 通过 AI 应用程序容器化实现高效的 MLOps
通过 AI 应用程序容器化实现高效的 MLOps

到 2021 年底,人工智能市场的价值估计为 583 亿美元。这一数字势必会增加,预计未来 5 年将增长 10 倍,到 2026 年将达到 3096 亿美元。鉴于人工智能技术如此受欢迎,公司广泛希望为其业务构建和部署人工智能应用解决方案。在当今技术驱动的世界中,人工智能已成为我们生活中不可或缺的一部分。根据麦肯锡的一份报告,人工智能的采用率正在继续稳步上升:56% 的受访者表示至少在一项业务功能中采用了人工智能,高于 2020 年的 50%。这种采用率的增加是由于构建和部署战略的不断发展人工智能应用。各种策略正在演变以构建和部署 AI 模型。AI 应用程序容器化就是这样一种策略。
机器学习操作 (MLOps) 正变得越来越稳定。如果您不熟悉 MLOps,它是有助于提高机器学习工作流程效率的原则、实践和技术的集合。它基于 DevOps,正如 DevOps 简化了从开发到部署的软件开发生命周期 (SDLC) 一样,MLOps 对机器学习应用程序也完成了同样的工作。容器化是用于开发和交付 AI 应用程序的最有趣和新兴的技术之一。容器是软件包的标准单元,它将代码及其所有依赖项封装在一个包中,允许程序快速可靠地从一个计算环境转移到另一个计算环境。Docker 处于应用程序容器化的最前沿。
什么是容器?
容器是包含应用程序执行所需的一切的逻辑框。操作系统、应用程序代码、运行时、系统工具、系统库、二进制文件和其他组件都包含在此软件包中。或者,根据特定硬件的可用性,可能会包含或排除某些依赖项。这些容器直接在主机内核中运行。容器将共享主机的资源(如 CPU、磁盘、内存等)并消除管理程序的额外负载。这就是容器“轻量级”的原因。
为什么容器如此受欢迎?
首先,它们是轻量级的,因为容器共享机器操作系统内核。它不需要整个操作系统来运行应用程序。VirtualBox,通常称为虚拟机 (VM),需要安装完整的操作系统,这使得它们非常庞大。
容器是可移植的,可以轻松地从一台机器传输到另一台机器,其中包含所有必需的依赖项。它们使开发人员和操作员能够提高物理机的 CPU 和内存利用率。
在容器技术中,Docker 是最流行和使用最广泛的平台。不仅基于 Linux 的 Red Hat 和 Canonical 已经采用了 Docker,微软、亚马逊和甲骨文等公司也在依赖它。如今,几乎所有 IT 和云公司都采用了 docker,并被广泛用于为其解决方案提供所有依赖项。
点击查看完整大小的图片
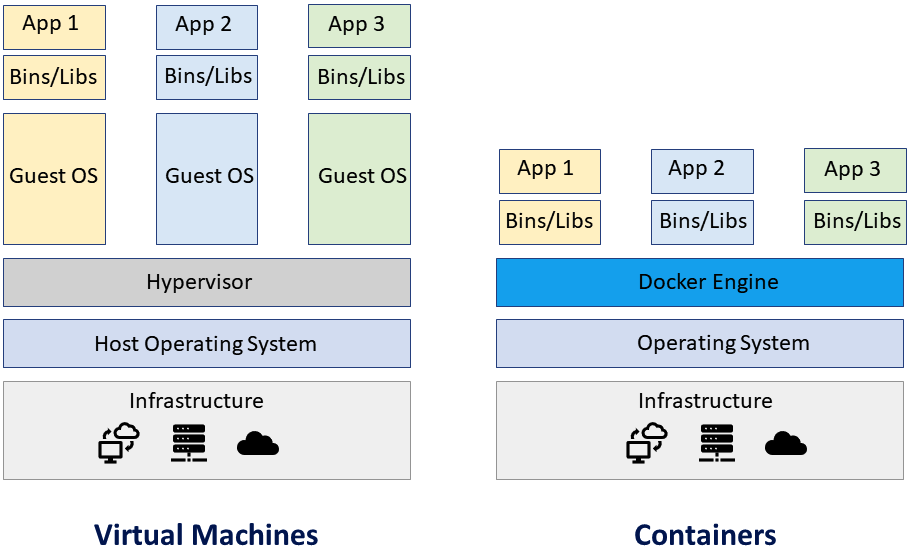
虚拟机与容器(来源:Softnautics)
Docker 和容器之间有什么区别吗?
Docker 已广泛成为容器的代名词,因为它是开源的,拥有庞大的社区基础,并且是一个相当稳定的平台。但容器技术并不新鲜,它以 LXC 的形式被纳入 Linux 已有 10 多年了,FreeBSD jails、AIX Workload Partitions 和 Solaris Containers 也提供了类似的操作系统级虚拟化。
Docker 可以通过将 OS 和包需求合并到一个包中来简化流程,这是容器和 docker 之间的区别之一。
我们经常对为什么 docker 被用于数据科学和人工智能领域感到困惑,但它主要用于 DevOps。ML 和 AI 与 DevOps 一样,具有跨操作系统的依赖性。因此,单个代码可以在 Ubuntu、Windows、AWS、Azure、谷歌云、ROS、各种边缘设备或其他任何地方运行。
AI/ML 的容器应用
与任何软件开发一样,AI 应用程序在由团队中的不同开发人员组装和运行或与多个团队协作时也面临 SDLC 挑战。由于 AI 应用程序的不断迭代和实验性质,有时依赖关系可能会交叉交叉,从而给同一项目中的其他依赖库带来不便。
点击查看完整大小的图片

