 利用对比前缀控制文本生成以及长文本生成的动态内容规划
利用对比前缀控制文本生成以及长文本生成的动态内容规划

引言
文本生成作为人工智能领域研究热点之一,其研究进展与成果也引发了众多关注。本篇主要介绍了三篇ACL2022的三篇文章。主要包含了增强预训练语言模型理解少见词语能力的可插拔模型、利用对比前缀控制文本生成以及长文本生成的动态内容规划。
文章概览
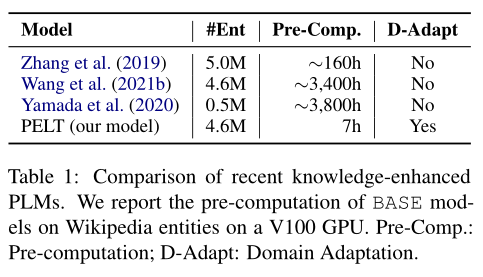
1. A Simple but Effective Pluggable Entity Lookup Table for Pre-trained Language Models
一个简单但有效的预训练语言模型的可插拔实体查找表
论文地址:https://arxiv.org/pdf/2202.13392.pdf
预训练语言模型(PLM)不能很好地回忆大规模语料库中实体词语的知识,尤其是那些少见的实体。这篇文章通过将实体在语料库中多次出现的输出嵌入表示结合起来,构建了一个简单但有效的可插拔实体查找表(PELT)。PELT可以兼容地插入PLM,向其补充实体词语的知识。与以往的知识增强PLM相比,PELT仅需要0.2% ~ 5%预训练的计算量,并具有从不同领域语料库获取知识的能力。
2. Controllable Natural Language Generation with Contrastive Prefixes
带有对比前缀的可控文本生成
论文地址:https://arxiv.org/pdf/2202.13257.pdf
为了引导预训练语言模型的生成具有某种属性的文本,以前的工作主要集中在微调语言模型或利用属性鉴别器。这篇文章在前缀微调的基础上进行改进,考虑了前缀之间的关系,同时训练多个前缀。本文提出了一种新的监督学习和一种无监督学习来训练单个属性标签控制的前缀,而这两种方法的结合可以实现多个属性标签的控制。实验结果表明,该方法能够在保持较高语言质量的同时,引导生成文本具有所需的属性。
3. PLANET: Dynamic Content Planning in Autoregressive Transformers for Long-form Text Generation
PLANET:用于长文本生成的自回归Transformer中的动态内容规划
论文地址:https://arxiv.org/pdf/2203.09100.pdf
现有的方法在长文本生成任务中存在逻辑不连贯的问题,这篇文章提出了一个新的生成框架PLANET,利用自回归的自注意力机制来动态地进行内容规划和表层实现。为了指导输出句子的生成,该框架将句子的潜在表征补充到Transformer解码器中,以维持基于词袋的句子级语义规划。此外,该模型引入了一个基于文本连贯性的对比学习目标,以进一步提高输出的内容连贯性。在反驳论点生成和观点文章生成这两个任务中,该方法明显优于base line,能生成更连贯的文本和更丰富的内容。
论文

动机
一些最新的研究表明,预训练语言模型(PLM)可以通过自我监督的预训练从大规模语料库中自动获取知识,然后将学到的知识编码到模型参数中。然而,由于词汇量有限,PLM难以从大规模语料库中回忆知识,尤其是少见的实体。
为了提高PLM理解实体的能力,目前有两种方法:
一是从知识图谱、实体描述或语料库中获得外部实体词嵌入。为了利用外部知识,模型将原始词嵌入与外部实体嵌入对齐。缺点是忽略了从PLM本身探索实体嵌入,使得所学到的嵌入没有领域适应性。
