 Edge AI 挑战内存技术
Edge AI 挑战内存技术
随着边缘人工智能的兴起,对存储系统提出了一系列新要求。当今的内存技术能否满足这一具有挑战性的新应用的严格要求,新兴内存技术对边缘 AI 的长期承诺是什么?
首先要意识到的是,没有标准的“边缘人工智能”应用;最广泛解释的边缘涵盖了云外所有支持人工智能的电子系统。这可能包括“近边缘”,通常涵盖企业数据中心和本地服务器。
更进一步的是用于自动驾驶的计算机视觉等应用。用于制造的网关设备执行 AI 推理以检查生产线上产品的缺陷。电线杆上的 5G“边缘盒”分析智能城市应用(如交通管理)的视频流。5G 基础设施在边缘使用人工智能来实现复杂但高效的波束形成算法。
在“远端”,人工智能在手机等设备中得到支持——想想 Snapchat 过滤器——在将结果发送到另一个网关设备之前,工厂中执行传感器融合的设备和物联网传感器节点的语音控制。
内存在边缘 AI 系统中的作用——存储神经网络权重、模型代码、输入数据和中间激活——对于大多数 AI 应用程序来说都是相同的。必须加速工作负载以最大化 AI 计算能力以保持高效,因此对容量和带宽的要求通常很高。然而,特定应用的需求是多种多样的,可能包括尺寸、功耗、低电压操作、可靠性、热/冷却考虑和成本。
边缘数据中心
边缘数据中心是一个关键的边缘市场。用例范围从医学成像、研究和复杂的金融算法,其中隐私阻止上传到云。另一个是自动驾驶汽车,延迟会阻止它。
这些系统使用与其他应用程序中的服务器相同的内存。
“在开发和训练 AI 算法的应用中,将低延迟 DRAM 用于快速、字节级的主内存非常重要,”内存产品设计师和开发商 Smart Modular Technologies 的解决方案架构师 Pekon Gupta 说。“大型数据集需要高容量 RDIMM 或 LRDIMM。系统加速需要 NVDIMM——我们将它们用于写入缓存和检查点,而不是速度较慢的 SSD。”

佩孔古普塔
将计算节点定位在靠近最终用户的位置是电信运营商采用的方法。
“我们看到了使这些[电信] 边缘服务器更有能力运行复杂算法的趋势,”Gupta 说。因此,“服务提供商正在使用 RDIMM、LRDIMM 和 NVDIMM 等高可用性持久内存等设备为这些边缘服务器增加更多内存和处理能力。”
Gupta 认为英特尔 Optane 是该公司的 3D-Xpoint 非易失性内存,其特性介于 DRAM 和闪存之间,是服务器 AI 应用程序的良好解决方案。
“Optane DIMM 和 NVDIMM 都被用作 AI 加速器,”他说。“NVDIMM 为 AI 应用程序加速提供了非常低延迟的分层、缓存、写入缓冲和元数据存储功能。Optane 数据中心 DIMM 用于内存数据库加速,其中数百 GB 到 TB 的持久内存与 DRAM 结合使用。尽管这些都是用于 AI/ML 加速应用程序的持久内存解决方案,但它们有不同且独立的用例。”
英特尔 Optane 产品营销总监 Kristie Mann 告诉EE Times , Optane正在服务器 AI 领域获得应用。

英特尔的克里斯蒂曼
“我们的客户现在已经在使用 Optane 持久内存来支持他们的 AI 应用程序,”她说。“他们正在成功地为电子商务、视频推荐引擎和实时财务分析应用提供支持。由于可用容量的增加,我们看到了向内存应用程序的转变。”
DRAM 的高价格使 Optane 越来越成为有吸引力的替代品。配备两个 Intel Xeon Scalable 处理器和 Optane 持久内存的服务器可以为需要大量数据的应用程序容纳多达 6 TB 的内存。
“DRAM 仍然是最受欢迎的,但从成本和容量的角度来看,它有其局限性,”Mann 说。“由于其成本、容量和性能优势,Optane 持久内存和 Optane SSD 等新的内存和存储技术正在 [新兴] 作为 DRAM 的替代品。Optane SSD 是特别强大的缓存 HDD 和 NAND SSD 数据,可以持续为 AI 应用程序提供数据。”
她补充说,Optane 还优于目前尚未完全成熟或可扩展的其他新兴存储器。

