 分布式架构为AI工作负载提供有效的解决方案
分布式架构为AI工作负载提供有效的解决方案
人工智能 (AI) 在相对较短的时间内从科幻小说变成了我们生活中不可或缺的一部分。当您想到 AI 时,您可能会想到能够在国际象棋、围棋或“危险”中超越人类的自动驾驶汽车或计算机。现实情况是,你会发现人工智能应用无处不在——在定制的谷歌新闻源、潘多拉播放列表、Netflix 推荐、智能扬声器语音识别、智能助手中的自然语言处理、车辆中的计算机视觉、智能工厂——还有无数更多的例子。当您从亚马逊购物时,机器学习 (ML) 会在幕后工作,从提出购买建议到将点击发货时间缩短到仅 15 分钟。
随着人工智能应用程序对消费者越来越重要,数十亿美元现在在商业世界中处于危险之中。例如,97% 的手机用户使用人工智能语音助手。Siri 或 Cortana 误解的语音命令对我们来说可能是一个小麻烦,但在语音助手市场上的失败代表了苹果、亚马逊和谷歌之间的竞争中损失了数十亿美元的份额 。还有更严重的挑战——错误的自动驾驶算法或医疗保健行业的误诊可能导致致命后果和法律影响。
让 AI 结果具有相关性、可靠性和易于获得性是一场竞赛。只有那些在最好的机器/深度学习基础设施上训练过的人工智能模型,来自最大的数据集,才能生存下来。
ML/深度学习:不是您的平均计算工作量
机器学习——尤其是它的子集——深度学习系统——构成了人工智能基础设施的基础。抛开复杂的数学问题不谈,最简单的 ML 算法通过对答案进行重复“猜测”来实现一个目标(例如,成功识别手写符号),并通过检查预期答案来从每个不准确的猜测中学习,直到猜测以非常高的准确度匹配预期的答案。这种反馈结构称为神经网络,训练神经网络是机器/深度学习的过程。图 1 显示了一个用于手写识别的相对简单的神经网络示例。
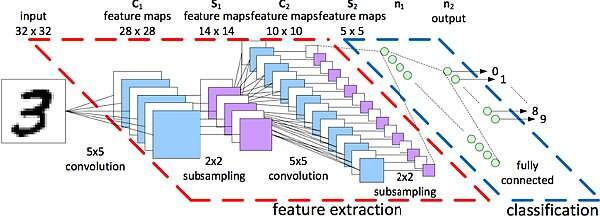
图1 用于手写识别的神经网络示例[6]
深度神经网络使用更多层来获得复杂目标的准确答案。深度学习过程使用不断增加的训练数据集来训练深度神经网络。目标越复杂,神经网络中的层数就越多,神经网络就越难训练。例如,百度的中文语音识别模型使用约 12,000 小时的语音训练数据,需要数十 exaflops 的计算,这需要长达六周的时间才能完成。图像识别工作负载的计算要求呈指数级增长。
