 SPL的实际应用效果如何呢?
SPL的实际应用效果如何呢?

前段时间的俄乌冲突,Oracle 宣布“暂停在俄罗斯的所有业务”,相信大家的心情绝不是隔岸观火,而是细思恐极。
数据库号称 IT 领域三大核心之一(其他两个是 CPU 和操作系统),一直以来都被国际巨头垄断,人家控制着核心,想什么时候锁喉就什么时候锁,你一点办法都没有。
现在解决这个问题的办法只能是自强,将数据库核心技术掌握在自己手里,做属于自己的国产数据库。其实,这个事我国也已经张罗了几十年,早在上世纪 80 年代以研究所和大学为主的国家队就开始投入研发国产数据库,并在 90 年代相继推出了几款数据库产品。不过可惜的是这些产品研发从一开始就缺乏产业端的接入,并不是因为实际需求的刺激,而纯粹是为了拥有。这样,产品在商业市场的拓展也比较弱。作为追赶者,始终也没有看到对手的背影。
知乎上有个问题:“中国跨过数据库这座大山了吗?” 翻译一下就是:现在有完全自主研发的国产数据库了吗?回答有 100 多个,看了看不是普及数据库知识的就是推广自家产品的,大多回答并没有直面这个问题。确实也没法直面,因为我们还不能说已经翻过这座大山了。
国产数据库现状
这几年,雨后春笋般地冒出数百个国产数据库,但有多少拥有原创技术呢?
其实没多少!甚至可以粗暴一点说:几乎没有!
这几百个国产数据库中,绝大多数是基于开源数据库改造的,90% 都不止。其中又有绝大部分(大概又是 90%)是基于 MySQL 或 PostgreSQL 改造的。
MySQL 作为最著名的开源数据库,由于使用者众多、兼容性强、接口丰富等因素,被很多国产数据库厂商用来改造成自家产品也不足为奇,毕竟熟悉它的人不少,改造成本也低一点。
不过,相对 MySQL,基于 PostgreSQL(俗称 PG)封装的更多。这是由于 PG 采用 BSD 开源许可非常宽松,允许修改源码后再闭源,甚至不需要版权声明。因此 PG 成为众多国产数据库厂商的最爱,纷纷基于 PG 封装出自己的“原创”国产数据库,包括某些以创新闻名的著名大厂。正所谓“国外一开源,我们就原创”,有的厂家甚至懒得改造(也可能是没能力改造),连驱动程序都能直接借用。
除了 MySQL 和 PG 这两大阵营外,也有一些基于其他开源数据库封装的,不过数量很少。有些国产数据库看似原创,但其实是基于某个已经退出江湖的古老开源数据库改造的,现在很难看出来就被误以为原创了。
除了使用开源库封装,还有一些国内数据库厂商通过购买源码实现“自主”。像 2015 年有几家中国公司购买了 Informix 源码来发展自己的数据库。
这些“借用别人”的非原创数据库厂商,大多数并没有掌握核心技术,毕竟消化上千万行代码也不是一件容易的事儿。虽然手里有源代码,却仍然很难进行深入的改造,未来升级发展也要仰人鼻息。有些时候甚至还会有协议和法律问题,比如 MySQL 现在的所有权归 Oracle 所有,天知道哪天 O 记不高兴了会不会对我们干些啥。
不过,欣慰的是,还是有少量难能可贵的厂商是从 0 开始自主实现的。比较有代表性的是 OceanBase。因为诞生于互联网企业,面对急速扩张的业务,继续使用国外商用数据库无论在成本上还是容量上都难以支撑,自身就有很有很强的动力摆脱对国外产品的依赖,就必须走出一条自研之路。当然,从头自研一个数据库并非易事,这是个十年才能磨一剑的艰辛事业,肯这样熬的厂商确实是凤毛麟角。
除此之外,我们还有另一个更奇葩的也是十年磨出一剑的,一个看起来不像数据库却能完成大量数据库任务的产品:润乾软件开发的集算器 SPL。它不仅在工程实现上完全自主开发,连理论模型都是自己原创的,突破的不仅仅是数据库本身,还有背后的理论框架,这样的产品在国内可以说更是绝无仅有的了。
SPL 是啥?和数据库有啥关系?效果咋样?背后又突破了什么理论?下面我们就来说道说道。
SPL 的由来
SPL 的开发主体是润乾软件,润乾报表你可能听过或用过,是 20 年前为了解决中国式复杂报表制作创新的一个产品,其中使用了独创的非线性报表模型理论。我们知道,报表是一个强数据计算场景,数据库中的数据距离要呈现出来的数据还很远,需要很多步骤的复杂运算才能得到。而报表工具只能解决呈现环节那一步的少量计算,对于进入报表工具之前的数据计算则无能为力。这导致了虽然有成熟的报表工具来解决格式及呈现环节的计算问题,而报表开发却依然很难的现状。
