 AI 能否帮助管理 SoC 验证所需的数据?
AI 能否帮助管理 SoC 验证所需的数据?
西门子公司 Mentor 仿真部门的技术营销总监 Thomas Delaye 最近研究了如何更有效地在芯片设计验证工具中使用数据,例如硬件仿真。他发现这是一个很大的挑战,因为硬件仿真存在数据问题,尤其是它生成的大量数据。接下来是 Lauro Rizzatti 对 Delaye 的采访,他们讨论了 AI 是否可以管理用于 SoC 验证的数据。
Lauro Rizzatti (LR):谢谢你今天加入我,Thomas。听说你做过大数据分析。也许您可以谈谈分析的标准和到目前为止的结果。
Thomas Delaye (TD):嗯,这并不是对大数据的真正分析。它更像是一个查看工程数据的项目,这与大数据不同。对我来说,大数据是关于创建大量信息的挑战,以及为特定目的有效处理信息的能力。
LR:您正在研究如何使用数据来增强或更有效地验证 SoC 设计。特别是硬件仿真。
TD:是的,没错。硬件仿真的数据问题有两个具体原因。第一个非常简单。硬件仿真会生成太多数据。想象一下,您有一个十亿门设计,并且您进行了十亿个周期的验证运行。在某些情况下,您捕获的数据量太大而无法处理甚至记录。波形等传统技术,每个人都已经使用了很长时间,但没有任何帮助,因为仅仅获得一百万个时钟的波形可能令人难以置信。除了大型数据集之外,还有整个基础架构可以将数据从模拟器中取出并存储。正如你可以想象的那样,这不是一件容易的事。
你是什么?这就是我们转向第二个问题的地方,即我们不想收集比需要更多的数据。通过管理数据收集,我们捕获了大量信息以用于验证设计。正是在这个更复杂的领域,人工智能可以发挥作用。
深度学习技术和机器学习算法可用于根据验证结果或设计行为来研究设计。AI 可以帮助确定要审查的数据的数量和类型,以帮助了解正在发生的事情。从那时起,验证工程师可以确定要进一步探索的内容。也许通过查看特定块并且仅查看该块而不是整个设计来启动后续运行或在当前运行中更深入地挖掘。突然之间,这个庞大的数据量变成了更合理的数据量。
