 跨语言命名实体识别:无监督多任务多教师蒸馏模型
跨语言命名实体识别:无监督多任务多教师蒸馏模型
前言 这是一篇来自于 ACL 2022 的关于跨语言的 NER 蒸馏模型。主要的过程还是两大块:1)Teacher Model 的训练;2)从 Teacher Model 蒸馏到 Student Model。采用了类似传统的 Soft 蒸馏方式,其中利用了多任务的方式对 Teacher Model 进行训练,一个任务是 NER 训练的任务,另一个是计算句对的相似性任务。整体思路还是采用了序列标注的方法,也是一个不错的 IDEA。

论文标题:
An Unsupervised Multiple-Task and Multiple-Teacher Model for Cross-lingual Named Entity Recognition
论文链接:
https://aclanthology.org/2022.acl-long.14.pdf
模型架构
2.1 Teacher Model
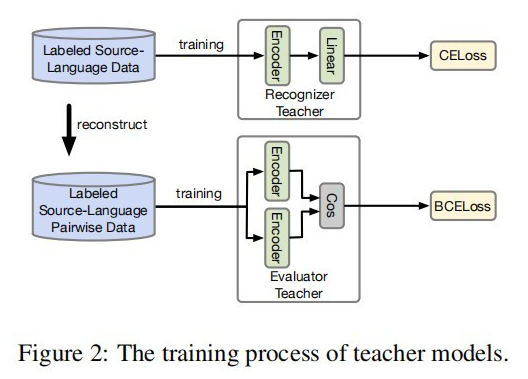
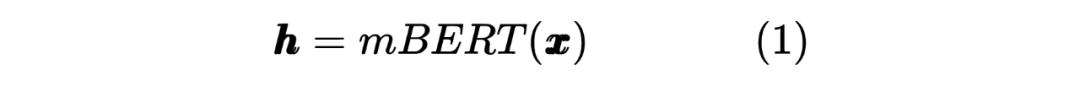
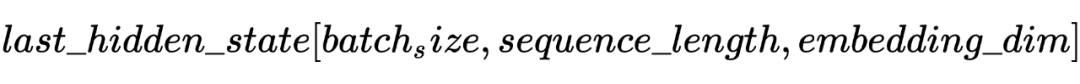
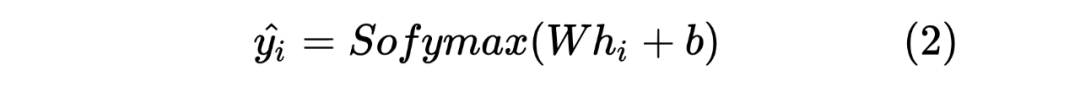
以上就是 Teacher Model 的第一个任务,直接对标注序列进行 NER,并且采用交叉熵损失函数作为 loss_function,计算如下:
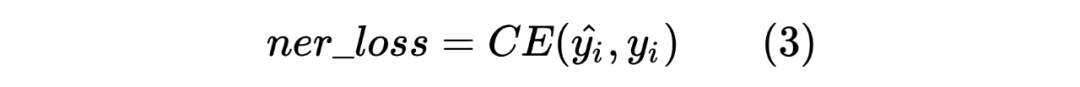
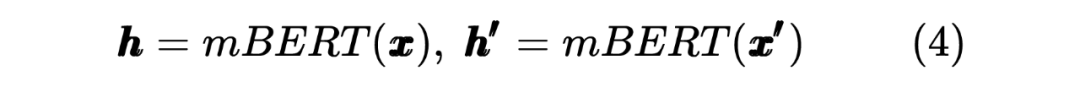
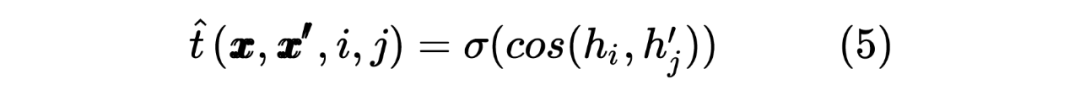
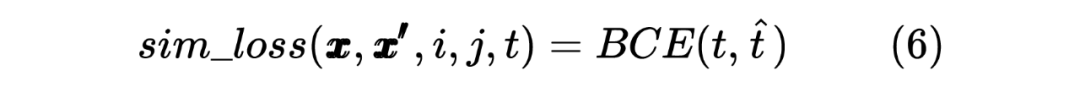
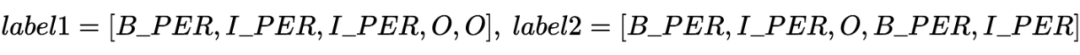
2.2 Student Model Distilled
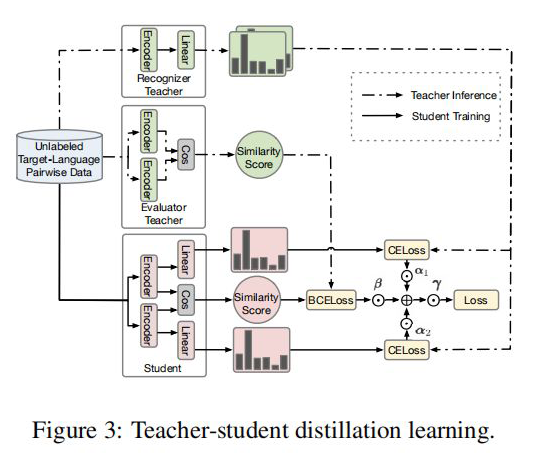
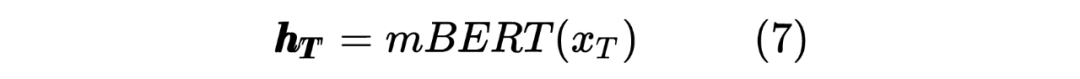
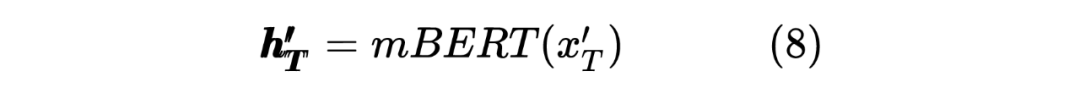
获得两个序列的hidden_state后进行一个线性计算,然后利用softmax进行归一化,得到每个Token预测的标签,计算如下:
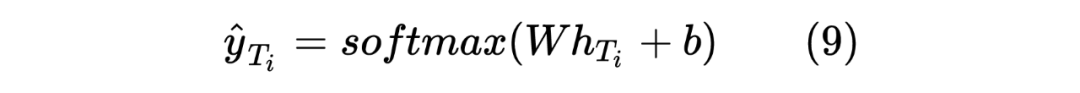
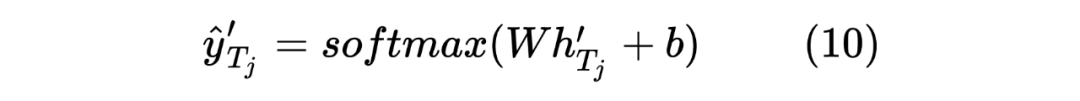
这里也类似 Teacher Model 的计算方式,计算 target 序列间的Token相似度,计算如下所示:
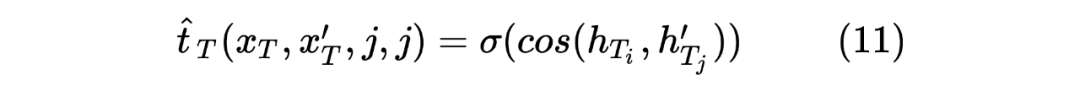
当然,这里做的是蒸馏模型,所以对于输入到 Student Model 的序列对,也是Teacher Model Inference 预测模型的输入,通过 Teacher Model 的预测计算得到一个 teacher_ner_logits 和 teacher_similar_logits,将 teacher_ner_logits 分别与 和 通过 CrossEntropyLoss 来计算 TS_ _Loss 和 TS_ _Loss,teacher_similar_logits 与 通过 计算 Similar_Loss,最终将几个 loss 进行相加作为 DistilldeLoss。
这里作者还对每个 TS_ _Loss,TS_ _Loss 分别赋予了权重 ,对 Similar_Loss 赋予了权重 ,对最终的 DistilldeLoss 赋予权重 ,这样的权重赋予能够使得 Student Model 从 Teacher Model 学习到的噪声减少。最终的 Loss 计算如下所示:
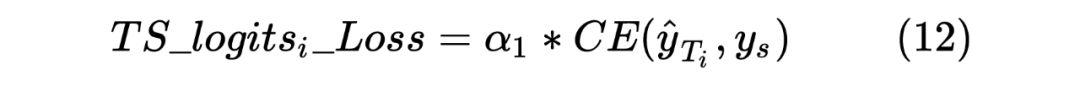
