 大模型技术发展背景
大模型技术发展背景
本文根据澜舟科技创始人兼 CEO 周明、澜舟大模型技术负责人王宇龙在「澜舟NLP分享会」演讲整理,带领大家回顾过去 12 个月以来,国内外大模型的发展趋势,包括百花齐放的国产大模型、新秀不断涌现的多模态模型、萌芽中的通用能力模型等等,并对大模型新应用、预训练框架等方面的进展进行了总结。
大模型技术发展背景
此前十余年,人工智能在“感知智能”方面进展非常迅速,涌现了“CV 四小龙”等公司。在 2017 年,谷歌提出了 Transformer 架构,随后 BERT 、GPT 等预训练模型相继提出,2019 年基于预训练模型的算法在阅读理解方面超过了人类的水平,此后 NLP 技术在各项任务中都有了大幅度的提升。
AI 从感知智能向认知智能迈进
我们今天看到了一个明显的趋势就是 AI 正从感知智能快速向认知智能迈进。AI 正从“能听、会说、会看”的感知智能,走向“能思考、能回答问题、能总结、做翻译、做创作”的认知智能,甚至走到“决策、推理”层面了。
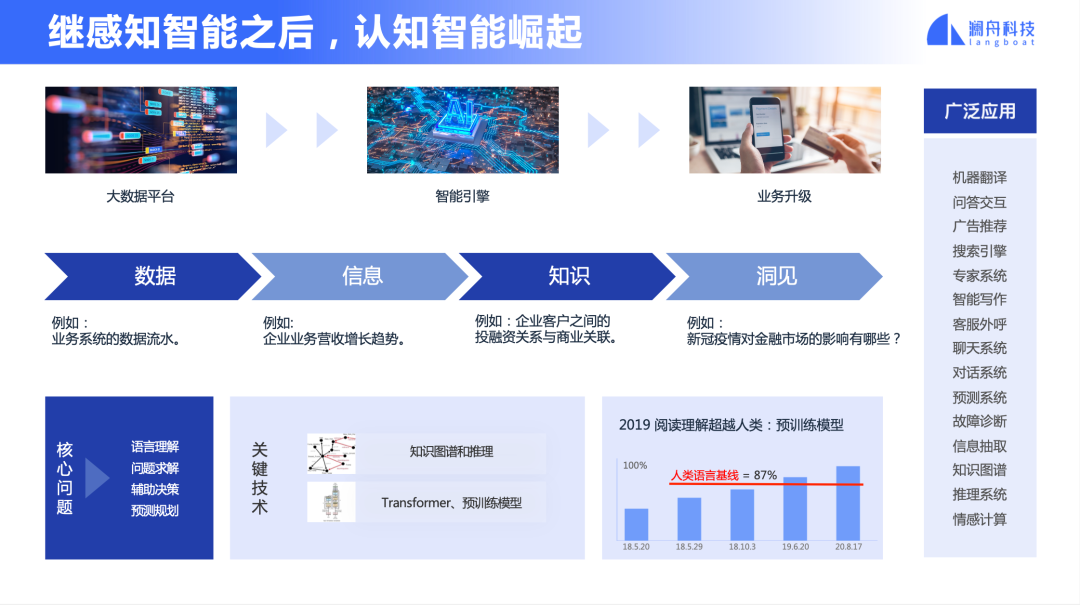
图 1
如图 1 右侧所示,认知智能的例子比比皆是。比如,达到了接近人类水准的机器翻译已经在手机和桌面普遍使用;聊天机器人几乎可以通过图灵测试;搜索引擎得益于阅读理解以及预训练模型,搜索相关度大幅度提升;自动客服系统已经普及;知识图谱在金融等领域得到快速应用。这些认知智能的能力在加速推动产业发展,从大数据出发到建立信息检索,再到建立知识图谱并实现知识推理,再到发现趋势形成观点和洞见,认知智能在大数据支持下,推动着企业的业务数智化,正深刻地影响产业的发展。可以说 NLP 和认知智能代表了人工智能的未来发展。
预训练成为了认知智能的核心技术
刚才说到 2017 年推出的 Transformer,催生了 BERT、GPT、T5 等预训练模型。这些模型基于自监督学习,利用大规模文本学习一个语言模型。在此基础上,针对每一个NLP 任务,用有限的标注数据进行微调。这种迁移学习技术推动了 NLP 发展,各项任务都上了一个大台阶。更为重要的是,产生的“预训练+微调”技术,可用一套技术解决不同语言和不同的 NLP 任务,有效地提升了开发效率。这标志着 NLP 进入到工业化实施阶段。
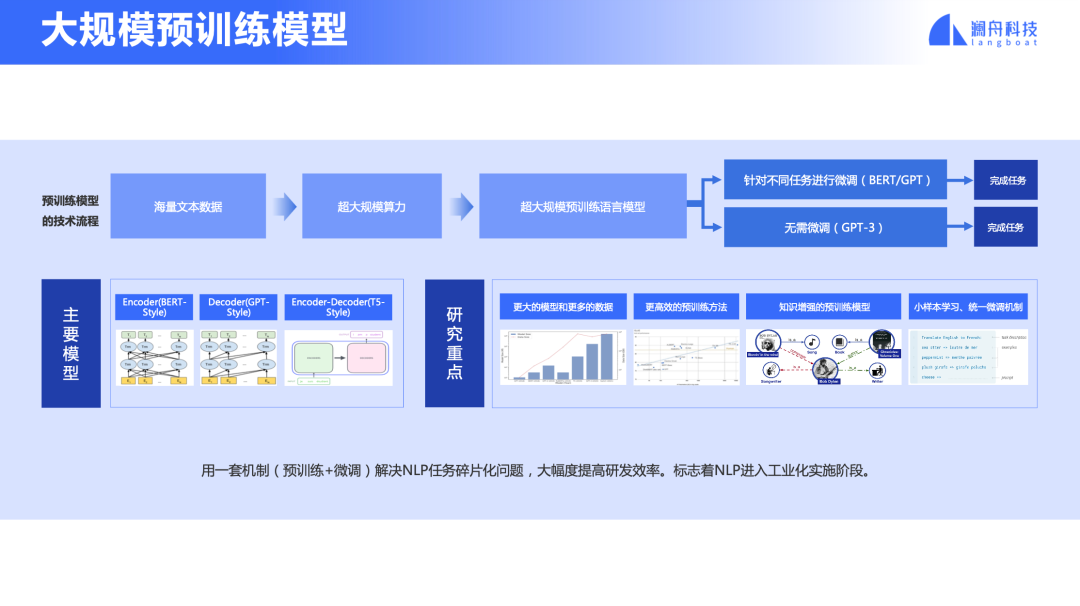
图2
当前在预训练模型领域较为关注的研究重点包括:如何训练超大规模参数的模型、对已有模型架构的创新性研究、更加有效的训练方法和训练加速的方法。还有简化微调的步骤,比如像 GPT-3 那样用一套提示机制来统一所有下游任务的微调,推动零样本学习和小样本学习。除此之外,多模态预训练模型和推理加速方法也是目前的研究焦点。
NLP领域需要挑战产品创新和商业模式创新
人们常说创新有三个层次,一个是科研的创新,第二个是产品的创新,第三是商业模式的创新。
我个人认为预训练模型是目前最具颠覆性的科技创新。可是再伟大的科技创新也要考虑如何推动产品的创新和商业模式的创新。如何从工业界观点来看,把科技创新贯穿到产品创新,贯穿到商业模式的创新呢?也就是说如何实现认知智能的落地?
