 扩散模型和其在文本生成图像任务上的应用
扩散模型和其在文本生成图像任务上的应用
本文主要介绍扩散模型和其在文本生成图像任务上的应用,从扩散模型的理论知识开始,再到不同的指导技巧,最后介绍文本生成图像的应用,带读者初探扩散模型的究竟。如有遗漏或错误,欢迎大家指正。
引言:扩散模型是一类生成模型,通过迭代去噪过程将高斯噪声转换为已知数据分布的样本,生成的图片具有较好的多样性和写实性。文本生成图像是多模态的任务之一,目前该任务的很多工作也是基于扩散模型进行构建的,如GLIDE、DALL·E2、Imagen等,生成的图片让人惊叹。本文从介绍扩散模型的理论部分开始,主要介绍DDPM一文中涉及到的数学公式,然后介绍扩散模型中常用到的指导技巧,最后会介绍文本生成图像的一些应用。 1. 扩散模型
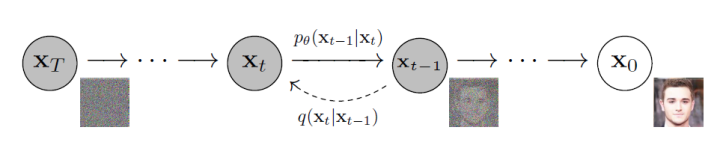
上图展示了扩散模型的两个过程。其中,从右到左(从到)表示正向过程或扩散过程,从左到右(从到)表示的是逆向过程。扩散过程逐步向原始图像添加高斯噪声,是一个固定的马尔科夫链过程,最后图像也被渐进变换为一个高斯噪声。而逆向过程则通过去噪一步步恢复原始图像,从而实现图像的生成。下面形式化介绍扩散过程、逆扩散过程和目标函数,主要参考DDPM[1]论文和What are Diffusion Models?[2]博客内容。1.1 扩散过程设原始图像,扩散过程进行步,每一步都向数据中添加方差为每一步都向数据中添加方差为,最终。所以,由马尔科夫链的无记忆性,可对扩散过程进行如下定义:
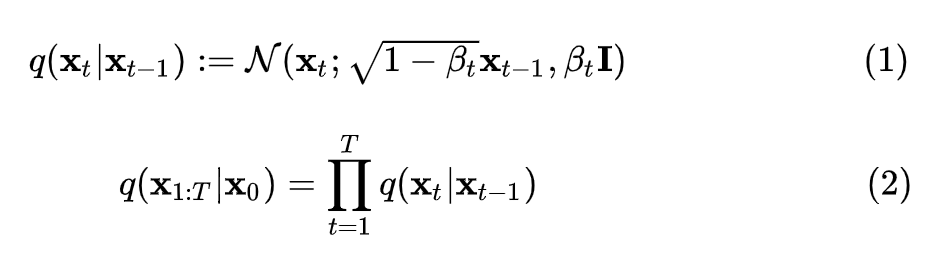
所以,扩散过程的均值和方差是已知的,其均值为,方差为。 扩散过程有一个显着特性,我们可以对任意 进行采样。为了证明该性质需要使用参数重整化技巧:假设要从高斯分布中采样时,可以先从采样出 ,然后计算 ,这样可以解决梯度无法回传问题。 所以首先将进行重参数化:设, 故: 设,: 其中 ,第三行到第四行进行了两个正态分布的相加。所以,重整化后 ,即 1.2 逆扩散过程 逆扩散过程是从给定的高斯噪声中恢复原始数据,也是一个马尔可夫链过程,但每个时刻 的均值和方差需要我们去学习,所以,我们可以构建生成模型 : 1.3 目标函数扩散模型使用负对数似然最小化的思想,采用近似的技术等价地要求负对数似然最小化。同时,由于KL散度具有非负性,因而将和的KL散度添加至负对数似然函数中,形成新的上界。 对于全部的训练数据,添加上式两边同乘 ,即:对上式进行化简:上式中第四行到第五行,利用了马尔可夫链的无记忆性和贝叶斯公式:第六行到第七行是第二个求和符号展开并化简的结果。 上述过程在DDPM论文中的附录部分也有展示。 观察可知,项的两个分布均已知,同时DDPM文中将项设置为一个特殊的高斯分布。故最后的目标只和有关。 