 基准分数突出了广泛的机器学习推理性能
基准分数突出了广泛的机器学习推理性能
继今年早些时候发布的训练基准分数之后,MLPerf 发布了其推理基准的第一组基准分数。
与目前有 5 家公司的 63 份参赛作品的训练轮相比,更多的公司提交了基于 MobileNet、ResNet、Yolo 等神经网络架构的推理结果。总共有来自 14 个组织的 500 多个分数进行了验证。这包括来自几家初创公司的数据,而一些知名初创公司仍然明显缺席。
在封闭的部门,其严格的条件可以直接比较系统,结果显示性能差异为 5 个数量级,并且在估计的功耗方面跨越三个数量级。在开放部门中,提交可以使用一系列模型,包括低精度实现。
Nvidia 在封闭部门的所有类别中都获得了商用设备的第一名。其他领先者包括数据中心类别的 Habana Labs、谷歌和英特尔,而 Nvidia 在边缘类别中与英特尔和高通竞争。

英伟达用于数据中心推理的 EGX 平台(图片:英伟达)
Moor Insights and Strategy 分析师 Karl Freund 表示:“Nvidia 是唯一一家拥有生产芯片、软件、可编程性和人才的公司,可以发布跨 MLPerf 范围内的基准测试,并在几乎所有类别中获胜。” “GPU 的可编程性为未来的 MLPerf 版本提供了独特的优势……我认为这展示了 [Nvidia] 实力的广度,以及挑战者的利基性质。但随着时间的推移,许多挑战者会变得成熟,因此英伟达需要继续在硬件和软件方面进行创新。”
Nvidia 发布的图表显示了其对结果的解释,在商用设备的封闭部门的所有四个场景中,它都位居第一。