对于这个问题,业界也没什么好办法,只能是写复杂 SQL(以及存储过程)或者在应用程序中用高级语言 (如 Java)编程,十分繁琐低效。而且由于 SQL 和 Java 的开发特性,还会带来耦合性高、维护困难等问题。
在这样的背景下,我们希望找到一种方式来解决数据计算难、计算慢的问题。我们通过大量总结分析碰到的各种数据计算问题后发现,如果继续沿用 SQL 的技术体系无论如何也解决不好这个问题,充其量在工程上做些优化(现在大多数数据库在做的),新瓶装旧酒而已。
SQL 的理论基础是关系代数,SQL 之所以难以应对复杂数据计算,根本原因是背后的关系代数理论。想要根本解决这个问题就不能再基于关系代数。
那怎么办?
既然没有现成的可用,就只能发明新的了,使用新的理论模型解决计算难题!
不过,这事儿说起来轻松,做起来却不容易。从 2007 年开始,我们用了十多年时间,历经四次大的重构才把模型和结构稳定下来,形成了一套理论模型——离散数据集,基于这套模型开发出了 SPL(Structured Process Language),专门用于结构化数据计算的程序设计语言,配合有存储机制后,也可以理解成为数据仓库产品。
由于 SPL 采用了新的理论模型,在市面上根本没有其他产品可以借鉴,更不可能有现成的开源代码可以“借用”,只能完全自己一行一行开发。所以,SPL 的核心运算模型代码从头到脚都是完全自主原创的。连理论基础都是自己发明的,代码更加只能原创,你说够不够自主?
说到这你可能发现,SPL 看起来跟传统数据库不太一样,它的实际应用效果如何呢?
SPL 应用效果
对于大数据计算类任务来讲,就已应用的效果来看,SPL 在实践中的表现非常出色。实现复杂计算时,不仅代码简短,性能相较于传统数据库通常能快一个数量级以上。
国家天文台的某个天体计算场景:11 张照片,每张 50 万天体(目标规模为 500 万),天文距离(三角函数计算)较近的天体被视为同一个,需要将不同照片中的“相同”天体合并,属性重新聚合。
这个任务的技术本质是个非等值关联,计算量是平方级的(也就是 50 万 *50 万 =2500 亿)。Python 代码约 200 行,单线程计算 6.5 天,按个速度估算,目标的 500 万规模需要近 2 年时间,彻底没有可实用性;国内某大厂的分布式数据库上动用了 100 个 CPU 的 SQL 代码也用了 3.8 小时,算下来单核计算速度比 Python 还慢;而 SPL 实现的优化代码仅 50 多行,利用任务特点大幅降低了计算量(远不到 2500 亿),在 4 核的笔记本上仅用 2 分多钟就完成了计算,计算 500 万的目标规模只要数小时就能搞定,完全可以实用。
这个差距的背后:受限于理论模型的 SQL,无法实现这种优化技术,只能眼睁睁地看着计算资源消耗;Python 硬编码虽然可以实现优化算法,但工作量巨大,代码将远不止 200 行;只有 SPL,代码更短,还跑得更快。
不仅如此,在其他行业,SPL 的优势也很明显。
在某保险公司团体保明细单查询场景中,SPL 相比 Oracle 性能提升了 2000 倍,同时代码量减少了 5 倍以上……
在某保险公司车险跑批计算优化场景中,使用 SPL 将 RDB 跑批时间从 2 个小时优化到 17 分钟,而实现代码从原来的 2000 行缩短到不到 500 行……
在某银行的客户画像场景中,SPL 将用户画像客群交集计算性能提升了 200 倍以上……
在某金融用户的报表查询场景中,SPL 将报表计算时间从 3700 秒缩短到 105 秒,提升了 35 倍多……
…… 类似的案例 SPL 实施过不少,还没有失手过,平均提速超过一个数量级,同时代码量降低数倍。
这里还有一份性能测试报告:《全国产计算数据库性能测试报告》(http://c.raqsoft.com.cn/article/1564972044122)。用 SPL 在国产芯片上实现的运算,能超越在 Intel 芯片上跑的 Oracle。这都是 SPL 理论创新(离散数据集)带来的效果。
SPL 为什么更强
我们看到 SPL 的应用效果后不禁要问,SPL 到底有何种魔法居然能达到这些惊为天人的效果?SPL 背后的理论基础离散数据集模型到底是什么样的?
