 使用高级 MCU 实现加速机器学习应用
使用高级 MCU 实现加速机器学习应用
从历史上看,人工智能 (AI) 是一种 GPU / CPU 甚至 DSP 依赖的技术。然而,最近人工智能正在通过集成到运行在较小微控制器(也称为 MCU)上的受限应用程序中来进入数据采集系统。这一趋势主要由物联网 (IoT) 市场推动,Silicon Labs 是其中的主要参与者。
为了应对这一新的物联网趋势,Silicon Labs 宣布推出一款可以执行硬件加速 AI 操作的无线 MCU。为了实现这一点,该 MCU 设计为嵌入矩阵矢量处理器 (MVP),即 EFR32xG24。
在本文中,我将首先介绍一些 AI 基础知识,重点介绍 MVP 的用例。最重要的是,如何使用 EFR32xG24 设计 AI IoT 应用程序。
人工智能、机器学习和边缘计算
人工智能是一个试图模仿人类行为的系统。更具体地说,它是一种电气和/或机械实体,可以模拟对输入的响应,类似于人类会做的事情。尽管术语 AI 和机器学习 (ML) 经常互换使用,但它们代表了两种不同的方法。AI 是一个更广泛的概念,而 ML 是 AI 的一个子集。
使用机器学习,系统可以在重复使用所谓的模型后做出预测并改进(或训练)自身。模型是使用经过训练的算法,最终将用于模拟决策。可以通过收集数据或使用现有数据集来训练该模型。当该系统将其“训练过的”模型应用于新获取的数据以做出决策时,我们将其称为机器学习推理。
如前所述,推理需要通常由高端计算机处理的计算能力。但是,我们现在能够在不需要连接到此类高端计算机的更多受限设备上运行推理;这称为边缘计算。
