 NVIDIA Triton的概念、特性及主要功能
NVIDIA Triton的概念、特性及主要功能
NVIDIA Triton 推理服务器是 NVIDIA AI 平台的一部分,它是一款开源推理服务软件,可助力标准化模型的部署和执行,并在生产环境中提供快速且可扩展的 AI。
什么是 NVIDIA Triton?
NVIDIA Triton 推理服务器可助力团队在任意基于 GPU 或 CPU 的基础设施上部署、运行和扩展任意框架中经过训练的 AI 模型,进而精简 AI 推理。同时,AI 研究人员和数据科学家可在不影响生产部署的情况下,针对其项目自由选择合适的框架。它还帮助开发者跨云、本地、边缘和嵌入式设备提供高性能推理。
NVIDIA Triton特性
支持多个框架
NVIDIA Triton 推理服务器支持所有主流框架,例如 TensorFlow、NVIDIA TensorRT、PyTorch、MXNet、Python、ONNX、RAPIDS FIL(用于XGBoost、scikit-learn 等)、OpenVINO、自定义 C++ 等。
高性能推理
NVIDIA Triton 支持所有基于 NVIDIA GPU、x86 和 ArmCPU 的推理。它具有动态批处理、并发执行、最优模型配置、模型集成和串流输入等功能,可更大限度地提高吞吐量和利用率。
专为 DevOps 和 MLOps 设计
Triton 与 Kubernetes 集成,可用于编排和扩展,导出 Prometheus 指标进行监控,支持实时模型更新,并可用于所有主流的公有云 AI 和 Kubernetes 平台。它还与许多 MLOps 软件解决方案集成。
各项应用中快速且可扩展的AI
高推理吞吐量
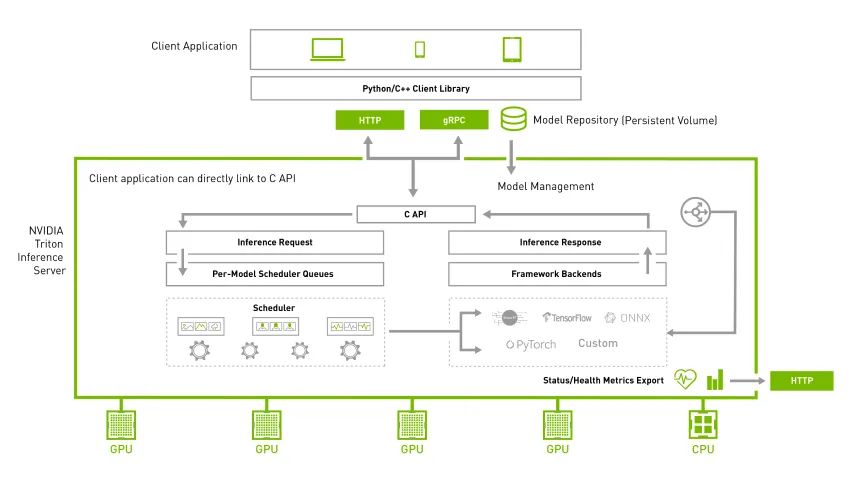
NVIDIA Triton 可在单个 GPU 或 CPU 上并行指定相同或不同框架下的多个模型。在多 GPU 服务器中,NVIDIA Triton 会自动为基于每个 GPU 的每个模型创建一个实例,以提高利用率。
它还可在严格的延迟限制条件下优化实时推理服务,通过支持批量推理来更大限度地提高 GPU 和 CPU 利用率,并内置对音频和视频流输入的支持。对于需要使用多个模型来执行端到端推理(例如对话式 AI)的用例,Triton 支持模型集成。
模型可在生产环境中实时更新,无需重启 Triton 或应用。Triton 支持对单个 GPU 显存无法容纳的超大模型进行多 GPU 以及多节点推理。
