 基于OnePose的无CAD模型的物体姿态估计
基于OnePose的无CAD模型的物体姿态估计
作者:Jiaming Sun,Zihao Wang,Siyu Zhang,Xingyi He, Hongcheng Zhao,Guofeng Zhang, Xiaowei Zhou
摘要
我们提出了一种名为OnePose的物体姿态估计的新方法。与现有的实例级或类别级方法不同,OnePose不依赖于CAD模型,可以处理任意类别的物体,而不需要进行针对实例或类别的网络训练。OnePose借鉴了视觉定位的思路,只需要对物体进行简单的RGB视频扫描,就可以建立一个物体的稀疏SfM模型。然后,这个模型被注册到具有通用特征匹配网络的新查询图像上。为了缓解现有视觉定位方法的缓慢运行时间,我们提出了一个新的图注意网络,该网络直接将查询图像中的二维兴趣点与SfM模型中的三维点进行匹配,从而实现高效和稳健的姿势估计。结合基于特征的姿势跟踪器,OnePose能够稳定地检测并实时跟踪日常家用物品的6D姿势。我们还收集了一个大规模的数据集,其中包括150个物体的450个序列。
一、介绍
物体姿势估计在增强现实(AR)中发挥着重要作用。AR中物体姿态估计的最终目标是将任意物体作为AR效果的 “虚拟锚”,这就要求我们有能力估计日常生活中周围物体的姿态。大多数既定的物体姿势估计工作假定物体的CAD模型是先验的。由于高质量的日常物体的CAD模型往往是不可获取的,因此对AR场景下的物体姿态估计的研究需要新的问题设置。
为了不依赖实例级的CAD模型,最近许多方法都在研究类别级的姿态估计。通过在同一类别的不同实例上训练网络,网络可以学习物体外观和形状的类别级表征,从而能够归纳到同一类别的新实例。然而,这种方法需要大量的同一类别的训练样本,而这些样本可能很难获得和注释。此外,当新的实例具有明显不同的外观或形状时,类别级方法的泛化能力也得不到保证。更重要的是,在许多现实世界的应用中,例如移动AR,当需要处理的物体类别数量巨大时,为每个类别训练和部署一个网络是负担不起的。
为了减轻对CAD模型或特定类别训练的需求,我们回到了物体姿势估计的 “旧 ”问题,但用一种新的基于学习的方法翻新了整个管道。类似于视觉定位的任务,即在给定场景的SfM地图的情况下估计未知的相机姿势,物体姿势估计长期以来一直是在基于定位的环境下制定的。与实例或类别级别的方法不同,这种设置假定给定了物体的视频序列,并且可以从该序列中重建稀疏点云模型。然后,估计物体的姿势等同于相对于重建的点云模型定位摄像机的姿势。在测试时,从查询图像中提取二维局部特征,并与SfM模型中的点相匹配,以获得二维到三维的对应关系,由此可以通过PnP解决物体的姿势问题。与通过神经网络学习实例或特定类别的表征不同,这个传统的管道利用了一个明确的物体三维模型,该模型可以针对新的实例即时建立,这为任意物体带来了更好的泛化能力,同时使系统更容易解释。
在本文中,我们将这一问题设置称为one-shot物体姿势估计,其目标是能够估计任意类别的物体的6D姿势,只需给定一些物体的姿势注释图像进行训练。虽然这个问题与视觉定位类似,但直接移植现有的视觉定位方法并不能解决这个问题。现代视觉定位pipeline通过首先在查询图像和检索到的数据库图像之间进行二维二维匹配来产生二维三维对应关系。为了确保定位的高成功率,与多个图像检索候选者的匹配是必要的,因此,2D-2D匹配可能很昂贵,特别是对于基于学习的匹配器。因此,现有的视觉定位方法的运行时间往往是几秒钟,不能满足实时跟踪移动物体的要求。
基于上述原因,我们建议直接在查询图像和SfM点云之间进行2D-3D匹配。我们的关键想法是使用图注意网络(GATs)来聚合对应于同一三维SfM点(即一个特征轨迹)的二维特征,形成一个三维特征。聚合后的三维特征随后与查询图像中的二维特征进行自我和交叉注意层的匹配。与自我注意和交叉注意层一起,GATs可以捕捉到地面真实的2D-3D对应关系中所表现出的全局考虑和上下文相关的匹配先验,使匹配更加准确和稳健。