这些场景代表不同的用例。离线和服务器场景用于数据中心的推理。离线场景可能代表大量图片的离线照片标记并测量纯吞吐量。服务器场景代表一个用例,其中包含来自不同用户的多个请求,在不可预测的时间提交请求,并在固定时间测量吞吐量。边缘场景是单流,它对单个图像进行推理,例如在手机应用程序中,以及多流,它测量可以同时推理多少个图像流,用于多摄像头系统。
公司可以为选定的机器学习模型提交结果,这些模型在四种场景中的每一种中执行图像分类、对象检测和语言翻译。
数据中心结果
“从数据中心的结果来看,Nvidia 在服务器和离线类别的所有五个基准测试中均名列前茅,”Nvidia 加速计算产品管理总监 Paresh Kharya 说。“在商用解决方案中,我们的 Turing GPU 的性能优于其他所有人。”
Kharya 强调了这样一个事实,即英伟达是唯一一家在数据中心类别的所有五个基准模型中提交结果的公司,而对于服务器类别(这是更困难的情况),英伟达的性能相对于其竞争对手有所提高。
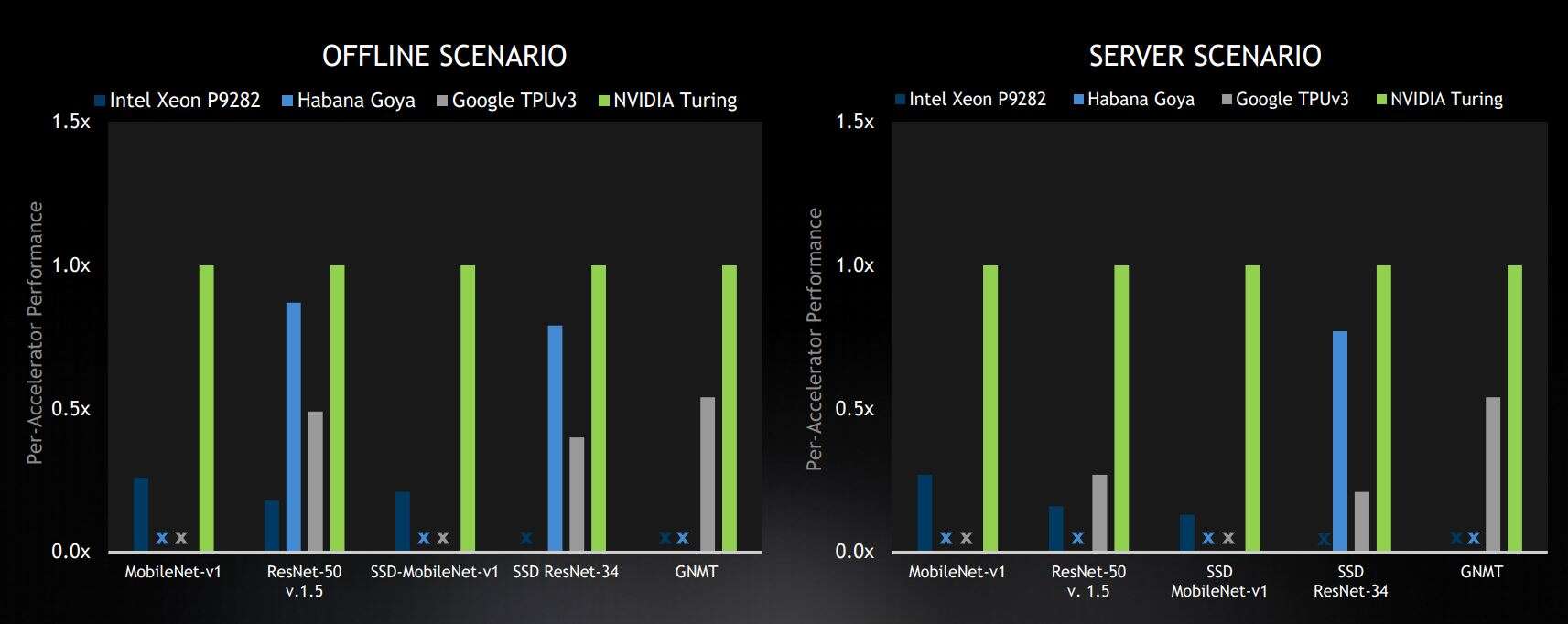
选定的数据中心基准测试结果来自封闭部门,在商用设备类别中处于领先地位。结果显示相对于每个加速器的 Nvidia 分数。X 代表“未提交结果”(图片:Nvidia)
英伟达在数据中心领域最接近的竞争对手是拥有Goya 推理芯片的以色列初创公司 Habana Labs 。
分析师 Karl Freund 表示:“Habana 是唯一一个全面生产高性能芯片的挑战者,当下一个 MLPerf 套件有望包含功耗数据时,它应该会做得很好。”
Habana Labs 在接受 EETimes 采访时指出,基准分数纯粹基于性能——功耗不是衡量标准,实用性也不是(例如考虑解决方案是被动冷却还是水冷),成本也不是。