英特尔傲腾 200 系列模块。英特尔表示,Optane 目前
已用于为 AI 应用程序提供动力。(来源:英特尔)
GPU 加速
对于高端边缘数据中心和边缘服务器应用程序,GPU 等 AI 计算加速器正在获得关注。除 DRAM 外,这里的内存选择还包括GDDR,一种用于为高带宽 GPU 供电的特殊 DDR SDRAM,以及HBM,一种相对较新的芯片堆叠技术,它将多个内存芯片与 GPU 本身放在同一个封装中。
两者都是为 AI 应用程序所需的极高内存带宽而设计的。
对于最苛刻的 AI 模型训练,HBM2E 提供 3.6 Gbps 并提供 460 GB/s 的内存带宽(两个 HBM2E 堆栈提供接近 1 TB/s)。这是可用的性能最高的内存之一,在最小的区域内具有最低的功耗。GPU 领导者Nvidia 在其所有数据中心产品中都使用 HBM 。
Rambus IP 内核产品营销高级总监 Frank Ferro 表示,GDDR6 还用于边缘的 AI 推理应用程序。Ferro 表示,GDDR6 可以满足边缘 AI 推理系统的速度、成本和功耗要求。例如,GDDR6 可以提供 18 Gbps 并提供 72 GB/s。拥有四个 GDDR6 DRAM 可提供接近 300 GB/s 的内存带宽。
“GDDR6 用于 AI 推理和 ADAS 应用,”Ferro 补充道。
在将 GDDR6 与 LPDDR(从 Jetson AGX Xavier 到 Jetson Nano 的大多数非数据中心边缘解决方案的 Nvidia 方法)进行比较时,Ferro 承认 LPDDR 适用于边缘或端点的低成本 AI 推理。
“LPDDR 的带宽限制为 LPDDR4 的 4.2 Gbps 和 LPDDR5 的 6.4 Gbps,”他说。“随着内存带宽需求的增加,我们将看到越来越多的设计使用 GDDR6。这种内存带宽差距有助于推动对 GDDR6 的需求。”