为了评估所提出的方法,我们收集了一个大规模的数据集,用于one-shot姿势估计设置,其中包含150个物体的450个序列。与之前的实例级方法PVNet和类别级方法Objectron相比,OnePose无需对验证集中的任何物体实例或类别进行训练就能达到更好的精度,而在GPU上处理一帧只需要58毫秒。据我们所知,当与基于特征的姿势跟踪器相结合时,OnePose是第一个基于学习的方法,可以稳定地实时检测和跟踪日常家用物品的姿势(参考项目页面)。
贡献:
革新物体姿势估计的视觉定位管道,无需CAD模型或额外的网络训练即可处理新的物体。
用于稳健的2D-3D特征匹配的图注意网络的新结构。
一个大规模的物体数据集,用于带有姿态注释的一次性物体姿态估计。
二、相关工作
基于CAD模型的物体姿态估计:目前最先进的物体6DoF姿态估计方法可以大致分为回归和关键点技术。第一类方法直接将姿势参数与每个感兴趣区域(RoI)的特征进行回归。相反,后一类方法首先通过回归或投票找到图像像素和三维物体坐标之间的对应关系,然后用透视点(PnP)计算姿势。这些方法需要高保真纹理的三维模型来产生辅助的合成训练数据,并用于姿势的改进,以达到训练实例的高精确度。
与上述为每个实例训练单一网络的方法不同,NOCS提议在图像上的像素和每个类别内共享的归一化物体坐标(NOCS)之间建立对应关系。有了这个类别级的形状先验,NOCS可以在测试时消除对CAD模型的依赖。后来的一些工作遵循利用类别级先验的趋势,通过NOCS表示进一步恢复物体的更准确的形状。这一工作思路的局限性在于,一些实例的形状和外观可能会有很大的不同,即使它们属于同一类别,因此训练过的网络对这些实例的概括能力是值得怀疑的。此外,在训练过程中仍然需要准确的CAD模型来生成地面真实的NOCS地图,并且需要为不同的类别训练不同的网络。我们提出的方法在训练和测试时都不需要CAD模型,而且是不分类别的。
无CAD模型的物体姿态估计:最近,有一些尝试是为了在训练和测试时实现无CAD模型的物体6D姿势估计。神经对象拟合和LatentFusion都是通过合成分析的方法来解决这个问题的,其中可区分的合成图像与目标图像进行比较,为物体姿势优化产生梯度。神经对象拟合提出用完全合成数据训练的Variational Auto Encoder(VAE)来编码类别级别的外观先验,而LatentFusion为每个未见过的物体用摆好的RGB-D图像建立了一个基于三维潜空间的物体表示。然而,这些方法的效率和准确性受到图像合成网络的高度限制,不适合AR应用。RLLG采取了不同的方法,从图像像素到物体坐标学习对应关系,而不需要CAD模型。尽管RLLG可以达到与同行相当的精度,但它只在实例层面工作,需要高度精确的实例掩码来分割前景像素。
最近,Objectron提出了一种数据驱动的方法,通过大量的注释训练数据来学习回归每个类别的投影盒角的像素坐标。这种方法成本很高,而且只限于几个类别,因为所学的模型是针对类别的。此外,它只能获得没有尺度的姿势,因为它使用单视角的图像作为输入。相反,我们的方法可以在映射阶段利用视觉-惯性运动学来恢复度量尺度,从而能够在测试时恢复度量6D姿势。
基于特征匹配的姿势估计:基于特征匹配的视觉定位pipeline已经被研究了很久。传统上,解决定位问题的方法是在输入的RGB图像和来自SfM的3D模型之间寻找2D-3D的对应关系,并使用手工制作的局部特征,如SIFT和ORB。
最近,基于学习的局部特征检测、描述和匹配超越了这些手工制作的方法,并取代了定位管道中的传统对应方法。值得注意的是,层次化定位(HLoc)提供了一个完整的工具箱,用于运行SfM与COLMAP以及特征提取和匹配与SuperGlue。我们的方法在使用自关注层和交叉关注层进行特征匹配方面受到SuperGlue的启发。然而,SuperGlue只关注图像之间的二维-二维匹配,没有考虑SfM图的图形结构。我们的方法使用图注意网络来处理对应三维SfM点(即特征轨迹)的二维特征,这在二维三维匹配过程中保留了SfM的图结构。