SPL 的优势主要集中在两点,实现数据计算的代码简短(写得简单),而且性能更高(跑得快)。那是 SPL 改变了计算机的速度了吗?并没有,软件不可能改变硬件的性能。SPL 更强的原因是因为设计了很多别人没有的算法(和存储机制),基于这些算法可以让计算机少执行一些运算,从而获得高性能,而这些算法大都要依靠离散数据集理论才能很好实现。
下面是 SPL 的部分算法,很多都是 SPL 的独创发明,在业内首次提出,窥一斑而知全豹。

像常见的 TopN 运算,在 SPL 中 TopN 被理解为聚合运算,这样可以将高复杂度的排序转换成低复杂度的聚合运算,而且很还能扩展应用范围。
A
1=file(“data.ctx”).open().cursor()
2=A1.groups(;top(10,amount))金额在前 10 名的订单
3=A1.groups(area;top(10,amount))每个地区金额在前 10 名的订单
和 SQL 不同,SPL 完成这个运算的语句中没有排序字样,也就不会产生大排序的动作,在全集还是分组中计算 TopN 的语法基本一致,不仅写法上更简单,性能也更高。而 SQL 只能写出有排序字样的语句,是不是能跑得快就只能指望数据库的优化引擎了,简单情况时数据库还能对付,但情况复杂时连 Oracle 这样的资深数据库都会“晕掉”,这里有相关的详细测试案例:性能优化技巧:TopN 。
我们已经将 SPL 的离散数据集理论整理成论文( SPL论文 http://c.raqsoft.com.cn/article/1653097658478 ),其中严格地定义了离散数据集代数体系,并描述了它与关系代数的不同。
高性能靠的不是代码,而是代数,代码只是个实现手段而已,关键是 SPL 背后的理论体系中提供的数据类型和算法以及存储模型。
这篇文章 写着简单跑得又快的数据库语言SPL 中用更通俗的说法解释了 SPL 的高效原理。关系代数和 SQL 就像小学时代的算术,只有加减乘除,而离散数据集和 SPL 则相当于增加了中学的乘方开方指数对数。加减乘除可以应对日常购物买菜,但要造出飞机大楼就必须用到更多的数学了。
了解了这些,再看前文提到的在国产芯片上跑出超越 Oracle 在 Intel 芯片上的性能也就不神奇了。即使国产芯片还有很长的路要走,基于 SPL 打造完全自主、高效的国产数据库也能成为现实,让国产芯片也能插上翅膀腾飞起来。
SPL 的未来
当然,SPL 本身也还有很长的路要走,目前已发布的功能还只面向 OLAP(数据分析)场景,主要解决数据计算难题。我们知道,数据库除了计算还有交易,就是常说的 OLTP 能力。在面向交易的场景,SPL 仍然会通过创新解决当前数据库面临的各类问题。
还是创新
现在数据库上云已经是大势所趋,但是简单地把关系数据库从本地搬到云上并不能体现出云应用的特征。云应用的基本特征在于数据结构的多样性。云数据库要同时为多个用户提供服务,而不同用户的数据结构可能不同,同一个用户在不同时段的数据结构也会变,这样就会积累大量不同结构的数据要一起存储和计算。这就会面临个性化(不同数据结构)和海量用户的矛盾,这是关系数据库无法解决的问题。
事实上,50 年前诞生的数据库在设计时并没有考虑过这个问题(也不可能想到 50 年后的需求),因此关系代数中几乎没有设计针对多样性结构数据的处理能力。想要解决这个问题就不能再沿用关系代数体系。
同时,关系数据库在实现一致性时成本过高,资源消耗严重,导致并发能力下降。而高并发又是云应用的典型特性,这又成了一对不可调和的矛盾。这个问题的原因在于它的数据组织机制(数据类型),这仍然是由其理论关系代数决定的。想要同时兼顾一致性和高并发就还要打破关系代数的限制,换一种方式组织和存储数据。
突破理论限制才能从根本上解决问题,SPL(离散数据集)正当时!
