 带宽进步推动 PCIe 标准
带宽进步推动 PCIe 标准
Peripheral Component Interconnect Express (PCIe) 总线标准有很多依赖。或者更准确地说,需要容纳大量流经它的数据。
相对成熟的非易失性内存快速 (NVMe) 协议以及刚刚起步但快速发展的计算快速链路 (CXL) 都在利用无处不在的 PCIe,预计 6.0 将于 2021 年底广泛发布。
Microchip Technology 数据中心业务部主管 Mark Orthodoxou 表示,PCIe 的价值在于它无处不在,因为它可以跨 CPU 互操作,而且它的开放性允许围绕它建立一个生态系统。他说 PCIe 的缺点源于它随着时间的推移变得相当复杂,但这些挑战是可以克服的,因为有很多可授权的 IP 可以利用。
点击查看完整大小的图片
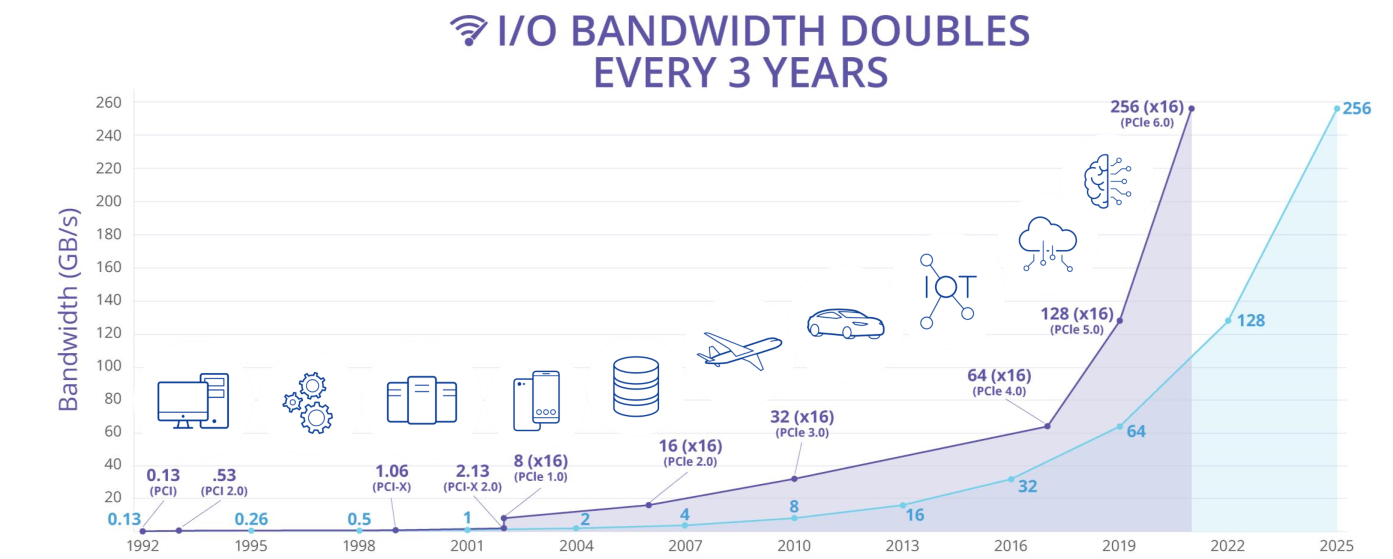
随着移动和汽车领域出现新机遇,PCIe I/O 总线规范预计将继续每三年更新一次,NVMe 和 CXL 会利用它提高存储和内存性能访问。(由 PCI-SIG 提供)
缺点之一是当今存在的某些特性和功能甚至在 PCIe 的早期阶段都没有想到。Orthodoxou 说,随着新应用程序的映射,出现了意想不到的问题。一个示例是以热插拔 NVMe SSD 的形式从服务器中移除设备。“它不是作为热插拔接口设计的,所以需要做一些工作来处理这样的事情。随着时间的推移,PCIe 变得越来越复杂,因为人们找到了不同的使用方式。” 他说,即使出现了利用 PCIe 的新用途,例如 CXL,也没有任何内在限制创新。“最终,它是一种仅存在于 PCIe 电气设备上的协议。”
虽然 CXL 有可能比其他设备更早地利用 PCIe 6.0,但 Orthodoxou 表示,CXL 联盟可能需要尽可能多的时间来整理 CXL 需要什么样的外观来支持需要最新和最好的 PCIe 的用例. “如果我们有一些不同的电气接口可用,CXL 不会移动得更快。”
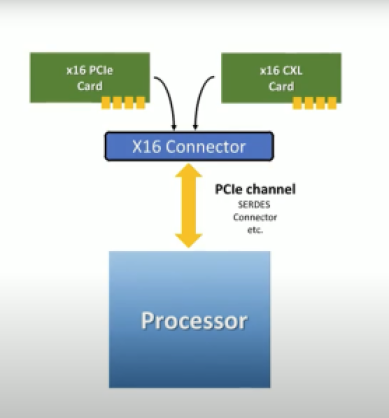
CXL 使用灵活的处理器端口,可以自动协商到标准 PCIe 事务协议或备用 CXL 事务协议。(来源:CXL)
Microchip 在不同的业务部门拥有许多产品,这些产品利用了 PCIe,包括工业、汽车和数据中心市场,包括 PCIe 交换机和 NVMe 控制器。“PCIe 为我们创造了大量的市场机会,”他说。然而,除了其 CXL Retimer 之外,该公司还没有宣布任何 CXL 产品,但它在财团中很活跃。
与此同时,IDC 固态存储和支持技术研究副总裁 Jeff Janukowicz 指出,NVMe 的采用已经将近十年,但去年标志着一个拐点,超过一半的企业在闪存 SSD 上的支出是 NVMe PCIe。“实现这一转变需要一些时间,但我们看到围绕 PCIe 的许多好处开始显现。” 他说NVMe 2.0 的发布将允许围绕 PCIe 的进一步发展,以及围绕硬盘驱动器无法实现的外形尺寸的创新。“从硬件的角度来看,我们开始摆脱一些限制。”
Janukowicz 表示,虽然 PCIe 已成为一项基础技术,但 CXL 等协议的出现反映了工作负载日益多样化。“有很多创新试图满足不同的环境,而你开始看到一些兴趣是围绕 CXL 之类的东西。” 虽然 NVMe 的构建考虑了固态存储,但他表示 CXL 是围绕内存而非存储构建的,以推动更高的性能和更低的复杂性,并包括内存连接设备、内存扩展和加速器。