二是通过额外的预训练将知识注入PLM的参数中,例如从语料库构建额外的实体词汇,或采用与实体相关的训练前任务来强化实体表示。缺点是额外预训练计算量过于庞大,增加了下游任务扩展或更新定制词汇表的成本。
本文为了解决前两种方法的缺点,引入了一个简单有效的可插拔实体查找表(PELT),将知识注入到PLM中。优点是只消耗相当于0.2% ~ 5%的预训练计算量,并且支持来自不同领域的词汇。
模型
重新审视Masked Language Modeling
PLM进行自我监督的预训练任务,如掩码语言建模(Masked Language Modeling,MLM),从大规模未标记语料库中学习语义和句法知识。MLM可以看作是一种完形填空任务,根据上下文表示来预测缺失的词。
给定一个词序列, MLM先将其中某个词语替换为[MASK]标记,再将替换之后的进行词嵌入和位置嵌入作为PLM的输入,获得上下文表示:
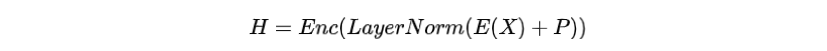
其中为Transformer的编码器,为层归一化,为词嵌入,为位置嵌入。
然后PLM使用前馈神经网络(FFN)来输出被掩盖位置的预测词嵌入
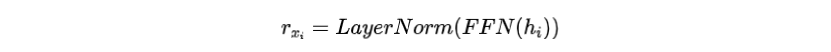
进一步计算在所有单词之间的交叉熵损失
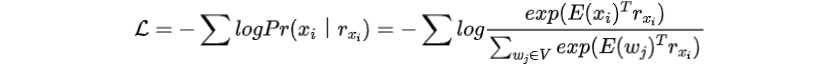
重新审视上式中的损失,可以直观地观察到词嵌入和PLM的输出位于同一个向量空间。因此,我们能够从PLM的输出补充实体词的嵌入,将其上下文知识注入到模型中。
构建可插拔的实体嵌入
具体地说,给定一个通用的或特定于领域的语料库,本文的模型构建了一个实体词查找表。对于实体,例如Wikidata实体或专有名词实体,我们构造其嵌入如下:
步骤1:收集所有包含实体e的句子,并用[MASK]掩盖
为了在PLM词汇表中加入实体,可以在其他参数被冻结的情况下优化其嵌入。首先收集包含实体的句子,并用[MASK]替换。在中,对MLM损失的影响为
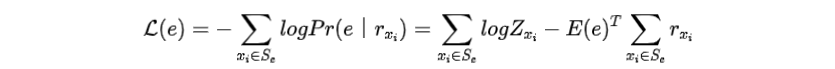
其中
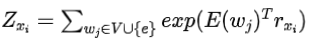
步骤2:求
与整个词汇量对的影响相比,的影响要小得多。如果忽略这部分影响,
求对的最优解,那么的结果与成正比,记为
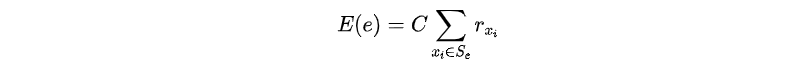
其中为比例因子。
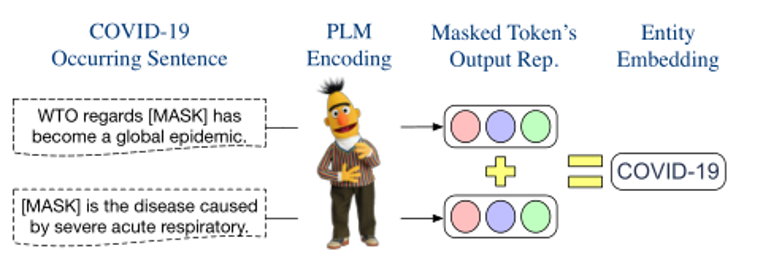
这里说明了将若干个相加即可得到实体的新嵌入表示,如下图所示。
将实体知识注入PLM
由于上述得到的新的实体嵌入和原始词嵌入都是从MLM中获得的,因此新的实体嵌入可以看作是一个特殊的输入表示。为了将实体知识注入到PLM中,本文使用一对括号将构建的新嵌入包围起来,然后将其插入到原始实体词嵌入之后。例如,原始输入为Most people with COVID-19 have a dry [MASK] they can feel in their chest.,在注入新嵌入之后变为•Most people with COVID-19(COVID-19)have a dry [MASK] they can feel in their chest.