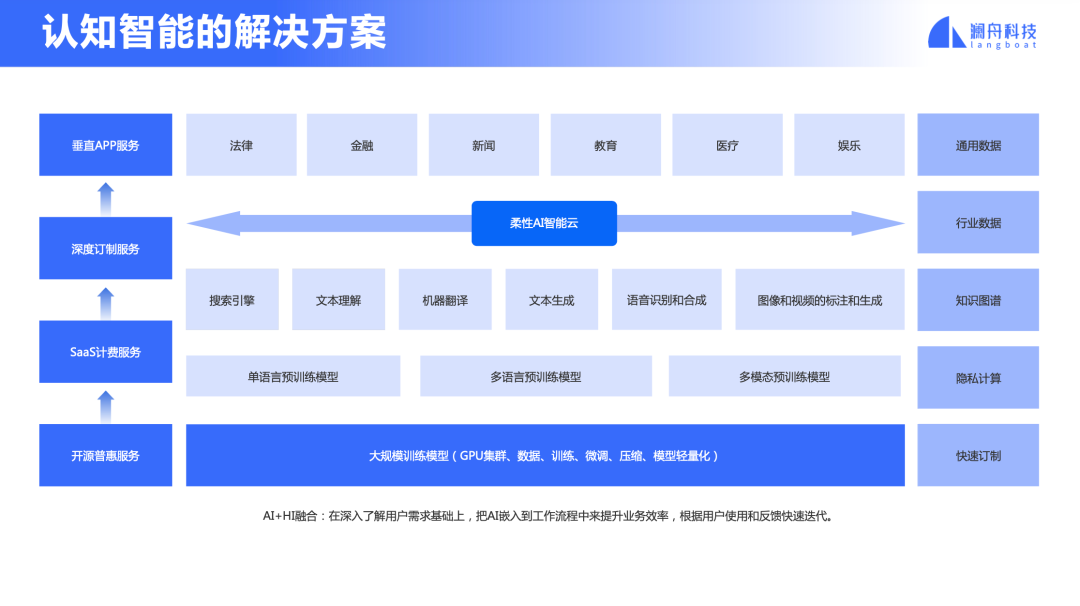
图 3
这里我跟大家分享如下四个观点。
模型训练。首先需要积累各类互联网数据、包括单语和双语数据、行业数据。通过实体、关系和时间序列抽取建立知识图谱。与此同时,建立大规模的预训练模型支持单语、多语、多模态等各项任务,并进而支持搜索、文本理解、生成、翻译、语音、图像、视频等各项应用。
模型快速适配。要有能力针对某一个行业需求,快速训练所需的模型。鉴于大模型在落地的时候部署代价大,需要考虑模型压缩和轻量化。为了解决 NLP 开发碎片化问题,建立一套基于预训练和微调机制的技术平台支撑所有语言、所有领域和任务的研发和维护。
柔性AI智能云服务。需要开发柔性AI智能云技术,使得用户以傻瓜型“拖拉拽”操作方式,“所见即所得”地实现自己的功能,并提供随着用户用量灵活调度云资源的弹性服务。
多样化的服务。通过开源方式提供普惠服务,并建立起品牌和口碑;通过SaaS提供付费服务;通过深度订制对重要客户提供优质服务。
这里特别提一下澜舟科技在预训练模型方面的研究。2021 年 7月,澜舟自研的孟子预训练模型以十亿级的规模,荣获了中文 NLP 比赛 CLUE 第一名。超过了许多大公司的大模型。它具备如下特色:
小:提供 100M 至 1B 参数量的多级别模型,实现低硬件需求和低研发成本。
精:模型结构上引入更多知识,同样模型体积下可有更好的表现。
快:可用 8 张 3090 卡约 3 天完成一个领域迁移(base 级),8 张 3090 卡半天完成一个任务适应。
专:可对每个领域或者每个任务定制预训练模型。由于是专用模型,其水平可超过通用的大模型。
目前,我们开源了四个模型(孟子Mengzi-BERT 模型、孟子Mengzi-T5 模型、孟子Mengzi-金融模型、孟子Mengzi-图文模型),并跟同花顺、华夏基金等公司展开紧密合作,此外还通过刚才所说的柔性智能云——“澜舟认知智能平台”来释放我们的能力,并通过SaaS服务广大客户,以实现科技创新到产品创新到商业模式的创新全贯通。
国内外预训练模型近一年的新进展
下面我就快速讲一下过去 12 个月以来,预训练模型国内外发展的一些新的状况。
我试图用一张图按照时间顺序来概括过去一年多大模型的进展。虽然我尽量概括全部,但是由于时间有限,或者水平和眼界所限,可能会漏掉某些重要的工作。
国内大模型百花齐放

图 4
首先我想介绍国内的一些进展,国内有关公司和学校的预训练模型研究非常令人关注(图 4 高亮的部分)。
今年4月,华为云发布了盘古系列超大预训练模型,包括中文语言(NLP)、视觉(CV)大模型,多模态大模型、科学计算大模型。华为云盘古大模型旨在建立一套通用、易用的人工智能开发工作流,以赋能更多的行业和开发者,实现人工智能工业化开发。
清华和腾讯推出的 CokeBert,虽然模型小,但是根据上下文动态选择适配的知识图谱的子图,在利用知识增强预训练方面(简称知识增强)有一定特色。
孟子是澜舟自研的模型,走轻量化路线,覆盖多语言和多模态,理解和生成,去年 7 月在 CLUE 登顶。
