 实体关系抽取模型CasRel
实体关系抽取模型CasRel

写在前面
今天来跟大家分享一篇发表在2020ACL上的实体关系抽取论文CasRel。
论文名称:《A Novel Cascade Binary Tagging Framework forRelational Triple Extraction》
论文链接:https://aclanthology.org/2020.acl-main.136.pdf
代码地址:https://github.com/weizhepei/CasRel
1. 关系抽取任务定义
实体关系抽取(关系抽取)是构建知识图谱非常重要的一环,其旨在识别实体之间的语义关系。换句话说,关系抽取就是从非结构化文本即纯文本中抽取实体关系三元组(SRO)。这里 代表头实体, 代表关系, 代表尾实体。

上图展示了3个例子:
第一句文本中,“刘翔”和“上海”两个实体之间的语义关系是“出生地”。
第二句文本中,“张艺谋”与“菊豆”两个实体之间的语义关系是“导演”。
第三句文本中,“史蒂夫.乔布斯”与“苹果”之间的语义关系是“创始人”。
2. 关系抽取方法
关系抽取方法主要可分为两类:
管道学习方法(pipeline):管道学习方法通常先抽取句子中的实体,然后再对实体对进行关系分类,从而找出SRO三元组。
联合学习方法(Joint):联合学习方法同时进行实体识别和实体对的关系分类两个子任务。
许多实验证明联合学习方法由于考虑了两个子任务之间的信息交互,大大提升了实体关系抽取的效果,所以目前针对实体关系抽取任务的研究大多采用联合学习方法。