通过在 MCU 上运行推理,可以考虑执行边缘计算。边缘计算涉及在距离获取数据的最近点运行数据处理算法。边缘设备的示例通常是简单且受限的设备,例如传感器或基本执行器(灯泡、恒温器、门传感器、电表等)。这些设备通常在低功耗 ARM Cortex-M 类 MCU 上运行:
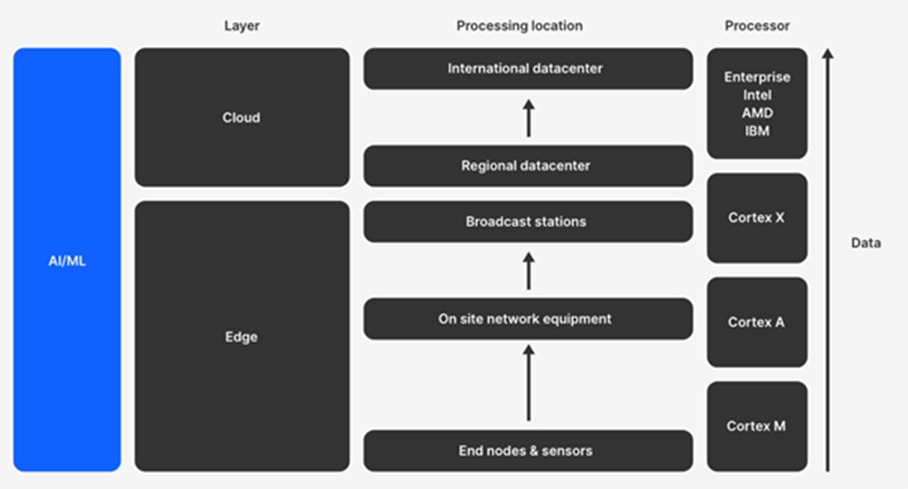
执行边缘计算有很多好处。可以说,最有价值的好处是使用边缘计算的系统不依赖于外部实体。设备可以在本地“做出自己的决定”。
在本地进行决策具有以下实际好处:
-
提供更低的延迟
原始数据不需要传输到云端进行处理,这意味着决策可以实时出现在设备上。 -
减少所需的互联网带宽
传感器会产生大量实时数据,这反过来又会产生对带宽的大量需求,即使没有什么可“报告”,从而使无线频谱饱和并增加运行成本。 -
降低功耗
与传输数据相比,本地分析数据(使用 AI)所需的功率要少得多 -
符合隐私和安全要求
通过在本地做出决策,无需将详细的原始数据发送到云端,只需将推理结果和元数据发送到云端,从而消除了数据隐私泄露的可能性。 -
降低成本
在本地分析传感器数据可以节省使用云基础设施和流量的费用。 -
提高弹性
如果与云的连接中断,边缘节点仍可以自主运行。
Silicon Labs 用于边缘计算的 EFR32xG24
EFR32xG24 是一款安全无线 MCU,支持多种 2.4 GHz IoT 协议(蓝牙低功耗、Matter、Zigbee 和 OpenThread 协议)。它还包括 Secure Vault,这是一种改进的安全功能集,适用于所有 Silicon Labs Series 2 平台。
但是,除了改进了该 MCU 独有的安全性和连接性之外,还有一个用于机器学习模型推理的硬件加速器(以及其他加速器),称为矩阵矢量处理器 (MVP)。
