 使用汇编知识排查疑难问题的方法
使用汇编知识排查疑难问题的方法
1 前言
在我的上一篇文章中,有讲到掌握汇编知识的重要性,关键时刻可能还会拯救你于泥潭之中。
那么,本篇文章,我将再介绍一个使用汇编知识排查疑难问题的方法,希望对大家有所帮助。
2 问题描述
问题是这样的,前一段时间我们项目组在进行一项自测试中,偶然发现我们的代码好像挂了一样:现象就是命令行输入不了,但是没有看到复位信息输出。
当时,我们一个小伙伴说:“好像我们的系统挂了?”当我了解到这个现象之后,根据我之前的排查经验,我当即得出了一个结论:“可能是我们的代码跑进死循环了,好好检查下”!
于是,我们开始debug代码,加了一些必要的调试信息,最终发现有一个计算校验的函数,调进去了但是没有退出来,而这个校验的函数非常之简单,它就长这样:
uint16_t checksum(uint8_t *data, uint8_t len){uint8_t i;uint16_t sum = 0, res;for (i = 0; i < len; i++) {sum += data[i];}res = sum ;return res;}
我想当你看到这段函数时,肯定也是:“卧槽,这TM不就是算累加校验和吗?怎么可能会死循环?”
没错,当时我们的争论的场景也的确如此!
3 简单分析
这个checksum函数真的是非常简单,入参简单、实现也简单、返回值也简单,根本不存在难点。
一步步来分析:
既然代码没有崩溃,证明data指针肯定非NULL的,不会有问题;
倒是这个len有些可疑,len的类型是uint8_t无符号的,它的范围是0-255;但是如果外面传入的是-1呢?
如果传入-1,强制转换为uint8_t,其值也是255,那么下面的for循环,依然只会跑256次,它必须得退出呀?
有没有可能for循环的过程中,栈的值被修改了,然后i的值和len的值都变了,进而for的次数改变了?
于是我们开始打印i和len的值,发现他们两个的值,都是正常变化的,并不是刚刚想的那样。
这就很奇怪了!!!
如果说这个for循环要“无限”循环下去,造成“死循环”,必须满足的条件是len很大很大,但是len不是uint8_t类型嘛?最大也就255呀?
printf大法再来一遍:结果出乎我们的意料,请看:
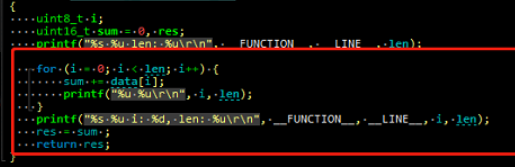
log输出:
[12-21 1938]checksum 128 len: 4294967295[12-21 1938]0 4294967295[12-21 1938]1 4294967295[12-21 1938]2 4294967295[12-21 1938]3 4294967295[12-21 1938]4 4294967295[12-21 1938]5 4294967295[12-21 1938]6 4294967295[12-21 1938]7 4294967295[12-21 1938]8 4294967295[12-21 1938]9 4294967295[12-21 1938]10 4294967295。。。省略很多[12-21 1938]250 4294967295[12-21 1938]251 4294967295[12-21 1938]252 4294967295[12-21 1938]253 4294967295[12-21 1938]254 4294967295[12-21 1938]255 4294967295[12-21 1938]256 4294967295[12-21 1938]257 4294967295[12-21 1938]258 4294967295[12-21 1938]259 4294967295[12-21 1938]260 4294967295
。。。还在不停的打印
看到这里似乎有点眉目了?len的值为4294967295?
这个值不是0xFFFFFFFF吗?
我们再使用%d打印了一下len,发现值为-1。
回过头来看下checksum的调用之处:
uint16_t res = checksum(&data[0], len - 1);
看似真相了,当len为0的时候,传入的值不就是-1吗?
好像是这么回事,但是-1进去,它是uint8_t的呀,顶多就是255啊?怎么变成了4294967295? 到底是谁干的啊?
同时也发现关键问题了,这里并不是真正意义的“死循环”,而是for循环执行太久了,导致长时间无法结束,因为我们的主频才160MHZ,CPU就是猛跑,从1加到0xFFFFFFFF,也需要好长一段时间呢!