同时,虽然无法直接给出,但当我们加入作为条件时,设 类似上面的处理,根据贝叶斯公式和马尔可夫性质,可知 然后由公式(1)(4)可知: 由于高斯分布的概率密度函数是: 将上面两个式子进行一一对应,可以得到均值: 所以,由高斯分布的KL散度计算式可知,可化为: 因此,我们可以直观地看到其目标含义是模型预测的均值要尽可能和接近。然后,由公式 可知,输入 不含参数,则在给定时,若 能够预测出,则也能够计算出均值,所以同样进行参数重整化,可得: 所以: DDPM论文中最终的简化目标为: 所以可以看出,从预测均值变为了直接预测噪声,加快了推理速度。 2. Guided Diffusion DDPM论文提出之后,扩散模型就可以生成质量比较高的图片,具有较强的多样性,但是在具体的指标数值上没有超过GAN。同时,在协助用户进行艺术创作和设计时,对生成的图像进行细粒度控制也是一个重要的考虑因素。所以之后尝试将一些具体的指导融入扩散模型中去。 2.1 Classifier Guidance 用于图像生成的GAN的相关工作大量使用了类标签,而我们也希望生成的图片更加写实,所以有必要探索在类标签上调整扩散模型。具体来说,Diffusion Models Beat GANs[3]一文中使用了额外的分类器,在前面我们描述的无条件的逆向过程的基础上,将类别作为条件进行生成,具体公式如下:
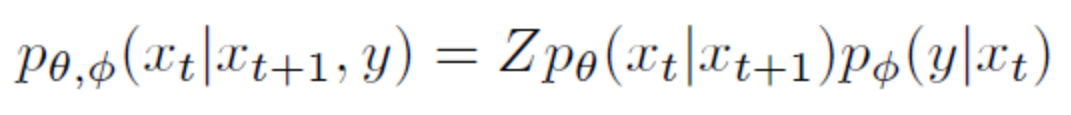
上式的含义是加入类别作为条件进行生成,可以看作无条件的生成和分类两者的结合。具体而言,用分类模型对生成的图片进行分类,得到预测与目标类别的交叉熵,从而使用梯度帮助模型的采样和生成。 实际中,分类器是在噪声数据上训练的。 采样过程的算法如下:

可以看到该过程中同时学习均值和方差,然后加入分类器的梯度引导采样过程。 2.2 Semantic Diffusion Guidance (SDG) 看到分类器指导的图像生成的有效性后,自然而然可以想到:是否可以将图像类别信息换为其他不同类型的指导呢?比如使用CLIP模型作为图像和文本之间的桥梁,实现文本指导的图像生成。 Semantic Diffusion Guidance(SDG)[4]是一个统一的文本引导和图像引导框架,通过使用引导函数来注入语义输入,以指导无条件扩散模型的采样过程,这使得扩散模型中的生成更加可控,并为语言和图像引导提供了统一的公式。
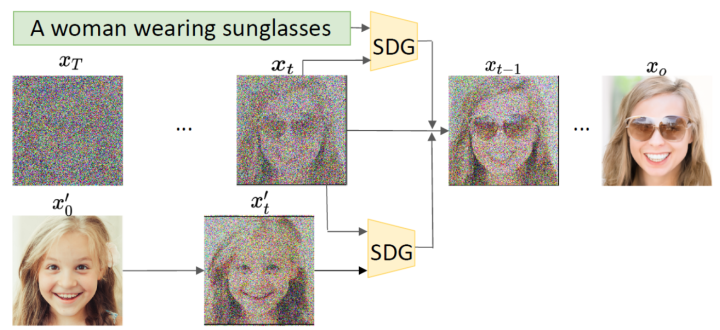

从采样过程可以看出,不同的引导其实就是中的不同,可以是文本、图像,也可以是两者的结合。 2.3 Classifier-Free Guidance 以上方法都是使用了额外的模型,成本比较高,而且须在噪声数据上进行训练,无法使用预训练好的分类器。Classifier-Free Guidance[5]一文提出在没有分类器的情况下,纯生成模型可以进行引导:共同训练有条件和无条件扩散模型,并发现将两者进行组合,可以得到样本质量和多样性之间的权衡。 原来分类器指导的式子如下,表示条件,和含义类似:
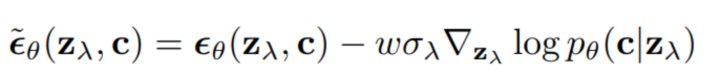
Classifier-Free Guidance方法将模型的输入分为两种,一种是无条件的 ,另一种是有条件的,使用一个神经网络来参数化两个模型,对于无条件模型,我们可以在预测分数时简单地为类标识符设为零,即。我们联合训练无条件和条件模型,只需将随机设置为无条件类标识符即可。然后,使用以下有条件和无条件分数估计的线性组合进行抽样:
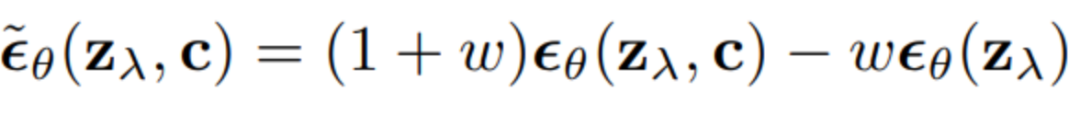
3. 应用
3.1 GLIDE OpenAI的GLIDE[6]将扩散模型和Classifier-Free Guidance进行结合去生成图像。同时文中比较了两种不同的引导策略:CLIP Guidance和Classifier-Free Guidance,然后发现Classifier-Free Guidance在照片写实等方面更受人类评估者的青睐,并且通常会产生很逼真的样本,并能实现图像编辑。其中,Classifier-Free Guidance中的条件是文本。

下表是GLIDE在MS-COCO上的实验结果。
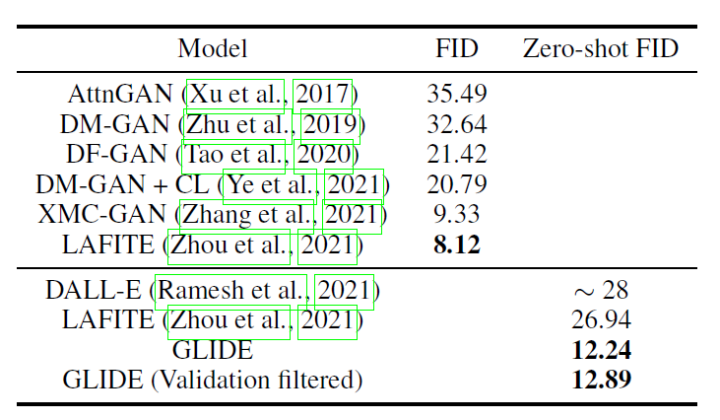
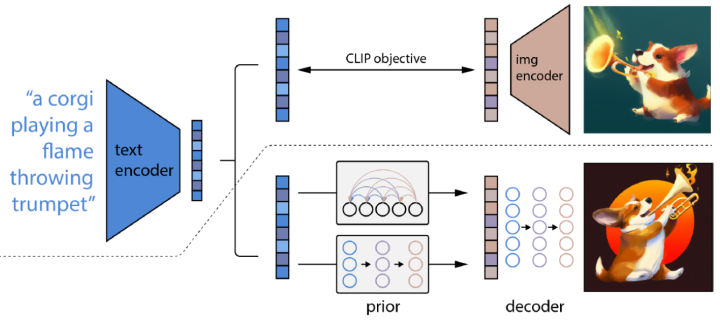
除了零样本生成之外,GLIDE还具有编辑功能,允许迭代地改进模型样本。 3.2 DALL·E 2 DALL·E2[7]利用CLIP来生成图像,提出了一个两阶段模型:一个先验prior网络用于生成一个给定文本下的 CLIP 图像嵌入,一个解码器decoder在给定图像编码的情况下生成图像。DALL·E2对解码器使用扩散模型,并对先验网络使用自回归模型和扩散模型进行实验,发现后者在计算上更高效,并产生更高质量的样本。 具体来说:
prior :在给定文本条件下生成CLIP图像的编码,并且文中探索了两种实现方式:自回归和扩散,均使用classifier-free guidance,并且发现扩散模型的效果更好:
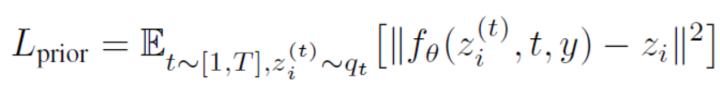
注意此处目标和前面有所不同,prior直接去预测图像特征,而不是预测噪声
decoder:在图像编码(和可选的文本标题)条件下生成图像;使用扩散模型并利用classifier-free guidance和CLIP guidance在给定CLIP图像编码的情况下生成图像。为了生成高分辨率图像,训练了两个扩散上采样模型,分别用于将图像从64*64上采样到256*256、进一步上采样到1024*1024。