与没有硬件加速的 ARM Cortex-M 相比,MVP 提供了更高效地运行机器学习推理的能力,功耗降低了 6 倍,速度提高了 2-4 倍(实际改进取决于模型和应用程序)。
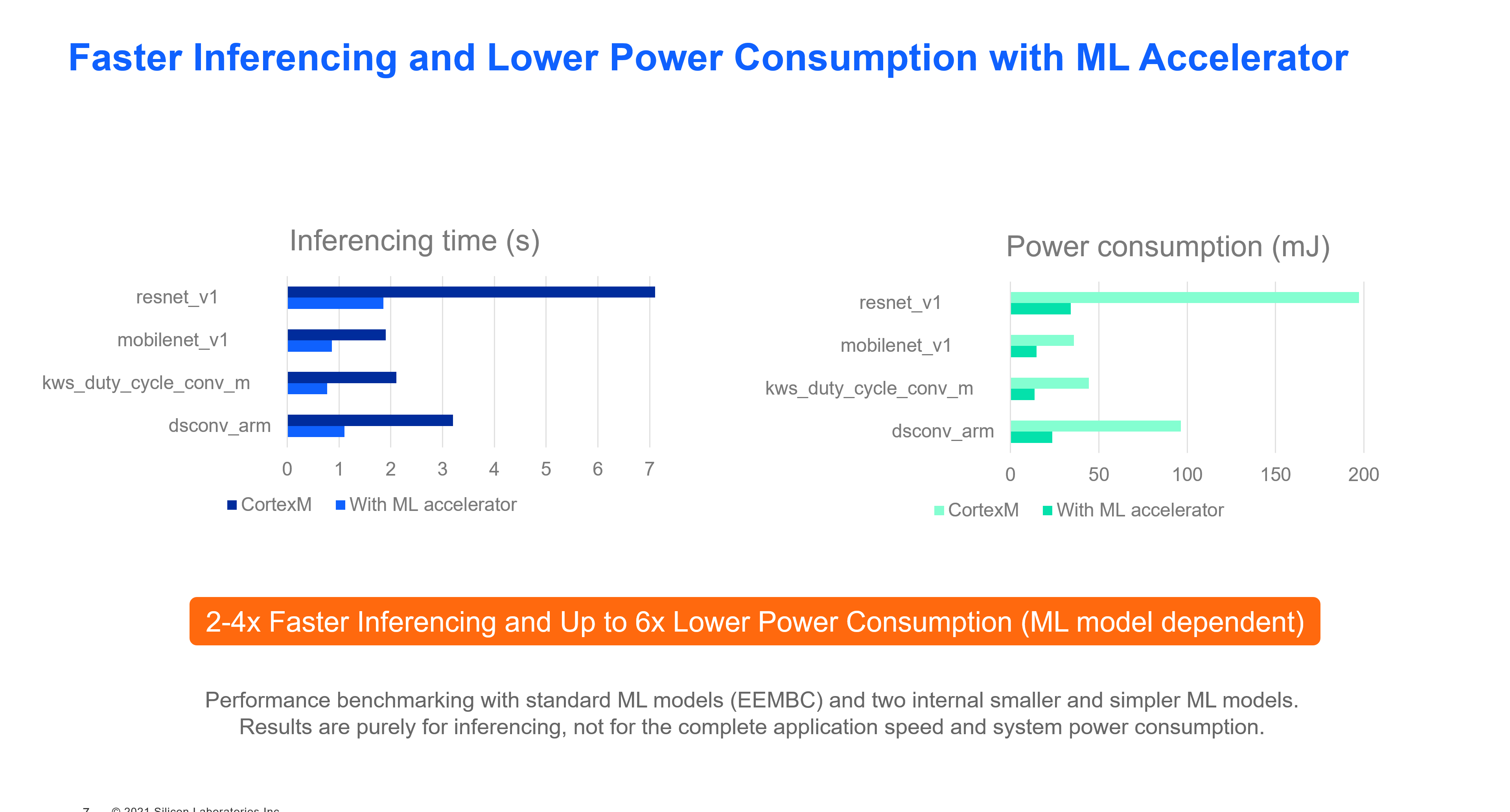
MVP 旨在通过处理密集的浮点运算来卸载 CPU。它专为复杂的矩阵浮点乘法和加法而设计。
MVP 由专用硬件算术逻辑单元 (ALU)、加载/存储单元 (LSU) 和定序器组成。
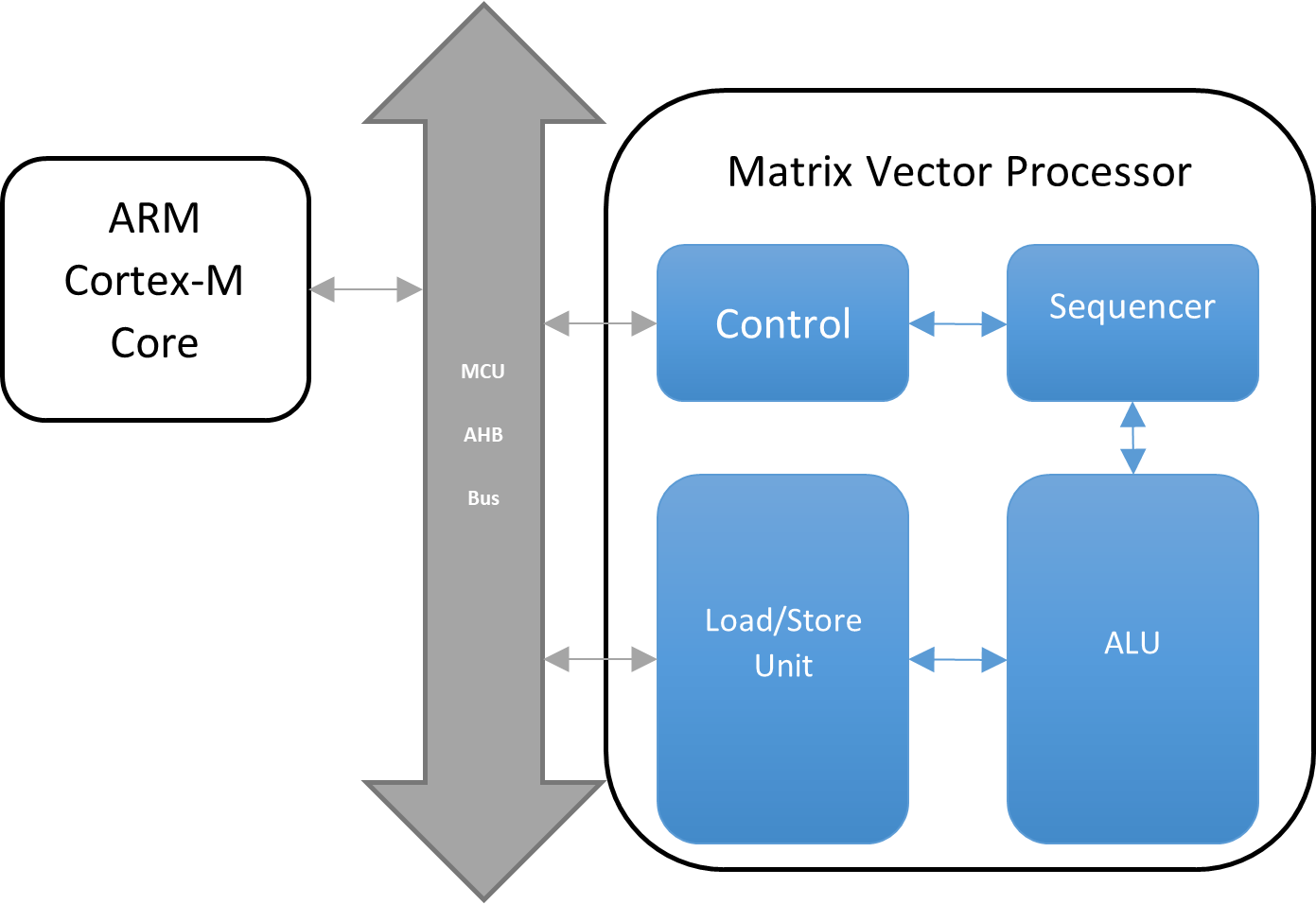
因此,MVP 有助于加速各种应用程序的处理并节省功耗,例如到达角 (AoA)、MUSIC 算法计算、机器学习(本征或基本线性代数子程序 BLAS)等。
由于该设备是一个简单的 MCU,它无法解决 AI/ML 可以涵盖的所有用例。它旨在解决下面列出的以下四个类别以及实际应用:
为了帮助解决这些问题,Silicon Labs 提供了基于称为 TensorFlow 的 AI/ML 框架的专用示例应用程序。
TensorFlow 是来自 Google 的用于机器学习的端到端开源平台。它拥有一个由工具、库和社区资源组成的全面、灵活的生态系统,使研究人员能够推动 ML 的最新技术,开发人员可以轻松构建和部署 ML 驱动的应用程序。
Tensor Flow 项目还针对嵌入式硬件变体进行了优化,称为 TensorFlow Lite for Microcontrollers (TFLM)。这是一个开源项目,其中大部分代码由社区工程师贡献,包括 Silicon Labs 和其他芯片供应商。目前,这是与 Silicon Labs Gecko SDK 软件套件一起交付的用于创建 AI/ML 应用程序的唯一框架。
Silicon Labs 提供的 AI/ML 示例有:
- Zigbee 3.0 带语音激活的电灯开关
- 张量流魔棒
- 声控 LED
- 张量流 Hello world
- 张量流微演讲
要开始开发基于其中任何一个的应用程序,您可以有很少的经验,或者您可以成为专家。Silicon Labs 提供多种机器学习开发工具供您选择,具体取决于您的机器学习专业水平。
对于第一次 ML 开发人员,您可以从我们的一个示例开始,或者尝试我们的第 3 方合作伙伴之一。我们的第 3 方 ML 合作伙伴通过功能丰富且易于使用的 GUI 界面支持完整的端到端工作流程,以便为我们的芯片构建最佳机器学习模型。
对于希望直接使用 Keras/TensorFlow 平台的 ML 专家,Silicon Labs 提供了一个自助式、自助式的参考包,将模型开发工作流程组织成一个专为为 Silicon Labs 芯片构建 ML 模型而定制的工作流程。
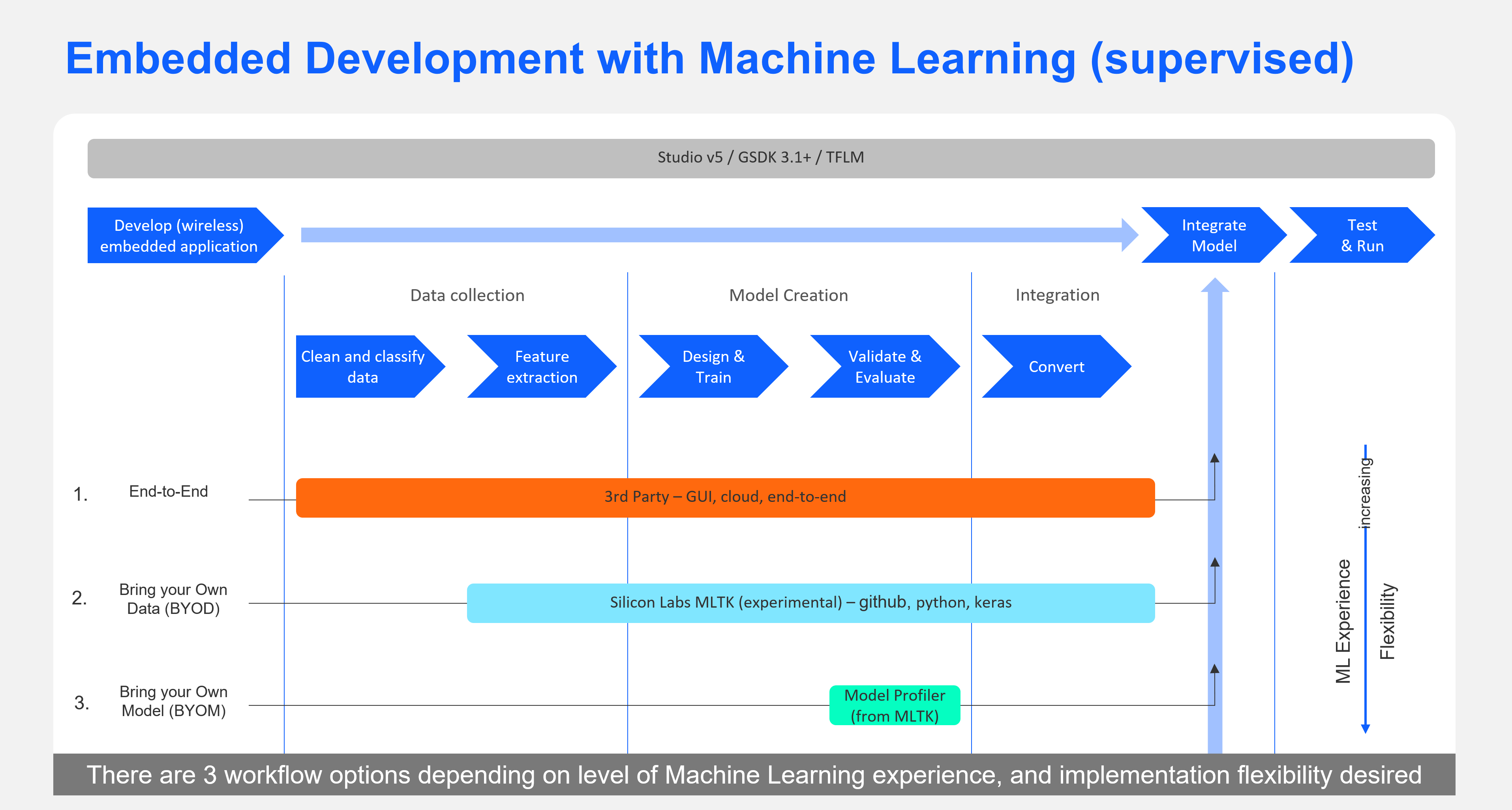
开发支持 ML 的应用示例:采用 EFR32xG24 的语音控制 Zigbee 开关
要创建支持 ML 的应用程序,需要两个主要步骤。第一步是创建一个无线应用程序,您可以使用 Zigbee、BLE、Matter 或任何基于 2.4 GHz 协议的专有应用程序来完成。它甚至可以是未连接的应用程序。第二步是构建 ML 模型以将其与应用程序集成。
如上所述,Silicon Labs 提供了多种选项来为其 MCU 创建 ML 应用程序。此处选择的方法是使用具有预定义模型的现有示例应用程序。在这个例子中,模型被训练来检测两个语音命令:“on”和“off”。
EFR32xG24 应用程序入门
 |