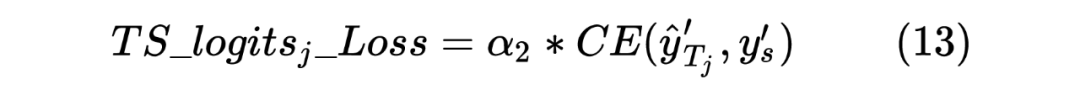
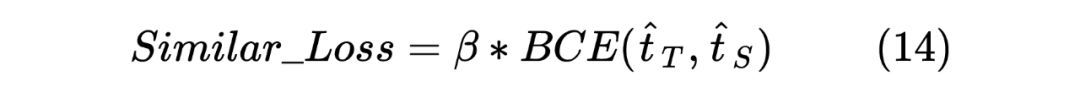
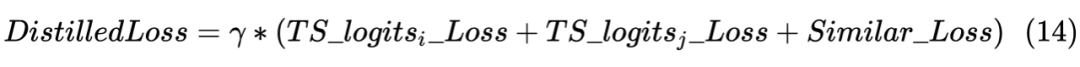
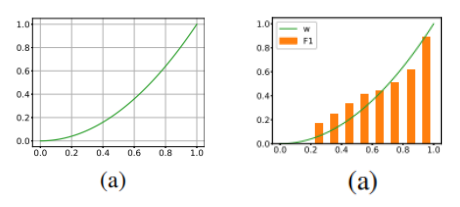
这里的权重 笔者认为是用来控制 Student Model 学习倾向的参数,首先对于 来说,由于 Student Model 输入的是 Unlabeled 数据,所以在进行蒸馏学习时,需要尽可能使得 Student Model 的输出的 student_ner_logits 来对齐 Teacher Model 预测输出的 teacher_ner_logits,由于不知道输入的无标签数据的数据分布,所以设置一个权重参数来对整个 Teacher Model 的预测标签进行加权,将各个无标签的输入序列看作一个数据量较少的类别。这里可以参考 在进行数据标签不平衡时使用权重系数对各个标签进行加权的操作。而且作者也分析了, 参数是一个随着 Teacher Model 输出而递增的一个参数。如下图所示:
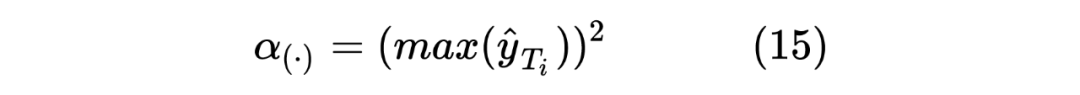
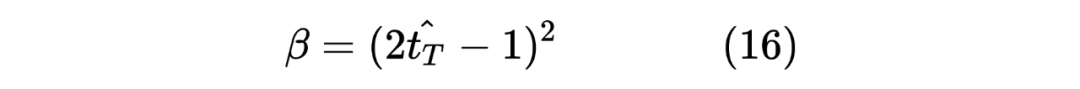
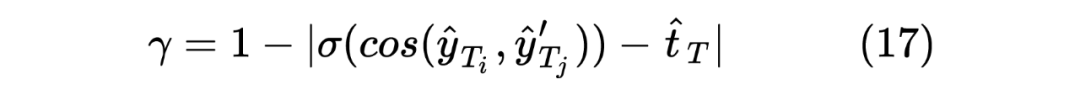
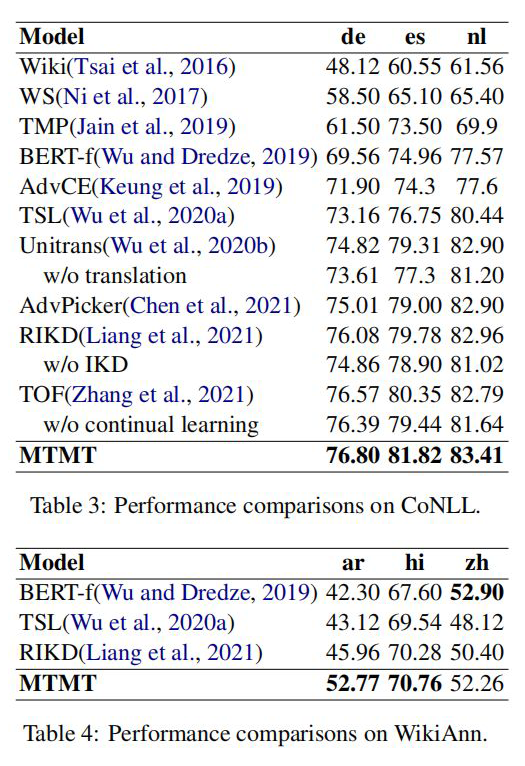
实验结果
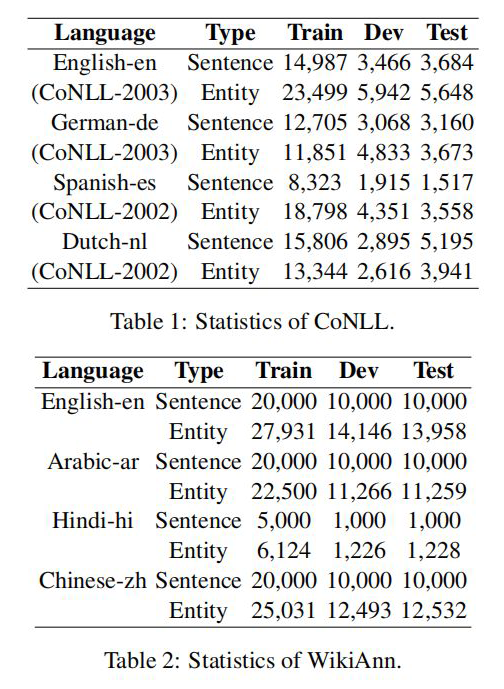
作者分别在 CoNLL 和 WiKiAnn 数据集上进行了实验,数据使用量如下图所示:
简单代码实现
#!/usr/bin/envpython
#-*-coding:utf-8-*-
#@Time:2022/5/3013:59
#@Author:SinGaln
"""
AnUnsupervisedMultiple-TaskandMultiple-TeacherModelforCross-lingualNamedEntityRecognition
"""
importtorch
importtorch.nnasnn
importtorch.nn.functionalasF
fromtransformersimportBertModel,BertPreTrainedModel,logging
logging.set_verbosity_error()
classTeacherNER(BertPreTrainedModel):
def__init__(self,config,num_labels):
"""
teacher模型是在标签数据上训练得到的,
主要分为三个encoder.
:paramconfig:
:paramnum_labels:
"""
super(TeacherNER,self).__init__(config)
self.config=config
self.num_labels=num_labels
self.mbert=BertModel(config=config)
self.fc=nn.Linear(config.hidden_size,num_labels)
defforward(self,batch_token_input_ids,batch_attention_mask,batch_token_type_ids,batch_labels,training=True,
batch_pair_input_ids=None,batch_pair_attention_mask=None,batch_pair_token_type_ids=None,
batch_t=None):
"""
:parambatch_token_input_ids:单句子token序列
:parambatch_attention_mask:单句子attention_mask
:parambatch_token_type_ids:单句子token_type_ids
