 一个大规模多任务学习框架µ2Net
一个大规模多任务学习框架µ2Net
【导读】谷歌大神Jeff Dean最近亲自操刀发新作,提出了一个大规模多任务学习框架µ2Net,基本把各大数据集多任务学习的SOTA刷了个遍,但这次为何网友有点不买账了?很简单,差钱。
2021年10月,Jeff Dean亲自撰文介绍了一个全新的机器学习架构——Pathways。 目的很简单,就是让一个AI能够跨越数以万计的的任务,理解不同类型的数据,并同时以极高的效率实现:
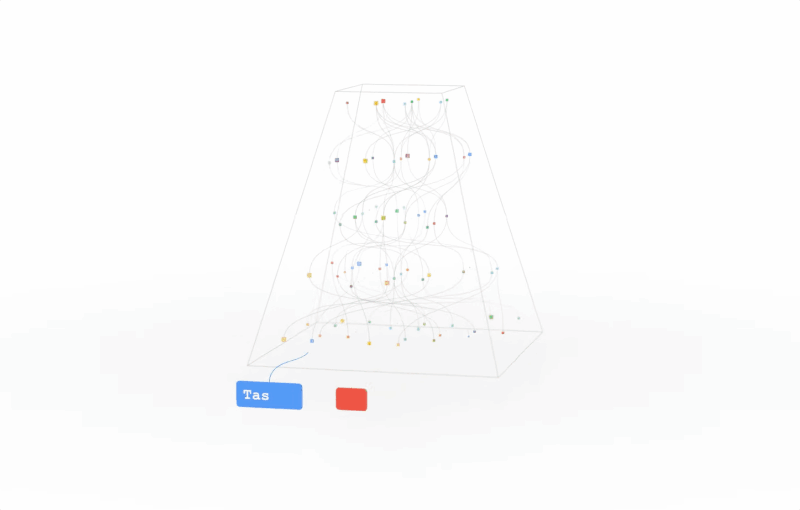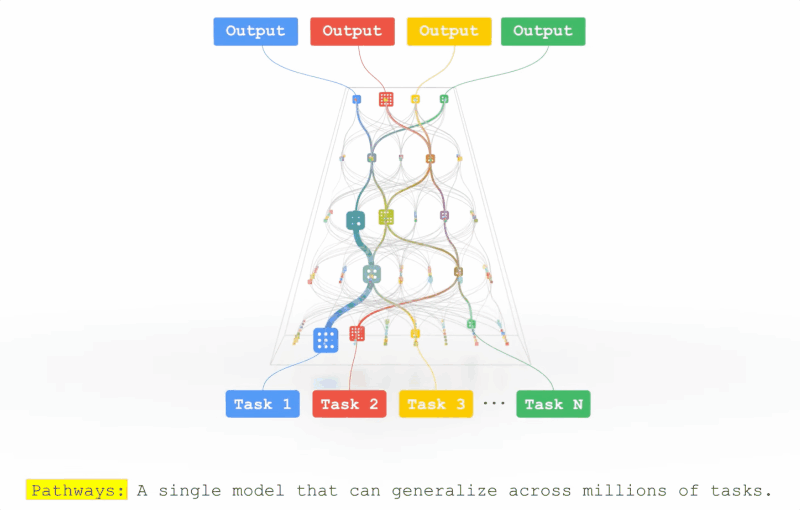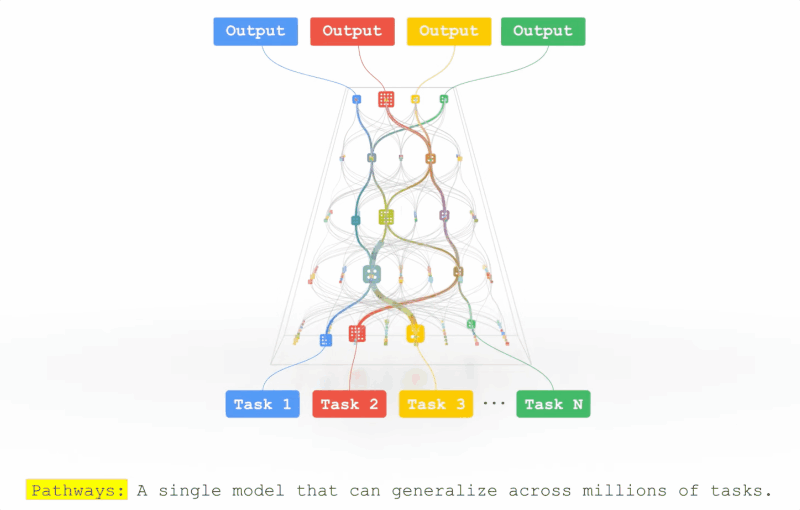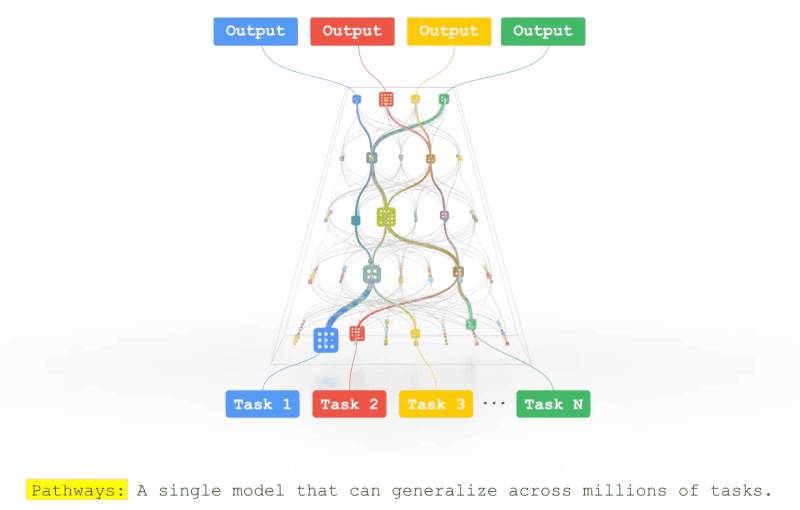
在大半年之后的2022年3月,Jeff Dean终于发布了Pathways的论文。