Rambus 的弗兰克·费罗
尽管设计为与 GPU 一起使用,但其他处理加速器可以利用 GDDR 的带宽。Ferro 重点介绍了 Achronix Speedster7t,这是一款基于 FPGA 的 AI 加速器,用于推理和一些低端训练。
“在边缘 AI 应用中,HBM 和 GDDR 内存都有空间,”Ferro 说。HBM“将继续用于边缘应用。对于 HBM 的所有优点,由于 3D 技术和 2.5D 制造,成本仍然很高。鉴于此,GDDR6 是成本和性能之间的良好权衡,尤其是对于网络中的 AI 推理。”
HBM 用于高性能数据中心 AI ASIC,例如Graphcore IPU。虽然它提供了出色的性能,但对于某些应用来说,它的价格可能很高。
高通公司就是使用这种方法的公司之一。其 Cloud AI 100 针对边缘数据中心、5G“边缘盒”、ADAS/自动驾驶和 5G 基础设施中的 AI 推理加速。
“与 HBM 相比,使用标准 DRAM 对我们来说很重要,因为我们希望降低材料成本,”高通计算和边缘云部门总经理 Keith Kressin 说。“我们希望使用可以从多个供应商处购买的标准组件。我们有客户想要在芯片上做所有事情,我们也有客户想要跨卡。但他们都希望保持合理的成本,而不是选择 HBM 甚至更奇特的内存。
“在训练中,”他继续说,“你有可以跨越[多个芯片]的非常大的模型,但对于推理[Cloud AI 100的市场],很多模型都更加本地化。”
遥远的边缘
在数据中心之外,边缘人工智能系统通常专注于推理,但有一些明显的例外,例如联邦学习和其他增量训练技术。
一些用于功耗敏感应用的 AI 加速器使用内存进行 AI 处理。基于多维矩阵乘法的推理适用于具有用于执行计算的存储单元阵列的模拟计算技术。使用这种技术,Syntiant 的设备专为消费电子产品的语音控制而设计,而Gyrfalcon 的设备已被设计成智能手机,用于处理相机效果的推理。
在另一个例子中,智能处理单元专家Mythic使用闪存单元的模拟操作在单个闪存晶体管上存储一个 8 位整数值(一个权重参数),使其比其他内存计算技术更密集。编程的闪存晶体管用作可变电阻器;输入作为电压提供,输出作为电流收集。结合 ADC 和 DAC,结果是一个高效的矩阵乘法引擎。
Mythic 的 IP 在于补偿和校准技术,可消除噪声并实现可靠的 8 位计算。
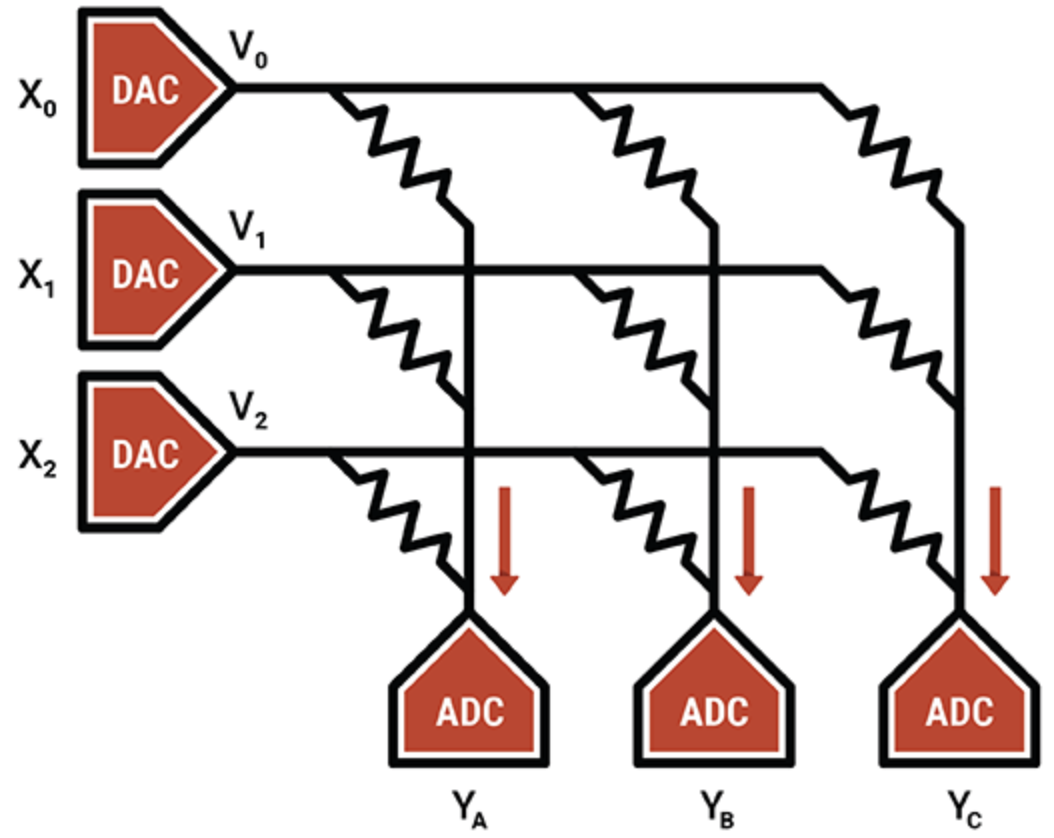
Mythic 使用闪存晶体管阵列来制造密集的乘法累加引擎(来源:Mythic)
除了内存计算设备外,ASIC 在特定的边缘领域也很受欢迎,特别是低功耗和超低功耗系统。ASIC 的内存系统使用多种内存类型的组合。分布式本地 SRAM 是最快、最节能的,但不是很节省面积。在芯片上拥有一个大容量 SRAM 的面积效率更高,但会带来性能瓶颈。片外 DRAM 更便宜,但耗电量更大。
Flex Logix 的首席执行官 Geoff Tate 表示,要为其 InferX X1 在分布式 SRAM、大容量 SRAM 和片外 DRAM 之间找到适当的平衡,需要进行一系列性能模拟。目标是最大化每美元的推理吞吐量——这是芯片尺寸、封装成本和使用的 DRAM 数量的函数。
“最佳点是单个 x32 LPDDR4 DRAM;4K MAC(933MHz 时为 7.5 TOPS);和大约 10MB 的 SRAM,”他说。“SRAM 速度很快,但与 DRAM 相比价格昂贵。使用台积电的16纳米制程技术,1MB的SRAM大约需要1.1mm 2。“我们的 InferX X1 只有 54mm 2,由于我们的架构,DRAM 访问很大程度上与计算重叠,因此没有性能影响。对于具有单个 DRAM 的大型模型来说,这是正确的权衡,至少对于我们的架构而言,”Tate 说。
Flex Logix 芯片将用于需要实时操作的边缘 AI 推理应用,包括以低延迟分析流视频。这包括 ADAS 系统、安全镜头分析、医学成像和质量保证/检查应用程序。
在这些应用中,什么样的 DRAM 将与 InferX X1 一起使用?
“我们认为 LPDDR 将是最受欢迎的:单个 DRAM 提供超过 10GB/秒的带宽……但有足够的位来存储权重/中间激活,”Tate 说。“任何其他 DRAM 都需要更多的芯片和接口,并且需要购买更多未使用的位。”
这里有任何新兴内存技术的空间吗?
“当使用任何新兴存储器时,晶圆成本会急剧上升,而 SRAM 是‘免费的’,除了硅片面积,”他补充道。“随着经济的变化,临界点也可能发生变化,但它会更进一步。”
涌现的记忆
尽管具有规模经济性,但其他内存类型为人工智能应用提供了未来的可能性。
MRAM(磁阻式 RAM)通过由施加电压控制的磁体方向存储每一位数据。如果电压低于翻转位所需的电压,则只有位翻转的可能性。这种随机性是不受欢迎的,因此用更高的电压驱动 MRAM 以防止它发生。尽管如此,一些人工智能应用程序可以利用这种固有的随机性(可以被认为是随机选择或生成数据的过程)。
实验已将其 MRAM 的随机性功能应用于Gyrfalcon 的设备,这是一种将所有权重和激活的精度降低到 1 位的技术。这用于显着降低远端应用程序的计算和功率要求。取决于重新训练网络的方式,可能会在准确性上进行权衡。一般来说,尽管精度降低,神经网络仍可以可靠地运行。
“二值化神经网络的独特之处在于,即使数字为 -1 或 +1 的确定性降低,它们也能可靠地运行,”Spin Memory 产品副总裁 Andy Walker 说。“我们发现,这种 BNN 仍然可以以高准确度运行,因为 [通过] 引入错误写入的内存位的所谓‘误码率’降低了这种确定性。”