:parambatch_pair_input_ids:句对token序列
:parambatch_pair_attention_mask:句对attention_mask
:parambatch_pair_token_type_ids:句对token_type_ids
"""
#RecognizerTeacher
single_output=self.mbert(input_ids=batch_token_input_ids,attention_mask=batch_attention_mask,
token_type_ids=batch_token_type_ids).last_hidden_state
single_output=F.softmax(self.fc(single_output),dim=-1)
#EvaluatorTeacher(类似双塔模型)
pair_output1=self.mbert(input_ids=batch_pair_input_ids[0],attention_mask=batch_pair_attention_mask[0],
token_type_ids=batch_pair_token_type_ids[0]).last_hidden_state
pair_output2=self.mbert(input_ids=batch_pair_input_ids[1],attention_mask=batch_pair_attention_mask[1],
token_type_ids=batch_pair_token_type_ids[1]).last_hidden_state
pair_output=torch.sigmoid(torch.cosine_similarity(pair_output1,pair_output2,dim=-1))#计算两个输出的cosine相似度
iftraining:
#计算loss,训练时采用平均loss作为模型最终的loss
loss1=F.cross_entropy(single_output.view(-1,self.num_labels),batch_labels.view(-1))
loss2=F.binary_cross_entropy(pair_output,batch_t.type(torch.float))
loss=loss1+loss2
returnsingle_output,loss
else:
returnsingle_output,pair_output
classStudentNER(BertPreTrainedModel):
def__init__(self,config,num_labels):
"""
student模型采用的也是一个双塔结构
:paramconfig:mBert的配置文件
:paramnum_labels:标签数量
"""
super(StudentNER,self).__init__(config)
self.config=config
self.num_labels=num_labels
self.mbert=BertModel(config=config)
self.fc1=nn.Linear(config.hidden_size,num_labels)
self.fc2=nn.Linear(config.hidden_size,num_labels)
defforward(self,batch_pair_input_ids,batch_pair_attention_mask,batch_pair_token_type_ids,batch_pair_labels,
teacher_logits,teacher_similar):
"""
:parambatch_pair_input_ids:句对token序列
:parambatch_pair_attention_mask:句对attention_mask
:parambatch_pair_token_type_ids:句对token_type_ids
"""
