 JMEE利用句法树以及GCN来建模多事件之间的关联
JMEE利用句法树以及GCN来建模多事件之间的关联
写在前面
今天要跟大家分享的是发表在EMNLP的一篇事件抽取的工作JMEE。JMEE针对的是多事件触发词及角色联合抽取问题,其中多事件是指在待处理的同一文本范围内存在多个不同事件。
同一文本范围内的多个事件间通常具有一定的相关性,对相关性进行建模将有助于消除事件触发的歧义,提高事件抽取的效果。
本文分享的JMEE首先利用句法树将输入文本从序列模式转换到句法依存图模式,以此缩短token之间信息传递的距离;然后,在句法依存图上利用图卷积来进行节点信息聚合;最后,为了利用多事件之间的关联,设计了self-attention机制来计算上下文表征向量。结合以上方法,JMEE在多事件句的事件抽取任务上相对于其他方法取得了一定的提升。

1. 背景知识
在正式开始分享论文内容之前,我们先介绍下事件抽取。按照比较标准的定义,事件抽取本身包括两个子任务:
事件检测(Event Detection):检测触发词(最能代表一个事件发生的词),同时还要正确判定其事件类型;
论元检测(Argument Detection):检测事件的相关元素,同时正确判定这些元素在这个事件中承担的角色。
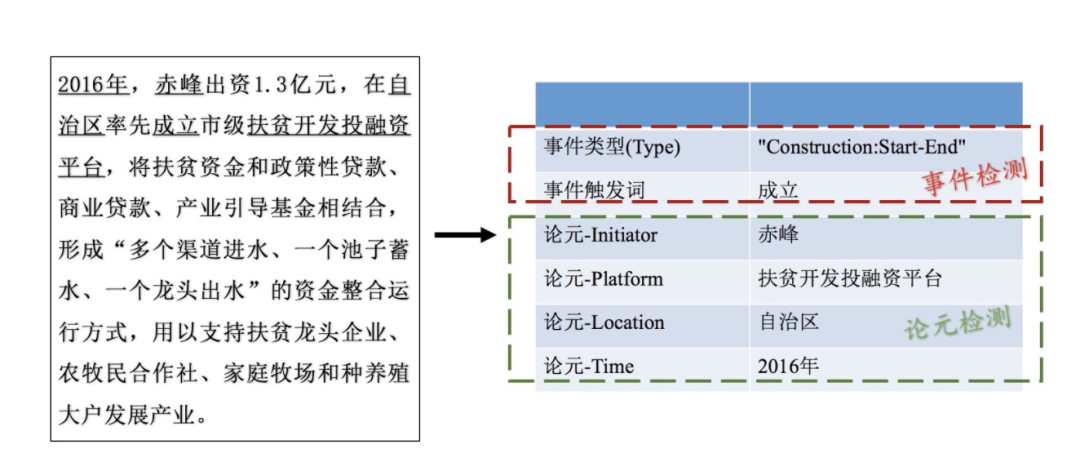
上图是一个直观的例子。图中左侧是常见的无结构化文本,右侧是事件抽取结果。事件检测发现了 "成立" 这个触发词,并且判定其事件类型为 "Construction" ;论元检测则发现了事件"construction" 发生的时间、地点、执行者以及所作用的对象。
2. 多事件