这个未来也并不遥远,SPL 面向 OLTP 的功能已经在实验室中打磨了几年,再完善一段时间就可以亮剑出窍,届时完全基于自主原创理论的国产数据库将划破天际。
超越
同时,理论上的创新还可能带来另外一个结果,那就是:超越!在数据库领域实现对国外产品的超越。
我们明白,作为追赶者,采用技术跟随战略是没希望的。目前的国产数据库绝大多数仍然是关系数据库,可以说都是技术跟随者。而国外巨头们做这些事已经好几十年,人强钱多积累厚,我又没有三头六臂,凭什么超越人家呢?唯一的可能就是对手犯错,但是作为十名开外的我们不能指望前面 N 名对手同时犯错吧。而寄希望于某种政策把国外产品拒之门外,也有点没出息不是,而且在这开放的年代也不太可能出现这种情况。
那么就唯有创新!
数据库,我们必须比对手做得更好,还要好很多,这样才有机会超越,才能弥补生态的不完善。而要做得更好,就需要有颠覆性的技术,在新技术面前我们和对手是站在同一起跑线上的。
关系数据库已经发明了几十年,早就不适应现代更复杂的应用需求和更强大的硬件环境,很多看似简单的问题非常难做,开发维护成本很高,也不能充分利用计算机资源,眼睁睁地忍受低性能。
对于那些关系数据库巨头来讲,要向股东交代,就要保持稳定的收益,它还不能随便革掉自己的命,结果反而处于相对不利的局面。这就给了能在理论层面创新的产品机会,实现超越并非异想天开。
马车再高档也还是马车,无论如何优化都还是要靠马拉动。初生的汽车,操作上当然会有各种不习惯,功能上也会有众多不如意。但它是发动机驱动的,假以时日不断完善,它的巨大优势必将全面碾压马车。
让我们拭目以待,也让我们砥砺前行!
审核编辑 :李倩
-
SQL
+关注
关注
1文章
807浏览量
46925 -
数据库
+关注
关注
7文章
4082浏览量
68538 -
spl
+关注
关注
0文章
22浏览量
16797
原文标题:有没有完全自主的国产化数据库技术
文章出处:【微信号:cxuangoodjob,微信公众号:程序员cxuan】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
更新 SPL 和 U-Boot的提示和技巧
学生宿舍稳压续航直流UPS(iUPS)好不好?效果如何?
如何使 i.MX93 上的 U-Boot SPL 和 ATF/BL31输出静音呢?
实战排障|RK平台启动卡死、SPL崩溃,两行日志直接定位DDR硬件死穴!