4 场景再现
为了充分说明这个问题,我尽可能地还原下当时我们的代码场景:
/*一个结构体定义数据不要急于吐槽它的定义,这代码是开源的,冤有头。。。还有不要怀疑是字节对齐不对齐的问题,曾经我也怀疑过,最后知道真相的时候,我被打脸了!*/typedef struct _data_t {/* result, final result */uint8_t len;uint8_t flag;uint8_t passwd_len;uint8_t *passwd;uint8_t ssid_len;uint8_t *ssid;uint8_t token_len;uint8_t *token;uint8_t bssid_type_len;uint8_t *bssid;uint8_t ssid_is_gbk;uint8_t ssid_auto_complete_disable;uint8_t data[127];uint8_t checksum;} data_t;
/* 1.c 调用checksum的C文件 *//* 定义全局的数据 */static data_t g_data;/* 设置全局的数据 */void set_global_data(void){g_data.len = 0;}void handle_global_data(void){uint16_t res = checksum(&g_data.data[0], g_data.len - 0); //sometimes no return form checksum}void test_func_entry(void){set_global_data();handle_global_data();}
/* 2.c 定义checksum函数的工具类 */uint16_t checksum(uint8_t *data, uint8_t len){uint8_t i;uint16_t sum = 0, res;for (i = 0; i < len; i++) {sum += data[i];}res = sum ;return res;}
在我的第一次认知里,还是len=-1=255的情况,由于g_data.data只有127字节,但它最后是可以访问到255下标的,其实这本身就有数据非法访问的问题;但是经过仔细论证,得出的结论是,这并不会导致死循环,或者说并不会改变len的值;因为checksum里面知识读取data指针的值,并没改变它的值,即便越界了,顶多访问了别人,并不会出啥异常(至少在我们的处理器平台是这样)。
这个问题对我们来说,真的是百思不得其解,为了规避掉这个问题,我们在调用checksum的时候做了判断,但len为0的时候直接不调用,也就绕过了这个问题。
但是作为一个深挖底层逻辑的攻城狮来说,我们不应该放过这样的细节,或许还有什么我们未发现的潜在风险呢?
这个问题一直困扰着我,时不时有空的时候,我就会想想,到底还有什么情况还会导致这个现象?
5 柳暗花明
偶然有一天,我正浏览到一篇关于编译器做代码优化的文章,它是在知乎上发出来的,我看到其中一个重要线索:

突然我脑子里,闪过一个疑问:“会不会那段for循环的checksum函数,正是因为调用方没有申明checksum函数,也就是说没有include对应的头文件导致编译器做了默认处理呢?”?
我们都知道,在使用gcc编译器编译C代码时,如果一个函数未申明就调用,是会报一个警告的:“warning: implicit declaration of function ‘checksum’ [-Wimplicit-function-declaration]”!
同时,尤其编译器不知道被调用函数的原型,那么它只能依靠你的调用代码结合一些默认值做假设:
比如我们的调用代码是:
uint16_t res = checksum(&g_data.data[0], g_data.len - 0);
这里,我猜测编译器的行为就是,你有一个叫checksum的函数,但我找不到它的原型,那么我就按“返回值是uint16_t类型,第一个参数是int型,第二个参数也是int型”来吧!
为何,gcc默认参数列表都是int类型?这是我的假想猜测,下面我们再论证,究竟是不是这样?
有了这个假设之后,我们回到ARM汇编在函数调用时的参数,这时R0应该等于&g_data.data[0],R1应该等于-1。
由于R0/R1都是32位的寄存器,在存储数据的时候,无所谓有符号和无符号一说,且本问题R0没有出现问题,我们仅讨论R1。
这个时候R1的寄存器值,应该是“-1 = 0xFFFFFFFF”,这个假设很关键,如果分析地很顺利,那么这个for循环不停地循环下去,才可以有理论进行下去。
6 找到证据
既然上面我们发现了端倪,那么我们应该进一步找到相关的证据,证明我们的想法;同时,如果这个问题根源在于include头文件,那么当我们添加了头文件之后,这个问题应该不会再复现。我们来看下,究竟是不是这样?
6.1 究竟是不是警告
由于我们的代码实在太多警告了,就属于那种 0 error N warnings 那种,属于你需要找一个警告往往好费好大劲!

经过好一番检索,果不其然,还真的报警告了,的确是“warning: implicit declaration of function ‘checksum’ [-Wimplicit-function-declaration]”!