括号中的即为实体COVID-19新嵌入,而其他词使用了原来的嵌入。本文只是将修改后的输入传递给PLM进行编码,而不需要任何额外的结构或参数,以帮助模型预测[MASK]处的单词为"cough"。
实验
论文比较了关系分类、知识获取的准确率:
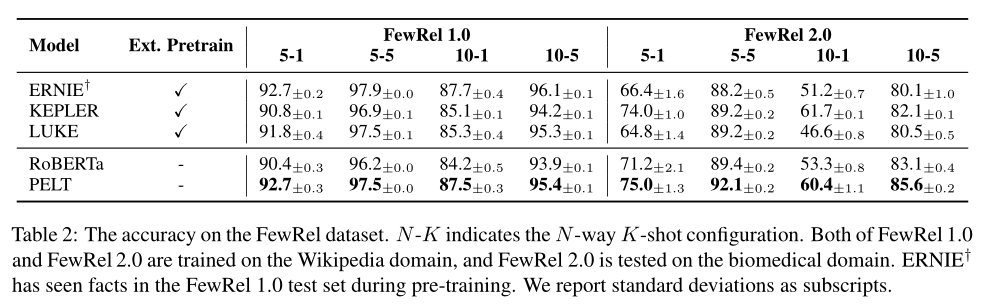
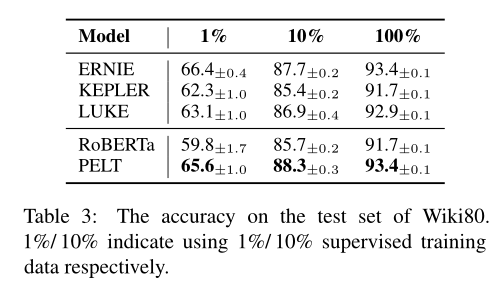
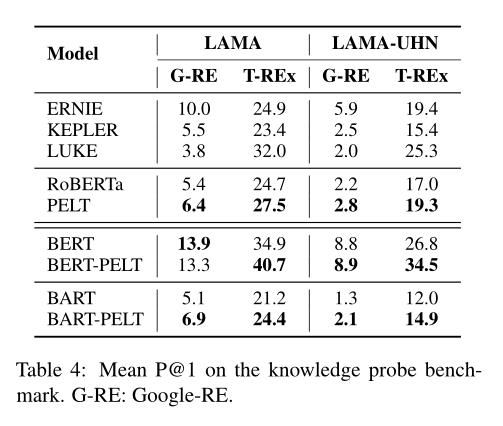
以及对低频率实体性能的提升:
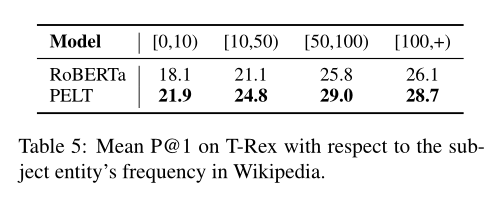
论文

动机
可控文本生成的任务是引导文本向着期望属性生成。属性之间往往存在相互关系,例如,对情感这个主题可以设定两个对立的属性:积极和消极,作者认为这种相反的关系有助于提高前缀的可控性,训练时将某个主题的所有属性一起训练,但每个属性都各自训练一个前缀,且前缀互相独立。
模型
本文的方法是使用前缀来引导GPT-2的文本生成,其中前缀是一个属性特定的连续向量,位于GPT-2激活层之前。某个主题的前缀集合记为。与Li和Liang(2021)的每个属性前缀都独立训练不同,作者考虑了属性之间的关系,同时训练多个前缀。
的维数为,其中为前缀数量,在单主题控制中,等于属性的数量。为前缀向量的长度。,为GPT-2中激活层维度,其中为Transformer层数,为隐藏层大小,代表一个key向量和一个value向量。仿照Li和Liang(2021)的做法,作者通过一个大矩阵和有较小参数的对进行训练,式子为。训练结束后,只需要保留,和可以丢弃。由于GPT-2参数在训练时被固定,因此也不需要保存。