AI/ML 对容器应用的需求(来源:Softnautics)
问题是真实的,因此,如果您要展示需要特定执行方法的项目,则需要遵循每个步骤的可接受文档。想象一下,对于同一个项目的不同模型,您有多个 python 虚拟环境,并且没有更新文档,您可能想知道这些依赖项是做什么用的?为什么在安装较新的库或更新的模型等时会发生冲突?
开发人员不断面临“它在我的机器上工作”的困境,并不断尝试解决它。
为什么它可以在我的机器上运行(来源:Softnautics)
使用 Docker,所有这些都可以变得更容易和更快。容器化可以帮助您节省大量更新文档的时间,并使您的程序的开发和部署从长远来看更加顺利。即使通过提取多个与平台无关的图像,我们也可以使用 docker 容器为多个 AI 模型提供服务。
完全在 Linux 平台上编写的应用程序可以使用 docker 在 Windows 平台上运行,它可以安装在 Windows 工作站上,使跨平台的代码部署变得更加容易。
点击查看完整大小的图片
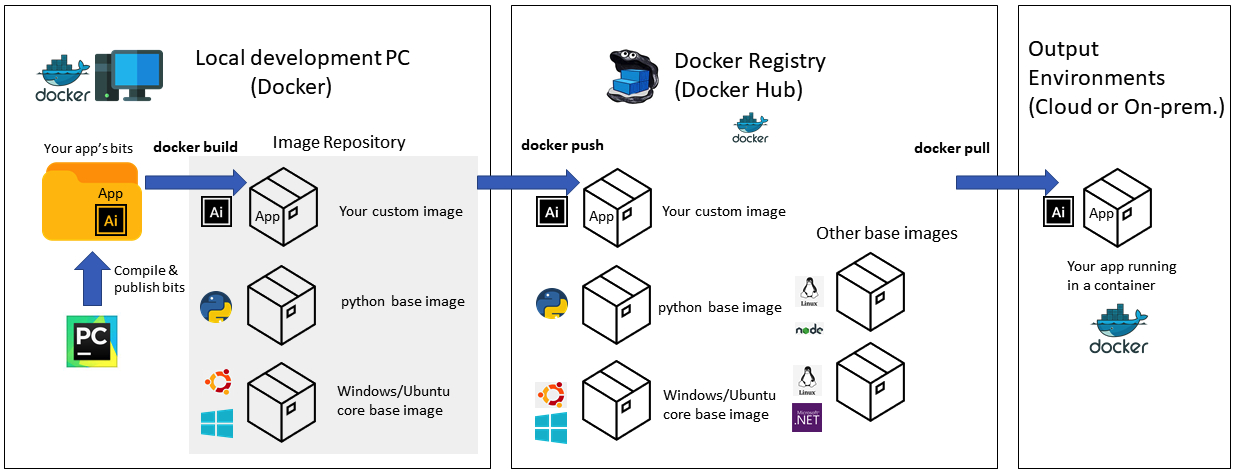
使用 docker 容器部署代码(来源:Softnautics)
容器与虚拟机上 AI 模型的性能
已经进行了许多实验来比较 Docker 与市场上用于 AI 部署的各种虚拟机的性能:下表可以大致了解影响 AI 模型部署的 VM 和 Docker 容器的性能和差异。
| 方差 | 虚拟机 | 容器 |
| 操作系统 | 需要一个客人 | 共享 |
| 开机速度 | 比传统机器慢 | 比虚拟机快 |
| 标准化 | 本质上特定的操作系统标准 | 特定于应用程序的性质 |
| 可移植性 | 不是很便携 | 更快、更容易移植 |
| 需要服务器 | 需要更多 | 很少的服务器 |
| 安全 | 管理程序定义安全性 | 安全是共享的 |
| 冗余级别 | VM拥有资源 | 共享操作系统,减少冗余 |
| 硬件抽象 | 硬件抽象 | 可实现硬件接入 |
| 资源共享 | 需要更多资源 | 需要和共享的资源更少 |
| 资源隔离 | 高的 | 缓和 |
| 记忆 | 高内存占用 | 更少的内存占用和共享 |
| 文件共享 | 无法共享文件 | 文件可以共享 |
表 1:虚拟机与容器(来源:Softnautics)
从所有比较实验的结论中得出的广泛结论如下:
容器的开销比虚拟机低,性能与非虚拟化版本一样好。
在高性能计算 (HPC) 中,容器的性能优于基于管理程序的虚拟化。
深度学习计算工作负载主要卸载到 GPU,从而导致资源争用,这对于众多容器来说很严重,但由于出色的资源隔离,在虚拟机中这种情况很少。
服务大型 AI 模型通常通过 REST API 容器完成。
多模型服务主要使用容器完成,因为它们可以使用更少的资源轻松扩展。
现在,让我们通过Kennedy Chengeta在他最近的研究中收集的以下实验结果来总结容器对任何 VM 的优势。基于 Prosper Lending 和 Lending Club 数据集的深度学习数据集进行分类,下表比较了 4 种不同的虚拟化技术(KVM、Xen、Docker、Docker + Kubernetes)的启动时间、网络延迟、数据下载和网络延迟. KVM(基于内核的 VM)是表中其他的基准值。
