 英伟达Orin算法库主要三类算法
英伟达Orin算法库主要三类算法
做自动驾驶芯片必须软硬一体,最多的工作不是芯片本身,而是与之对应的算法库。对于自动驾驶,英伟达提供两种合作模式。
图片来源:互联网
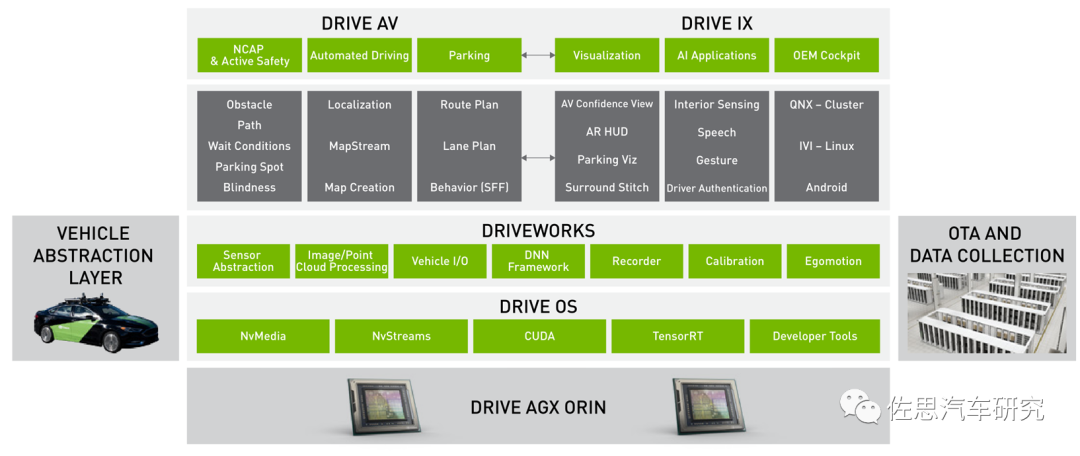
一种是车企交出全部灵魂,英伟达提供全套解决方案,包括底层OS,中间件DRIVEWORKS,上层应用模块DRIVE AV包括座舱的模块DRIVE IX也一起提供。不过中国禁止国外厂家上路采集信息,也就是用于识别的训练数据集还是需要中国厂家自己去做。如果是在美国,训练数据集英伟达也可以提供。
另一种是车企交出部分灵魂,英伟达提供底层的基础算法,这些算法大多基于手工模型,和深度学习没关联。实际深度学习或者说AI是自动驾驶领域最容易做的部分,搜集数据,标注数据,训练数据,提取权重模型。这也是为什么AI不具备可解释性,无法迭代,好在AI可溯源。工作量最大,难度最高的都是非深度学习部分。手工模型,传统算法的好处是可解释,可迭代,具备确定性。
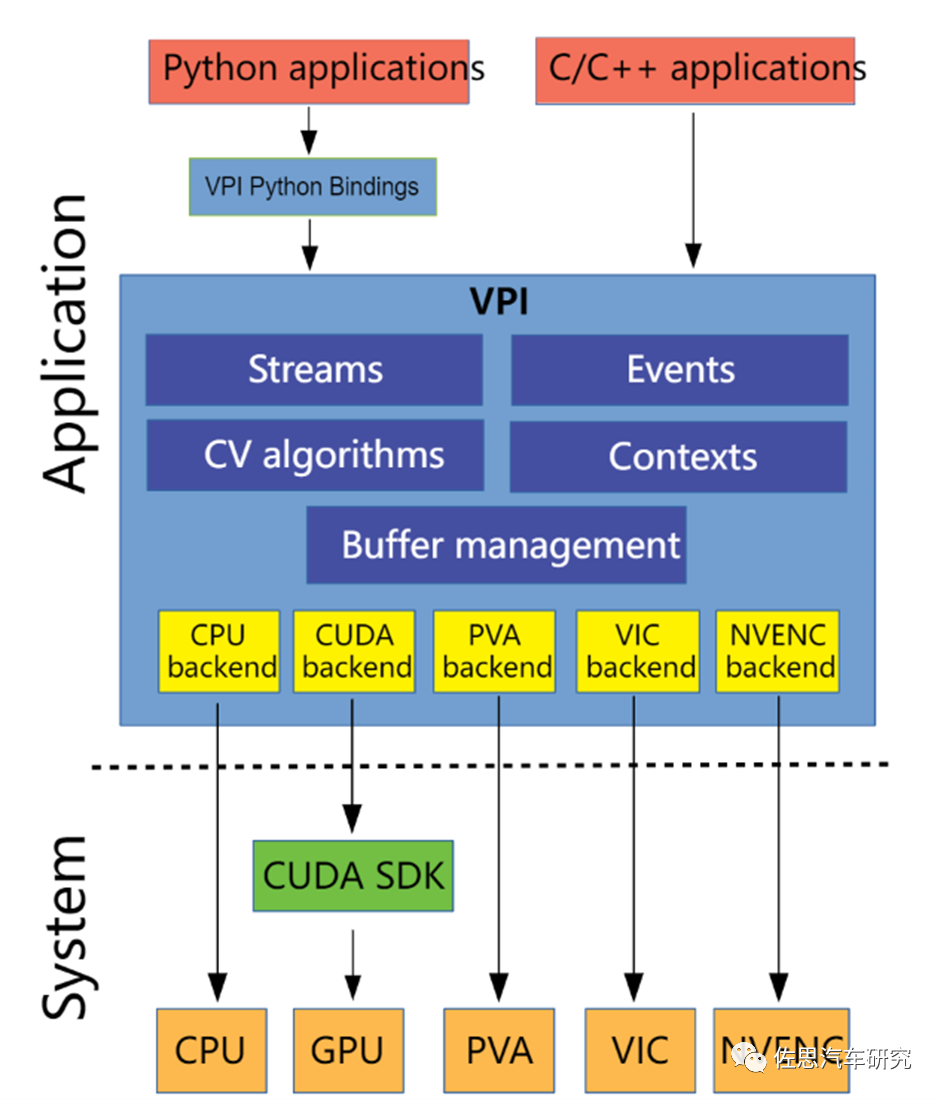