中科院自动化所推出紫东太初,它是融图、文、音三模态于一体(视觉-文本-语音)的三模态预训练模型,具备跨模态理解与跨模态生成能力。
智源研究院也在不断推出新模型,覆盖文本和多模态。
沈向洋博士领导的大湾区 IDEA 研究院推出了二郎神模型,其中“二郎神-1.3B”模型在 FewCLUE 和 ZeroCLUE 上都取得榜一成绩。
当然,其他大公司也都推出了他们自己的新模型,比如阿里的 M6 采用相对低碳方式突破 10万亿,有多模态、多任务;百度的 ERNIE 3.0 是融合了大量知识的预训练模型,既用了自回归,也用了自编码,使得一个模型兼具理解和生成。这里不再赘述细节。
多模态模型新秀涌现

图5
图 5 highlight 了一些新的多模态模型,比如微软亚洲研究院提出的一个可以同时覆盖语言、图像和视频的统一多模态预训练模型——NÜWA(女娲),直接包揽 8 项 SOTA,还有其文档理解的 LayoutLM 也有了新的进展。当然谷歌的 ImageN 和 OpenAI 的 DALL-E 2,实现了更强大的“文一图”生成能力,也引起广泛关注。
通用能力模型萌芽
我也注意到,把大模型拓展可以构建某种意义上的通用能力模型。比如,OpenAI 的 VPT 模型:在人类 Minecraft 游戏的大规模未标记视频数据集训练一个视频预训练模型,来玩 Minecraft。
而 Deepmind 用预训练构建了一个 AGI 智能体 Gato,它具有多模态、多任务、多具身(embodiment)特点,可以玩雅达利游戏、给图片输出字幕、和别人聊天、用机械臂堆叠积木等等。Gato 使用相同的训练模型就能玩许多游戏,而不用为每个游戏单独训练。DeepMind 这项最新工作将强化学习、计算机视觉和自然语言处理这三个领域合到一起。
它们都试图把大模型的概念推广到一个相对通用的人工智能领域。像 Gato,它具备多模态、多任务、多具身的特点,可以玩多种游戏,用一个模型来覆盖多个游戏,而不是说为每个游戏单独训练一个模型。实际上把强化学习、计算机视觉和自然语言处理这三个领域试图合在一起。
小结
总的来讲,小样本,零样本取得了新的进展,SOTA模型的尺寸在降低,检索增强的预训练模型逐渐成为主流技术。多模态模型能力提高很快,从图、视频、声音、code、甚至扩展到AGI。我们也看到了很多新的应用。
以上只是非常 high level 地概括最近预训练的发展,下面我们会更详细地说明。
预训练之“不可能的三角”
下面具体介绍近期有亮眼进展的预训练模型。
大家可能都知道在分布式系统里有 CAP 定理,该定理指出,对于一个分布式计算系统来说,不可能同时满足“一致性”、“可用性”、“分区容错性”。类似的,去年有一篇论文提出了预训练模型“不可能三角”理论(图6) ,三角形顶端分别是“合理的模型尺寸”、“先进的小样本能力”以及“先进的微调能力”,一个模型很难兼顾这三点,大多数模型只能做到其中一点或者兼顾两点。
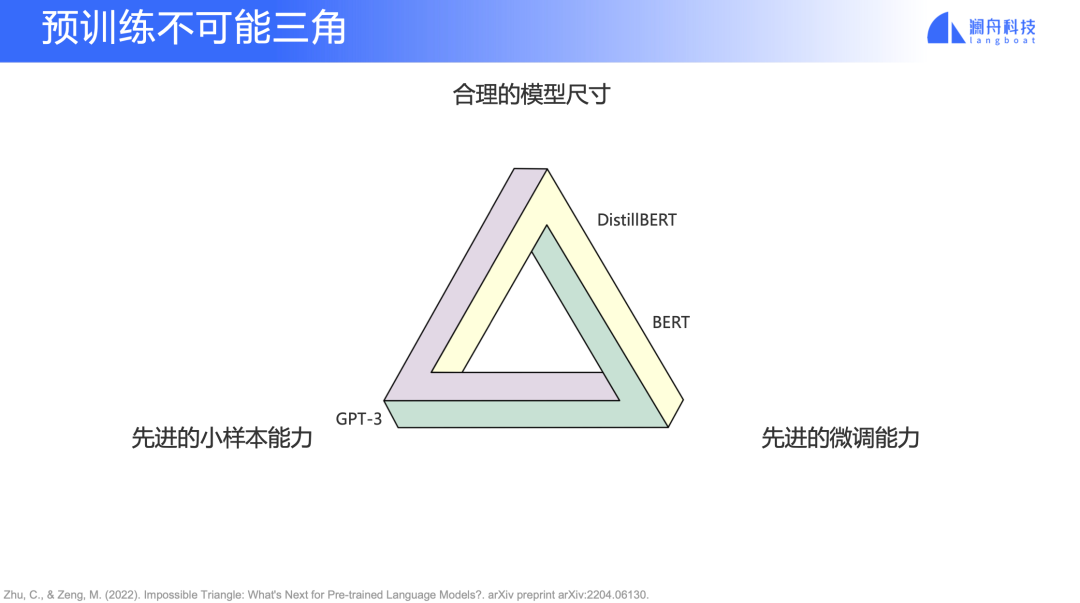
图6