要开始使用,请获取 EFR32MG24 开发人员套件 BRD2601A(左)。 该开发套件是一个紧凑型电路板,嵌入了多个传感器(IMU、温度、相对湿度等)、LED 和 Stereo I 2 S 麦克风。 该项目将使用 I 2 S 麦克风。 这些设备可能不像 GPU 那样稀有,但如果您没有机会获得这些套件之一,您还可以使用基于系列 1 的旧开发套件,称为“Thunderboard Sense 2”参考。SLTB004A(右)。 但是,此 MCU 没有 MVP,将使用主内核执行所有推理,无需加速。 |
 |
接下来,您需要 Silicon Labs 的 IDE Simplicity Studio 来创建 ML 项目。它提供了一种下载 Silicon Labs 的 Gecko SDK 软件套件的简单方法,该套件提供了应用程序所需的库和驱动程序,如下所示。
- 无线网络堆栈(本例中为 Zigbee)
- 硬件驱动程序(用于 I2S 麦克风以及 MVP)
- TensorFlow Lite 框架
- 一个已经训练过的用于检测命令词的模型
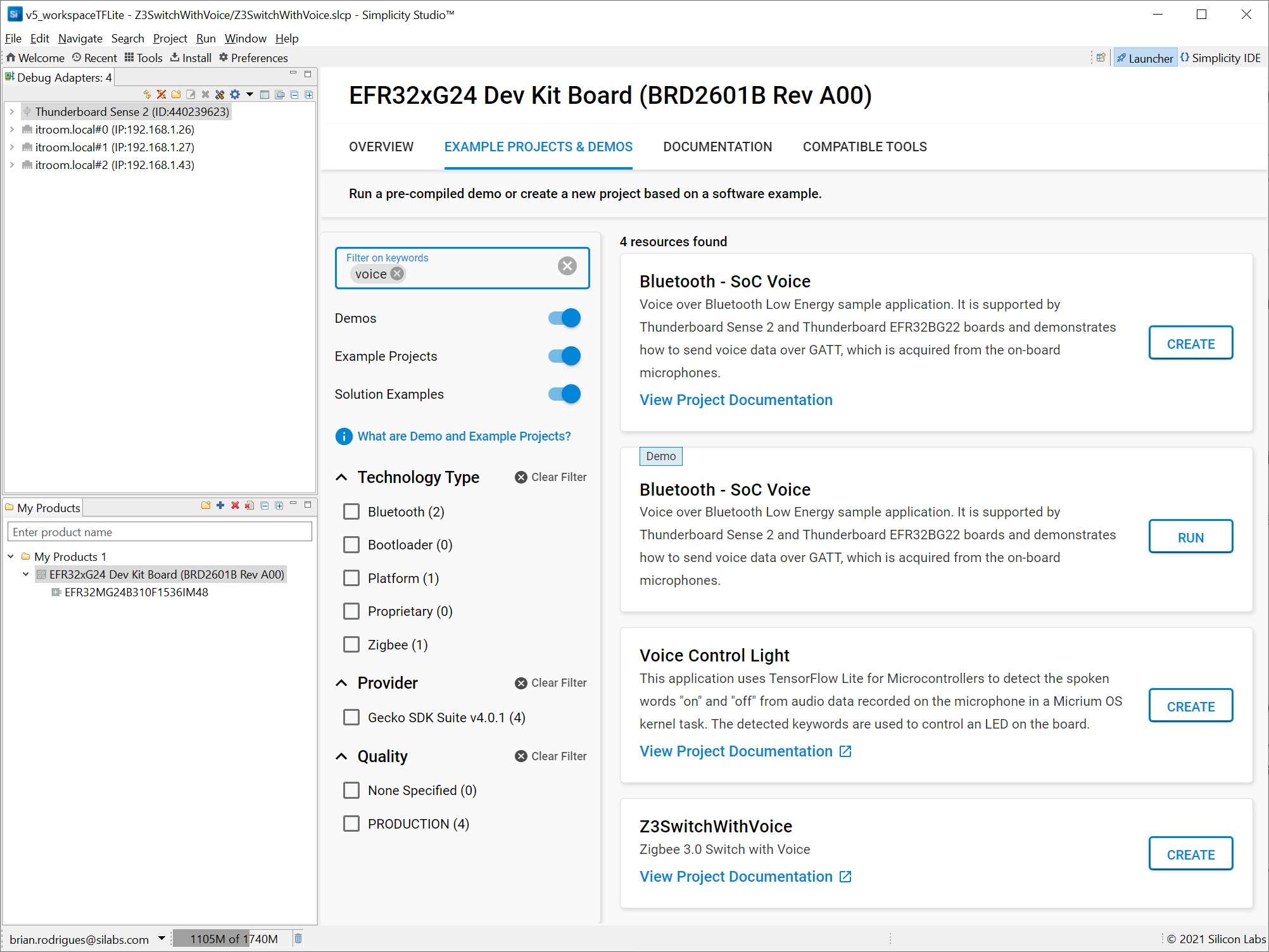
IDE 还提供工具来进一步分析您的应用程序功耗或网络操作。
创建启用 MVP 的 Zigbee 3.0 Switch 项目
Silicon Labs 提供了一个即用型示例应用程序 Z3SwitchWithVoice,您将创建和构建该应用程序。该应用程序已经附带了一个 ML 模型,因此您无需创建一个。
创建后,请注意 Simplicity Studio 项目由组件带来的源文件组成,这些组件是 GUI 实体,通过简化复杂软件的集成,可以轻松使用 Silicon Labs 的 MCU。在这种情况下,您可以看到默认安装了 MVP 支持和 Zigbee 网络堆栈。