6.2 盘根问底
看编译器的行为,我们肯定是要看其对应的汇编文件,这里有两个地方需要看,一个是checksum函数的汇编,还有一个调用checksum函数附近的汇编。
我们一起看看:
/* checksum 函数的汇编代码 */.section .text.checksum,"ax",%progbits.align 1.global checksum.code 16.thumb_func.type checksum, %functionchecksum:.LFB4:.loc 1 125 0.cfi_startproc@ args = 0, pretend = 0, frame = 0@ frame_needed = 0, uses_anonymous_args = 0.LVL27:push {r4, r5, r6, lr}.cfi_def_cfa_offset 16.cfi_offset 4, -16.cfi_offset 5, -12.cfi_offset 6, -8.cfi_offset 14, -4.loc 1 125 0movs r4, r0movs r5, r1 // r1 -> r5 ,即 len的值存在r5中.loc 1 129 0movs r2, r1ldr r0, .L29.LVL28:bl printf //打印len的值.LVL29:movs r3, r4.loc 1 127 0movs r0, #0adds r5, r4, r5.LVL30:.L26:.loc 1 130 0 discriminator 1cmp r3, r5 //for循环里面的关键判断,即 i < lenbeq .L28 // 退出for循环.loc 1 131 0 discriminator 3 //下面就是for循环的循环执行体ldrb r2, [r3]adds r3, r3, #1.LVL31:adds r0, r0, r2.LVL32:lsls r0, r0, #16lsrs r0, r0, #16.LVL33:b .L26.LVL34:.L28:.loc 1 136 0@ sp needed.LVL35:pop {r4, r5, r6, pc}.L30:.align 2.L29:.word .LC12.cfi_endproc.LFE4:.size checksum, .-checksum
由它的汇编代码可知,for循环执行多少次,关键在于r5寄存器的值,也就是len的值。
注意在汇编代码这里,是看不到r5是uint8_t还是uint32_t的,它仅仅是一个32位的寄存器。
.section .text.verify_checksum,"ax",%progbits.align 1.global verify_checksum.code 16.thumb_func.type verify_checksum, %functionverify_checksum:.LFB5:.loc 1 81 0.cfi_startproc@ args = 0, pretend = 0, frame = 0@ frame_needed = 0, uses_anonymous_args = 0.LVL17:push {r4, lr}.cfi_def_cfa_offset 8.cfi_offset 4, -8.cfi_offset 14, -4.loc 1 83 0ldr r4, .L20.loc 1 91 0@ sp needed.loc 1 83 0movs r0, r4 //r0存储结构体g_data的地址ldrb r1, [r4] //将g_data的第一个字节,即g_data.len赋值为r1adds r0, r0, #34 //r0的地址偏移34个字节,即偏移到g_data.data的位置;subs r1, r1, #1 //关键的一步:r1 = r1 - 1 由于我们复现问题的时候,g_data.len是为0的,所以此时r1的值就是0xFFFFFFFFbl checksum //调用checksum函数,第1-2个入参,分别是r0和r1.LVL18:.loc 1 84 0adds r4, r4, #160.loc 1 89 0ldrb r3, [r4]lsls r0, r0, #24.LVL19:lsrs r0, r0, #24subs r0, r0, r3.loc 1 91 0pop {r4, pc}.L21:.align 2.L20:.word .LANCHOR4.cfi_endproc.LFE5:.size verify_checksum, .-verify_checksum