自旋记忆的安迪沃克
MRAM 可以在低电压水平下以受控方式自然地引入误码率,在保持精度的同时进一步降低功耗要求。关键是在最低电压和最短时间下确定最佳精度。沃克说,这转化为最高的能源效率。
虽然这项技术也适用于更高精度的神经网络,但它特别适用于 BNN,因为 MRAM 单元有两种状态,与 BNN 中的二进制状态相匹配。
Walker 表示,在边缘使用 MRAM 是另一个潜在应用。
“对于边缘人工智能,MRAM 能够在不需要高性能精度的应用中以较低的电压运行,但提高能效和内存耐用性非常重要,”他说。“此外,MRAM 固有的非易失性允许在没有电源的情况下保存数据。
一种应用是作为所谓的统一存储器,“这种新兴存储器可以作为嵌入式闪存和 SRAM 的替代品,节省芯片面积并避免 SRAM 固有的静态功耗。”
虽然 Spin Memory 的 MRAM 正处于商业应用的边缘,但 BNN 的具体实施最好在基本 MRAM 单元的变体上工作。因此,它仍处于研究阶段。
神经形态 ReRAM
用于边缘 AI 应用的另一种新兴内存是 ReRAM。Politecnico Milan 最近使用 Weebit Nano 的氧化硅 (SiOx) ReRAM 技术进行的研究显示了神经形态计算的前景。ReRAM 为神经网络硬件增加了一个可塑性维度;也就是说,它可以随着条件的变化而发展——神经形态计算中的一个有用品质。
当前的神经网络无法在不忘记他们接受过训练的任务的情况下学习,而大脑可以很容易地做到这一点。在 AI 术语中,这是“无监督学习”,算法在没有标签的数据集上执行推理,在数据中寻找自己的模式。最终的结果可能是支持 ReRAM 的边缘 AI 系统,它可以就地学习新任务并适应周围的环境。
总体而言,内存制造商正在引入提供人工智能应用所需的速度和带宽的技术。各种内存,无论是与 AI 计算在同一芯片上、在同一封装中还是在单独的模块上,都可用于适应许多边缘 AI 应用。
虽然边缘 AI 的内存系统的确切性质取决于应用程序,但 GDDR、HBM 和 Optane 被证明在数据中心中很受欢迎,而 LPDDR 与片上 SRAM 竞争端点应用程序。
新兴记忆正在将其新颖的特性用于研究,旨在推动神经网络超越当今硬件的能力,以实现未来的节能、受大脑启发的系统。
、审核编辑 黄昊宇
-
内存
+关注
关注
8文章
3071浏览量
74414 -
AI
+关注
关注
87文章
31845浏览量
270676 -
EDGE
+关注
关注
0文章
182浏览量
42802
发布评论请先 登录
相关推荐
人工智能和机器学习以及Edge AI的概念与应用
贸泽开售适用于AI和机器学习应用的 AMD Versal AI Edge VEK280评估套件
Google AI Edge Torch的特性详解

AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第二章AI for Science的技术支撑学习心得
使用TI Edge AI Studio和AM62A进行基于视觉AI的缺陷检测

Edge AI工控机的定义、挑选考量与常见应用
凌华智能推出全新AI 边缘服务器MEC-AI7400 (AI Edge Server)系列
美光内存助力未来AI技术更强大、更智能
SiMa.ai推出针对Edge AI调整的SoC
微软Edge浏览器拟推出内存限制器
NanoEdge AI的技术原理、应用场景及优势
【ALINX 技术分享】AMD Versal AI Edge 自适应计算加速平台之 Versal 介绍(2)
【ALINX 技术分享】AMD Versal AI Edge 自适应计算加速平台之准备工作(1)





 工商网监
工商网监
评论