后一种的算法库,英伟达称之为VPI,即Vision Programming Interface,2021年2月发布,目前是2.0版本,VPI除了针对智能驾驶,也能用在任何计算机视觉领域,英伟达Jeston系列硬件平台都支持VPI。VPI提供一系列软件库,可在英伟达的硬件平台上得到加速,通常加速器还叫Backend后端。VPI用来取代NVIDIAVisionWorks。VPI可以最大化利用硬件,特别是Xavier和Orin的PVA、VIC、OFA。简单地说VPI将一些简单的算法封装成了类似硬件指令集的指令,对用户几乎透明,可直接调用,让原本需要N行代码才能完成的算法函数,只需一行指令就完成,让不熟悉基础算法的人也能胜任。大大缩减了开发周期和开发人员,效率显著提升。缺点是被英伟达深度捆绑,想换个平台绝无可能。
图片来源:互联网
PVA(Programmable Vision Accelerator),可编程视觉加速器;
VIC(Video Image Compositor),做一些固定功能的图像处理,如缩放、色彩转换、消噪;
NVENC(NVIDIA Encoder Engine),主要做视觉编码,也能做稠密光流应用。
整个VPI的执行概念,就是提供适合实时图像处理应用的异步计算管道,由一个或多个异步计算流(streams)组成,这些流在可用计算后端(backends)的缓冲区(buffers)上运行算法(algorithms),流之间使用事件(events)进行同步。VPI将数据封装到需要使用的每个算法的缓冲区中,提供Images(二维图像)、Arrays(一维数组)和Pyramids(二维图像金字塔)的三种抽象,以及用户分配内存包装,由VPI直接分配和管理。