了解汇编知识的,看到上面的汇编代码,结合checksum函数的汇编代码,就应该明白,我前面的假设成立了,但len传入到checksum函数时,它的值真的是0xFFFFFFFF,而使用%u打印出来,就是4294967295。
到此,罪魁祸首其实已经找到了,与其说是编译器的无故优化,倒不如说是程序猿写代码不严谨,没有正确处理掉这个编译警告。
6.3 解除风险
既然找到了问题根源,那么我们尝试下解除这个风险。
方法其实也很简单,直接需要在调用checksum函数的1.c中,include一下checksum函数所在的头文件即可。
添加之后,我们看下发生的变化,很显然,checksum函数的汇编代码肯定是没有任何不变的,应该它压根没有改;
而调用checksum的汇编就发生了些许的变化,同时编译输出的地方,那个编译警告也都消失了。
* 添加头文件之后的汇编代码 */.section .text.verify_checksum,"ax",%progbits.align 1.global verify_checksum.code 16.thumb_func.type verify_checksum, %functionverify_checksum:.LFB5:.loc 1 81 0.cfi_startproc@ args = 0, pretend = 0, frame = 0@ frame_needed = 0, uses_anonymous_args = 0.LVL17:push {r4, lr}.cfi_def_cfa_offset 8.cfi_offset 4, -8.cfi_offset 14, -4.loc 1 83 0ldr r4, .L20.loc 1 91 0@ sp needed.loc 1 83 0movs r0, r4ldrb r1, [r4]adds r0, r0, #34subs r1, r1, #1 //r1寄存器的一样的操作 r1 = r1 - 1lsls r1, r1, #24 //关键改变!!!r1 = r1 * (2的24次幂),也就是算术左移24位lsrs r1, r1, #24 //关键改变!!!r1 = r1 / (2的24次幂),也就是算术右移24位bl checksum.LVL18:.loc 1 84 0adds r4, r4, #160.loc 1 89 0ldrb r3, [r4]lsls r0, r0, #24.LVL19:lsrs r0, r0, #24subs r0, r0, r3.loc 1 91 0pop {r4, pc}.L21:.align 2.L20:.word .LANCHOR4.cfi_endproc.LFE5:.size verify_checksum, .-verify_checksum
为了好对比,我直接使用对比工具贴图上来看下:
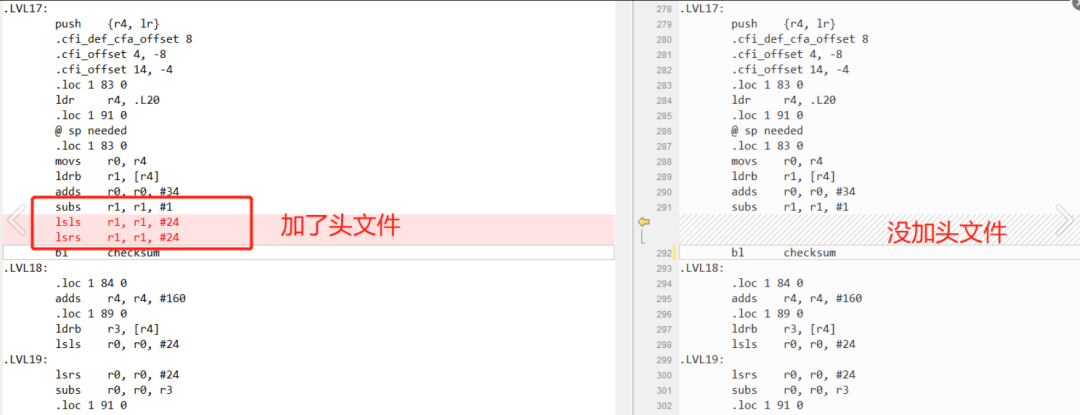
查了下多出来的这两条指令:lsls和lsrs,参考这里。
一个是算术左移24位,一个是算术右移24位,倒来倒去,无非就是把高24位给情况,这样-1的值传入checksum的时候,就只有0x000000FF了,而不是0xFFFFFFFF。
这样就把uint8_t len拉回正常的逻辑了,自然也就不会出现之前的for循环一直退不出来了。
7 扩展延伸
上面我提及的场景对应的是ARM平台的,由于我们的代码是跨平台的,支持RISC-V架构,X86架构等等。
7.1 RISC-V架构
所以我们来对比看下RISC-V架构下的情况:
这么看,RISC-V的处理也是够粗暴的,一个addi指令,把高24位去掉就完事了!!!