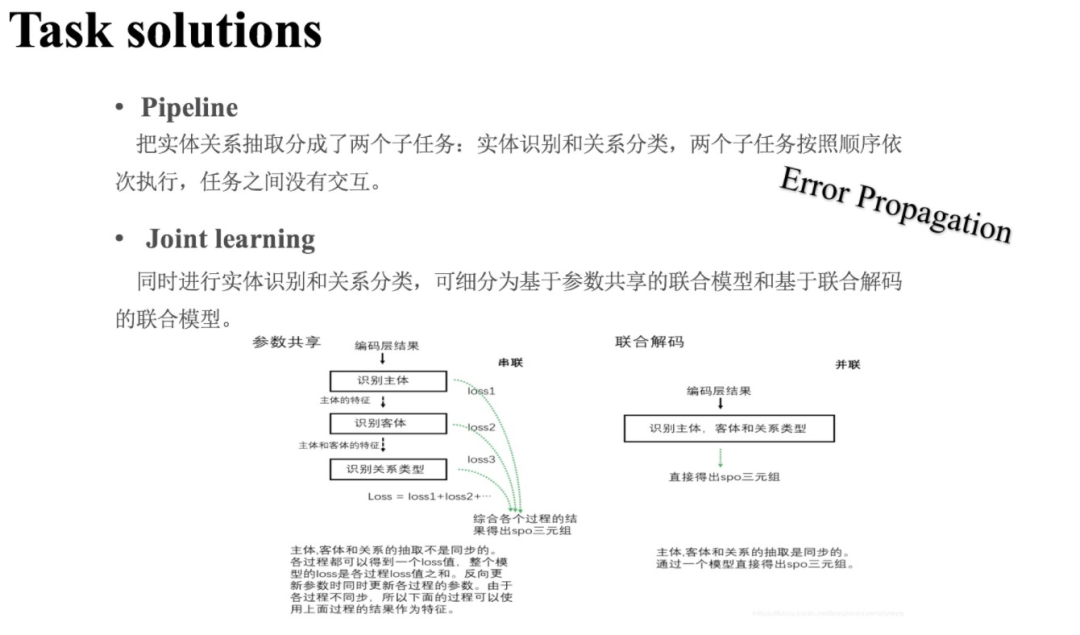
进一步地,联合学习方法又可以细分为以下两种:基于参数共享的联合模型;基于联合解码的联合模型。另一方面,解码方式对实体关系抽取性能的影响也很大,主要的解码方式有三种:基于序列标注;基于指针网络;基于片段分类。
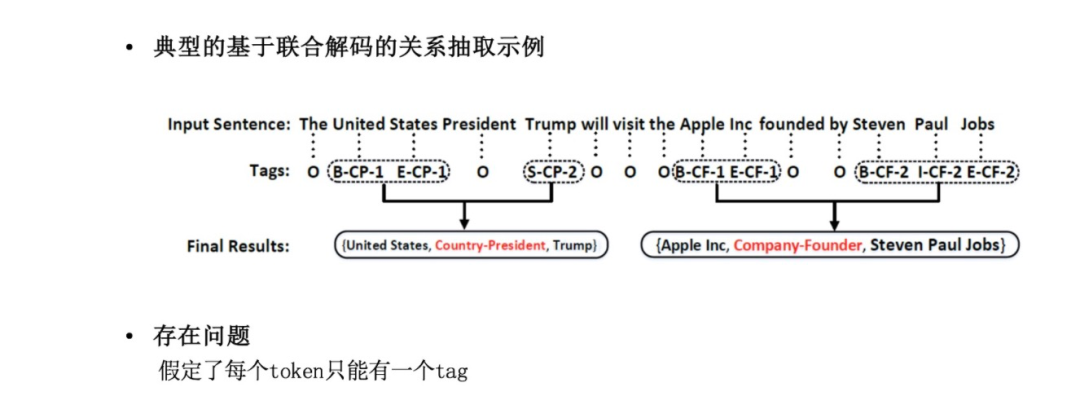
《Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme》[1]是采用序列标注的联合解码的典型方法。简单地说,它将实体关系抽取当作了序列标注问题,设计了比较特别的标注标签可以实现实体、关系的联合抽取(如上图所示)。
3. 关系抽取难点

如上图所示,和大多数的自然语言处理任务一样,关系抽取同样有许多难点。我们今天所分享的CasRel关注的难点主要是三元组的重叠问题(实体关系重叠),即:输入文本中有多个实体关系三元组,彼此之间可能共享了某些实体。
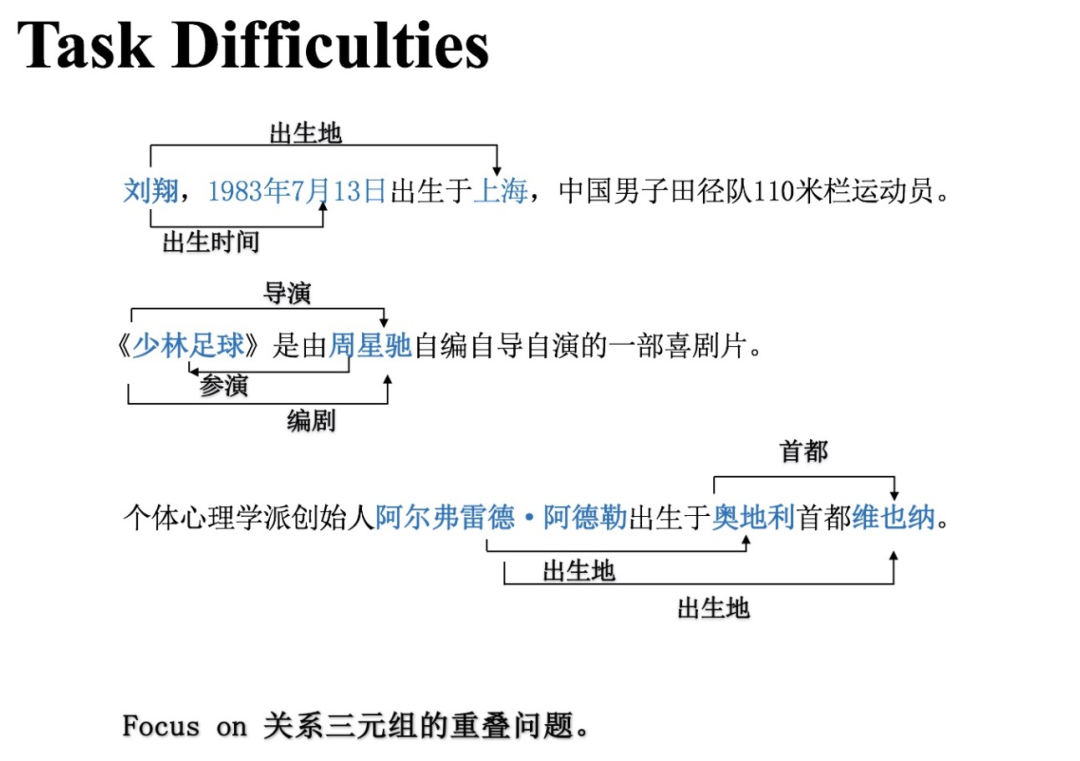
上图给出了部分示例:
(刘翔, 出生地, 上海)与(刘翔, 出生时间, 1983年7月13日)都有“刘翔”;
(《少林足球》, 导演, 周星驰)、(《少林足球》, 编剧, 周星驰)、(周星驰, 参演, 《少林足球》)都有“《少林足球》”和“周星驰”;
(阿尔弗雷德.阿德勒, 出生地, 奥地利)与(阿尔弗雷德.阿德勒, 出生地, 维也纳)都有“阿尔弗雷德.阿德勒”..