output1=self.mbert(input_ids=batch_pair_input_ids[0],attention_mask=batch_pair_attention_mask[0],
token_type_ids=batch_pair_token_type_ids[0]).last_hidden_state
output2=self.mbert(input_ids=batch_pair_input_ids[1],attention_mask=batch_pair_attention_mask[1],
token_type_ids=batch_pair_token_type_ids[1]).last_hidden_state
soft_output1,soft_output2=self.fc1(output1),self.fc2(output2)
soft_logits1,soft_logits2=F.softmax(soft_output1,dim=-1),F.softmax(soft_output2,dim=-1)
alpha1,alpha2=torch.square(torch.max(input=soft_logits1,dim=-1)[0]).mean(),torch.square(
torch.max(soft_logits2,dim=-1)[0]).mean()
output_similar=torch.sigmoid(torch.cosine_similarity(soft_output1,soft_output2,dim=-1))
soft_similar=torch.sigmoid(torch.cosine_similarity(soft_logits1,soft_logits2,dim=-1))
beta=torch.square(2*output_similar-1).mean()
gamma=1-torch.abs(soft_similar-output_similar).mean()
#计算蒸馏的loss
#teacherlogits与studentlogits1的loss
loss1=alpha1*(F.cross_entropy(soft_logits1,teacher_logits))
#teachersimilar与studentsimilar的loss
loss2=beta*(F.binary_cross_entropy(soft_similar,teacher_similar))
#teacherlogits与studentlogits2的loss
loss3=alpha2*(F.cross_entropy(soft_logits2,teacher_logits))
#finalloss
loss=gamma*(loss1+loss2+loss3).mean()
returnloss
if__name__=="__main__":
fromtransformersimportBertConfig
pretarin_path="./pytorch_mbert_model"
batch_pair1_input_ids=torch.randint(1,100,(2,128))
batch_pair1_attention_mask=torch.ones_like(batch_pair1_input_ids)
batch_pair1_token_type_ids=torch.zeros_like(batch_pair1_input_ids)
batch_labels1=torch.randint(1,10,(2,128))
batch_labels2=torch.randint(1,10,(2,128))
#t(对比两个序列标签,相同为1,不同为0)
batch_t=torch.as_tensor(batch_labels1.numpy()==batch_labels2.numpy()).float()
batch_pair2_input_ids=torch.randint(1,100,(2,128))
batch_pair2_attention_mask=torch.ones_like(batch_pair2_input_ids)
