 简单讲讲RISC-V指令集CPU的参数
简单讲讲RISC-V指令集CPU的参数
第二代CPU新鲜出炉。
下面简单讲讲该CPU的参数。
CPU芯片封装全貌
本次CPU采用32位RISC-V指令集架构(一代是自己瞎编指令集)。指令集就是程序指令的集合,指引硬件如何设计、如何运行。不同指令集的CPU运行的程序是不同的,相同的指令集的CPU则基本可以兼容为此指令集编写的程序。目前主流的指令集有电脑中的x86和手机中的ARM。RISC-V作为一种新兴的指令集架构,它汲取了之前的指令集的架构的优缺点,有着先天的优势。此外,它不同于老牌指令集架构,没有需要为前代软件兼容的困扰,可以说是无病一身轻,整个架构轻盈简单却又高效。
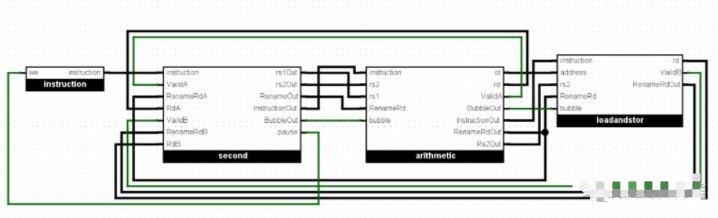
第二级流水线
采用6级流水线设计(一代是单周期设计,可以理解成一级流水线)。流水线设计是CPU设计的一大难点,开始设计之初我曾考虑是否真的要直接上5级经典流水线(一位学长曾劝我再改进一次单周期CPU),最后竟然还多设计出了1级流水线。我先解释一下流水线是什么。CPU中有很多部件(这些部件不一定有很清楚的边界并且不一定是处于一个集中的位置),例如译码器(将指令翻译成控制信号)、寄存器组(存放数据),ALU(计算单元)和存储控制单元(控制读取和写入数据)等等。单周期CPU执行一条指令需要一个周期,在这整个周期中执行指令需要分别用到上面所说的所有部件,用是都要用,但是在本周期的一个时间段中至多只能用到一个单元,那么这段时间中总有别的单元被闲置了,而这些单元是线性排布的,在用寄存器组之前必须先经过译码器解码,经过ALU之前必须从寄存器组中读取数据……比如说:一个时钟周期是1s。译码占0.2s,从寄存器中读数占0.2s,计算占0.4s,写回数据占0.2s,加起来一共是1s。
如果我们每周期只用一个单元,让多个指令依次使用这些单元,那么就可以极大提高CPU的执行速度,这就是流水线技术。那么时钟周期就缩短至0.4s(与耗时最长的那一步时间齐平),其中译码占0.2s,从寄存器中读数占0.2s,计算占0.4s,写回数据占0.2s。我们发现时钟周期可以变短了,也就是频率变高了,处理速度变快了。
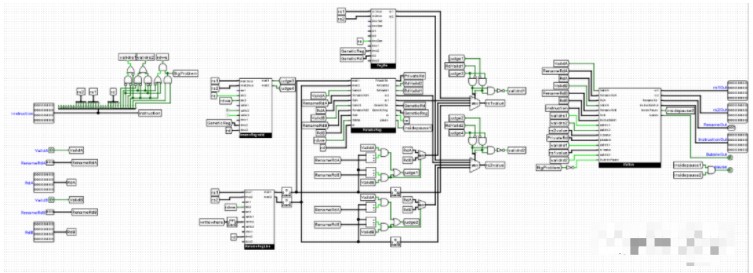
其实听起来也没那么难嘛?考虑一下这个问题。假设第一条指令是把A寄存器中的数值和B寄存器的数值加起来放到C的寄存器里,第二条指令是把B寄存器的数值和C的寄存器的数值加起来放到A的寄存器中。那么第二个指令开始执行到ALU(计算单元)的前端的时候就会发现第二条指令要用的C的数值呢?哦,前一条指令还没算出C的数值,那怎么办?那第二条指令还不能执行。什么时候能执行?第一条指令算好的时候。第一条指令什么时候算好?不知道……反正一堆麻烦。而且大多数真实情况是前面有十几条指令要用C的数值,并且指令可能各不相同,有的是做做加法,有的可能是做做除法(异常耗时),有的甚至拿C寄存器的数值作为地址访问内存。你们可以想想这个问题要怎么解决。
多端口写入读取寄存器组
第二条指令要等第一条指令。这种情况又被叫作冲突(hazard),冲突又被分为寄存器冲突和结构冲突(好像是这两个词,意思领会到就行),这种属于寄存器冲突。刚才说到,第二条指令不能等第一条指令,那么我们需要一种特殊的信号控制无指令的单元,这种信号叫作空泡(bubble)。那么回过来想,虽然用了流水线,但是因为各种冲突,指令可能也不能好好执行几个。相反,可能由于这复杂的控制电路和更高的电路运行频率,功耗变高了,芯片面积变大了,好像适得其反。那么我们就要讲到第二代CPU的第二个亮点。
乱序执行。什么第二个指令不能执行?那第三个能吗?第三个可以!那就先执行第三个。这就是乱序执行的全部逻辑。看起来也很简单,但做起来确实不太容易。当时设计之初也在考虑是否要实现乱序执行,因为流水线的难度已经很大了,乱序执行再加下去难度简直要爆炸,但是我转念一想,如果流水线没有乱序执行,就像高楼没有电梯(原谅我贫穷的比喻),发挥不出任何优势。最后还是硬着头皮上了,竟然也成了……
CPU保留站(解决冲突的,乱序执行的重要位置)
除了上述所讲的亮点之外,还有一些先进之处。例如寄存器重命名、保留站、FIFO队列等等。之后会再细讲。
审核编辑:刘清
-
ARM
+关注
关注
134文章
9091浏览量
367474 -
寄存器
+关注
关注
31文章
5342浏览量
120297 -
cpu
+关注
关注
68文章
10859浏览量
211687 -
RISC-V
+关注
关注
45文章
2275浏览量
46143
发布评论请先 登录
相关推荐
什么是RISC-V?以及RISC-V和ARM、X86的区别
RISC-V的指令集位宽的几点学习心得
RISC-V和arm指令集的对比分析
RISC-V指令集的特点总结
CISC(复杂指令集)与RISC(精简指令集)的区别
RISC-V基础整数指令集
什么是RISC-V?RISC-V指令集的优势






 工商网监
工商网监
评论