论文连接:https://arxiv.org/abs/2203.12533 其中,补充了不少技术上的细节,比如最基本的系统架构等等。
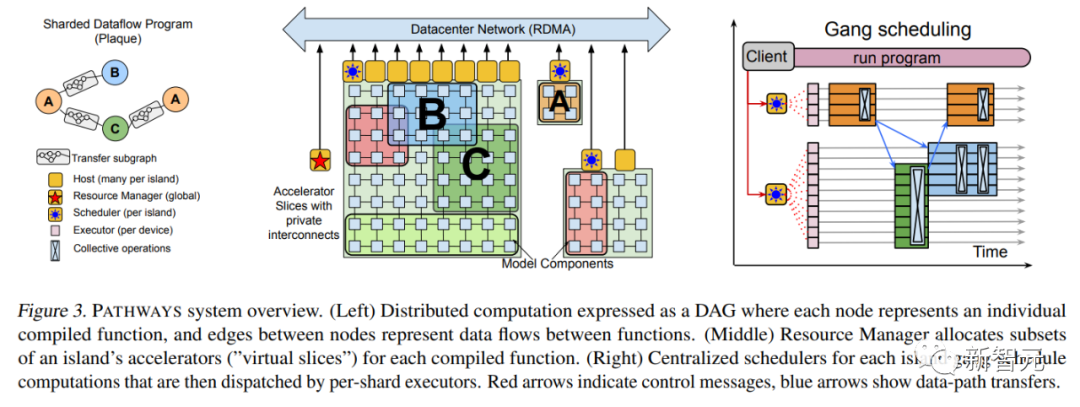
2022年4月,谷歌用Pathways的PaLM语言模型横空出世,接连打破多项自然语言处理任务的SOTA,这个拥有5400亿参数的Transformer语言模型再次证明了「大力出奇迹」。 除了用到强大的Pathways系统外,论文中介绍PaLM的训练用到了6144个TPU v4,使用了7800亿token的高质量数据集,并且其中有一定比例的非英文多语种语料。

论文地址:https://arxiv.org/abs/2204.02311 最近,Jeff Dean一篇新作又引发了大家对Pathways的猜测。
Pathways的拼图又合上了一块?
这篇论文的作者只有两位:大名鼎鼎的Jeff Dean和来自意大利的工程师Andrea Gesmundo。 有趣的是,不仅Gesmundo很低调,而且前两天刚吹完自家Imagen的Jeff Dean也完全没有在推特上提及此事。 而有网友拜读之后推测,这可能是下一代AI架构Pathways的组成部分。