U-Boot SPL核心文件spl.c深度解析:从启动流程到调试优化
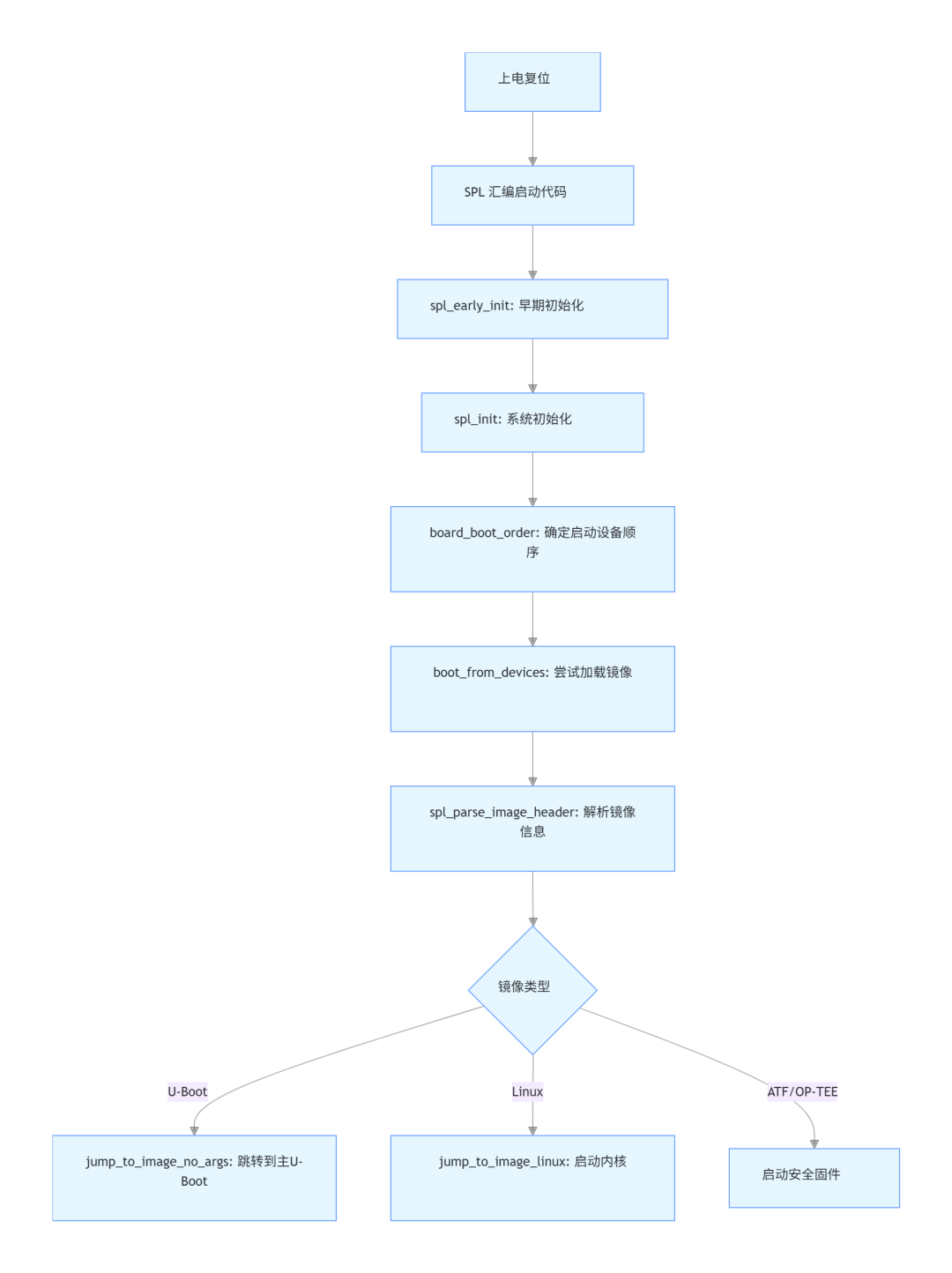
深度解析SPL阶段A/B分区启动:spl_ab.c代码全拆解

光伏“可观”功能效果如何量化?——效益与技术实现深度评估
Neway电机方案在实际应用中效果如何?
合粤固液混合电容在哪些车型上有应用呢

【EASY EAI Nano-TB(RV1126B)开发板试用】+LED闪烁效果及按键控制
LCD屏幕无法正确显示效果如何解决?
fn_u-boot-spl.bin和u-boot-spl.bin区别是什么?请问如何从u-boot-spl.bin生成fn_u-boot-spl.bin?
超声波清洗机对于微小毛刺的去除效果如何?

探索吉他音色与效果器的奇妙世界(3)- 时延和哇音效果器

超声波清洗设备的清洗效果如何?



评论