下图显示了一个在训练后的前缀控制下生成文本的示例。这些前缀可以以监督、半监督或无监督的方式进行训练。由于半监督方法是监督方法和无监督方法的结合,所以文章将介绍监督方法和无监督方法。为了清晰起见,文章在单主题控制设置下介绍这些方法。
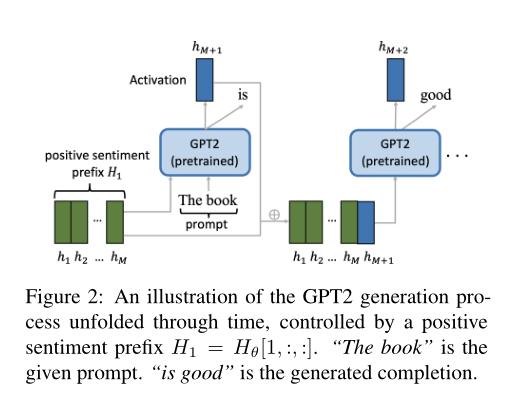
监督学习
假设相关主题有属性集,每个训练样本都是一对,其中是输入文本,,为的属性。注意属性同时表示中前缀的索引,因此在下面的描述中也表示前缀索引。
给定一个训练样本,对前缀进行优化以生成,而不鼓励其他前缀生成。为了实现这一目标,中的所有前缀都应该同时进行训练,且需要引入额外的损失函数。因此,总训练损失是语言模型损失与对比损失的加权和:
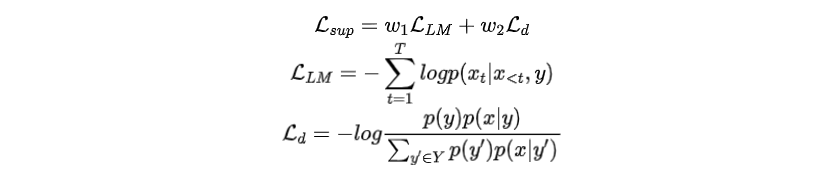
损失能够让生成的文本包含鼓励生成的信息,损失能够让生成的文本去除不鼓励产生的信息,代表着不同属性之间的“距离”。整个训练过程如下图所示。

无监督学习
在无监督学习中,假设相关主题的属性集是已知的。训练样本只包含输入文本。属性不再可用,因此与x关联的前缀的索引是未知的。因此,对应的前缀的索引是一个潜变量,其后验分布遵循分类分布。
文章采用上述监督学习中的主要模型作为解码器,并引入一个编码器来参数化分类分布,根据选择前缀索引,然后将前缀输入解码器。由于前缀的选择过程不可微,作者使用Gumbel-Softmax松弛,计算如下:
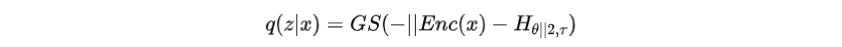
其中是Gumbel-Softmax的温度,是编码器函数。
为了训练前缀,总损失函数是三个损失项的加权和:
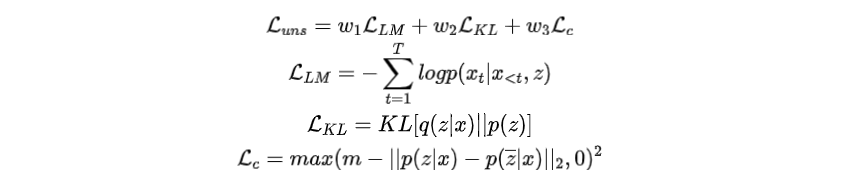