Janukowicz 说,与 PCIe 一样,价值主张的很大一部分是它是一个开放标准,任何人都可以参与创建解决工作负载方向的解决方案。“我们看到对扩展内存池以支持某些下一代工作负载的兴趣越来越大,无论是内存类型的应用程序和内存数据库,还是人工智能 (AI) 和机器学习等新兴应用程序。 ”

史蒂夫·伍
但并不是每个人都认为 PCIe 的开放标准方法是唯一的选择。Nvidia 选择开发自己的 PCIe 替代品 NVLink。用于近距离半导体通信的基于有线的通信协议于 2014 年首次推出,可用于 CPU 和 GPU 之间以及仅在 GPU 之间的处理器系统中的数据和控制代码传输。
Nvidia 产品管理高级总监 Paresh Kharya 表示,虽然 PCIe 可能无处不在,但其速度远远低于 Nvidia 在自己的服务器中为人工智能和高性能计算等工作负载提供的速度。“对计算能力的需求不断增加。扩展计算的方法之一是让多个 GPU 协同工作。” NVLink 提供快速且可扩展的互连,因此 Nvidia GPU 可以作为巨型加速器协同工作。他说,当它首次推出时,NVLink 提供的带宽是 PCIe 3.0 的五倍,现在提供每秒 600 GB 的双向带宽,几乎是主导 PCIe 4.0 的 10 倍。
虽然 NVLink 是 Nvidia 的专有技术,但其 GPU 仍然支持 PCIe。“这就是我们今天连接到 CPU 的方式,”Kharya 说。他说,虽然 IBM 等其他供应商已与 Nvidia 合作,将 NVLink 整合到他们的处理器中,但总的来说,这种互连主要用于使用 Nvidia GPU 加速工作负载。Nvidia 为已经具有 NVLink 功能的服务器提供基板和主板,以加速更广泛的生态系统的采用,并且世界上一些最快的超级计算机使用 NVLink。
Kharya 表示,NVLink 使 Nvidia 能够快速创新并不断提高其客户的性能。“我们希望继续以尽可能快的速度发展 NLink 链接。” 他说,但它也积极与 CXL 社区合作并参与 PCIe 标准的推进,尽管 Nvidia 认为 NVLink 是当今提供的带宽的明显赢家。“我们真的希望 PCIe 标准能够尽快发展。”
Janukowicz 表示,定制方法确实有其优点,并围绕特定环境的性能延迟、成本或功耗等某些指标进行了优化,但开放标准仅在为市场带来一些规模经济方面提供了很多好处。“从历史上看,开放标准对于推动市场确实是必要的。” 他说,客户总是不愿与特定的供应商锁定,尤其是考虑到当今大流行带来的供应链挑战。“它强调了一些灵活性的必要性,你往往会在更多的开放环境中获得这种灵活性,在这种环境中,你当然可以双源或有多种选择。”
与此同时,随着 CXL 的发展,对 PCIe 的更新正在继续快速进行。Rambus 研究员 Steve Woo 表示,CXL 是数据如何推动架构发展的一个例子,而高带宽内存 (HBM) 和图形 DDR (GDDR) 标准的发展速度比以往更快,以响应数据和这些架构的重要性。“像 CXL 这样的重要驱动因素将继续推动行业提高 PCIe 速度,”他说。“它可靠,人们理解它,它在这个行业已经存在了一段时间,并且值得信赖。”