7.2 80x86架构
我push了一个简易的工程代码到github,以便于重现此问题,感兴趣的可以看这里。
很遗憾的是,在80x86上竟然没有复现此问题。
代码的核心差别就是是否include 2.h:
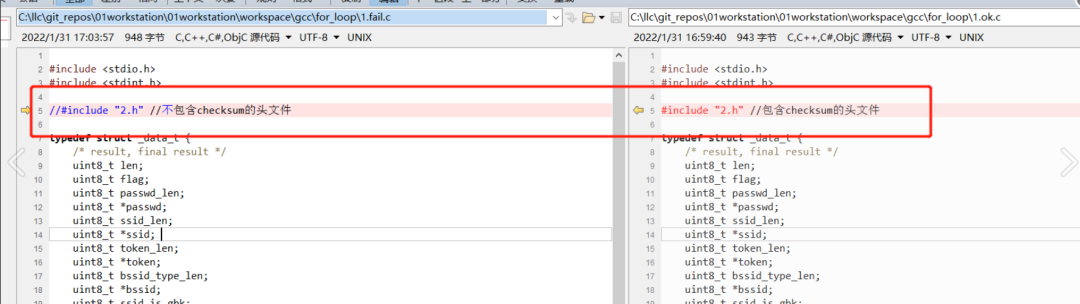
汇编代码确实有差异:
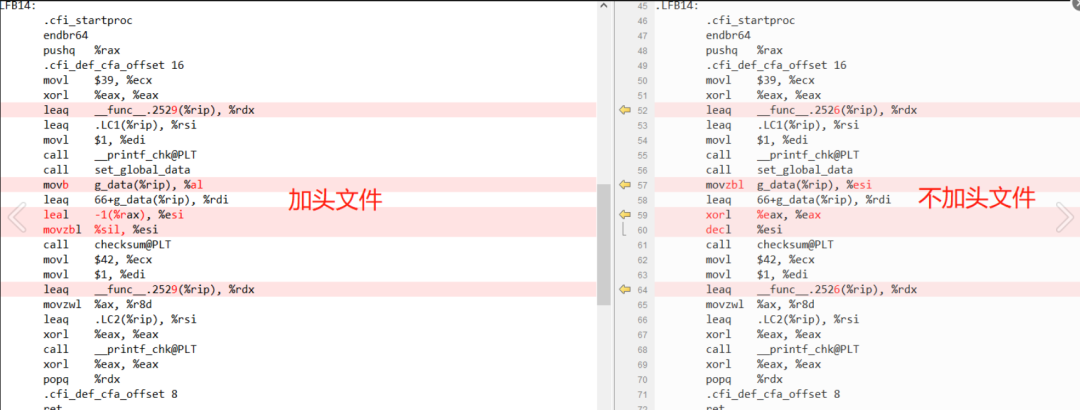
但是跑出来的效果确实一样的:
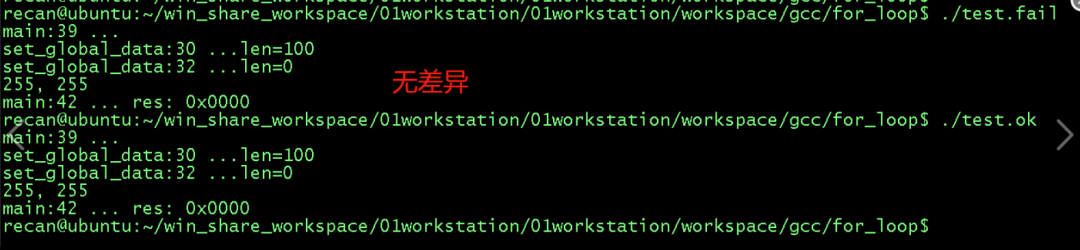
总结下没有复现问题的原因,可能是:
编译选项没有使用正确?
80x86编译器更懂事?更能知道如何合理编译代码?
还有未知的编译特性未了解到?
7.3 其他架构
感兴趣的可以在其他平台上验证下,是否有类似的问题,欢迎讨论。
8 经验总结
请提升你的代码编译严谨性,如果是gcc编译器,-Wall -Werror -Os是最低要求;
谈优化代码前,请close掉你的代码编译异常,先达到 0 error 0 warning 再说;
请重视warning: implicit declaration of function这个编译警告;
如果使用gcc编译器,不提示任何编译警告和错误,并不代表编译器没有告诉你,也许是你使用-w选项编译了输出,你仅仅是在自欺欺人而已;
老老实实在调用函数前申明你的函数,或者包含其对应的头文件,有时候编译器的默认行文不见得就可靠;
代码细节很重要,真的是细节决定成败;
不放过一丝可能性,作为一个攻城狮,这点专研精神需要时刻挂在心里;
大胆假设,小心求证,亘古不变的方法论。
审核编辑:汤梓红
-
汇编
+关注
关注
2文章
214浏览量
25898 -
代码
+关注
关注
30文章
4744浏览量
68343
原文标题:【汇编实战开发笔记】从汇编代码中找出一段普通的for循环变成“死循环”的根本原因
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
为什么要用汇编语言写程序
飞控中的疑难问题分享
如何有效地排查内存泄露的疑难问题
如何在C程序中使用汇编
视频会议系统中常见的疑难问题解答
电脑入门与提高疑难排解大全
模拟电子疑难问题解惑系列(三):成为熟练的电子工程师
模拟电子疑难问题解惑系列(四):滤波器、振荡器
关于高速AD/DAC测量及设计中82个疑难问题的解答
51单片机C语言调用汇编子程序的简便方法程序和工程文件免费下载

单片机使用汇编开发的简单介绍







 工商网监
工商网监
评论