其中为语言模型损失。是KL散度,这里作者假设先验是均匀分布。注意,这两项构成了VAE的损失函数,优化这两个损失项可以改善的证据下界。
为无监督对比损失,类似于监督学习中,但计算方式不同,因为真实属性不可用。其中为预先设置的距离,是另一个表示相对前缀索引的潜在变量,计算方法如下
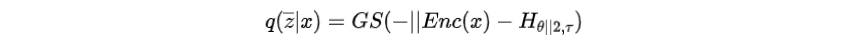
的目的是通过将从推开一段距离。的计算如下:
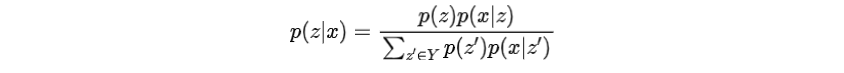
实验
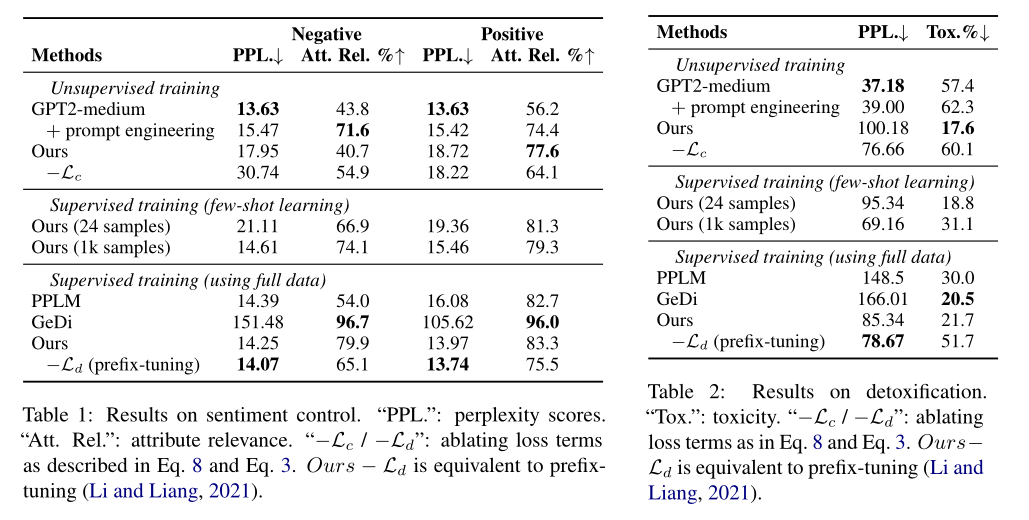
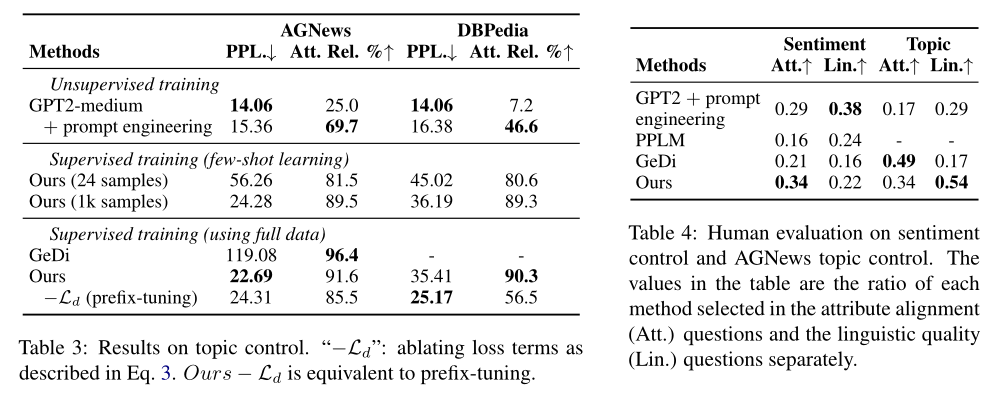
作者做了三个实验,分别是情感控制、去除有害文本、主题控制。结果说明了模型在引导生成文本具有某种属性的能力上有提升
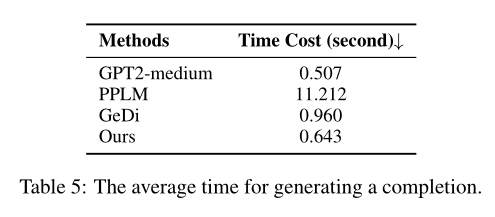
论文

动机
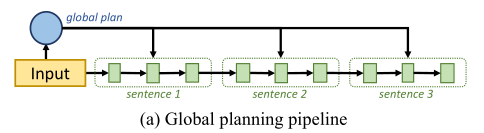
尽管预训练语言模型在生成流畅文本方面取得了进展,但现有的方法在长文本生成任务中仍然存在逻辑不连贯的问题,这些任务需要适当的内容规划,以形成连贯的高级逻辑流。现有的方法大致分为两类,一类是全局规划,利用潜在变量作为全局规划来指导生成过程,但是没有考虑细粒度的句子级规划。
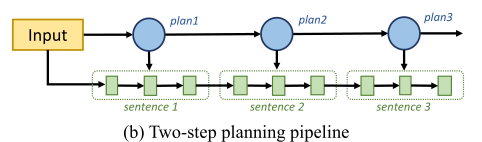
另一类是两阶段规划,首先生成句子级的内容规划,然后将内容规划传递给表层实现模块生成文本,但是内容规划和表层实现模块是脱节的,无法反向传播,会导致错误累积。
因此文章提出了一个新的生成框架PLANET,利用自回归的自我注意力机制来动态地进行内容规划和表层实现。