从庞大的数据集到仅捕获可用数据量的这条路径是下一代验证平台的关键。这样,验证工程师就可以更精确地处理不断增长的设计规模和复杂性,以及不断增加的软件内容。
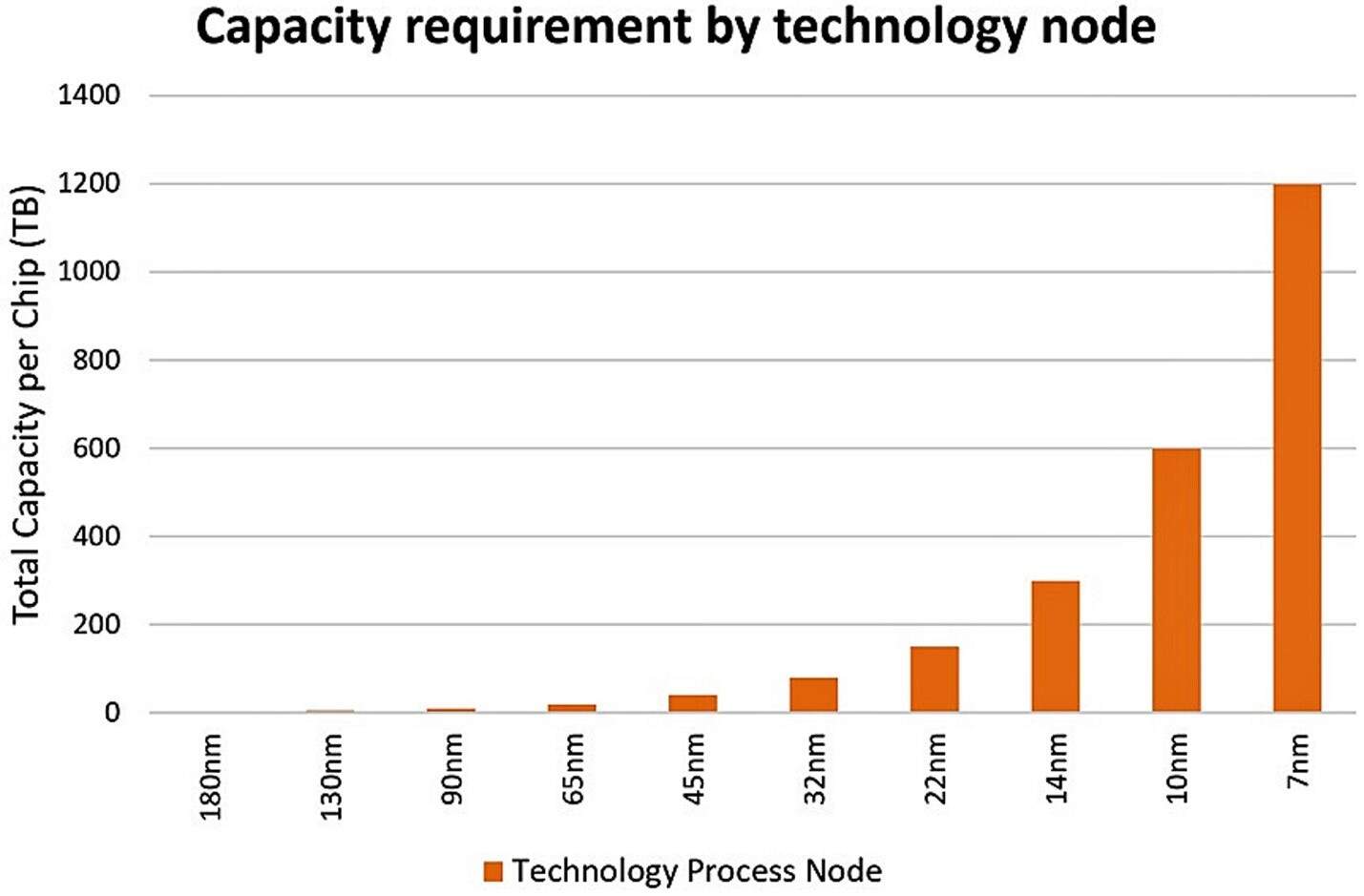
上图估计了 RTL 到 GDSII 流程中每个芯片与工艺节点的存储容量需求。资料来源:戴尔易安信
LR:您希望将仿真转移到这个下一代验证平台吗?
TD:在仿真中,我们有能力运行很长时间,并且有能力“处理”整个设计。例如,借助 Mentor 的 Veloce Strato,您可以在需要时随时查看所有内容。虽然很容易捕捉到你想要的一切,但没有多少人愿意这样做。所需要的是一种向用户提供关于何时和什么内容的指导的机制。
这是变得有点困难的地方,因为模拟器可以提供多种类型的数据。诸如运行中的基本信息之类的信息与设计本身无关。例如,运行的时钟周期数、执行的事务类型。我将所有这些数据称为通用细节。您只需拥有一个可以运行完整设计的具有完全可见性的快速平台即可访问它。
另一类基本信息是对设计行为的理解。例如,此信息让您知道设计现在正在重置中,您不需要捕获任何内容,因为重置序列只是重置所有内容。你只想等到下一个阶段。
这种类型的数据收集需要一个“大脑”,当访问特定内存或激活特定时钟结构时,大脑会显示重置。所有这些都需要设计知识。实现这一点非常复杂,因为仿真器必须查看设计中发生的情况,并将智能应用到过程中。模拟器通常不会这么做。仿真引擎和仿真引擎只是纯引擎。他们接收数据,处理数据,然后取出数据。然而,在Veloce Strato中,我们创建了用于特定目的的数据采集和分析环境。下一步是扩展这种能力,并减轻在整个系统级别验证具有大量数据的大型设计的痛苦。这就是挑战。
LR:你能给我一个具体的例子,说明数据问题的这两个方面在现实生活中是如何发挥作用的吗?