Habana Labs PCIe 卡采用 Goya 推理芯片(图片:Habana Labs)
Habana 还使用开放分区来展示其低延迟能力,比封闭分区进一步限制延迟,并为多流场景提交结果。
边缘计算结果
在边缘基准测试中,Nvidia 赢得了所有四个在封闭部门提交商用解决方案的类别。高通的 Snapdragon 855 SoC 和英特尔的 Xeon CPU 在单流类别中落后于英伟达,高通和英特尔都没有提交更困难的多流场景的结果。
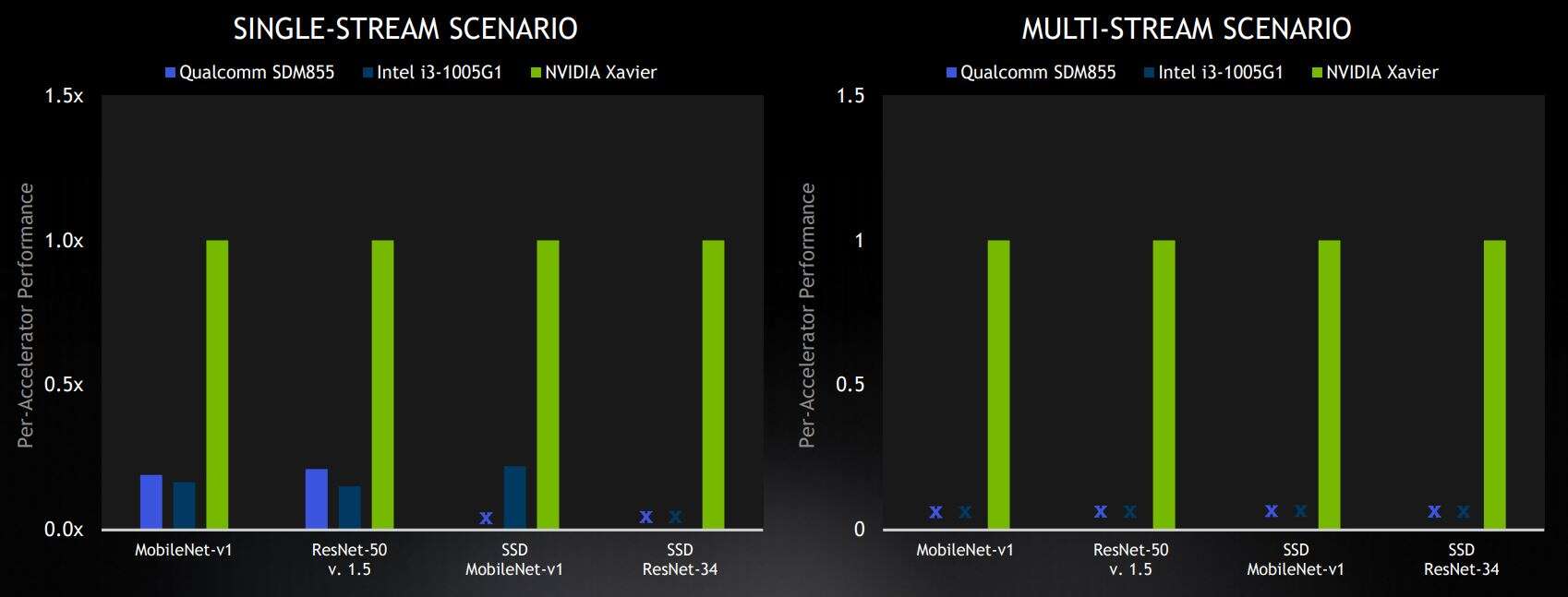
选定的边缘基准测试结果来自封闭部门,在商用设备类别中处于领先地位。结果显示相对于每个加速器的 Nvidia 分数。X 代表“未提交结果”(图片:Nvidia)
“预览”系统(尚未商业化)的结果将阿里巴巴 T-Head 的含光芯片与英特尔的 Nervana NNP-I、Hailo-8和 Centaur Technologies 的参考设计进行了对比。与此同时,研发类别的特色是一家隐秘的韩国初创公司 Furiosa AI,对此我们知之甚少。
MLPerf 网站上提供了最近的推理分数以及早期的训练分数。
审核编辑 黄昊宇
-
基准测试
+关注
关注
0文章
19浏览量
7593 -
机器学习
+关注
关注
66文章
8422浏览量
132739
发布评论请先 登录
相关推荐
《具身智能机器人系统》第7-9章阅读心得之具身智能机器人与大模型
NVIDIA Jetson Orin Nano开发者套件的新功能

利用Arm Kleidi技术实现PyTorch优化

解锁NVIDIA TensorRT-LLM的卓越性能
Arm KleidiAI助力提升PyTorch上LLM推理性能
Arm成功将Arm KleidiAI软件库集成到腾讯自研的Angel 机器学习框架
澎峰科技高性能大模型推理引擎PerfXLM解析

开箱即用,AISBench测试展示英特尔至强处理器的卓越推理性能

魔搭社区借助NVIDIA TensorRT-LLM提升LLM推理效率
学习笔记|如何移植NCNN

自然语言处理应用LLM推理优化综述

UL Procyon AI 发布图像生成基准测试,基于Stable Diffusion
深度探讨VLMs距离视觉演绎推理还有多远?

瑞萨电子宣布推出一款面向高性能机器人应用的新产品—RZ/V2H

Torch TensorRT是一个优化PyTorch模型推理性能的工具






 工商网监
工商网监
评论