前面我们所提的联合解码模型由于其标签设计或CRF层限定了每个token只能有一个tag,所以无法适用于实体关系重叠情况。此外,基于参数共享的关系抽取方法最后通常是一个多分类层,也就是一对实体只能有一个标签。简单地将其改成多标签分类就能一定程度上解决实体关系重叠问题,但是这种改进并不具备什么创新性。
那接下来我们就来看看CasRel是如何另辟蹊径来解决实体关系重叠问题的。
4. CasRel核心思想
CasRel本质上也是基于参数共享的联合实体关系抽取方法,它通常被大家称作层叠指针网络。实际上,CasRel的核心思想或者说作者改进现有模型的重点在于子层的设计。
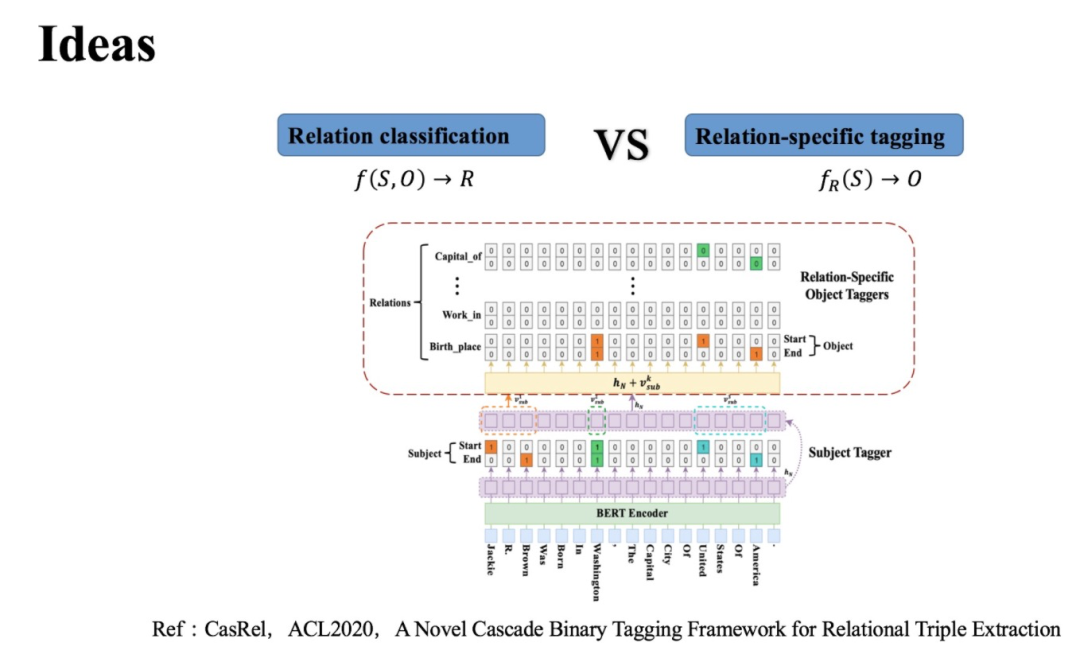
因为CasRel对于关系抽取这个任务的拆分不同,所以子任务及子任务求解顺序也不同。具体地:首先CasRel 会识别所有可能的主语(头实体);然后在给定类别关系 下,再去识别与主语相关的宾语(尾实体)。
更形式化的表达:如果说以前关系抽取/关系分类是这样一个映射函数 ,;那么现在在CasRel中关系抽取对应的映射函数则是 。
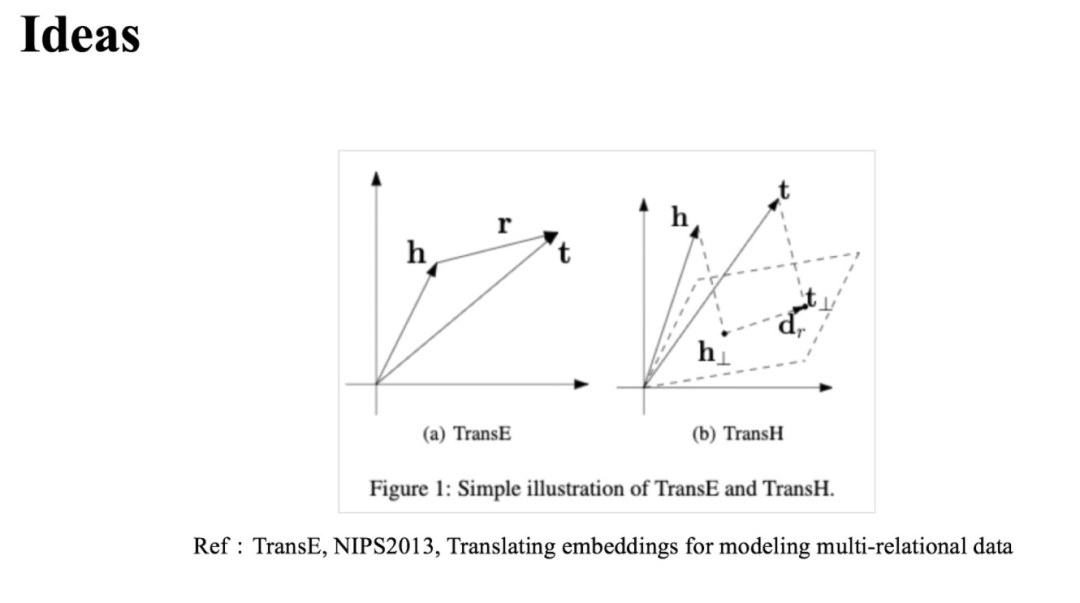
与之相似的思想很早之前就有出现在知识图谱表示学习方法当中,比如在下图的 TransE[2]模型中就有 (这里 为头实体, 为尾实体)。
5. 模型细节

现在我们再来看CasRel的模型细节。CasRel是一个基于联合解码的实体关系抽取模型,其思想和模型都很简单,主要包括三层:
编码端:基于BERT的编码层用于获取上下文语义信息对字/词进行表征;
解码端:解码端主要包括了头实体识别层、关系与尾实体联合识别层。
在这里,基于BERT的编码层我们就不做过多的介绍了,感兴趣的读者可以下载论文《Pre-trained Models for Natural Language Processing》进行阅读学习。接下来,我们将着重介绍CasRel的解码端。
5.1 头实体识别层
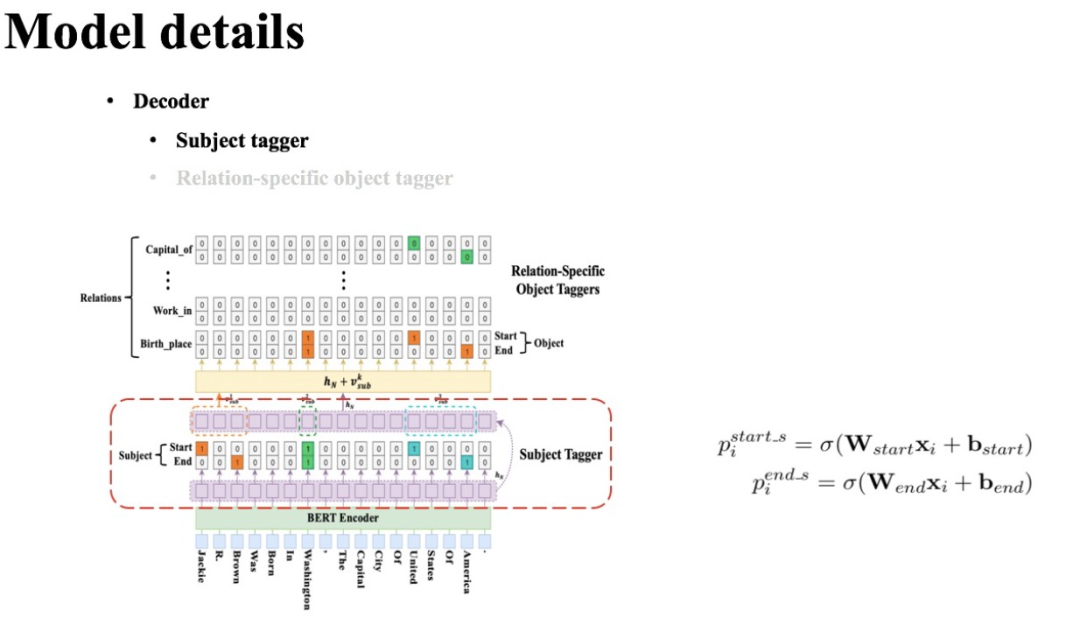
CasRel的头实体识别层直接对编码层的结果进行解码,去识别所有可能的头实体。这里CasRel是识别头实体span,也就是start和end位置,所以它采用的是二分类。这点和我们在实体识别BERT-MRC论文阅读笔记、实体识别LEAR论文阅读笔记中类似。
因此,模型本身很简单:
首先,利用一个线性层一个sigmoid激活函数判断每个token是不是头实体的开始token或结束token;
然后,利用最近匹配原则将识别到的start和end配对获得候选头实体集合。
5.2 关系、尾实体联合识别层
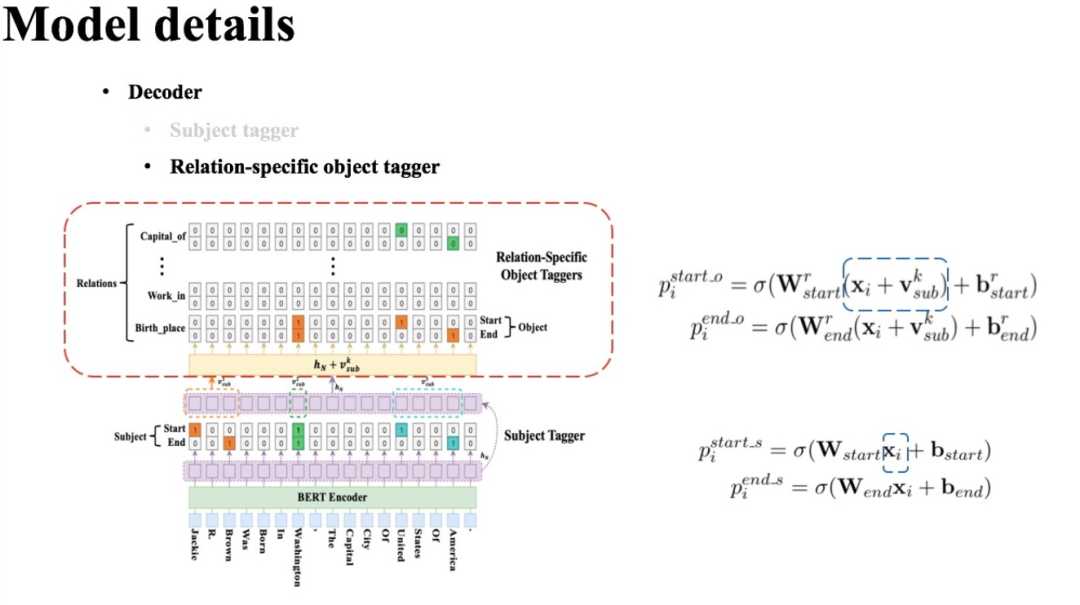
识别头实体后就要进行关系和尾实体的联合识别了。这里,CasRel是通过一组关系相关的尾实体识别层来实现的。每一层尾实体识别层的结构其实与头实体识别层是一样的,不同主要在于输入:
头实体识别层的输入直接就是编码层的输出;
而尾实体识别层的输入还考虑了头实体的特征:
这里 是第 个候选头实体所包含的所有token的向量的平均。