TD:是的。这是一个非常简单的例子。想象一下在基于事务的环境中运行很长时间的验证。您拉取一个报告,告诉您何时触发了一些DPI调用或事务调用。根据时间戳,尝试将该事件与设计中嵌入的处理器上运行的软件相关联。最后,您想确定此时我正在运行这段代码。
基于报告的用户正在得出这一结论,但仿真环境没有提供真正的相关信息。只有交易在给定时间发生。然后你可能会说,在这个时候,我正在运行和练习这个特定的块-例如,我的DDR。也许我应该看看我的DDR,以了解为什么我在这个时候发送这个交易。
用户要求我们建立关于设计中发生的事情的指针和信息,以便他们可以根据他们所知道的和他们知道要查找的内容返回并找到它。然后因为他们知道去哪里寻找,他们知道应该与哪个设计团队合作来解决它。有时,验证问题只是不知道应该咨询哪个设计师团队或外观问题。也许顺序不正确,或者某些代码加载不正确,或者其他原因。在我的 100 亿门设计中首先看什么以及在哪里看?这是第一个问题。
接下来,他们正在寻求有关可以提供哪些数据以帮助他们专注于一个特定问题的帮助。我们不需要告诉他们问题出在哪里。当然,那会更好。当我们可以根据收集到的所有数据提供范围狭窄的数据时,它将使所提供的各种日志之间的关联变得更容易。
另一方面,我们也可以想象有某种验证方法可以创建标准接口或集中方式向工具提供数据,以识别最常见的问题块,或信号类型或行为类型。进行了调查。所有这些东西都可以根据需要提供给模拟器,就像你提供断言一样,但是比较模糊,所以你不想花太多时间在上面。只是说,如果您在电源线上看到不符合正确顺序的东西,您应该标记它。我们可以提供数据来缩小分析范围。
LR:在这个思考和搜索的过程中,您是否遇到过任何您认为重要数据点的文献、文章、博客等?
TD:不是我能想到的。我认为没有人从学术甚至公众的角度来处理这个问题。我认为这个问题是验证的下一步。这无疑是一个全球性的问题,目前还没有很好的答案。每个人都在向人工智能寻求帮助。
此外,人工智能引起了我们所有用户的特别关注,因为如果我们有效地使用人工智能,我们将能够几乎对他们的代码进行逆向工程。而且我很确定,由于保密性和安全性,许多公司不愿意向我们提供任何细节或提供任何设计或提供日志。我认为这种验证方法的安全性将是困难的。在这种情况下,我们将不得不找到比 AI 更有意义的方法,而不仅仅是提供波形。
再次感谢您的有趣对话和见解,Thomas。也许我们可以在未来跟进,看看这项工作是如何进行的。
审核编辑 黄昊宇
-
soc
+关注
关注
38文章
4177浏览量
218464 -
AI
+关注
关注
87文章
31079浏览量
269413 -
人工智能
+关注
关注
1792文章
47400浏览量
238906 -
大数据
+关注
关注
64文章
8896浏览量
137514
发布评论请先 登录
相关推荐
芯片设计进阶之SOC电源管理系统介绍
soc设计中的热管理技巧
Rockchip SoC 赋能 AI 与视觉创新:推动智能设备的未来发展

戴尔升级非结构化存储与数据管理,AI创新引领新变革
《AI for Science:人工智能驱动科学创新》第二章AI for Science的技术支撑学习心得
新思科技PCIe 7.0验证IP(VIP)的特性

【HZHY-AI300G智能盒试用连载体验】基建智慧工地物联边缘代理技术研究及应用
西门子推出Solido Simulation Suite,帮助客户大幅提升验证速度
瑞萨如何利用Synopsys VSO.ai将SoC验证生产率提高30%
NanoEdge AI的技术原理、应用场景及优势
用于SoC和多轨子系统的TPS650250电源管理 IC (PMIC)数据表

是德科技推出AI数据中心测试平台旨在加速AI/ML网络验证和优化的创新





 工商网监
工商网监
评论