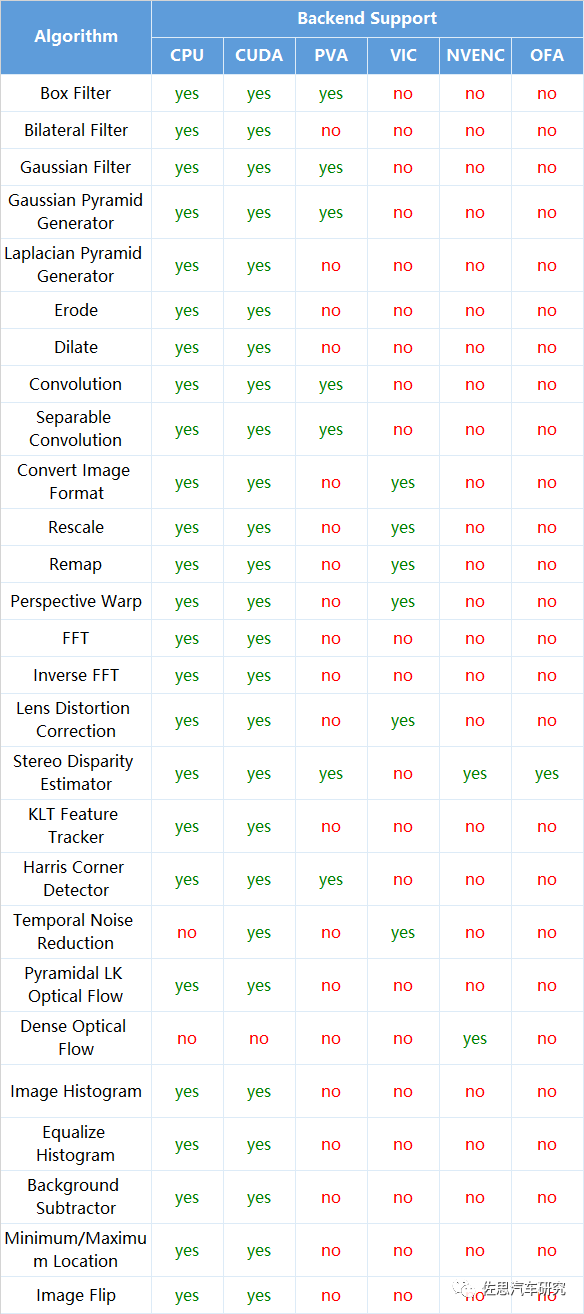
英伟达VPI 2.0算法对应硬件。
图片来源:互联网
算法库主要包含三类算法:
一是简单的图像前处理,包括各种平滑滤波、镜头畸变矫正、缩放、透视、拼接、直方图、消噪、快速傅里叶变换等;
二是针对立体双目视差的获得;
三是光流追踪。
OFA即光流加速器,为Orin平台独有,Xavier平台不支持。OFA只针对一个算法,就是立体双目视差估算。
英伟达VPI核心算法即图中这六大算法

图片来源:互联网
尽管只有奔驰和丰田用英伟达处理器处理立体双目,新型造车除了RIVIAN目前都不使用立体双目(小鹏小米可能在将来使用立体双目),但英伟达每一次硬件升级都不忘对立体双目部分特别关照。
英伟达立体双目处理流程
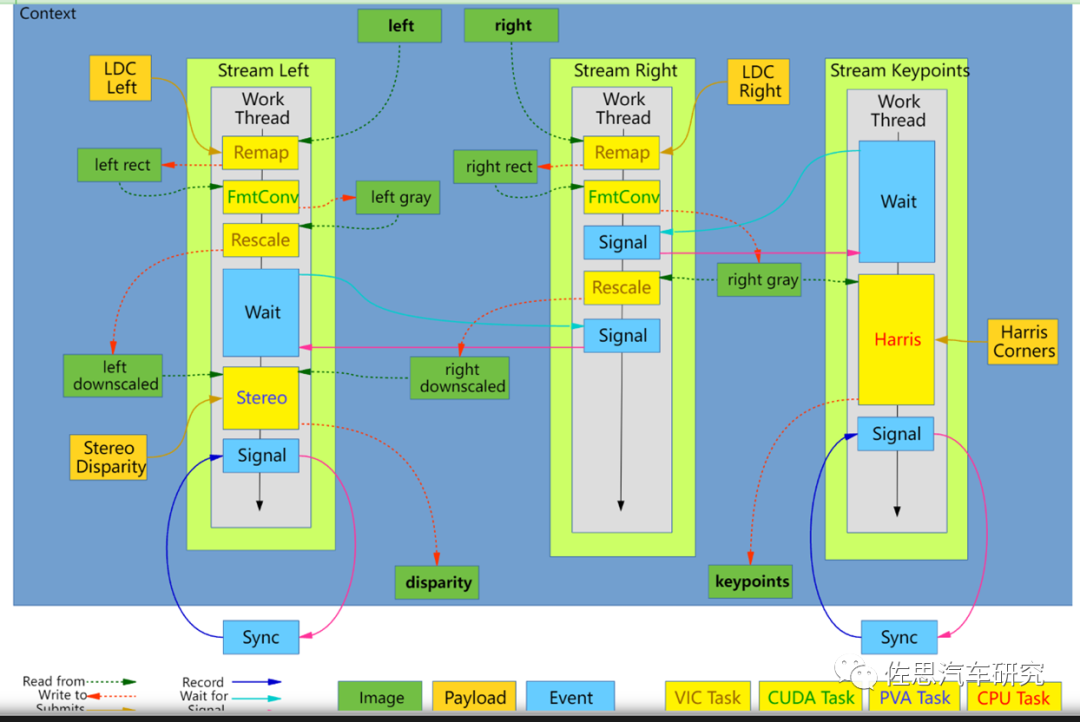
图片来源:互联网
立体双目视差的获得需要多种运算资源的参加,包括了VIC、GPU(CUDA)、CPU和PVA。
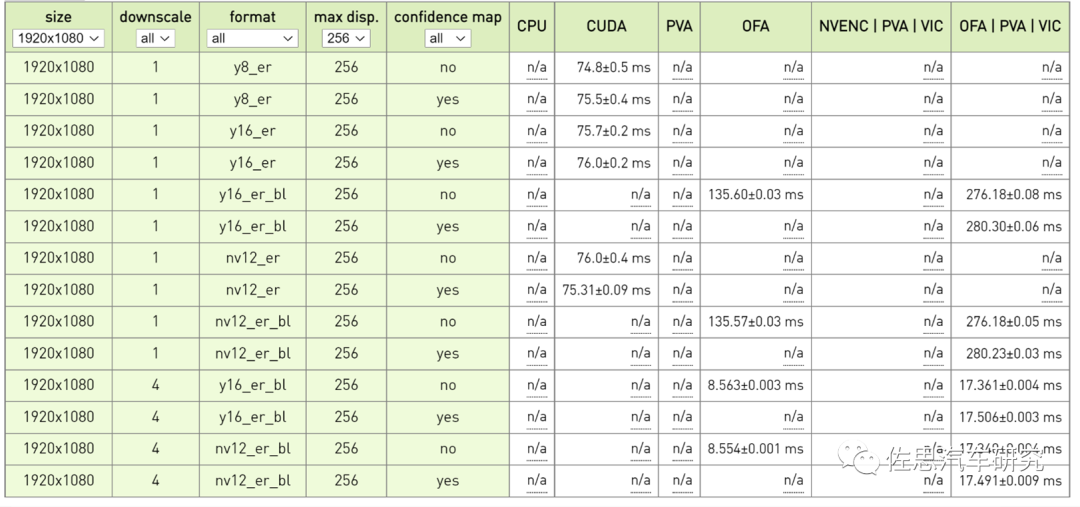
图片来源:互联网