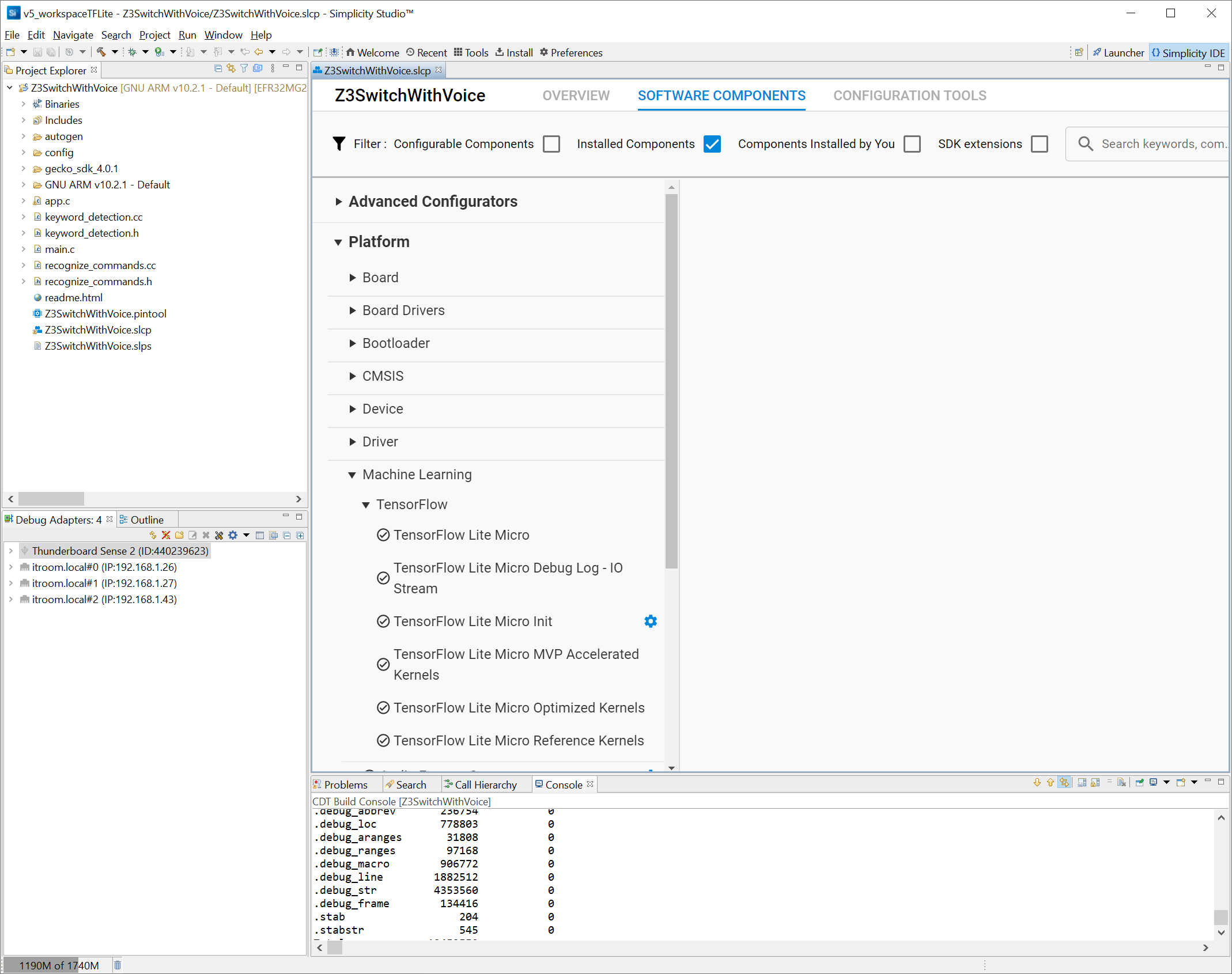
主要应用程序代码位于 app.c 源文件中。
在网络方面,应用程序可以通过一个简单的按钮与任何现有的 Zigbee 3.0 网络配对,也称为“网络转向”。联网后,MCU 将寻找兼容且可配对的照明设备,也称为“绑定”。
当应用程序的网络部分启动并运行时,MCU 将定期轮询麦克风数据样本并在其上运行推理。此代码位于keyword_detection.c 中。
()
{
found_command_index = 0;
分数 = 0;
is_new_command = ;
current_time_stamp;
current_time_stamp = sl_sleeptimer_tick_to_ms(sl_sleeptimer_get_tick_count());
TfLiteStatus process_status = command_recognizer->ProcessLatestResults(
sl_tflite_micro_get_output_tensor(), current_time_stamp, &found_command_index, &score, &is_new_command);
(process_status != ) {
SL_STATUS_FAIL;
}
(is_new_command) {
(found_command_index == 0 || found_command_index == 1) {
printf( , kCategoryLabels[found_command_index],
分数,current_time_stamp);