在第一节所示的例子里,一个句子中只出现了一个事件。实际上,更常见的情形是一个句子中存在多个事件:

这里暂称只含一个事件的句子为单事件句,含多个事件的句子为多事件句。相对于单事件句而言,多事件句的事件抽取是相对更难。
论文原文说 “因为多个事件之间往往是相互关联的,所以多事件抽取才更难” 。个人不太认可这个因果关系的说法。一方面,小喵觉得“多个事件判定比一个事件判定要难” 这个说法没问题,但不是因为事件之间的相关性让这个问题变得难;另一方面,事件之间的相关性真正的作用是有助于多事件场景中事件类型的判定。
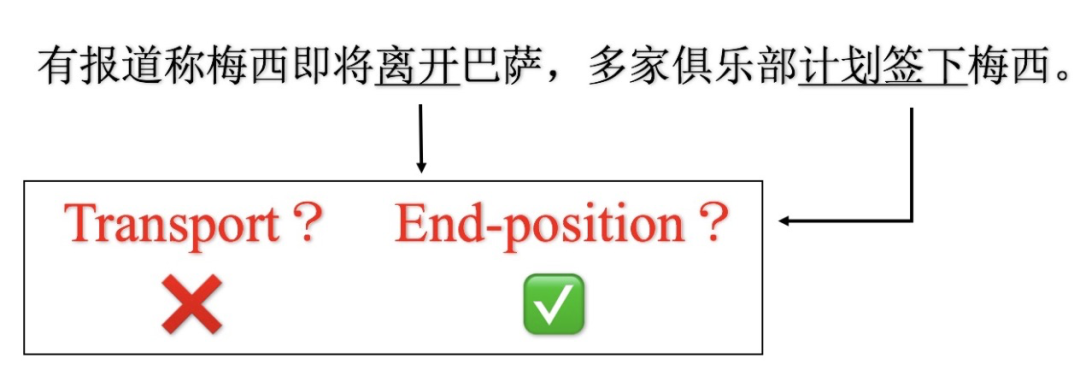
在多事件场景下单独对每一个事件进行判定很有可能出错。假设我们不知道 "巴萨" 代表的是“巴萨罗那足球俱乐部” ,那么“梅西即将离开巴萨"中的 “离开” 可能是“离开某个地方”,也可以是 “不在为球队效力” ;但是结合“计划签下”这个事件的意思,我们可以知道 “离开” 不是 “离开某个地方” 而是 “不在为球队效力”。
3. JMEE核心思想
3.1 整体思想
JMEE主要是通过引入句法树构建词网络以及后续的GCN、self-attention来捕获事件间的相关性,从而获得更好的词/字的语义表征,在此基础上再进行后续的工作。其中,引入句法树是关键的关键。
3.2 为什么要引入句法树
我们来看下为什么要引入句法树。
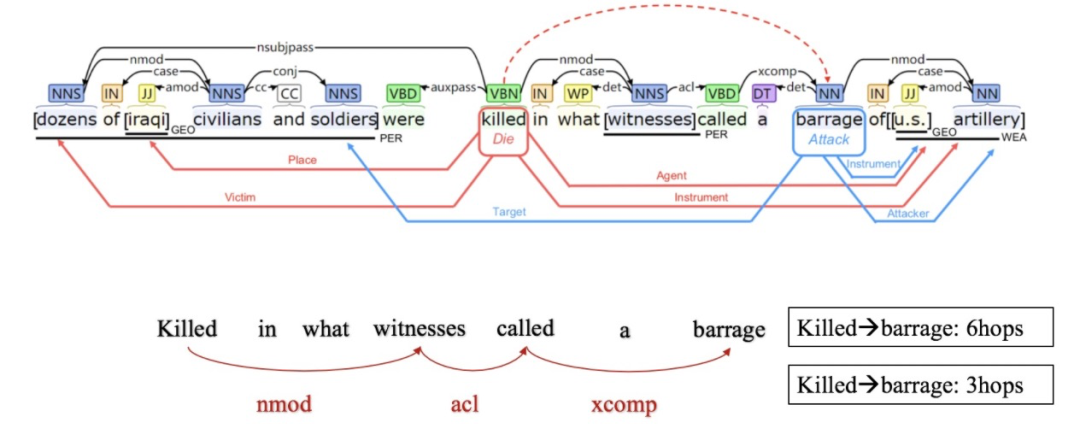
上图例子中共有两个触发词,即:“killed”和“barrage”,他们之间间隔了5个其他词。换句话说,从“killed” 到“barrage”需要6步 (6hop,6跳)。实际上,多个事件触发词之间的距离可能远大于我们例子中的6。