高度可扩展的推理
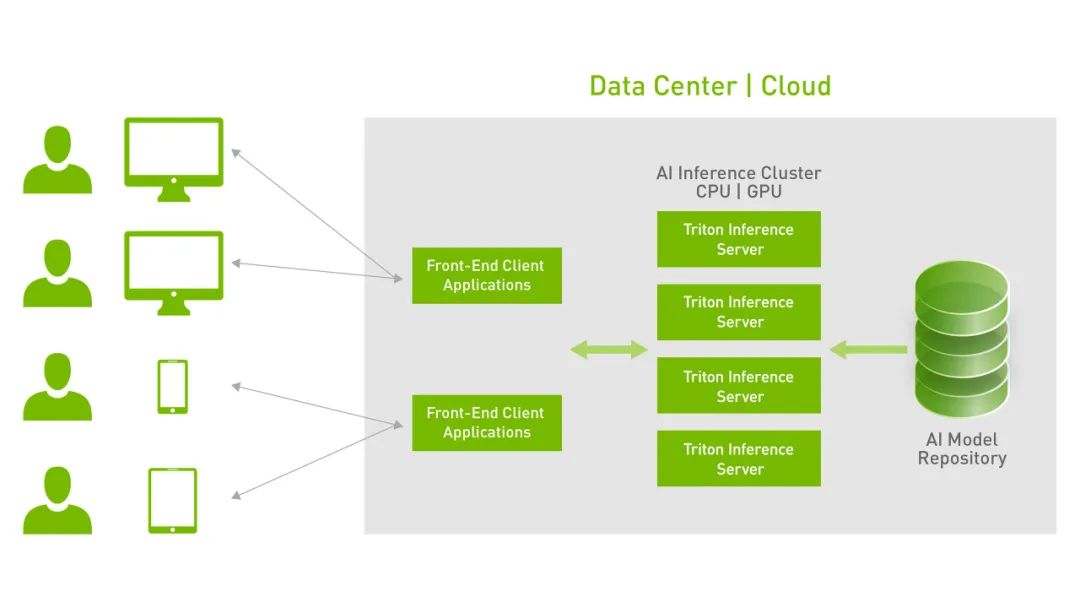
作为一个 Docker 容器,Triton 与 Kubernetes 集成,用于编排、指标和自动缩放。Triton 还与 Kubeflow 和 Kubeflow 工作流集成,实现端到端的 AI 工作流,并导出 Prometheus 指标,用于监控 GPU 利用率、延迟、内存使用率和推理吞吐量。它支持标准的 HTTP / gRPC 接口,可与 load balancer 等其他应用连接,并可轻松扩展到任意数量的服务器,以为任意模型处理日益增长的推理负载。
Triton 可通过一个模型控制 API 来服务于数十或数百个模型。您可基于为适应 GPU 或 CPU 显存而进行的改动,将模型加载到推理服务器中或从推理服务器中卸载。支持兼具 GPU 和 CPU 的异构集群有助于跨平台实现推理标准化,并动态扩展到任意 CPU 或 GPU 以处理峰值负载。
NVIDIA Triton的主要功能
Triton Forest Inference Library (FIL) 后端
新的 Forest Inference Library (FIL) 后端支持在 CPU 和 GPU 上对基于树的模型进行具有可解释性(Shapley 值)的高性能推理。它支持来自 XGBoost、LightGBM、scikit-learn RandomForest、RAPIDS cuML RandomForest 以及其他 Treelite 格式的模型。
Triton 模型分析器
Triton 模型分析器是一种自动评估 Triton 部署配置(例如目标处理器上的批量大小、精度和并发执行实例)的工具。它有助于选择优化配置,以满足应用的服务质量(QoS)限制(延迟、吞吐量和内存要求),并且可以将找到优化配置所需的时间从数周缩短到数小时。
审核编辑:汤梓红
-
NVIDIA
+关注
关注
14文章
5075浏览量
103615 -
服务器
+关注
关注
12文章
9295浏览量
85962 -
Triton
+关注
关注
0文章
28浏览量
7054
原文标题:DevZone | NVIDIA Triton推理服务器
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
变频电源的主要功能及特点
负载管理器的主要功能
数字化智能工厂的主要功能组成

漏洞扫描的主要功能是什么
电子地图的主要功能与应用






 工商网监
工商网监
评论