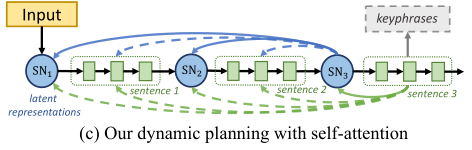
模型
任务描述
输入:
(1)一个语句,该语句可以是论点生成的主题,也可以是文章生成的标题,
(2)与该语句相关的一组无序的关键短语,作为话题的引导信号,对长文本生成任务进行建模。
输出:
一个由多个句子组成的文本,以连贯的逻辑恰当地反映了主题和关键短语。
训练目标:
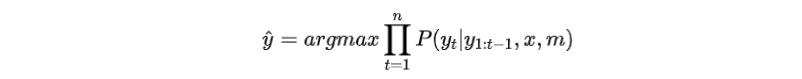
整体框架如图
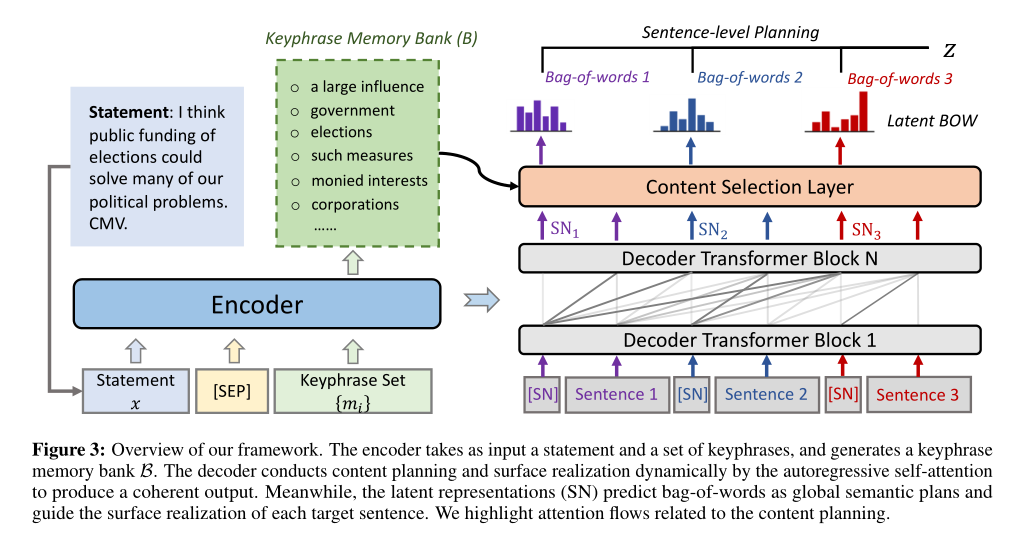
潜在表征学习
为每个目标句子引入一个潜在表征,来表示整个语义信息,并指导词的生成。
步骤一:在每个目标句子前插入一个标记,并将解码器在对应位置的隐藏层作为目标句子的潜在表征。
步骤二:当产生第j个输出句子时,潜在表征首先通过前面的潜在表征和前面句子计算得到。
步骤三:在句子表层实现时,之前生成的句子和潜在表征都参与到当前句子的计算中,且以当前潜在表征为指导。
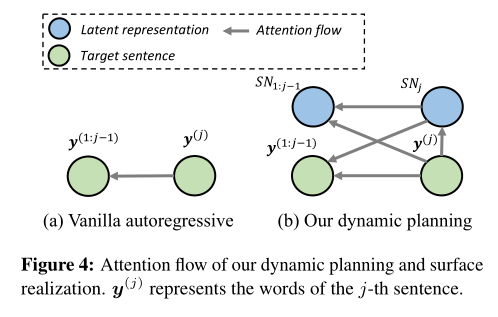
内容选择
关键词潜在表征
先将关键词用分隔符拼接,输入编码器以获得潜在表征,再收集这些潜在表征,构建关键词存储库
内容选择层
内容选择层从关键词存储库B中检索关键词信息,并将所选信息集成到解码过程中。
步骤一:在解码时间步,Transformer解码器的顶层表示通过多头注意力连接到关键词存储库,获得加入所选关键词信息的上下文向量
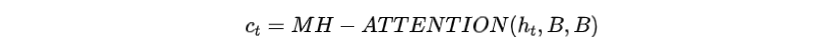
步骤二:通过前馈层和残差连接(RC)将关键词上下文向量合并到解码器的隐藏层中