英伟达Orin平台立体双目视差测试成绩,要达到每秒30帧,那么处理时间必须低于30毫秒,考虑到还有后端决策与控制系统的延迟,处理时间必须低于20毫秒。1个下取样情况下,显然都无法满足30帧的要求,4个下取样,不加置信度图时,单用OFA就可以满足。加置信图后,需要OFA/PVA/VIC联手,也能满足30帧需求。但这只是200万像素,300万像素估计就无法满足了。

图片来源:互联网
并且此时是火力全开,运行频率如下:
CPU: 12x ARMv8 Processor rev 1 (v8l) running at 2.2016 GHz
EMC freq.: 3.1990 GHz
GPU freq.: 1.3005 GHz
PVA/VPS freq.: 1.1520 GHz
PVA/AXI freq.: 832.8 MHz
VIC freq.: 729.6 GHz
Power mode: MAXN
Fan speed: MAX
这种火力全开情况下,恐怕不能持续太长时间。
光流Optical Flow追踪主要用于目标的行驶轨迹的预测。
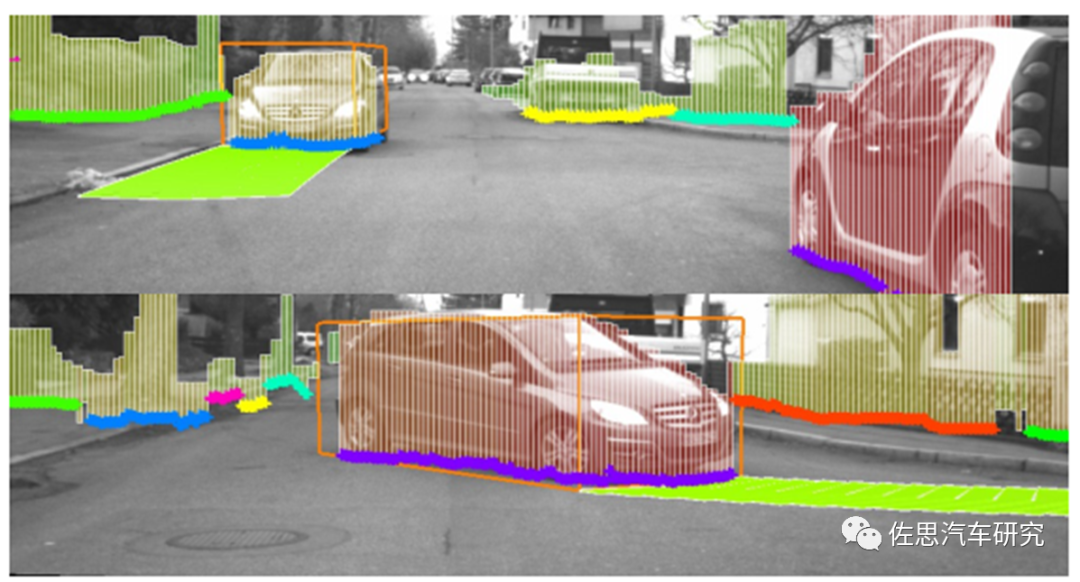
图片来源:互联网 上图就是奔驰用光流法预测车辆行驶轨迹。
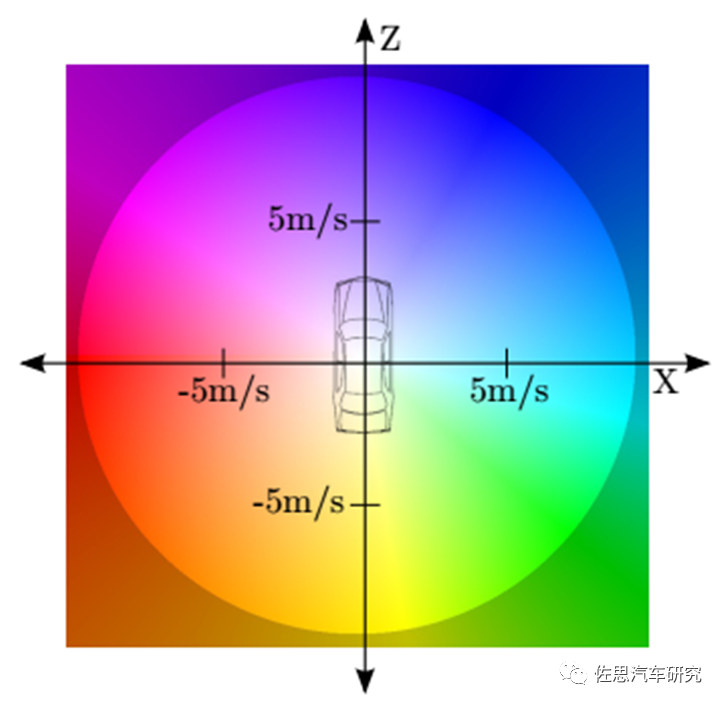
图片来源:互联网
上图是奔驰的颜色编码,不同的颜色代表车辆即将行驶的速度和方位角。