比如 GPT-3 小样本表现较好,但是模型较大,finetune 效果表现并不是那么好;BERT 和 DistillBERT 就是另外一个典型,那它们的模型尺寸可能没有那么大,然后微调能力也很好。但是它们在小样本和零样本上的表现就是会比较差。
但是最近半年我们也看到一些改进:在保证和 GPT-3 效果相当的前提下,去减小模型参数量。下面我们分开来讲。
FLAN (Google)
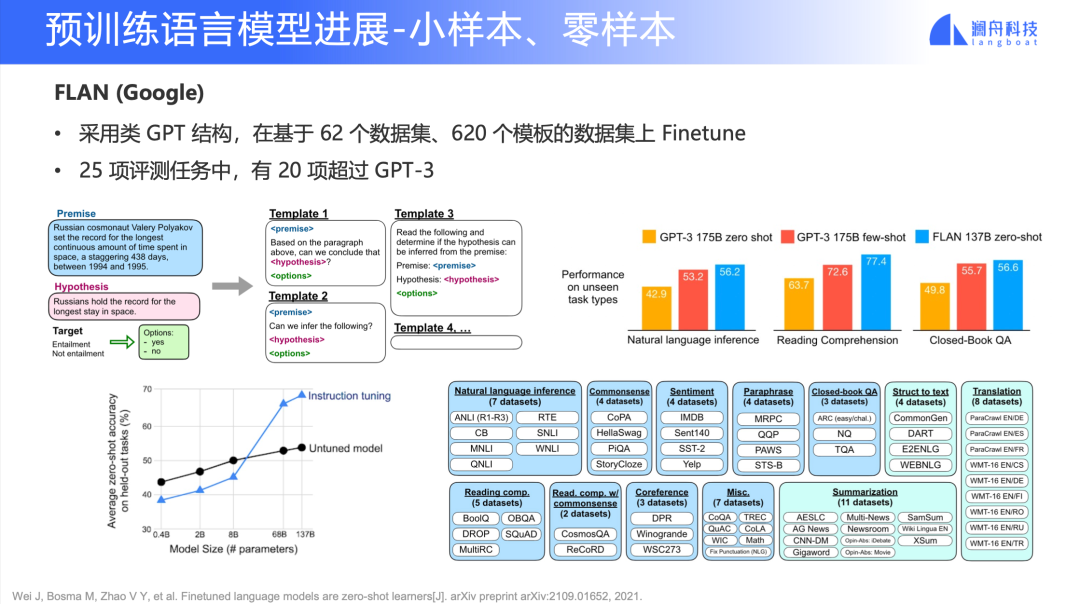
图 7
Google 去年提出了 FLAN,一个基于 finetune 的 GPT 模型。它的模型结构和 GPT 相似。但是不同于 GPT-3 的是,它基于 62 个数据集,每个数据集构造了 10 个 Prompt 模板,也就是总共拿到 620 个模板的数据之后再进行 finetune。
我们可以看到图 7 右侧,FLAN 的这个模型参数只有 137B,相比于 GPT-3 的 175B 有大幅降低,但是 FLAN 在一些下游任务 few-shot 和 zero-shot 上表现却变得更好。这给我们带来一个启示:我们不是必须去用像 GPT-3 级别超大规模的语言模型,而是通过更多的监督数据(而不是纯粹做无监督的训练),去降低模型规模,同时拿到更好的模型效果。
当然 FLAN 也会有些约束条件。如图 7 左下角所示,finetune 所带来的效果在 8B 以上的参数量才能够实现。
T0 (BigScience)
下图是 Huggingface 发起的“BigScience” workshop 中的一项工作,该模型取名为 T0。T0 选择的是 T5 的架构,但是它的数据量更多。T0 总共构造了 171 个数据集,最终构造了 2000 个多样的 Prompt 模板,最终用 11B 参数量(GPT-3 的 1/16)达到了和 GPT-3 相似的效果。
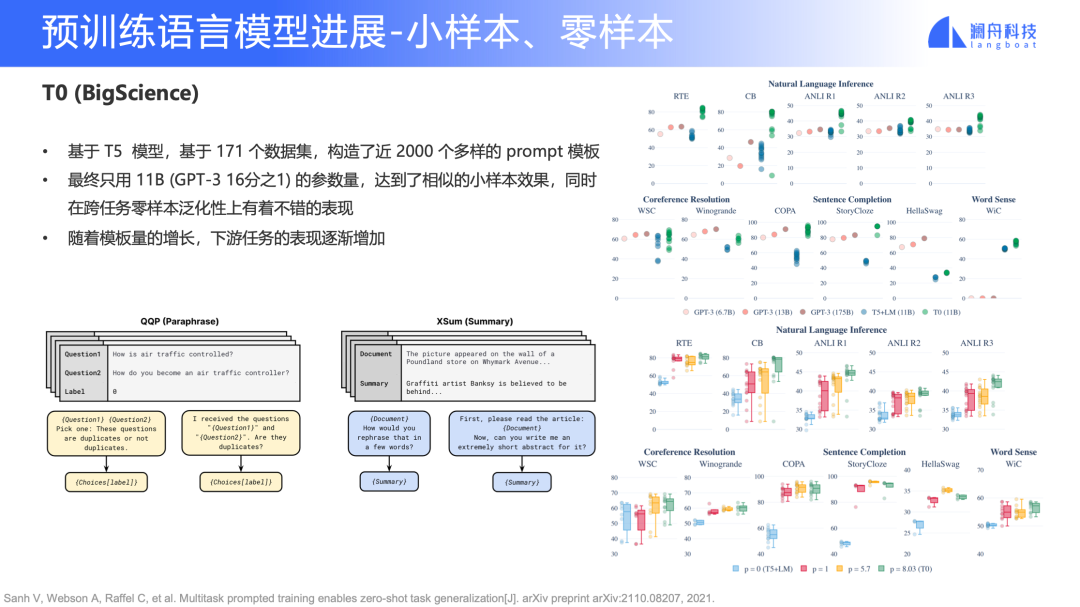
图 8
如图 8 右下角所示,我们可以看到随着 Prompt 的数量增加,下游任务表现也会逐渐地变好。这也启发我们,是不是可以通过不断增加任务数量以及构造更多样化的 Prompt 模板,不停地把这个超大规模语言模型的参数量压缩得更小?比如,上面 FLAN 是 137B,T0 现在是 11B,那如果我们再去增加数据量,或者再增加 Prompt 数量,参数是不是还有更高的压缩空间?这个也是值得探索。
CoT
这个是最近挺有话题性的一篇文章。逻辑比较简单,主要在探索“在 GPT-3 上,我们选择不同的 Prompt 是不是还有更好的表现”。

图 9
如图 9 左下角的表格所示,在一个任务上,它的 zero-shot 大概是 17.7 分,但是选择“Let's think step by step” 这个 Prompt,分数直接涨到 78 分。
这说明一些问题,一方面是超大规模的预训练语言模型其实还有很多挖掘的空间,另一方面,Prompt 鲁棒是一个很大的问题。如果我们要落地这样的模型会增加工程难度。就像我们之前做语言或者视觉方向上的特征工程一样,不同的特征工程对下游任务的最终表现影响是特别大的。