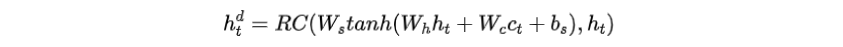
步骤三:通过softmax将增强后的隐藏层传递到另一个前馈层,估计每个输出词的概率
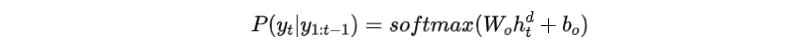
句子级词袋规划
该部分的目的是监督潜在表征SN的学习过程。目的是通过目标句子的词袋来反映全局语义规划,从而为潜在表征的意义奠定基础。
将第j个目标句子的词袋定义为整个词汇上的分类分布。其中,为多层前馈网络。我们期望该分布能够捕捉到对应句子的整体语义规划。
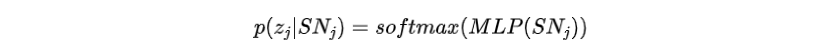
损失函数:最大化预测每个目标句子词袋的可能性。
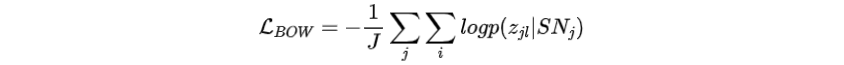
基于一致性的对比学习
该部分的目的是加强内容规划,并驱动模型学习更加连贯的输出。于是进一步设计了一个对比学习(CL)的训练任务。
负样本构造
将原始目标句子视为代表逻辑连贯输出的正样本,并构造不连贯的负样本。
对于一个正样本,根据以下策略创建4个负样本:
•SHUFFLE:随机打乱目标句子
•REPLACE:将50%的原始目标句子随机替换为语料库中的随机句子
•DIFFERENT:将所有原始目标句子全部替换为语料库中的随机句子
•MASK:从关键词集合中随机掩盖与关键词相关的20%的非停词,并采用BART填充掩盖的位置
损失函数
模型将内容选择层的输出表征映射到0到1之间的一致性得分,并且强制原始目标句子的得分比所有对应的负样本都大,即设定一个固定的边界
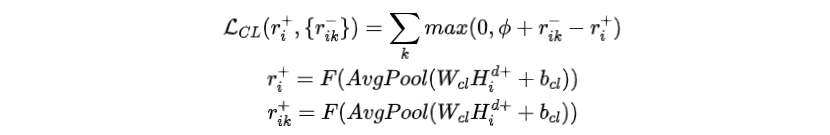
其中,是sigmoid变换,和是正样本和负样本在内容选择层的输出表征,是平均池化层