5.3 概率解释
最后,我们从概率角度来看CasRel模型。
既然实体关系抽取任务就是识别文本中潜在的实体关系三元组,那么模型的优化目标可以直接建立在三元组这个层面上。
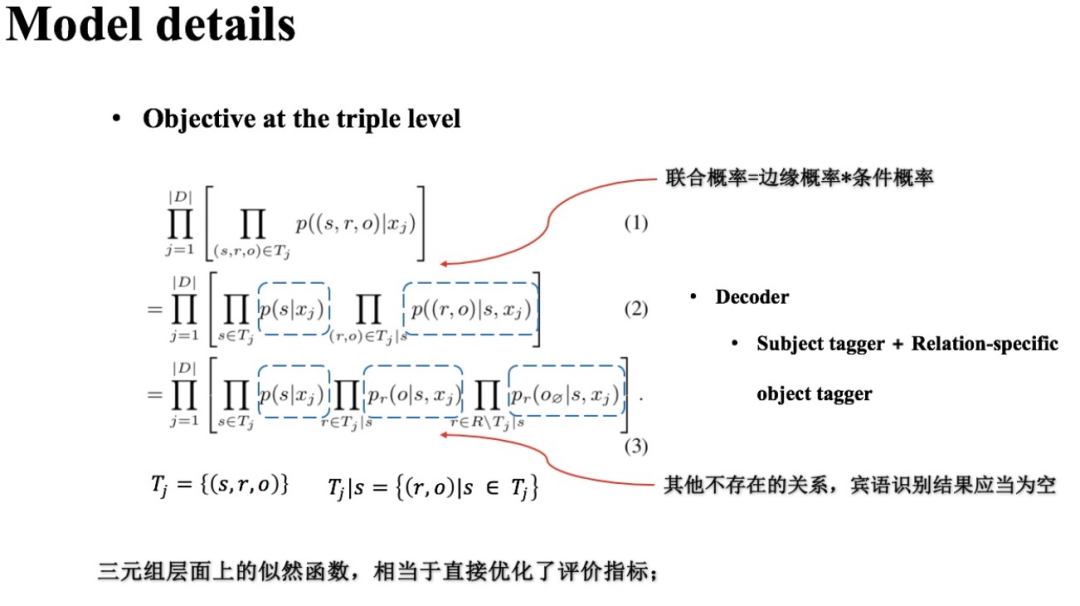
(1) 优化目标
假设 为训练集, 是第 个输入样本, 是文本 中含有的所有三元组,CasRel的训练目标自然是如下似然函数值最大:
(2) 概率公式变换
根据联合概率=边缘概率*条件概率,我们有:
这里 表示出现在 中的一个头实体, 表示出现在 中且其头实体为 的一组关系-尾实体对。 为先验概率, 为条件概率。
(3) 关系作为先验知识
然后,把关系作为先验知识,我们可以进一步把上式右端第二项拆成两部分,即出现在 中且头实体为 的关系、其他关系:
这里, 是所有关系的集合, 表示出现在 中且头实体为 的一组关系, 是 与 的差集,也就是没有出现在 中的其他关系。
表示对于文本 与头实体 以及没有出现在 中的关系 来说,尾实体识别结果应当为空。所以最终我们有:
(4) 结论
可以发现最终这个式子与CasRel抽取实体关系三元组的子任务顺序一致:
首先识别文本中所有可能的头实体;
然后在每个关系类别下,去抽取与识别到的头实体存在该关系的所有可能的尾实体。
另一方面,这个任务拆解方式也很自然解决了重叠实体关系三元组的提取问题。
5.4 实验
实验主要在两个公开的数据集NYT和WebNLG上进行。此外,需要注意的是CasRel模型本身还有两个变体:
:表示编码端的BERT参数是随机初始化的;
:表示编码端使用的是LSTM而不是BERT。
当然CasRel则表示采用预训练好的BERT作为编码端。
(1) 整体实验效果对比
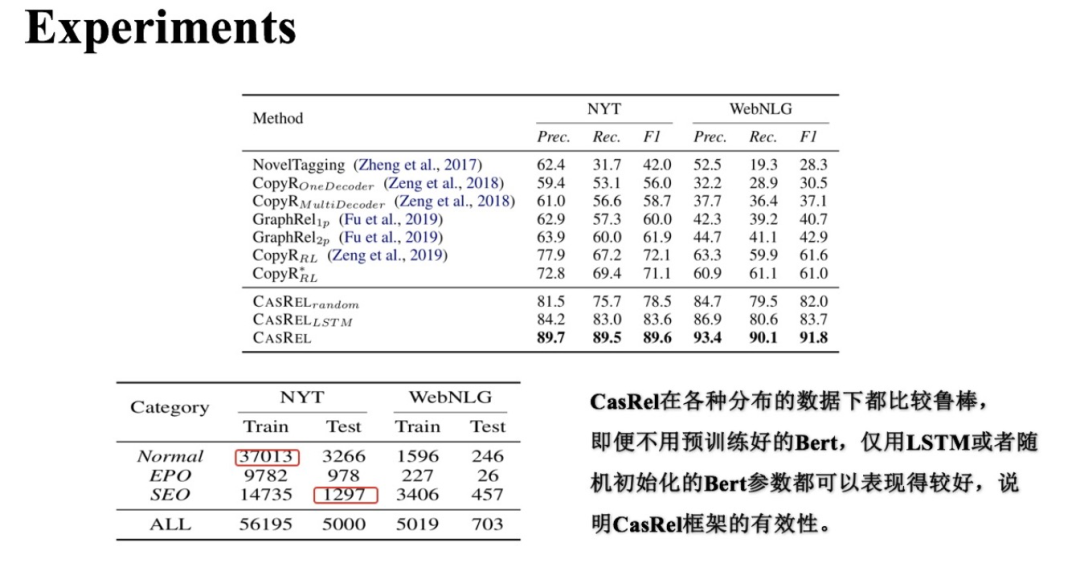
上图中展示了CasRel及其变体模型与其他基准方法在两个数据集上的效果。可以看到CasRel及其变体的效果都高于其他方法;尤其在WebNLG数据上,相对提升得更多。仔细看NYT、WebNLG两个数据分布差异还是蛮大的:
NYT、WebNLG两个数据中都有Normal类型的三元组、SEO类型的三元组、EPO类型的三元组,且三者在两个数据集中占比不同;
Normal、SEO、EPO分别代表常规实体关系三元组、单个实体重叠的实体关系三元组、实体对重叠的实体关系三元组;
NYT中的实体关系三元组类型多为Normal类型,即数据中常规实体关系三元组居多。
WebNLG中的实体关系三元组多为SEO类型,即单个实体重叠的实体关系三元组居多。
CasRel在两个数据集上相对稳定的表现说明了在实体关系重叠这种复杂场景下,其框架的有效性。
(2) 不同三元组重叠类型实验对比
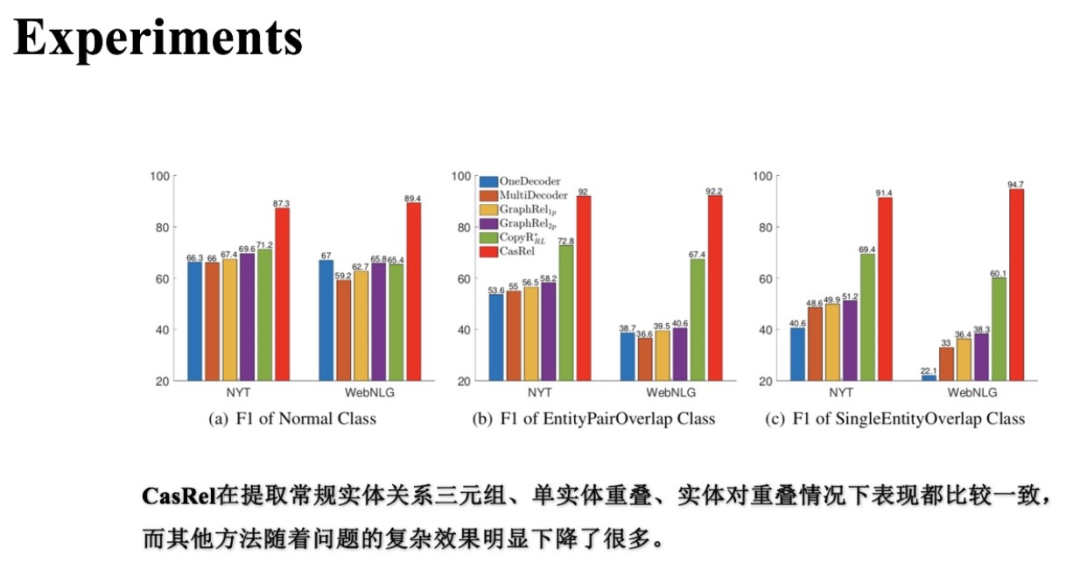
上图展示了在不同三元组重叠类型的样本上各个基准方法与CasRel的实验结果。可以发现随着场景逐渐复杂(Normal->EPO、SEO),基准方法的效果都逐渐下降,但CasRel则取得了相对稳定且优异的表现。这个对比实验进一步说明了CasRel在重叠三元组场景下的有效性。