RETRO (DeepMind)
除了多任务之外,还有一个新趋势是检索增强。早一些在做检索生成的时候,我们用到 REALM 和 RAG 等模型。而 RETRO 模型是 DeepMind 去年 12 月份左右提出的,它的主要思路是,除了使用这一个大规模预训练语言模型掌握语料知识之外,还可以把知识从这个模型中解耦,独立成一个单独的检索模块,把这些知识放到一个数据库里面。
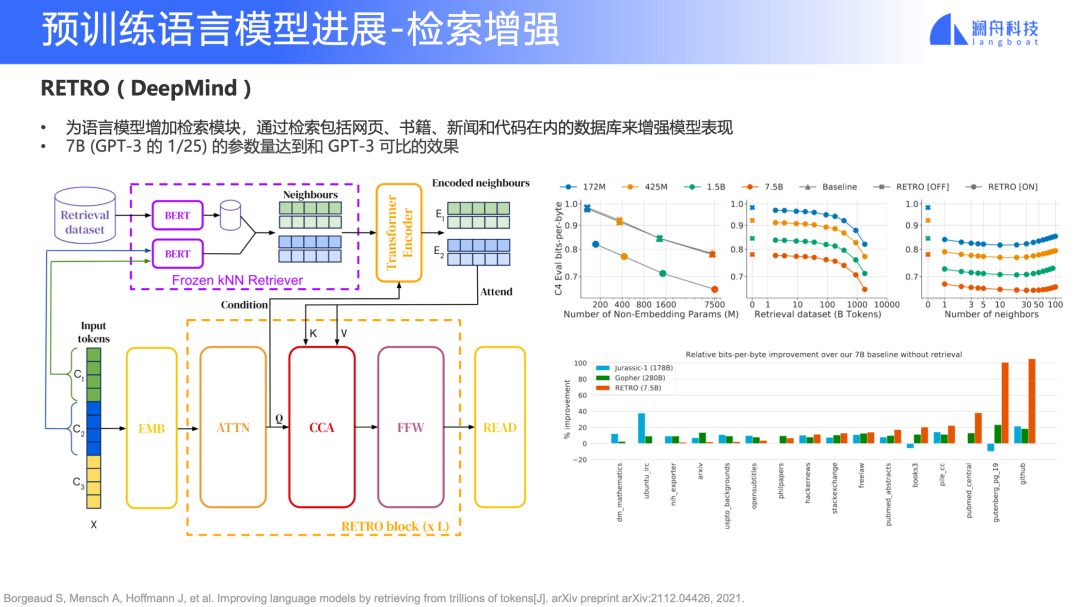
图 10
RETRO 只用了 7B 参数(相当于 GPT-3 的 1/25),就可以达到和 GPT-3 可比的效果。这也证明了提高模型效果并不只有增加参数量一条路。同时还能通过数据库更新的方式实时加入新的知识(OpenAI 的 GPT-3 API 只有 2020 年 8 月前的知识)。
当然 RETRO 也会有一些要求限制。如图 10 左上角所示,它对检索库的数据量有很高要求,在 1T Tokens 左右才能达到相似效果,这也是后续要解决的问题。
WebGPT (OpenAI)
WebGPT 其实跟 RETRO 很相似,我们可以从两个角度来看:
1. WebGPT 引入了外部知识,让 GPT-3 学会像人类一样去学会使用浏览器获取知识;
2. WebGPT 不仅仅是像 RETRO 一样直接引入一个外部的检索模块,它还会利用强化学习的方法,通过 6k 条人类的搜索行为数据让 GPT-3 模仿人类的搜索方式

图11
小结一下,从上面 FLAN、T0、CoT、RETRO、WebGPT 的工作来看,在 GPT-3 模型的基础上,我们可以通过增加多任务、Prompt 和增加检索模块,在更小的参数量级上达到 GPT-3 175B 相同水平的效果。之前只能在 GPT-3 中看到的小样本、零样本能力,未来通过更小参数量的模型在工业界中落地的可能性会越来越大,大量场景中的标注成本将会继续降低。未来,这一能力这将为我们带来全新的商业场景,让没有 NLP 算法团队的公司也能更容易、低成本的获得定制化的 NLP 能力。
多模态模型
DALL·E 2(Open AI)和 Imagen(Google)
多模态方面近期有很多进展,今年,OpenAI 发布了 DALL·E 2,Google 发布了 Imagen。虽然两个模型权重都未公开,但从释放出的大量示例来看,图片的真实度、分辨率都有较为明显的进步。我们已经到了需要讨论这项技术商业化落地的时间点了。当然,目前模型还存在的各种⻛险和限制也是我们要考虑的问题,比如暴恐、低俗的文字输入、版权⻛险、来自数据的偏⻅等。
以往关于文本生成图像的研究,除了最早出现的 GAN,大体可以分成两种思路:
一种是基于自回归模型,将文本特征和图像特征映射到同一空间,再使用类似于 Transformer 的模型架构,来学习语言输入和图像输出之间的关系。比如 DALL-E 和 CogView,就采用了这一思路。