亚内斯
Woo 说,数据移动已经开始成为瓶颈,而不是内存或计算。随着图形分辨率和帧速率的提高,过去是图形市场推动 PCIe 变得更快。但他说,这些数据速率与今天的节奏相去甚远。数据量每两年翻一番,这意味着管道的性能必须跟上。
PCIe 6.0 承诺做到这一点。在 5 月下旬由定义 PCIe I/O 总线规范和相关外形尺寸的组织 PCI Express 特别兴趣小组 (PCI-SIG) 的网络研讨会更新中,最新的迭代被描述为自 PCIe 迁移以来最显着的飞跃2.0 到 PCIe 3.0。即将到来的更新使其数据传输速率翻倍,并提供比其前身更高的信号速率和更严格的信号完整性要求。尽管 PCI Express 0.71 规范草案已在 7 月初发布供会员审查,但预计将在今年年底正式发布。预计草案 0.9 将遵循并对任何最终问题进行为期两个月的审查。
PCIe 6.0 实现 PAM4 信令,允许它在串行通道上将更多位打包到相同的时间量中包括低延迟前向纠错 (FEC) 以及其他机制,以提高带宽效率和提高可靠性。它还通过应用 AES-GCM 对整个 TLP 进行加密和经过身份验证的保护来提供 TLP 的完整性和数据加密 (IDE)。单个 PCIe 6.0 x16 可支持 800G 以太网。这一最新迭代针对高带宽应用程序,例如云、人工智能和机器学习以及边缘计算。
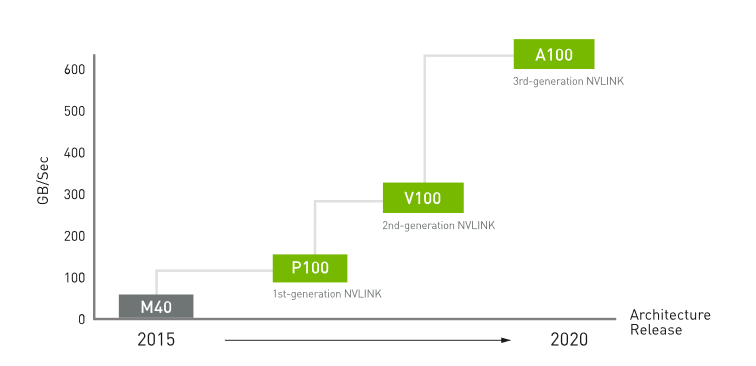
Nvidia 七年前选择开发自己的 PCIe 替代品。在 NVIDIA A100 中,NVLink 将 GPU 间通信带宽提高了一倍,几乎是 PCIe Gen4 带宽的 10 倍。(由英伟达提供)
它的完成将在 PCIe 5.0 设备预计开始进入企业市场之际完成。该规范于 2019 年 5 月发布,将其前身的带宽增加了一倍,同时保持与所有 PCIe 代的向后兼容性。PCIe 5.0 还具有电气变化,以提高连接器的信号完整性和机械性能。
PCI-SIG 总裁兼董事会主席 Al Yanes 表示,该组织的成员继续“蓬勃发展”,在全球范围内拥有近 900 名成员,重点是 PCIe 在移动领域采用的全系列设备以及汽车行业的大量兴趣。“我们成立了一个工作组并获得了很多参与,所以这就是我们的新目标行业。”
他预计每三年或更短时间更新一次,并继续关注合规性和向后兼容性,这两者都是总线标准成功秘诀的重要组成部分。
审核编辑 黄昊宇
-
带宽
+关注
关注
3文章
926浏览量
40913 -
PCIe
+关注
关注
15文章
1235浏览量
82597
发布评论请先 登录
相关推荐
PCIe数据传输协议详解
如何选择适合的PCIe配置
PCIe 4.0与3.0的区别 PCIe设备的故障排除方法
pcie扩展槽的使用技巧
pcie 4.0与pcie 5.0的区别
pcie带宽对计算性能的影响
PCIe连接器的类型和规格
如何测试PCIe插槽的速度
PCIe 4.0与PCIe 3.0的性能对比
家用电脑的PCIe接口如何设计PCB?

家用电脑的PCIe接口如何设计PCB?
FPGA的PCIE接口应用需要注意哪些问题
什么是PCIe?PCIe有什么用途?什么是PCIe通道
PCIe Tx/Rx 物理层信号完整性测试方法详解

PCIE相关概念和带宽计算方法






 工商网监
工商网监
评论