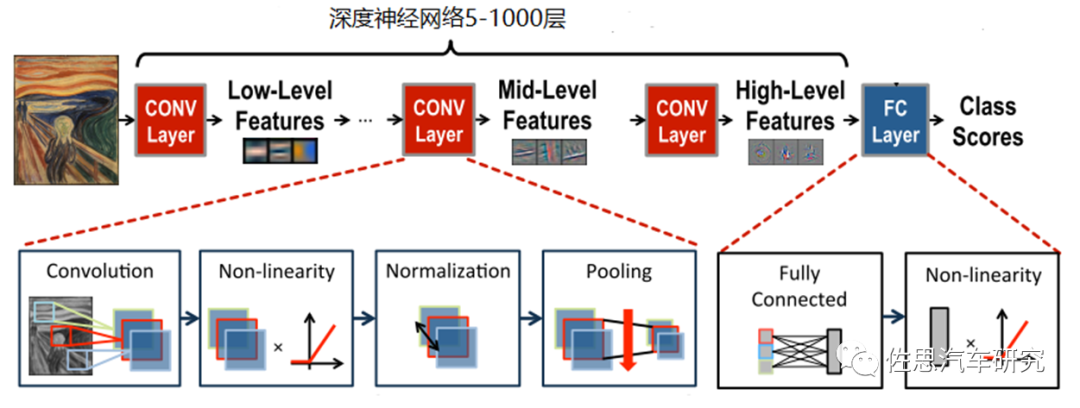
 如何提升NPU的能效比?
如何提升NPU的能效比?
现如今,深度神经网络正在以越来越大的规模部署,横跨了从云端,自动驾驶到IoT等平台。比如用于图像识别,语音识别及翻译,癌症检测以及自动驾驶中对感知层海量数据的处理等。在很多领域,深度神经网络的精度已经超越人类,它的优越性来源于它对原始数据的特征提取,并通过对大量数据的学习来获取输入空间的有效表征,但是它的高精度是以超高计算复杂度为代价。因此很多厂商都在追逐NPU的算力来解决这些复杂问题,但是随着算力的提高,NPU设计也越来越复杂,将伴随着面积和功耗的增加,这对于那些面积和功耗有很大限制的设备带来了挑战,因此如何提升NPU的能效比就成了亟待解决的问题。
NPU通过数据分区和有效调度,利用数据的重用以及执行分段来提高能效比和硬件利用率,而实现高利用率,数据重用将直接依赖于如何调度深度神经网络的计算和如何将这些计算有效的映射到NPU的硬件单元上。以CNN为例,数据流无非包含三个方面filter(Weight),ifmap和ofmap,如下图。
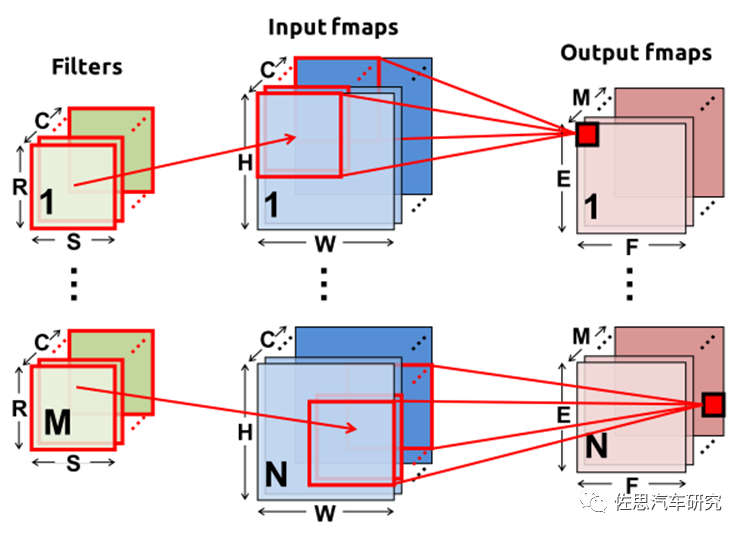
因此在设计NPU时需要考虑如利用内存的层次结构,决定哪些数据要读到那一层的内存中以及什么时候被处理,如何可以重用filter,ifmap和ofmap,将他们存放在本地内存中,从而大大减少DRAM的访问次数,这将在很大程度上提高NPU的硬件利用率及性能,并减少由于DRAM访问带了的额外功耗。根据数据处理特征可以将数据流分为以下几类:
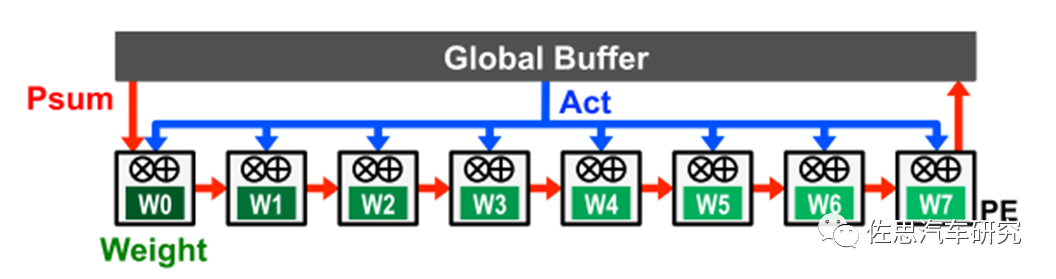
1)、静态weight
weight静态数据流的设计是通过在PE的RF(Register File)中存取weight,来减少读取weight产生的功耗。weight从DRAM读取到RF并保持静态以供进一步访问,NPU在计算时尽可能多的利用RF中的weight以达到最大程度的重用。通常的实现是将ifmap广播给所有的PE,部分和(Psum)将穿过所有的PE来完成空间上的累加。