论文地址:https://arxiv.org/abs/2205.12755 本文的思路是这样的: 通过动态地将新任务纳入一个大型运行系统,可以利用稀疏多任务机器学习模型的碎片,来实现新任务质量的提升,并可以在相关任务之间自动分享模型的碎片。 这种方法可以提高每个任务的质量,并在收敛时间、训练实例数量、能源消耗等方面提高模型效率。本文提出的机器学习问题框架,可以视作标准多任务和持续学习形式化的概括和综合。 在这个框架下,再大的任务集都可以被联合解决。 而且,随着时间的推移,任务集中可以加入连续的新任务流来实现扩展。预训练任务和下游任务之间的区别也不存在了。 因为,随着新任务的加入,系统会寻找如何将已有的知识和表征与新的模型能力相结合,以实现每个新任务的高质量水平。在解决一个新任务时获得的知识和学到的表征,也可用于任何未来的任务,或继续学习现有任务。 这个方法名为「突变多任务网络」或µ2Net。(μ=Mutation)
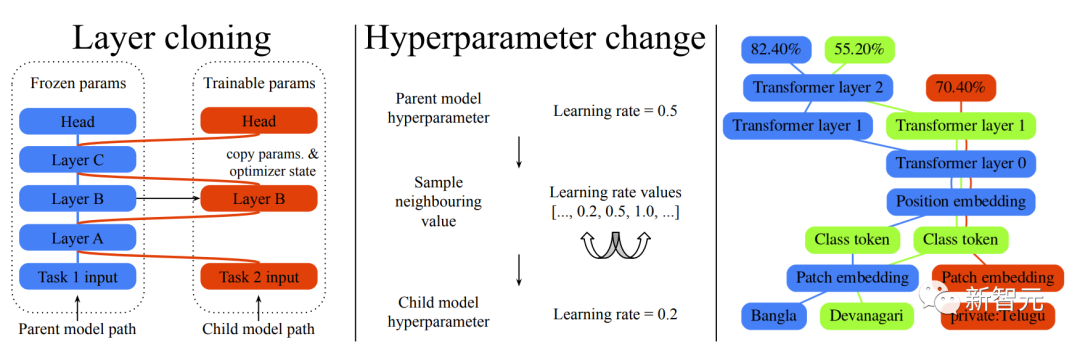
用于大规模持续学习实验的两类突变模型 简单说,就是生成一个大规模的多任务网络,去联合解决多个任务。不仅每个任务的质量和效率都获得了提升,还可以通过动态增加新的任务来实现模型的扩展。 通过对以前任务的学习,嵌入到系统中的知识积累越多,后续任务的解决方案的质量就越高。 此外,在减少每个任务新添加的参数方面,新任务的解决效率可以不断提高。生成的多任务模型是稀疏激活的,模型集成了基于任务的路由机制,随着模型的扩展,保证每个任务的计算成本的上升是有界限的。
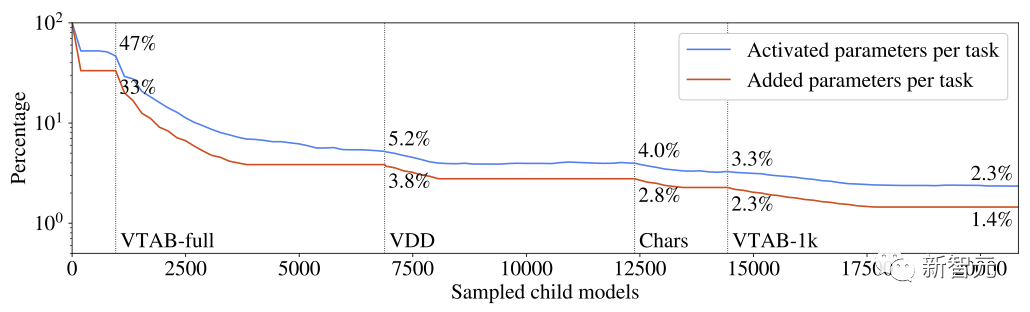
每个任务激活的和增加的参数占多任务系统参数总数的百分比 从每个任务学到的知识被分割成可以被多个任务重用的部分。实验证明,这种分块技术避免了多任务和持续学习模型的常见问题,如灾难性遗忘、梯度干扰和负迁移。 对任务路线空间的探索和对每个任务最相关的先验知识子集的识别是由一个进化算法引导的,该算法旨在动态地调整探索/利用的平衡,而不需要手动调整元参数。同样的进化逻辑被用于动态调整超参数多任务模型组件。

既然叫「突变网络」,这个突变是怎么解释的? 深度神经网络通常由架构和超参数来定义。本文中的架构是由一连串的神经网络层组成的。每个层将输入向量映射到一个可变维度的输出向量,网络实例化的细节,比如优化器或数据预处理的配置,则由超参数确定。 所以这里讲的突变也分为两类,层克隆突变和超参数突变。 层克隆突变创建了一个可以被子模型训练的任何父模型图层的副本。如果父模型的某层没有被选中进行克隆,会冻结当前状态并与子模型共享,以保证预先存在的模型的不变性。 超参数突变则用于修改子层从父层继承的配置。每个超参数的新值可以从一组有效值中抽取。对于数字超参数,有效值集被排序为一个列表,采样时仅限于相邻值,以应用一个增量变化约束。 来看看实际效果如何:

在ImageNet 2012、cifar100、cifar10三个数据集上,µ2Net在5任务迭代、10任务迭代后的表现均超过了当前最通用和性能最好的ViT预训练微调模型。 在任务扩展方面,在加入VTAB-full和VDD持续学习任务后,µ2Net性能表现获得进一步提升,在cifar10数据集上的VDD持续学习任务表现达到了99.43%的最佳成绩。

在多任务字符分类基准任务上,在两次任务迭代后,µ2Net在大部分数据集上刷新了SOTA水平,数据集规模由2.5k到240k样本容量不等。
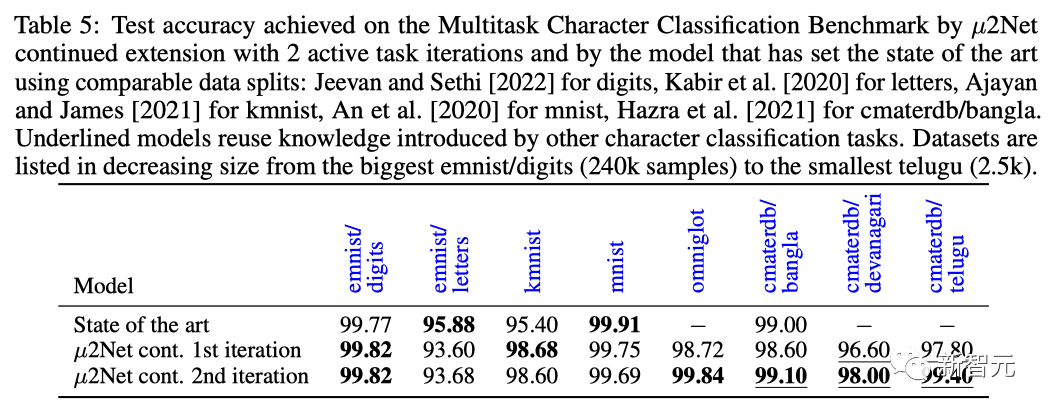
简单来说,在这个架构之下,模型学习的任务越多,系统学到的知识就越多,也就越容易解决新的任务。 比如,一个ViT-L架构(3.07亿个参数)可以演变成一个具有1308.7亿个参数的多任务系统,并解决69个任务。 此外,随着系统的增长,参数激活的稀疏性使每个任务的计算量和内存用量保持不变。实验表面,每个任务平均增加的参数减少了38%,而多任务系统只激活了每个任务总参数的2.3%。 当然,在这一点上,它只是一个架构和初步实验。
网友:论文很好,但……
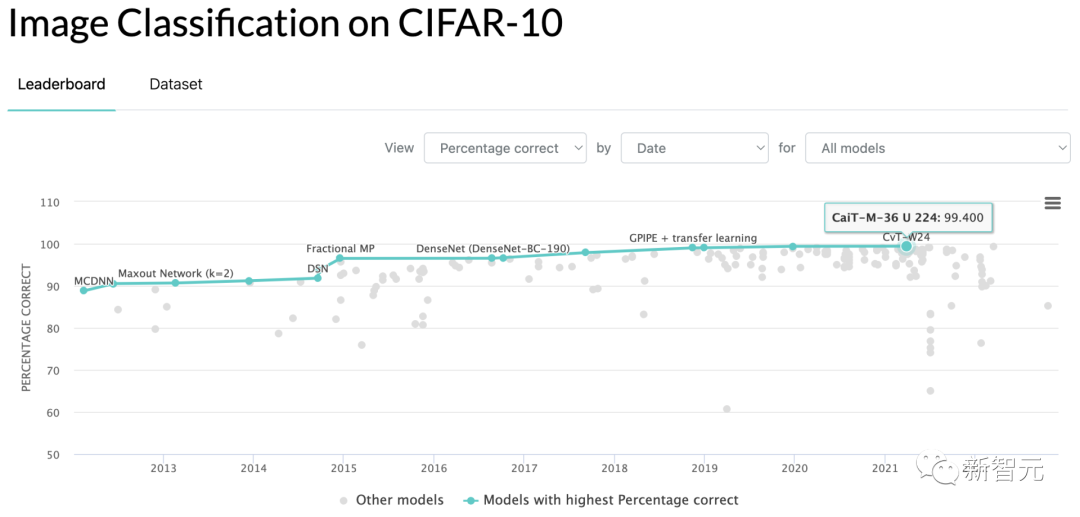
虽然论文很棒棒,但好像有人不买账。 有些热爱戳穿皇帝新衣的网友,在reddit上发帖,称他再也不相信爱情……哦不,「顶级实验室/研究机构」出品的AI论文了。 这位ID为「Acurite先生」的网友称,他自然相信这些论文里的数据与模型运行结果。 但,就拿Jeff Dean老师的这篇论文来说吧,18页的论文说了特别复杂的进化卷积与多任务学习算法,厉害,亮眼,好顶赞。 不过,有两点不得不提出: 第一,Jeff Dean们在论文中提出的证明自己胜过竞品的跑分结果,是CIFAR-10基准测试准确度99.43,胜过了当前SOTA的99.40…… 也不能说这是忽悠,但真的很让人难以措辞形容。
第二,论文末尾有用TPU跑算法得出最终结果的时间耗费表,总计17810小时。 假设有人不在谷歌干、又想复现论文结果,按照每小时3.22美元的市价租TPU来再跑一次,那花费就是57348美元。 有啥意思呢?连日常论文都要设置钞能力门槛了吗? 当然,这种做派现在是业界风气,包括但不限于谷歌、OpenAI这些大玩家。大家都往模型里灌少少改进现状的创意、和多多的预处理数据与基准。 然后,只要运行结果在数值上比对家高出哪怕百分点后的小数点后二位,研究者也可以理直气壮地在简历上新增一行论文题目啦! 这么搞,对学界和业界有啥真的推动?普通研究生又花不起钱来验证你的结论,普通企业又没法在项目里使用这么无聊的跑分。 还是那句话,有啥意思呢? 这难道就是AI界的可接受舒适区么?一小拨大企业、和偶尔的顶尖学校,天天炫耀我有钱可以为所欲为、你没钱只好跟后面吃灰? 这么玩下去,干脆另开个计算机学期刊,专收那些结果可以在消费级单机显卡上八小时跑出复现的论文算了。 跟帖里,有论文任务的研究生们纷纷诉苦。 有位ID是「支持向量机」的网友说,自己是小型实验室里的从业者,因为这个势头,已经快完全丧失继续搞深度学习的动力了。 因为靠自己实验室的预算,根本没法和这些巨无霸比,出不了钞能力打底的跑分结果。 即使你有个理论上的新点子,要写成能过评议的论文也难。因为现在论文评议人里,被大厂的钞能力养出了「美图偏见」,论文里用来测试的图像不好看,一切白搭。 不是说巨无霸大厂一无是处啊,GPT和DALL-E这些项目真的是开天辟地。但如果我自己的机器跑不动,我激动个啥呢。 另有一个博士生网友现身说法,跟帖佐证「支持向量机」。 博士生前两年递交了一份关于流模型的论文,主要着重于发现可采样的数据潜在空间,对模型的图片生成质量没影响。 结果论文打分人给的批评意见是:「生成的图像看起来不如用GAN生成的好」。 另一个ID叫「乌代」的研究生也说,2021年他提交的参加会议论文,打分人给的批评意见是:「数据不够花哨。」