另一方面,句中两个词的距离往往大于其在依存树中的距离,比如“killed”和“barrage”在句子中的距离为6,但在句法树中他们的距离仅仅为3。上图底部我用红色箭头标出了3跳的路径,红色的3个箭头组成了一个shortcut path。通过这个shortcut path,我们就可以使用较少的跳数,使信息从"killed"转移向"barrage"。也就是说,从句法树建模词与词的依赖关系更容易也更直接。
所以JMEE引入句法树,利用句法树的依赖关系连接词/字,缩短词/字之间的信息传递需要的距离(跳数);此外,引入句法树后也可以自然地从图卷积的角度来进行后续的操作。
4. 模型细节
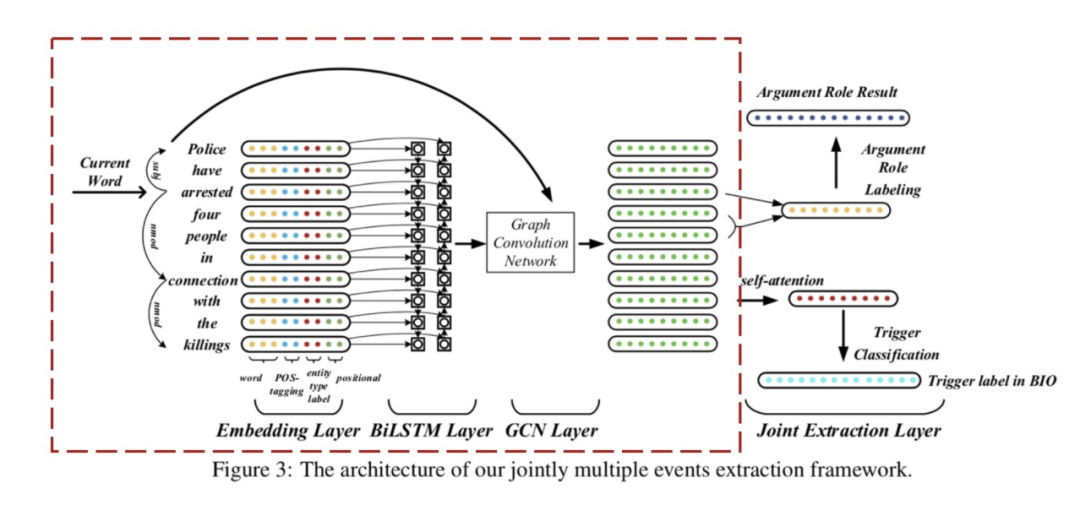
现在我们来看下JMEE模型的具体细节。JMEE整体框架大体上包括4部分:词嵌入、句法图卷积模块、触发词检测模块、论元检测模块。实际上,一直到句法图卷积模块都是在做表示学习。
4.1 词嵌入
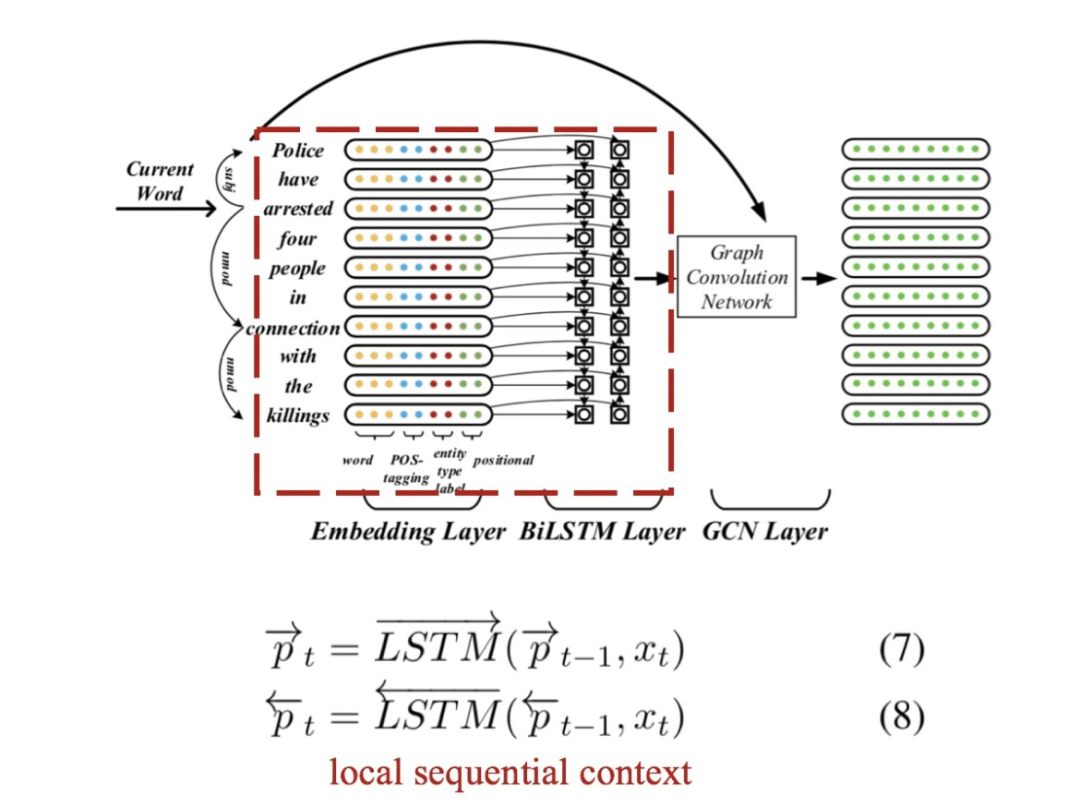
前面我们说引入句法树依赖关系后,很自然地就可以用图卷积的方式来做相应的词的表征了。但实际上,JMEE并没有一上来就这么做。因为如果完全依靠句法树里的依赖关系,某些词的左右词所涵盖的local context可能就被忽视了(本来直接一步或几步就能达到却变成需要很多步之后才能到了)。所以,JMEE选择先利用双向LSTM来捕获这种local context:
其中为输入文本中第个token(词或字)的表征向量,其利用了实体、词性、位置等信息,具体地由以下四个向量拼接而成:
的词嵌入(word embedding):从预先训练好的词向量模型中获得,JMEE选择的词向量模型为Glove;
的词性嵌入(Pos-tagging label embedding):利用随机初始化Pos-tagging label embedding table将的词性标签转换成实值向量;
的位置嵌入(Positional embedding):假设是当前词,那么为与的相对距离;利用随机初始化的Position embedding tabel将转换为实值向量;
的实体类型的嵌入:利用随机初始化的entity label embeeding label将对应的BIO实体类别标签如B-Name转换为实值向量。
LSTM层的输出作为图卷积的初始值。
4.2 图卷积
文章没有给出具体的网络图,所以下面我们直接来看公式。
图卷积部分整体上是比较简单的,把句中词/字当作网络图中的节点,利用节点的邻居来加权表征节点自己。这里的关键在于邻居节点以及边类型的定义。
节点
举个例子,假设当前节点是下图中的“arrested”,它的邻居节点就是与它通过句法依赖直接关联的词“police”、“connection”。注意,可能包括自己,因为可能有自环。
边及边类型
至于节点间的连边以及边类型,JMEE直接利用的是句法依赖关系。所以,这个例子中节点 “police“ 与节点 “arrested”,连边类型为:
节点“police“ 与节点 “connection” 相连,连边类型为:
图卷积
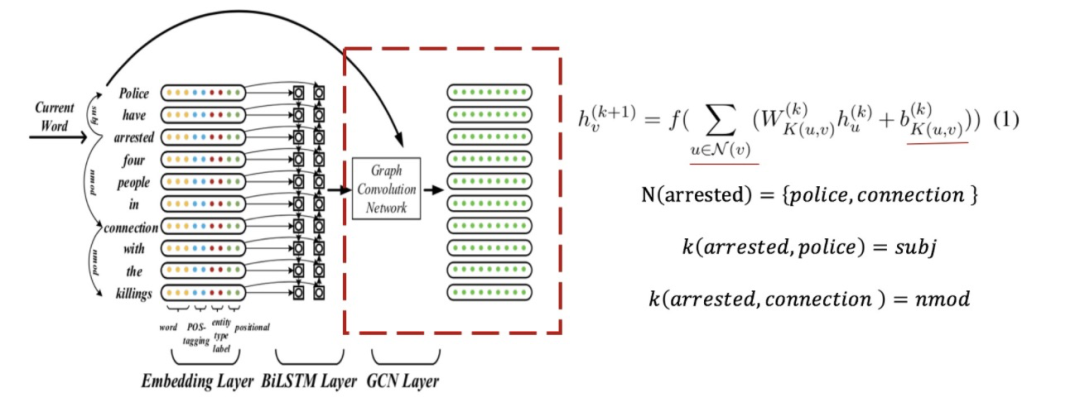
图卷积模块的第层,节点的图卷积向量为:
这里表示边(u,v)的类型标签;而、则分别是与类型标签的相关的权重参数和偏置参数;是激活函数;词嵌入模块的最终输出,即。
连边类别重新定义
假设,句法依赖关系共有种,再加上反向边和自环后,一层图卷积层就会有个权重参数和偏置参数,这个参数量太大了。为了减少参数量,JMEE重新定义了边类型,最终只维护了3种类型标签:
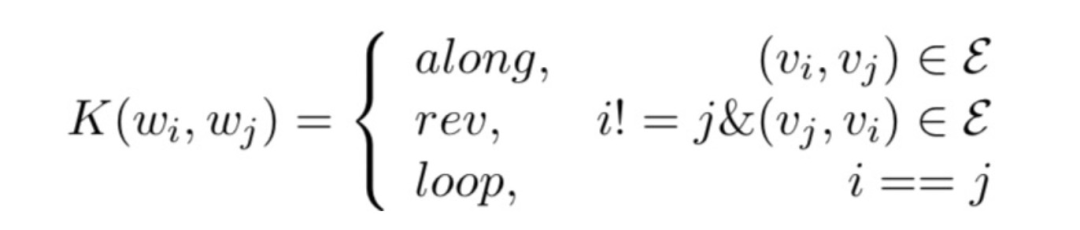
门控机制、highway units
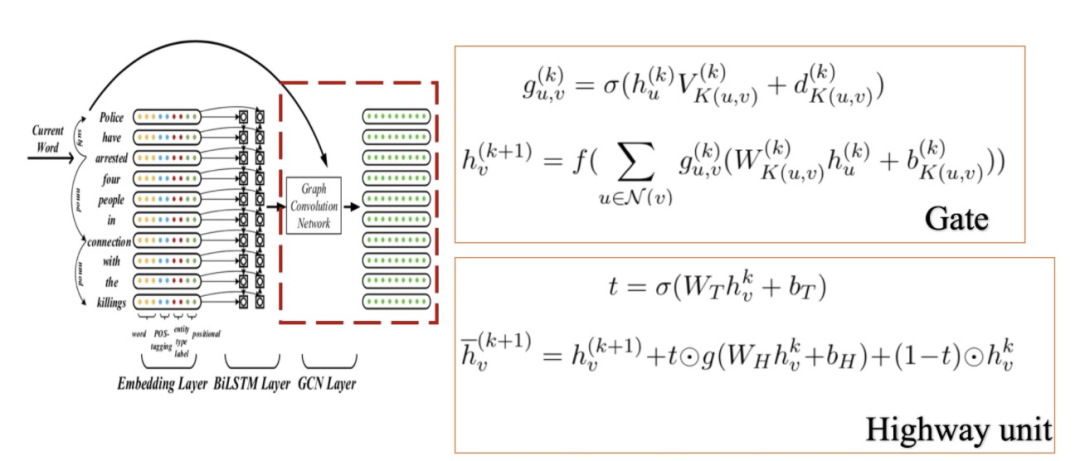
前面图卷积的公式相当于每次卷积的时候每个邻居都对当前节点的表征做了贡献。但实际上,不是所有的邻居或者说所有的边都是有益于表征的,有些词可能会增加歧义性。所以,JMEE增加门控机制,为有不同类型标签的边分配不同的权重,这也可以看成是加权邻居的贡献:
其中,为边的权重。图卷积存在一个问题,即over-smooth/information over propagation。换句话说,节点在拓扑上互相传播信息,利用其他节点的信息更新自己的信息(汇聚节点信息),当卷积深度不断增加时,处于同一连通分支的节点的表征会趋于一致。针对这个问题,JMEE增加了highway units。最终在原始信息、转移信息加新的表征信息共同作用下,获得节点的图卷积向量:
这里,通常被称为transform gate,则称为carry gate。个人觉得这个思想与跟残差网络思想(允许原始输入信息直接传输到后面的层中)类似。
4.3 事件、论元检测
事件检测和事件论元检测部分都是分类模型。