光流是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。研究光流场的目的就是为了从图片序列中近似得到不能直接得到的运动场,其本质是一个二维向量场,每个向量表示了场景中该点从前一帧到后一帧的位移。那对于光流的求解,即输入两张连续图像(图像像素),输出二维向量场的过程。除了智能驾驶,体育比赛中各种球类的轨迹预测,军事行动中的目标轨迹预测都能用到。光流场是运动场在二维图像平面上的投影。因为立体双目和激光雷达都是3D传感器,而单目或三目是2D传感器,所以单目或三目的光流非常难做。光流再分为稀疏和稠密(Dense)两种,稀疏光流对部分特征点进行光流解算,稠密光流则针对的是所有点的偏移。
最常见的光流算法即KLT特征追踪,源自1981年,早期的光流算法都是稀疏光流,手工模型或者说传统算法。2015年有人提出深度学习光流法,在CVPR2017上发表改进版本FlowNet2.0,成为当时最先进的方法。截至目前,FlowNet和FlowNet2.0依然是深度学习光流估计算法中引用率最高的论文。传统算法计算资源消耗少,实时性好,效果比较均衡,但鲁棒性不佳。深度学习消耗大量的运算资源,鲁棒性好,但容易出现极端,即某个场景非常差,但无法解释,与训练数据集关联程度高。即使强大的Orin也无法FlowNet2.0做到实时性,毕竟Orin不能只做光流这一件事。因此英伟达还是推荐KLT。产业领域光流法主流还是KLT。但学术领域已经是深度学习了。
硬件与算法互相推动,硬件算力的增强让人们敢于部署越来越大规模的深度学习模型,反过来,这又推动硬件算力的需求,特别是自动驾驶,传统可解释算法研究的人越来越少,因为投入产出比太低,深度学习正横扫一切,但深度学习不可解释,汽车领域需要的是可解释可预测可确定。否则无法迭代,无法划出安全边际线。这也是自动驾驶难以落地的主要原因。
审核编辑 :李倩
-
算法
+关注
关注
23文章
4615浏览量
93000 -
英伟达
+关注
关注
22文章
3780浏览量
91219 -
自动驾驶
+关注
关注
784文章
13839浏览量
166552
原文标题:英伟达Orin算法库都有什么算法?
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

Orin芯片的编程语言支持
Orin芯片的技术特点

使用lsm303agr传感器做一个电子罗盘,能否使用X-CUBE-MEMS1算法库?
英伟达Orin 的系统结构解析

mini57系列运行带算法库的程序,编译没有错误但无法运行是为什么?
理想、长城、极氪、小米宣布!合作英伟达!






 工商网监
工商网监
评论