(3) 不同三元组个数实验对比
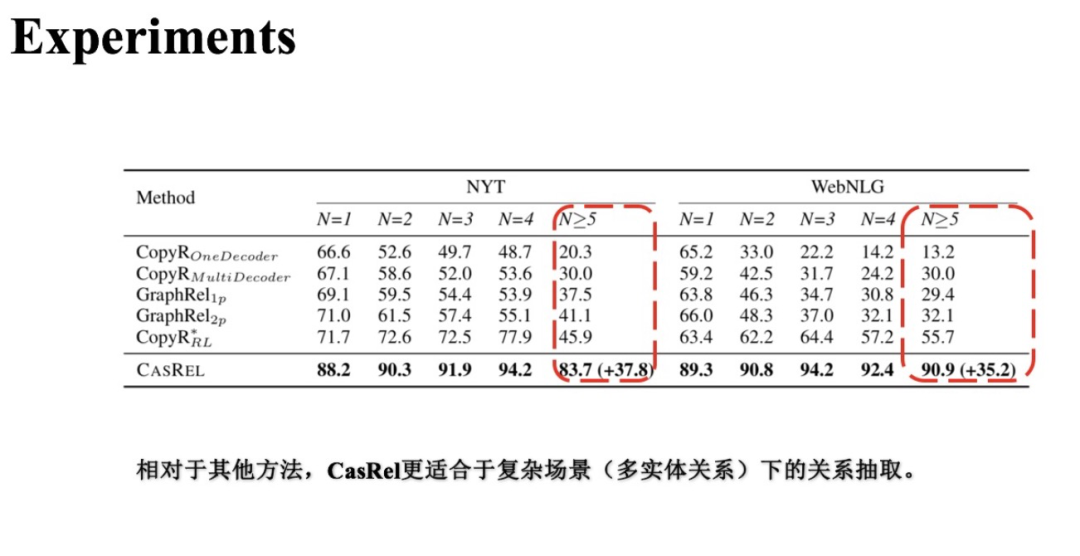
随着样本中三元组个数的增多,每个方法的效果都或多多少地受到了影响。尤其在 即多于五个三元组的样本上,基准方法效果基本都大幅度下降,而CasRel相对要好一些。同时,在 的样本上CasRel的效果相对于基准方法提升的最多。
这个对比实验反映了CasRel相比其他基准方法在处理多实体关系三元组下的能力更强。
6. 延伸思考
CasRel的思想可以很自然地迁移到上去信息抽取中的另一大任务事件抽取上,因为在事件抽取同样存在一些类似的挑战:
输入文本里面存在多个事件;
事件论元可能重叠,同一个论元可能扮演不同的角色、同一个角色下也可能有多个论元:同一个事件论元可能重叠;不同事件之间论元可能重叠。
6.1 事件抽取任务描述
事件抽取任务可拆为两个子任务:
事件检测(event detection):即触发词的抽取和事件类型判断;
事件论元识别(argument extraction):即识别事件论元并判断论元所扮演的角色。
6.2 CasRel范式迁移到事件抽取
阿墨最初看到CasRel时就想到它的层叠指针范式可以迁移到事件抽取中:
建模思路和子任务顺序:CasRel建模思路(TransE 中也是类似的)是“头实体+关系=尾实体”,即CasRel先抽头实体,再抽关系和尾实体;迁移到事件抽取中,可以是“触发词+角色=论元”即先抽触发词,再抽角色和论元。