看来人力不敌钞能力,真是东西心理攸同、中外道术未裂的世界性趋势。 不过三十年河东、三十年河西,说不定算法草根化、全民大写码,会带来第二次车库创业企业打败IBM的奇迹呢。
审核编辑 :李倩
-
框架
+关注
关注
0文章
403浏览量
17475 -
机器学习
+关注
关注
66文章
8406浏览量
132561 -
数据集
+关注
关注
4文章
1208浏览量
24689
原文标题:Jeff Dean大规模多任务学习SOTA遭吐槽,复现一遍要6万美元!
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
时空引导下的时间序列自监督学习框架

NPU与机器学习算法的关系
使用EMBark进行大规模推荐系统训练Embedding加速

【「大模型时代的基础架构」阅读体验】+ 第一、二章学习感受
TensorFlow与PyTorch深度学习框架的比较与选择
【大规模语言模型:从理论到实践】- 每日进步一点点
专用集成电路都是大规模的吗为什么呢
专用集成电路都是大规模的吗对吗
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
谷歌推出AI框架,实现AI模型的自然语言学习
大规模数据中心网络演进的七大主流趋势
谷歌模型框架是什么软件?谷歌模型框架怎么用?
如何选择RTOS?使用R-Rhealstone框架评估





 工商网监
工商网监
评论