传统的中央处理器 (CPU) 专为通用控制数据流而设计,对于 AI/ML 计算密集型工作负载效率不高。由于摩尔定律失效,供应商无法跟上 CPU 的速度或大到足以处理 AI/ML 工作负载的速度。
分布式机器学习:摩尔定律的治愈方法
设计用于处理 AI/ML 工作负载的现代服务器遵循分散式架构 - 一个由多个专用加速器包围的通用 CPU,用于处理从 ML 到加密、安全、存储和网络的任务。加速器可以是图形处理单元 (GPU)、定制的现场可编程门阵列 (FPGA) 或定制的专用集成电路的组合。开放计算项目 (OCP) [10] 最近发布了 OCP 加速器模块 (OAM)的通用外形规格,以简化服务器设计并实现模块化服务器架构。
分散式架构通过使用多个优化的数据处理器提供原始 exaflops。然而,为了实现更大规模的机器学习,处理单元需要相互充分连接。在 2018 年分布式计算原理研讨会上的演讲展示了使用 TensorFlow在 ResNet-152 图像分类方面的速度提高了近 10 倍。
图 2中显示的 ResNet-152 图像分类示例 还强调了连接性在现代高度分布式机器学习系统中的重要性,其中多达 90% 的时间可能用于节点通信。
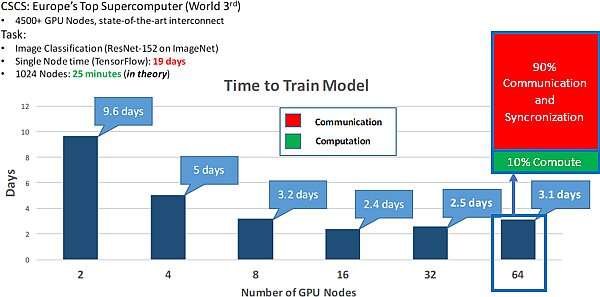
图 2 分布式机器学习的好处 - 19 天到 2.4 天
审核编辑:郭婷
-
AI
+关注
关注
87文章
31133浏览量
269463 -
机器学习
+关注
关注
66文章
8425浏览量
132770
发布评论请先 登录
相关推荐
分布式、域控及SOA架构车身功能测试方案
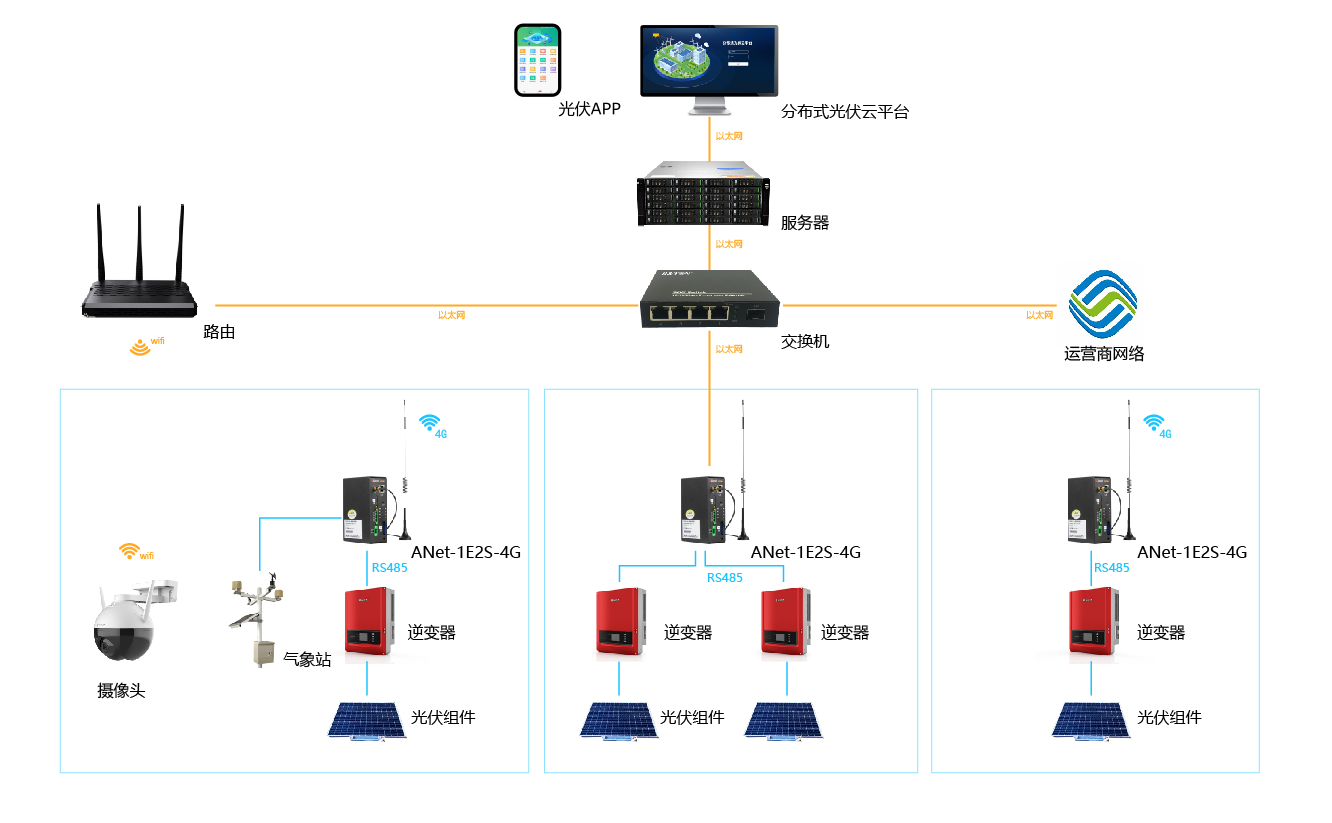
分布式光伏为企业带来哪些便捷!

一文讲清什么是分布式云化数据库!

一体式IO与分布式IO:工业控制系统的两种架构

浪潮信息发布AS13000G7-N系列分布式全闪存储
超越期待:StarlingX 9.0 正式面世,为企业提供可信赖、经济实惠的分布式云解决方案

分布式存储与计算:大数据时代的解决方案
分布式智慧终端:挑战与解决方案
什么是分布式架构?






 工商网监
工商网监
评论