训练目标函数
损失函数联合优化了内容规划和表层实现模型,结合了以下目标函数:
•句子级词袋规划损失函数()
•交叉熵损失函数()
•对比学习损失函数()
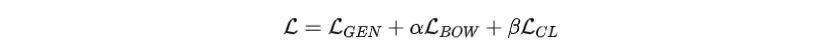
其中α和β被为超参数。
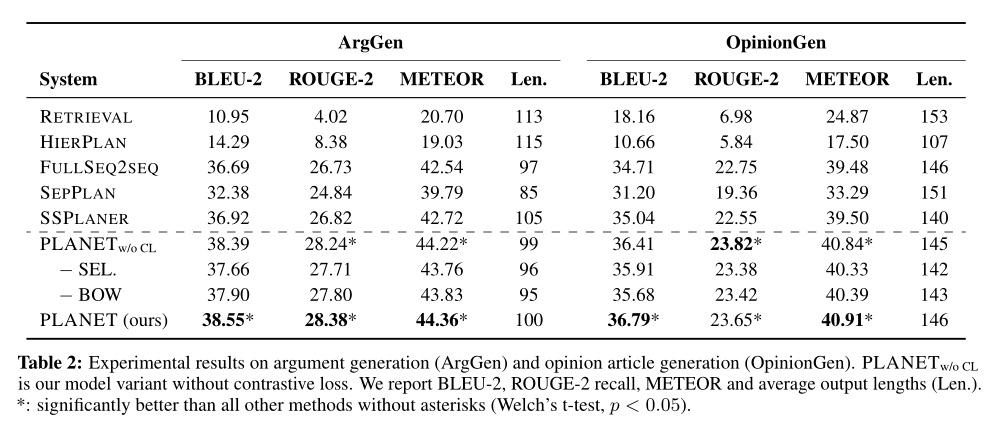
实验
在论点生成和观点文章生成任务上进行了实验。实验结果证明了方法在两种任务上都有提升。
审核编辑 :李倩
-
人工智能
+关注
关注
1819文章
50290浏览量
266826 -
PLM
+关注
关注
2文章
150浏览量
22193 -
文本
+关注
关注
0文章
120浏览量
17911
原文标题:ACL2022 | 文本生成的相关前沿进展
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
工作流大模型节点说明
详解DBC的Signal与JSON文本结合

泰克MP5000系列的TSP Toolkit I-V脚本生成功能
万里红文本生成算法通过国家网信办备案
小红书:通过商品标签API自动生成内容标签,优化社区推荐算法

AI生成的测试用例真的靠谱吗?

求助,关于STM32Cubemx 6.15版本生成工程的文件编码的问题求解
速看!EASY-EAI教你离线部署Deepseek R1大模型

Copilot操作指南(一):使用图片生成原理图符号、PCB封装
飞书开源“RTV”富文本组件 重塑鸿蒙应用富文本渲染体验
基于Arm架构的新款联想Chromebook Plus设备亮相
关于鸿蒙App上架中“AI文本生成模块的资质证明文件”的情况说明
边缘生成式AI面临哪些工程挑战?




评论