检测到的关键字(found_command_index);
}
}
SL_STATUS_OK;
}
检测到关键字后,app.c 中的处理程序将发送相应的 Zigbee 命令:
{
状态;
(emberAfNetworkState()==){
emberAfGetCommandApsFrame()-> = SWITCH_ENDPOINT;
(detected_keyword_index == 0) {
emberAfFillCommandOnOffClusterOn();
} (detected_keyword_index == 1) {
emberAfFillCommandOnOffClusterOff();
}
状态 = emberAfSendCommandUnicastToBindings();
sl_zigbee_app_debug_print( , , status);
}
}
此时,您已在无线 MCU 上运行硬件加速推理以进行边缘计算。
自定义 TensorFlow 模型以使用不同的命令词
如前所述,实际模型已经集成到该应用程序中,并且没有进一步修改。但是,如果您自己集成模型,则可以通过以下步骤进行:
- 收集和标记数据
- 设计和构建模型
- 评估和验证模型
- 为嵌入式设备转换模型
无论您对机器学习多么熟悉,都必须遵循这些步骤。不同之处在于如何构建模型,如下所示:
- 如果您是 ML 的初学者,Silicon Labs 建议使用我们易于使用的端到端第三方合作伙伴平台之一:Edge Impulse 或 SensiML 来构建您的模型。