另一种则是基于扩散模型的方式,DALL·E 2 和 Imagen 就属于这一类。可以看到的是,这些模型产生的图像分辨率更高,效果更好。

图 12
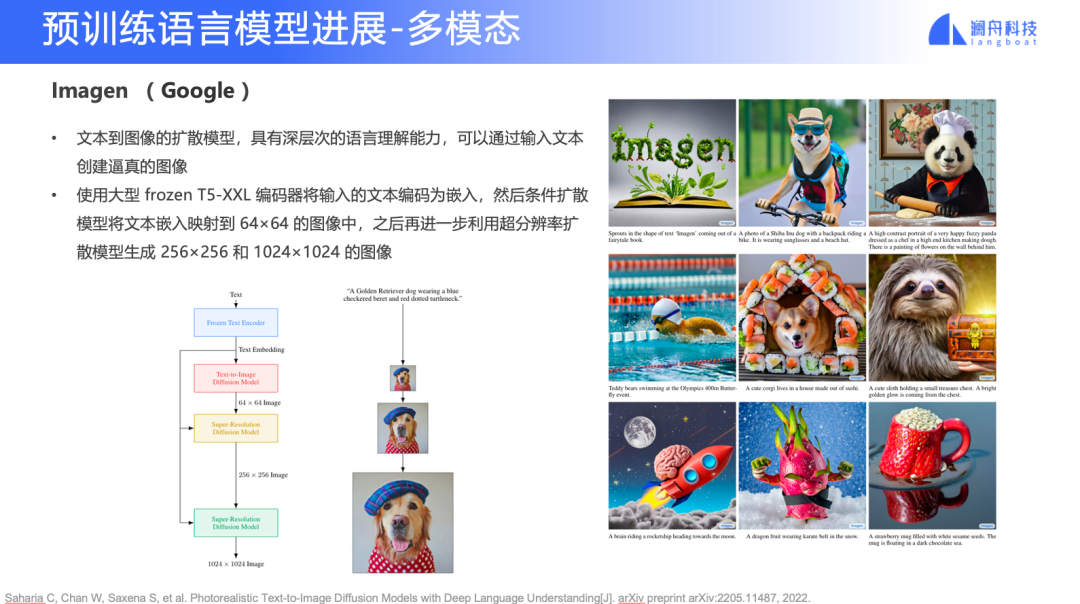
图13
LayoutLM v3
LayoutLM 在文档理解和智能文档领域有非常重要作用,这方面的工作已经推出了第三代。相比前一代,它用 patch embedding 来代替之前 CNN 的 backbone,使用统一的文本和图像的 mask 任务。
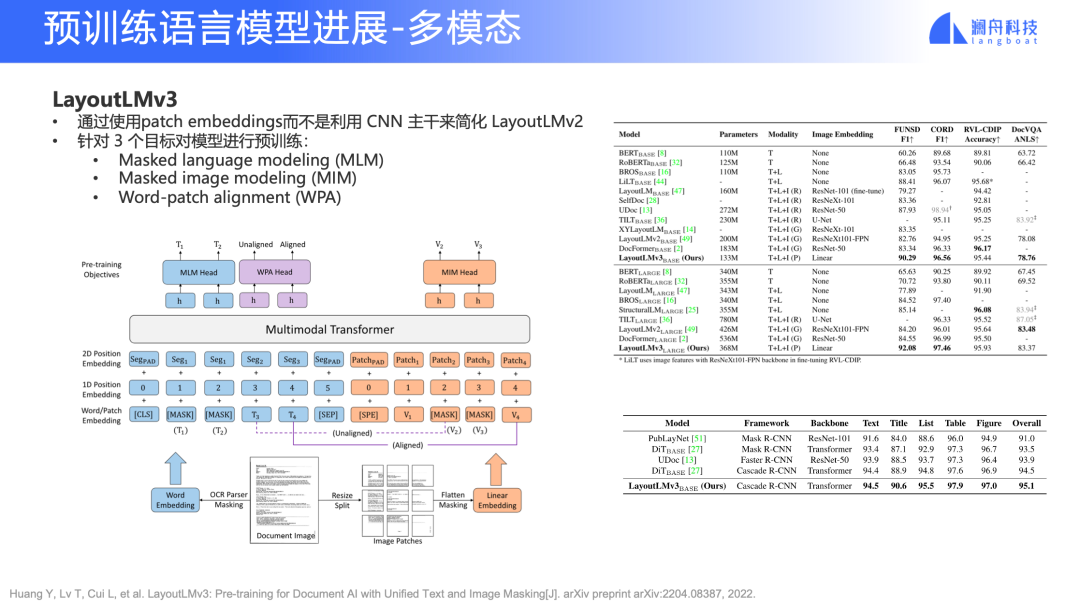
图 14
在 NLP 领域,我们不仅仅要面对文字,还有更多复杂的、未经处理的 PDF、Word 文档等,所以 LayoutLM 是一个非常值得关注的工作。
VPT
视频领域的预训练模型 VPT 应该算得上是一个里程碑式的工作。
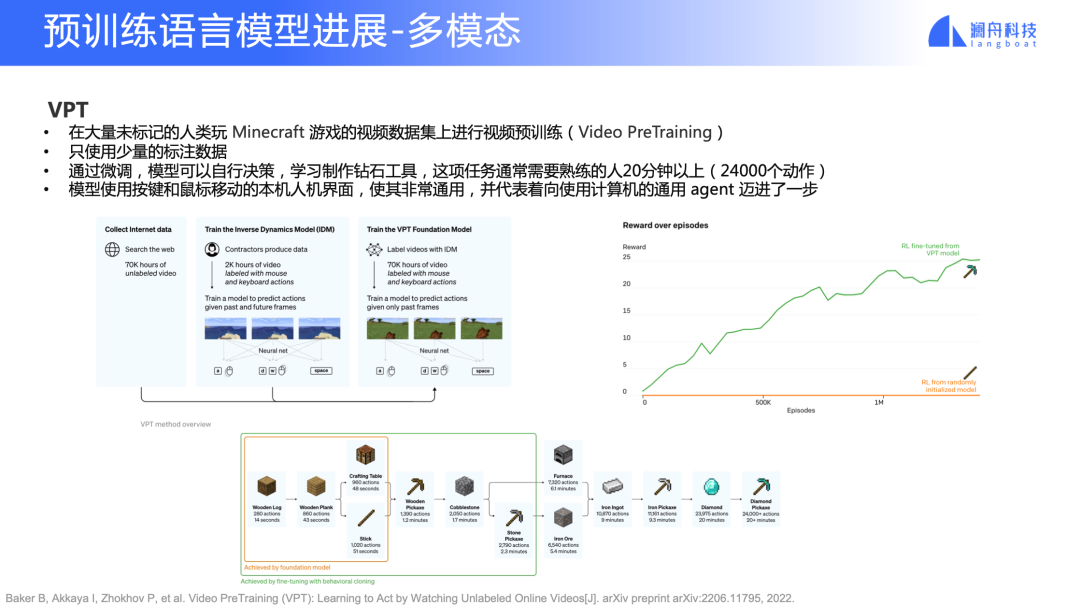
图 15
这里要先简单介绍一下 Minecraft,它是一个开放式的游戏,玩家可以在一个三维世界里采集资源,然后按照一个技能树去创造不同的工具和物品。一般人类玩家会先采集木头(如图 15 下半部分所示),然后制造一些工具,再采集石头、铁,最后采集钻石。整个游戏流程中需要进行不同类型的决策,除了要在三维世界里采集这些东西,玩家还要决定怎么制造道具。普通人类玩家——以我个人经验——差不多半个小时才能完成整个流程。这是首次有 AI 算法能使用和人类一样的交互(视频+键鼠)完成这个任务。
VPT 里大量使用了预训练。除了用大量无标注的视频数据做了预训练,还加入了少量的人工标记去学习人类行为。如图 15 右侧所示,我们可以看到,没有使用预训练的方法是很难完成这个工作的。所以,这给我们带来一些想象空间——预训练和强化练习,或者和机器人进行结合,能够像人类一样解决一些很通用的任务,可能会产生新的落地场景。
Gato (DeepMind)
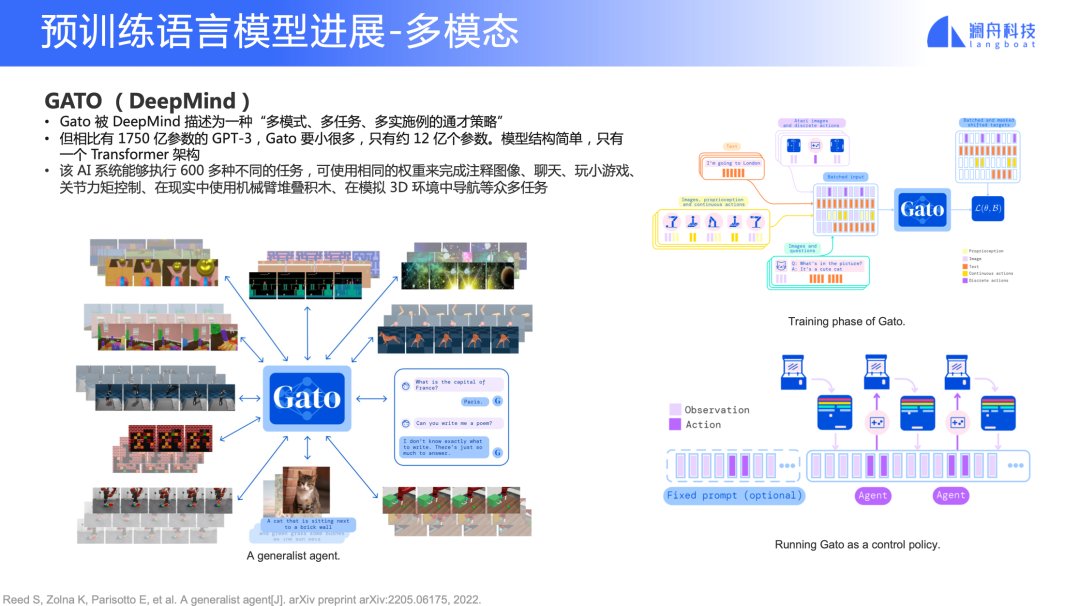
图 16
DeepMind 提出的 Gato 是用一个单一的预训练模型完成很多不同的任务。模型结构简单,只有一个 Transformer 架构,只有约 12亿参数。Gato 能够执行 600 多种不同的任务,可以使用相同的权重来完成注释图像、聊天、玩小游戏、bu关节力矩控制、在现实中使用机械臂对叠积木、在模拟 3D 环境中导航等等任务。
这启发我们,Transformer 架构实际上是有一定通用性的。不仅是能够完成文字类理解工作,甚至打游戏、视频相关的任务,它都能做。这意味着我们将来也许可以用一套更统一的框架来做更多事情。在工业界来说,就是用更低的成本来做预训练微调、解决不同场景的问题。
新应用 —— Copilot
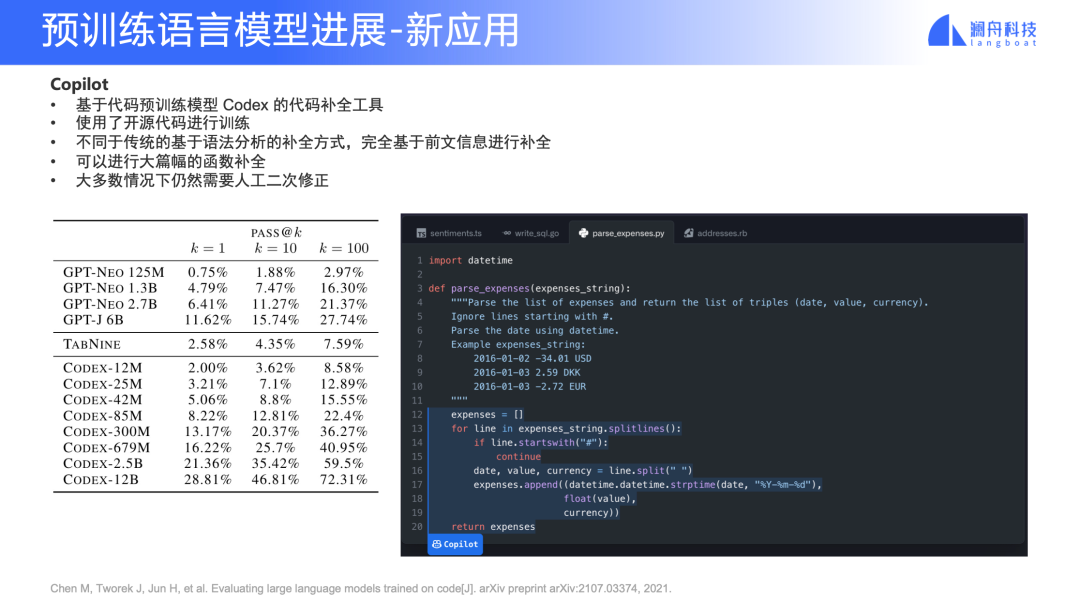
图 17