batch_pair2_token_type_ids=torch.zeros_like(batch_pair2_input_ids)
batch_all_input_ids,batch_all_attention_mask,batch_all_token_type_ids,batch_all_labels=[],[],[],[]
batch_all_labels.append(batch_labels1)
batch_all_labels.append(batch_labels2)
batch_all_input_ids.append(batch_pair1_input_ids)
batch_all_input_ids.append(batch_pair2_input_ids)
batch_all_attention_mask.append(batch_pair1_attention_mask)
batch_all_attention_mask.append(batch_pair2_attention_mask)
batch_all_token_type_ids.append(batch_pair1_token_type_ids)
batch_all_token_type_ids.append(batch_pair2_token_type_ids)
config=BertConfig.from_pretrained(pretarin_path)
#teacher模型训练
teacher_model=TeacherNER.from_pretrained(pretarin_path,config=config,num_labels=10)
outputs,loss=teacher_model(batch_token_input_ids=batch_pair1_input_ids,
batch_attention_mask=batch_pair1_attention_mask,
batch_token_type_ids=batch_pair1_token_type_ids,batch_labels=batch_labels1,
batch_pair_input_ids=batch_all_input_ids,
batch_pair_attention_mask=batch_all_attention_mask,
batch_pair_token_type_ids=batch_all_token_type_ids,
training=True,batch_t=batch_t)
#student模型蒸馏
teacher_logits,teacher_similar=teacher_model(batch_token_input_ids=batch_pair1_input_ids,
batch_attention_mask=batch_pair1_attention_mask,
batch_token_type_ids=batch_pair1_token_type_ids,
batch_labels=batch_labels1,
batch_pair_input_ids=batch_all_input_ids,
batch_pair_attention_mask=batch_all_attention_mask,
batch_pair_token_type_ids=batch_all_token_type_ids,
training=False)
student_model=StudentNER.from_pretrained(pretarin_path,config=config,num_labels=10)
loss_all=student_model(batch_pair_input_ids=batch_all_input_ids,
batch_pair_attention_mask=batch_all_attention_mask,
batch_pair_token_type_ids=batch_all_token_type_ids,
