize双线性插值
gradient clipping 梯度裁剪

实现一个简单的卷积
`/*输入:imput[IC][IH][IW]IC = input.channelsIH = input.heightIW = input.width卷积核: kernel[KC1][KC2][KH][KW]KC1 = OCKC2 = ICKH = kernel.heightKW = kernel.width输出:output[OC][OH][OW]OC = output.channelsOH = output.heightOW = output.width其中,padding = VALID,stride=1,OH = IH - KH + 1OW = IW - KW + 1也就是先提前把Oh和Ow算出来,然后将卷积核和输入数据一一对应即可*/for(int ch=0;ch<output.channels;ch++){for(int oh=0;oh<output.height;oh++){for(int ow=0;ow<output.width;ow++){float sum=0;for(int kc=0;kc<kernel.channels;kc++){for(int kh=0;kh<kernel.height;kh++){for(int kw=0;kw<kernel.width;kw++){sum += input[kc][oh+kh][ow+kw]*kernel[ch][kc][kh][kw];}}}//if(bias) sum +=bias[]output[ch][oh][ow]=sum;}}}`
卷积的过程
转置卷积的计算过程
1*1的卷积核有什么用,3*3的卷积核和一个1*3加一个3*1的有什么区别1*n和n*1,它们一般是搭配使用的,从而实现n*n卷积核的感受野,可以在减少参数的同时增加层数,在CNN的较高层中使用可以带来一定的优势。卷积核并非都是正方形的,还可以是矩形,比如3*5,在文本检测和车牌检测当中就有应用,这种设计主要针对文本行或者车牌的形状,能更好的学习特征。其实我觉得方形矩形影响不大,网络的学习能力是非常强的。当然我们也可以学习卷积的形状,类似于deformable convolution,老潘后续会讲下。
ResNet中bottlenet与mobilenetv2的inverted结构对比
卷积特征图大小的计算

动态图和静态图的区别
历年来所有的网络
depthwise Separable Conv让人眼前一亮。https://www.jianshu.com/p/4708a09c4352
一些统计知识
关于如何训练(训练过程中的一些问题)
全连接层的好伴侣:空间金字塔池化(SPP)
感受野计算

-
算法
+关注
关注
23文章
4608浏览量
92855 -
机器学习
+关注
关注
66文章
8412浏览量
132600 -
深度学习
+关注
关注
73文章
5503浏览量
121130
原文标题:机器学习、深度学习面试知识点汇总
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【面试题】人工智能工程师高频面试题汇总:机器学习深化篇(题目+答案)
人工智能工程师高频面试题汇总——机器学习篇

GPU深度学习应用案例
AI大模型与深度学习的关系
深度学习中的时间序列分类方法
深度学习中的无监督学习方法综述
深度学习与nlp的区别在哪
人工智能、机器学习和深度学习是什么
TensorFlow与PyTorch深度学习框架的比较与选择
深度学习模型训练过程详解
深度学习与传统机器学习的对比
为什么深度学习的效果更好?







 工商网监
工商网监
评论