将每个token(词/字)做为当前token,再经过词嵌入及句法图卷积模块都获得了所有token的向量表示。进一步,为了利用事件触发词之间的关联关系,JMEE设计了self-attention机制用于信息聚合。简单地说,JMEE认为在判断一个token的触发词标签时需要考虑到其他可能的触发词的信息,比如前面例子中的“离开”与“计划签下”。具体地,假设(文本序列中的第个token)为当前token,那么与之相关的上下文向量按如下方式计算:
这里代表归一化操作。可以看到主要由两部分组成,其一是的向量,其二是其余token的向量按attention权重加权后的表征。
事件检测
对进行触发词标签判定,只需要将其上下文向量送入一个简单的分类器,如下:
这里的是非线性激活函数,最终就是的触发词标签。JMEE标签体系选取的是BIO,所以经过事件检测模块就可以得到类似于序列标注的结果如“O,...,O,B-Name,I-Name,O,...,O,B-Loc,I-Loc,I-Loc,O,...,O”。我们基于这个结果序列就可以获得候选事件触发词。
论元检测
显然候选事件触发词、实体都是连续的文本片段(即tokens的子序列)。对每一对候选触发词和实体,我们从向量中获得其相关子序列中每个token的向量,然后利用max-pooling汇聚向量信息获得候选触发词的向量以及实体的向量。将和拼接后送入全连接层进行论元角色的判定:
结果表示的是第个实体在第个候选触发词所对应的事件中扮演的角色。这里需要补充一点,一般事件抽取认为输入文本中的实体即是候选论元,所以JMEE做论元检测时同于对实体进行角色分类。
5. 实验
5.1 实验数据
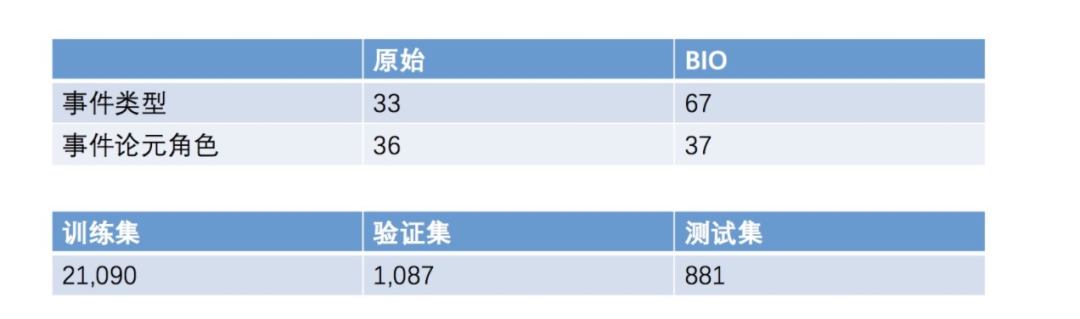
实验数据选择的是ACE2005,下面是它的具体信息:
5.2 实验结果