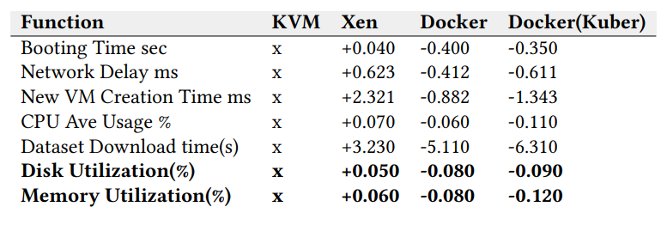
表 2:Lending Club 数据集表现(越低越好)(来源:Softnautics)
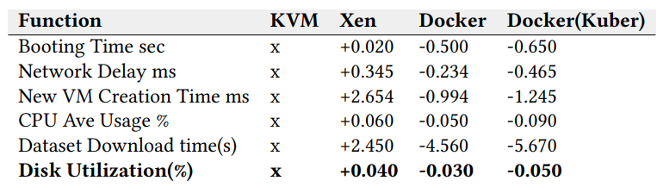
表 3:Prosper 数据集(越低越好)(来源:Softnautics)
如您所见,Docker 和由 Kubernetes 管理的 Docker 的性能优于 KVM 和 Xen Hypervisors。
大型 AI 模型是否对容器部署构成挑战?
由于开发人员将使用容器进行训练和推断他们的 AI 模型,因此对两者来说最关键的将是内存占用。随着 AI 架构变得越来越大,在它们上训练的模型也变得越来越大,从 100 MB 到 2 GB。由于容器被认为是轻量级的,因此此类模型变得笨重而无法装在容器中携带。开发人员使用模型压缩技术使它们具有互操作性和轻量级。模型量化是最流行的压缩技术,您可以通过将模型的内存占用从 float32 集更改为 float16 或 int8 集来减小模型的大小。领先平台提供的大多数预训练即用型 AI 模型都是容器中的量化模型。
结论
总而言之,将整个 AI 应用程序开发到部署管道转换为容器的好处如下:
针对不同版本的框架、操作系统和边缘设备/平台,为每个 AI 模型提供单独的容器。
每个 AI 模型都有一个容器,用于自定义部署。例如:一个容器对开发人员友好,而另一个容器对用户友好且无需编码即可使用。
每个 AI 模型的单独容器,用于 AI 项目中的不同版本或环境(开发团队、QA 团队、UAT(用户验收测试)等)
容器应用程序真正更有效地加速了 AI 应用程序开发-部署管道,并有助于维护和管理用于多种用途的多个模型。
审核编辑 黄昊宇
-
AI
+关注
关注
91文章
41479浏览量
302803 -
人工智能
+关注
关注
1821文章
50396浏览量
267206 -
Docker
+关注
关注
0文章
537浏览量
14433
发布评论请先 登录
IIOT安全运维网关如何通过MQTT和AI实现工业设备的“可预测化维护”

论马斯克的预言:AI使人类边缘化
如何在边缘AI应用场景中实现高性能、低功耗推理(下)

还在手动拼接 AI 代码?你的 IDE 早就该升级了
如何在边缘AI应用场景中实现高性能、低功耗推理(下)

全新升级!捷智算5090云容器正式上线,轻量高效,AI开发新选择!

一位00后如何登上MLOps全球舞台
订单退款自动化接口:高效处理退款流程的技术实现

电子行业如何通过MES系统实现数字化升级
学生适合使用的SOLIDWORKS 云应用程序
睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级
创龙 瑞芯微 RK3562 国产 2GHz 四核A53 工业开发板—Docker容器部署方法说明

Nordic收购 Neuton.AI 关于产品技术的分析




评论