- 如果您是 Keras/TensorFlow 方面的专家并且不想使用第三方工具,您可以使用机器学习工具包 (MLTK),它是一个自助式、自助式的 Python 包。Silicon Labs 围绕音频用例创建了这个参考包,可以扩展、修改或以其他方式挑选专家认为有吸引力的部分。该包将在 GitHub 上提供,附带文档。您也可以直接导入一个 .tflite 文件,该文件在 TensorFlow lite 的嵌入式版本上运行,用于为 EFR32 产品线进行微编译。您必须确保数据上的特征提取对于训练模型与在目标芯片上运行推理完全相同。
在 Simplicity Studio 中,后者是最简单的。要在 Simplicity Studio 中更改模型,请将 .tflite 模型文件复制到项目的 config/tflite 文件夹中。项目配置器提供了一个工具,可以自动将 .tflite 文件转换为 sl_ml_model 源文件和头文件。此工具的完整文档可在Flatbuffer Conversion获得。
[注意:所有图片和代码均由 Silicon Labs 提供。]
审核编辑 黄昊宇
-
mcu
+关注
关注
146文章
17172浏览量
351585
发布评论请先 登录
相关推荐
如何在低功耗MCU上实现人工智能和机器学习
什么是机器学习?通过机器学习方法能解决哪些问题?

NPU与机器学习算法的关系
FPGA加速深度学习模型的案例
AI引擎机器学习阵列指南


MCU如何实现AI功能
深度学习与传统机器学习的对比
MCX N系列微控制器适用于安全、智能的电机控制和机器学习应用
请问PSoC™ Creator IDE可以支持IMAGIMOB机器学习吗?
英飞凌最新的带神经加速的汽车MCU系列 AURIX TC4x微控制器

NVIDIA Isaac机器人平台升级,加速AI机器人技术革新
机器学习8大调参技巧





 工商网监
工商网监
评论