batch_pair_labels=batch_all_labels,teacher_logits=teacher_logits,
teacher_similar=teacher_similar)
print(loss_all)
笔者自己实现的一部分代码,可能不是原论文作者想表达的意思,读者有疑问的话可以一起讨论一下^~^。
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
编码器
+关注
关注
45文章
3664浏览量
135142 -
模型
+关注
关注
1文章
3298浏览量
49147 -
标签
+关注
关注
0文章
137浏览量
17919
原文标题:ACL2022 | 跨语言命名实体识别:无监督多任务多教师蒸馏模型
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
自然语言基础技术之命名实体识别相对全面的介绍
早期的命名实体识别方法基本都是基于规则的。之后由于基于大规模的语料库的统计方法在自然语言处理各个方面取得不错的效果之后,一大批机器学习的方法也出现在命名实体类
HanLP分词命名实体提取详解
可能词) 5.极速词典分词(速度快,精度一般) 6.用户自定义词典 7.标准分词(HMM-Viterbi) 命名实体识别 1.实体机构名识别(层叠HMM-Viterbi) 2.中国人名
发表于 01-11 14:32
基于结构化感知机的词性标注与命名实体识别框架
`上周就关于《结构化感知机标注框架的内容》已经分享了一篇《分词工具Hanlp基于感知机的中文分词框架》,本篇接上一篇内容,继续分享词性标注与命名实体识别框架的内容。词性标注训练词性标注是分词后紧接着
发表于 04-08 14:57
基于神经网络结构在命名实体识别中应用的分析与总结
近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展。作为NLP领域的基础任务—命名实体识别(Named Entity Recognition,NER)也不例外,神经

深度学习:四种利用少量标注数据进行命名实体识别的方法
整理介绍四种利用少量标注数据进行命名实体识别的方法。 面向少量标注数据的NER方法分类 基于规则、统计机器学习和深度学习的方法在通用语料上能取得良好的效果,但在特定领域、小语种等缺乏标注资源的情况下,NER 任务往往得
思必驰中文命名实体识别任务助力AI落地应用
验阶段走向实用化。近期,思必驰语言与知识团队对中文细粒度命名实体识别任务进行探索,并取得阶段性进展:在CLUE数据集Fine-Grain NER评测
新型中文旅游文本命名实体识别设计方案
传统基于词向量表示的命名实体识别方法通常忽略了字符语义信息、字符间的位置信息,以及字符和单词的关联关系。提出一种基于单词字符引导注意力网络( WCGAN)的中文旅游命名实体识别方法,利
发表于 03-11 11:26
•24次下载

知识图谱与训练模型相结合和命名实体识别的研究工作
本次将分享ICLR2021中的三篇投递文章,涉及知识图谱与训练模型相结合和命名实体识别(NER)的研究工作。 文章概览 知识图谱和语言理解的联合预训练(JAKET: Joint
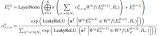

基于字语言模型的中文命名实体识别系统
造成的数据稀缺问题,以及传统字向量不能解决的一字多义问題,文中使用在大规模无监督数据上预训练的基于上下文相关的字向量,即利用语言模型生成上下文相关字向量以改进中文NER
发表于 04-08 14:36
•14次下载

基于神经网络的中文命名实体识别方法
在基于神经网络的中文命名实体识别过程中,字的向量化表示是重要步骤,而传统的词向量表示方法只是将字映射为单一向量,无法表征字的多义性。针对该问题,通过嵌入BERT预训练语言模型,构建BE
发表于 06-03 11:30
•3次下载
关于边界检测增强的中文命名实体识别
引言 命名实体识别(Named Entity Recognition,NER)是自然语言处理领域的一个基础任务,是信息抽取等许多任务的子





 工商网监
工商网监
评论