Copilot 已经是非常落地的一个应用了,很多开发者的体验反馈都是“非常惊艳”。传统的代码补全,通常用语法树解析去做预测。由于这个原因,对于解释性的语言的补全做得并不是很好,比如大家常用的 Python。当然,我们也知道有一些厂商做得可能稍微好一点,但相比于 Copilot 这种基于预训练的工具,属于不同“代次”。
Copilot 可能会对传统的 IDE 行业产生非常大冲击。
举一些具体的例子,我们一般写代码可能会输入一个符号,然后按一下键盘上的 “.” 来进行补全出 class 、function、symbol 等等。但是 Copilot 用法往往是这样:先写一个函数名称,再写几行注释,它就能够把函数的 5 到 10 行代码直接补全出来,当然也不是非常完美,有时候需要我们手动做二次修改,但相对于传统 IDE 是完全不同的体验。
除了可以把 Copilot 当做代码补全工具之外,也能把它当做替代 stackoverflow 的检索工具。以往写一些简单、重复性的代码片段,我们可能要去搜 stackoverflow,看看其他人分享的代码。但是有了 Copilot 之后,stackoverflow 的使用率会变得很低。因为基本只要写注释就能让 Copilot 帮你完成一些简单的工作。
预训练框架进展
JAX
除了模型之外,底层的预训练框架也是非常重要的。最近一年,我们可以看到预训练框架领域有了新的进展。
JAX 不是一个新的框架,它在 2018 年就已经问世了。2020 年 DeepMind 表示他们在用 JAX 去做他们的研究工作。相比 PyTorch,JAX 引入了 XLA 带来了速度提升、显存消耗下降,同时 API 形式是非常像NumPy,大家用起来会非常轻松。

图 18
我们更关注的是基于这套框架之上的预训练领域框架,如 T5X,最近 Google的工作很多用 T5X 实现。T5X 跟 Pathway 的思路会很接近,即通过一套框架让研究员很轻松地去调整设置,用不同架构完成预训练。目前在 Huggingface 上大多数模型也都已经有对应的 JAX 版本了。但是这个框架也有一些问题,由于它设计的思路,要求大家用函数式编程的思路写纯函数,那么对大多数没有接触过函数式编程语言(如 Lisp,Haskell 等)的人来说会有一定的上手门槛。
Megatron-DeepSpeed
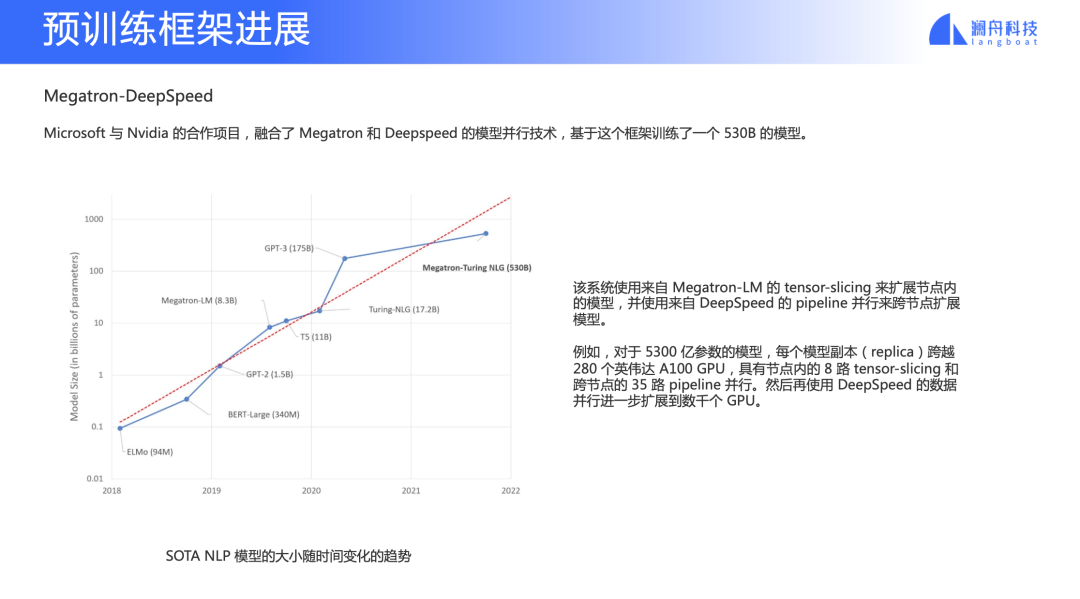
图 19
Megatron 和 DeepSpeed 是两个很重要的预训练框架。Megatron 是英伟达做的超大规模预训练模型框架,主要是利用 tensor parallel 做性能优化以及 mode parallel。DeepSpeed 是微软团队做的深度学习加速框架。这两个团队去年合作构造出 Megatron-DeepSpeed 框架,相当于是把两个框架的特点结合在一起,并用它训练一个 530B 的模型。后面会讲到的 BLOOM 模型也是基于这个框架的一个 fork 去做的。
ColossalAI

图 20
ColossalAI 是潞晨科技的开源项目,是 Megatron-DeepSpeed 有力的竞品,社区也非常活跃。它给大家带来一个非常直观的结果就是预训练成本降低了,在消费级的显卡上也可以做一些训练,相比 MegatronLM 更省力。