模型适配:CasRel 模型中的头实体识别子结构适配到事件抽取中触发词检测,CasRel模型中的关系尾实体识别子结构适配到事件论元识别。这样就完成了事件检测任务中的触发词抽取、事件论元识别任务,那么事件类型判定呢?
事件类型判定:事件类型判定既可在触发词检测完后做,即仅对触发词分类,也可以在最后结合触发词/论元/角色信息进行事件分类。
小改动完成完全适配:如果考虑“原文+事件类型=触发词”,那么实际上事件类型判定和触发词抽取可一并完成。只需要把用于抽取触发词子结构换成和用于事件论元识别子结构类似或者说一致即可。
实际上,在2020年阿墨进行事件抽取相关实验过程中,陆陆续续就有这个系列的工作出来如:JMCEE[3]、PLMEE[4] 及CasEE[5]。CasEE代码也开源了,阿墨去年也在上面进行了一些实验。文末附上了相关论文链接,感兴趣的读者可下载阅读。
总结
今天我们分享了实体关系抽取模型CasRel,并在最后联系事件抽取做了一些延伸思考。
审核编辑 :李倩
-
模型
+关注
关注
1文章
3831浏览量
52289 -
知识图谱
+关注
关注
2文章
132浏览量
8359
原文标题:一文详解关系抽取模型 CasRel
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介
零基础手写大模型资料2026
PCIe 5.0 E1.S硬盘盒重磅上市!可抽取式托盘+主动散热,免开箱秒换SSD


知识分享-嵌入式系统可靠性模型




思必驰空调大模型解决方案
【硬盘抽取盒民主实验】你的真话,决定产品命运!敢说就送!




评论