将这两个部分叠加起来会得到一个生成模型可以在给定标题下生成图像:。第一个等号是由于和是一对一的关系。
所以DALL·E2可以先用prior采样出,然后用decoder得到;
DALL·E2能够生成高分辨率、风格多样的图片,并且能够给定一张图,生成许多风格类似的图片;可以进行两张图片的插值,实现风格的融合等,在具体数值上也超越了GLIDE。
3.3 Imagen 下图是谷歌提出的Imagen[8]的模型架构:
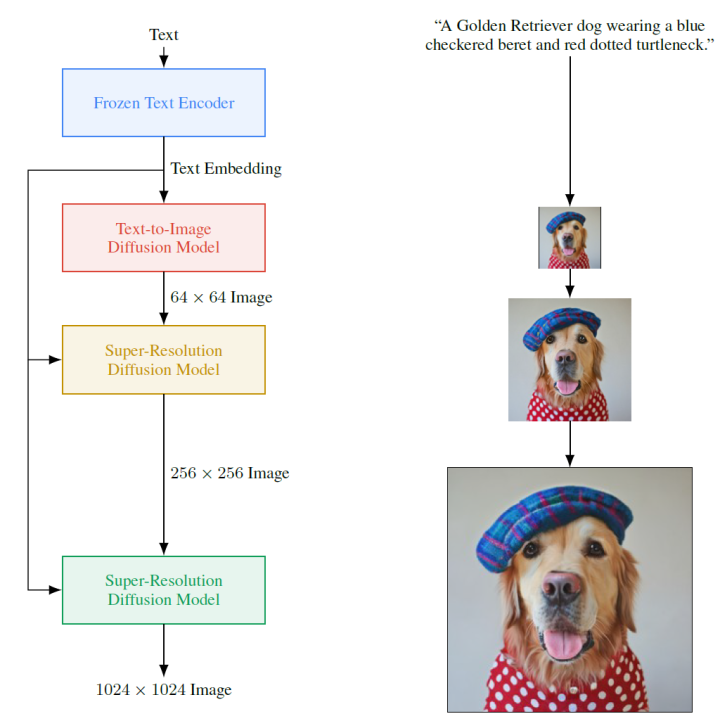
Imagen由一个文本编码器和一连串条件扩散模型组成。
预训练文本编码器:语言模型是在文本语料库上训练的,该语料库比配对的图像-文本数据要大得多,因此可以接触到非常丰富和广泛的文本分布。文中使用Frozen Text Encoder进行文本的编码
扩散模型和classifier-free guidance:使用前面提到的classifier-free guidance,将文本编码作为条件,进行图像的生成。同样,后面也有两个扩散模型进行分辨率的提升,最终可以生成1024*1024分辨率的图像。文本到图像扩散模型使用改进的U-Net 架构,生成64*64 图像,后面两个扩散模型使用本文提出Efficient U-Net,可以更节省内存和时间。
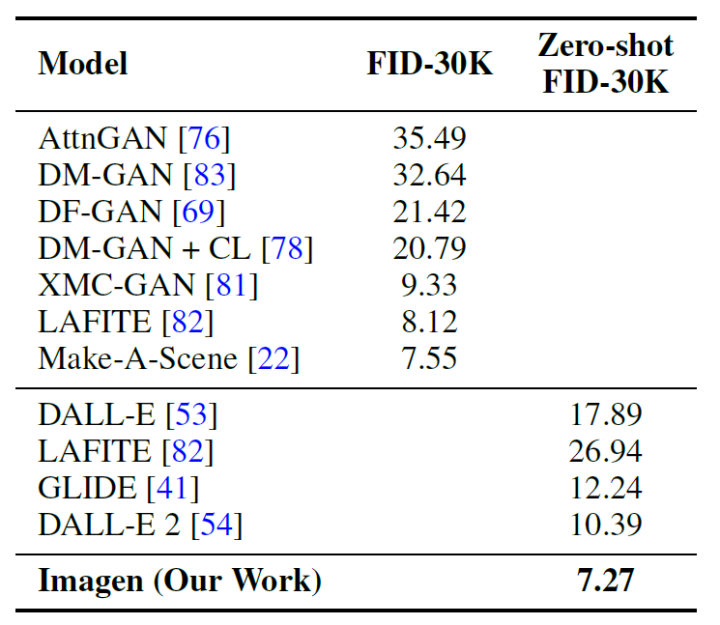
我们使用FID分数在COCO验证集上评估Imagen,下表展示了结果。Imagen在COCO上实现了最好的zero-shot效果,其FID为7.27,优于前面的一系列工作。

审核编辑 :李倩
-
图像
+关注
关注
2文章
1091浏览量
40641 -
模型
+关注
关注
1文章
3400浏览量
49422 -
扩散模型
+关注
关注
0文章
5浏览量
5586
原文标题:文本生成 | 扩散模型与其在文本生成图像领域的应用
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
DeepSeek大模型如何推动“AI+物流”融合创新
了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择
【「基于大模型的RAG应用开发与优化」阅读体验】+Embedding技术解读
#新年新气象,大家新年快乐!#AIGC入门及鸿蒙入门
借助谷歌Gemini和Imagen模型生成高质量图像

如何使用 Llama 3 进行文本生成
AI大模型在自然语言处理中的应用
【《大语言模型应用指南》阅读体验】+ 基础知识学习
Transformer语言模型简介与实现过程
llm模型和chatGPT的区别
【大语言模型:原理与工程实践】揭开大语言模型的面纱
OpenVINO™协同Semantic Kernel:优化大模型应用性能新路径





 工商网监
工商网监
评论