大教堂到集市:大模型研究的平民化
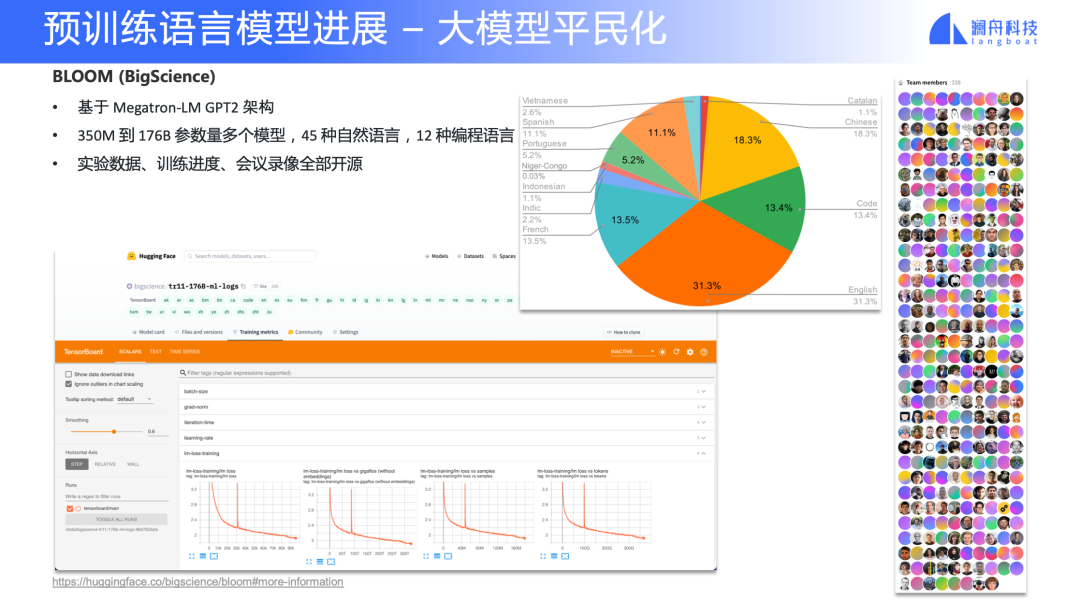
图 21
最近大家可能关注到 BLOOM 模型,这是来自 BigScience 的一项工作。这其实是近半年以来的一个新趋势——大模型平民化。BLOOM 模型在 7月中旬刚完成了最大规模 176B 的模型训练,Benchmark 过两天应该会出来,大家感兴趣可以去 Slack 围观进度。除了 BLOOM,最近 Meta 也开源了 OPT, EleutherAI 也开源了 GPT-Neo。
除了关注 BLOOM 模型本身,我们还要关注到它的项目组织形式。与 GPT-3 纯闭源的、顶级大厂内部研究不同,这个项目从立项开始就是开放的。其开源内容不仅是模型本身,还包含了数据治理、模型结构探索、实验数据、训练日志、线上会议录像等资料。大家可以去看一下他们中间经过了几次波折、训练中止这些问题怎么解决的。这是一个非常宝贵的资源,预计在后续半年内,BLOOM 模型还有很多迭代工作。
总结
最后总结一下本次演讲的内容。
继感知智能之后,认知智能已经崛起,最重要一个因素是“预训练+微调”技术的发展,相比于之前的特征工程,“预训练+微调”可以大大提升开发效率,也意味着我们可能用更统一的方式,让 NLP 能力在工业界落地。
最近一年,小样本和零样本技术也取得不错进展,通过这种多任务或多 Prompt 的形式,训练出的模型规模越来越小,让大家可以开始关注零样本商业化落地的可能性。
通过检索增强,能够把模型和知识解耦,让模型变得更加轻量化。
近期在多模态领域涌现出非常多的新工作,模型能力提升非常迅速,也到了考虑商业化可能性的时间节点;多模态预训练和强化学习的结合也是一个新的趋势。
多个预训练框架齐头并进,这些框架的改进将帮助研究员和工业界更轻松地去解决预训练的诸多问题。
开源训练框架的出现,未来或许会使得超大规模预训练模型技术壁垒逐渐消失。
审核编辑 :李倩
-
人工智能
+关注
关注
1792文章
47373浏览量
238875 -
nlp
+关注
关注
1文章
489浏览量
22052 -
大模型
+关注
关注
2文章
2477浏览量
2833
原文标题:一文看懂预训练模型最新进展
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
探讨大模型时代背景下数据存储的变革之道
纳微半导体亮相2024亚洲电源技术发展论坛
直流高压电源技术发展浅析
开关电源的最新技术发展趋势
揭示大模型剪枝技术的原理与发展
智能驾驶技术发展趋势
简述中软国际模型工场服务场景
SDV的发展背景背景与功能
无线充电技术发展趋势
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》
揭秘气候技术发展的关键平台Earth-2的核心—CorrDiff
岩土工程中的振弦采集仪技术发展与前景展望






 工商网监
工商网监
评论