整体性能比对
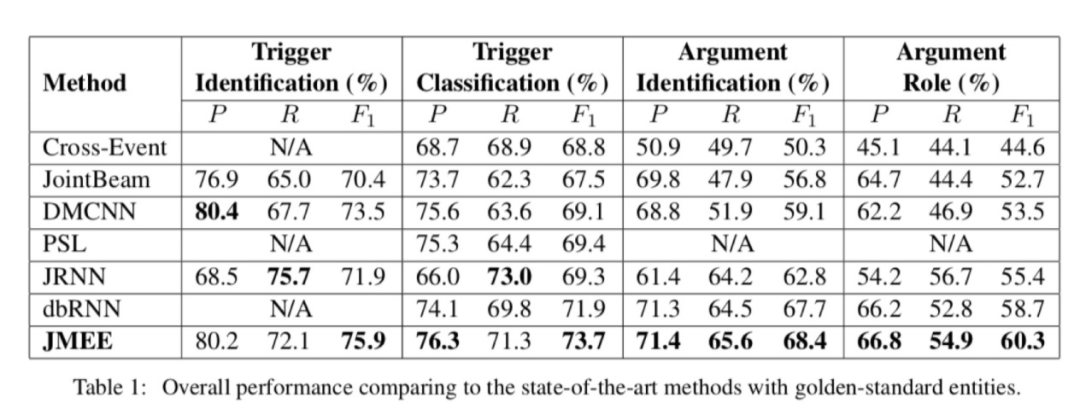
从JMEE与其他方法的整体性能比对结果来看,无论是在事件检测(触发词识别、触发词分类)还是论元检测(论元识别、论元角色分类),JMEE都取得了最佳的效果。
单事件、多事件场景比对
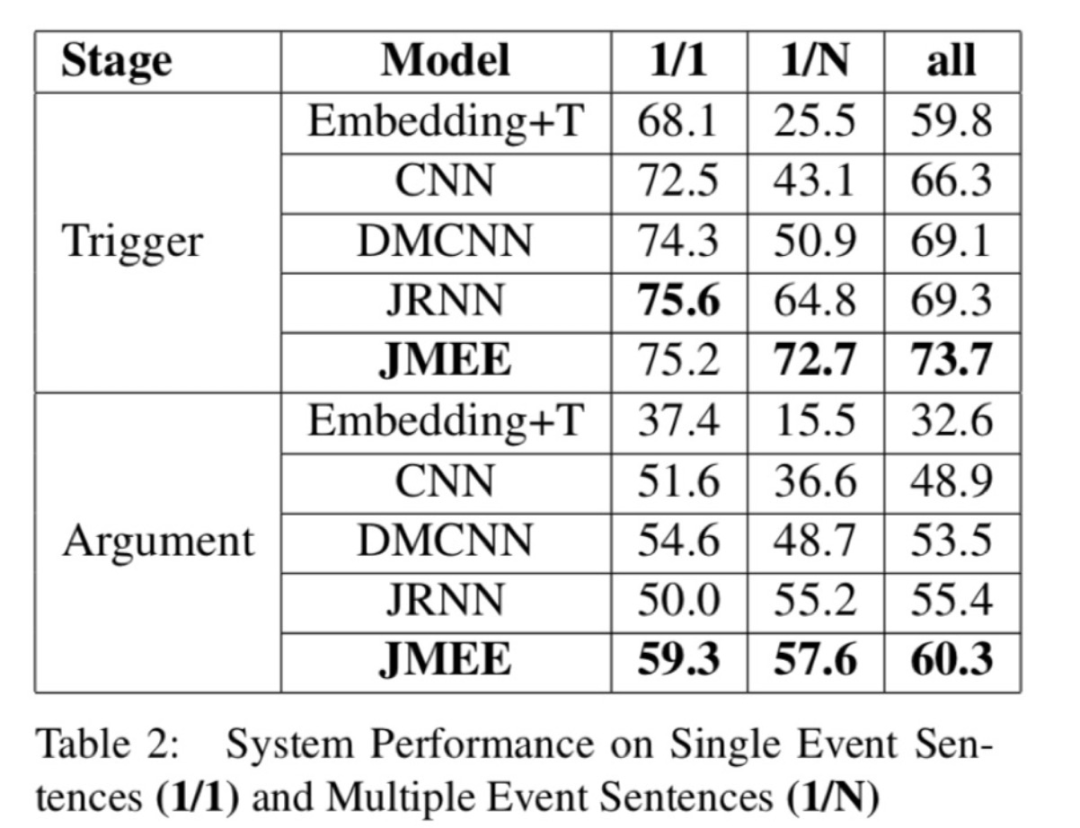
从 纯粹的单事件抽取(1/1) 和 纯粹的多事件抽取(1/N) 比对结果来看,在多事件抽取场景下,尤其在事件检测任务上JMEE相对于对比方法的提升更大。
总结
今天我们分享了事件抽取模型JMEE,它主要是利用了句法树、GCN以及self-attention来建模多事件之间的关联,从而提升多事件场景下事件抽取的效果。
审核编辑:刘清
-
图卷积网络
+关注
关注
0文章
8浏览量
1524 -
GCN
+关注
关注
0文章
5浏览量
2306 -
LSTM
+关注
关注
0文章
60浏览量
3812
原文标题:一文详解多事件抽取模型JMEE
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种基于决策树的飞机级故障诊断建模方法研究
依存句法分析器的简单实现
基于CRF序列标注的中文依存句法分析器的Java实现
基于本体和句法分析的领域分词的实现
基于集合枚举树的最小预测集挖掘算法
利用UML映射工具实现系统可靠性建模
Quasi-TreeIJSTMs一种针对句法树的混合神经网络模型的介绍和实验分析
什么是Transition-based基于转移的框架?
自然语言处理中极其重要的句法分析
什么是句法分析





 工商网监
工商网监
评论