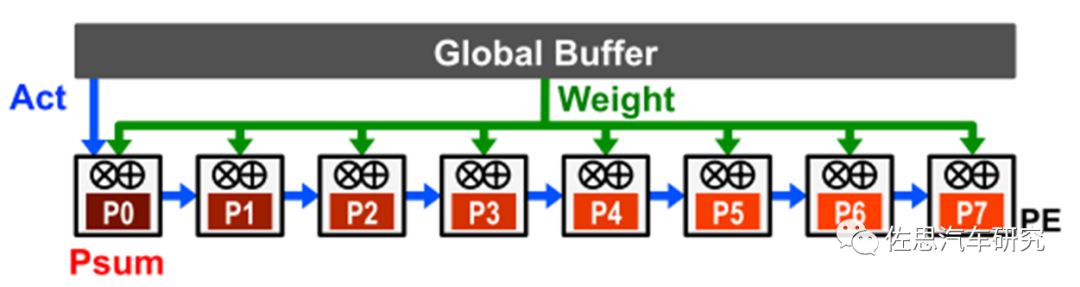
2)、静态输出
输出静态数据流的设计是通过将accumulator产生的Psum存放到本地的RF中,以避免将Psum刚写入DRAM再读回,从而减少因Psum读写产生的功耗。通常的实现是流式输入Activation,并将weight广播给所有的PE。
3)、无本地重用
如果考虑到RF会增大面积,可以将所有的数据都存放到Global Buffer中,这样没有任何数据会留在PE的RF,也不会增设RF单元来减小面积,但是增加了PE和Global Buffer的数据交互。具体来说是通过多广播Activation,单广播Weight以及Psum穿过所有的PE进行累加来实现的。
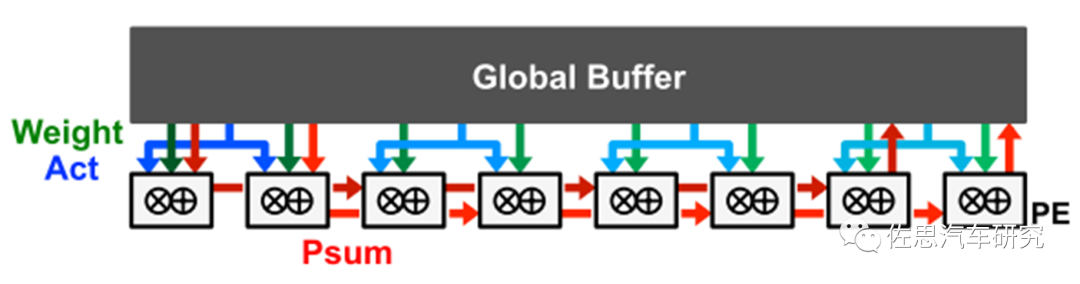
4)、静态行
静态行数据流的目标是将所有的数据类型(Activation,weight, psum)的重用和计算都在RF中完成,来提升总体的能效。它区别于上面的静态weight和静态输出,只是分别对weight和psum进行优化。
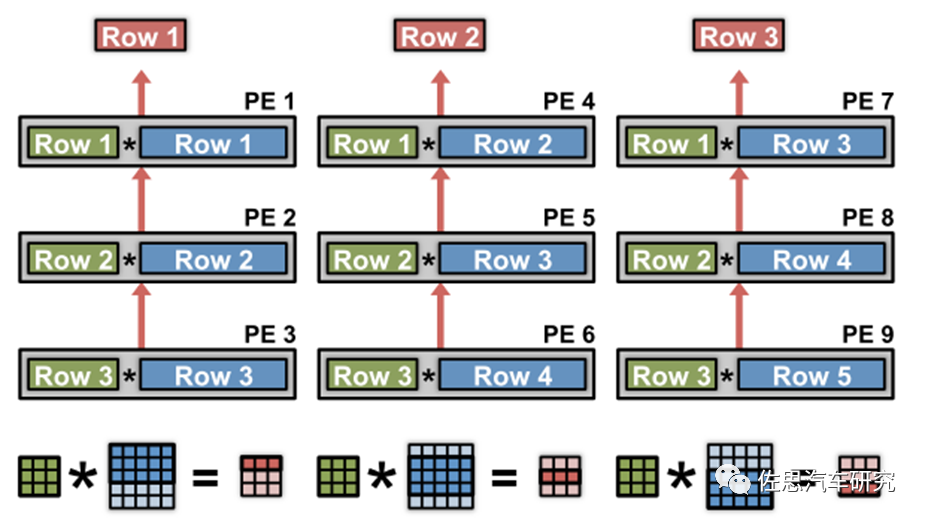
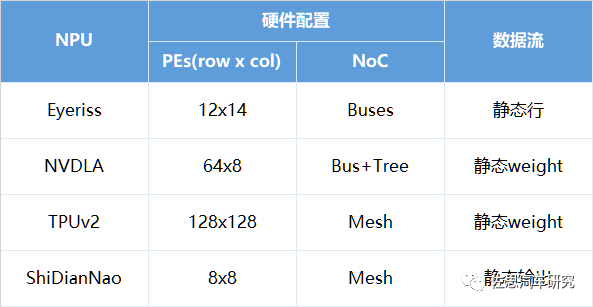
具体选用哪种数据流方式要结合NPU微架构的设计。下面总结了来自于几个厂家的NPU,它们分别利用了不同数据流类型来提高能效比。
参考文献:
【1】Vivienne S. Yu-Hsin C.and etc., “Efficient Processing of Deep Neural Networks: A Tutorial and Survey”
关于复睿微电子:
复睿微电子是世界500强企业复星集团出资设立的先进科技型企业。复睿微电子植根于创新驱动的文化,通过技术创新改变人们的生活、工作、学习和娱乐方式。公司成立于2022年1月,目标成为世界领先的智能出行时代的大算力方案提供商,致力于为汽车电子、人工智能、通用计算等领域提供以高性能芯片为基础的解决方案。
目前主要从事汽车智能座舱、ADS/ADAS芯片研发,以领先的芯片设计能力和人工智能算法,通过底层技术赋能,推动汽车产业的创新发展,提升人们的出行体验。在智能出行的时代,芯片是汽车的大脑。复星智能出行集团已经构建了完善的智能出行生态,复睿微是整个生态的通用大算力和人工智能大算力的基础平台。复睿微以提升客户体验为使命,在后摩尔定律时代持续通过先进封装、先进制程和解决方案提升算力,与合作伙伴共同面对汽车智能化的新时代。
审核编辑 :李倩
-
芯片
+关注
关注
455文章
50832浏览量
423812 -
神经网络
+关注
关注
42文章
4772浏览量
100789 -
NPU
+关注
关注
2文章
285浏览量
18619
原文标题:ADS算力芯片NPU数据流的重用性
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
IO模块助力PLC,全面提升中水处理设备能效

Erp指令能效
NPU与机器学习算法的关系
NPU的工作原理解析
NPU在边缘计算中的优势
NPU技术如何提升AI性能
什么是NPU芯片及其功能
AcrelEMS企业微电网能效管理平台如何辅助企业进行能源平衡优化?
智慧水务综合能效管理系统-提高污水厂能效
利用AI和加速计算提升天气预报效率和能效
重磅!英特尔发布intel3制程至强6能效核处理器,赋能数据中心能效升级

AMD披露高效数据中心策略,预计至2027年能效提升超百倍
天玑9300旗舰芯:全大核CPU架构,性能与能效的提升
智慧水务能效管理平台-为污水处理的能效管理提供科学、精细的解决方案





 工商网监
工商网监
评论