许多传统的物体识别和姿势估计方法也与视觉定位类似,都是基于特征的管道。这些方法首先通过从各视图中的匹配关键点重建稀疏点云来建立物体模型,并通过给定的查询图像用稀疏点云模型进行定位。一些方法[28, 45]提出用类似于同步定位和映射(SLAM)的框架在线建立点云模型。值得注意的是,BundleTrack提出了一个没有实例或类别级模型的在线姿态跟踪管道,这与我们的方法很相似。然而,它使用的是2D-2D特征匹配,而不是像我们这样的2D-3D。为了恢复三维信息,它还需要深度图作为输入,这可能会限制它在AR中的应用。
三、本文方法
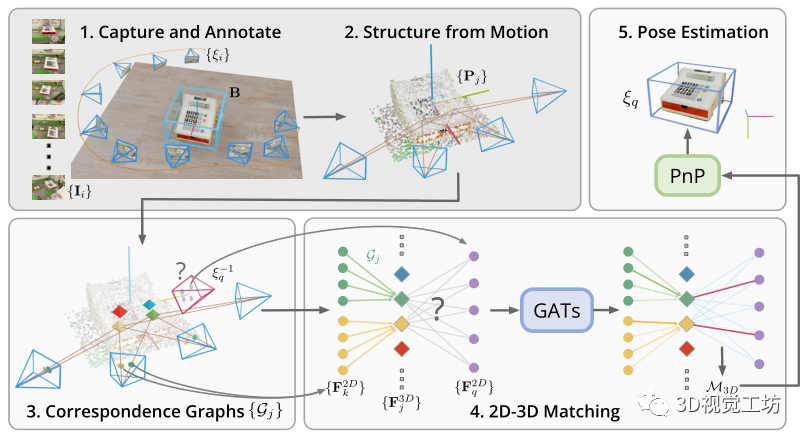
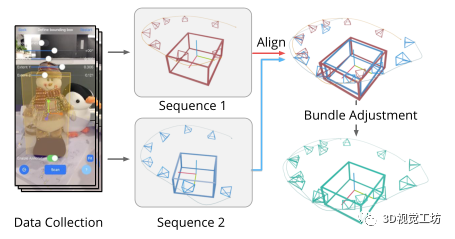
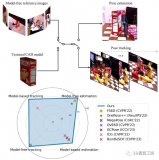
图2展示了提出方法的简介。在第1节介绍的One-shot物体姿态估计的设置中,用移动设备(如iPhone或iPad)对物体周围进行视频扫描。考虑到视频扫描和测试图像序列{Iq},One-shot物体姿态估计的目标是估计物体的姿态{ξq}∈SE(3)定义在摄像机坐标系中,其中q是视频中的关键帧索引。
3.1. 序言
数据采集和注释:在数据采集过程中,假设物体被设置在一个平面上,并且在采集过程中保持静态。为了定义物体的典型姿势,在AR中对物体的边界框B进行了注释,摄像机的姿势{ξi}∈SE(3)由ARKit或ARCore等非自身AR工具箱跟踪,i是帧索引。捕捉界面如图4所示。B是由中心位置、尺寸和围绕Z轴的旋转(偏航角)组成的参数。在数据捕获和注释之后,OnePose的管道可以被分成离线映射阶段和在线定位阶段。
恢复运动结构:在映射阶段,给定一组从视频扫描中提取的图像{I},我们使用恢复运动结构(SfM)来重建物体的稀疏点云{Pj},其中j是点索引。由于B是有注释的,{Pj}可以在物体坐标系中被定义。图2中可以看到对象{Gj}的所有对应图的可视化。具体来说,首先从每个图像中提取二维关键点和描述符,并在图像之间进行匹配,以产生二维-二维对应关系。每个重建的点Pj都对应于一组匹配的二维关键点和描述符∈Rd,其中k是关键点。其中k是关键点索引,d是描述符的维度。对应图{Gj},也被称为特征轨迹,由的关键点索引形成,如图2所示。
通过视觉定位进行姿势估计:在定位阶段,一连串的查询图像{Iq}被实时捕获。相对于{Pj},对查询图像的相机姿势进行定位,产生在相机坐标中定义的物体姿势{ξq}。
对于每个Iq输入图像,二维关键点和描述符{F2Dq }∈Rd被提取出来用于匹配。∈Rd被提取出来并用于匹配。在现代的视觉定位pipeline中,一个图像检索网络被用来提取图像级别的全局特征,这些特征可以被用来从SfM数据库中检索出候选图像,用于2D-2D匹配。增加要匹配的图像对的数量将大大降低定位的速度,特别是对于基于学习的匹配器,如SuperGlue或LoFTR。减少检索的图像数量会导致低的定位成功率,因此必须在运行时间和姿态估计精度之间做出权衡。
为了解决这个问题,我们建议直接在查询图像和SfM点云之间进行2D-3D匹配。直接的2D-3D匹配避免了对图像检索模块的需求,因此可以在快速的同时保持定位的准确性。在下一节中,我们将描述如何获得M3D的2D-3D对应关系。
3.2. OnePose

我们建议使用[40]中的图注意层来实现自适应聚合。我们将其命名为聚合-注意力层。聚合-注意层对每个单独的Gj进行操作。对于每个Gj,将权重矩阵表示为W∈Rd×d,聚集-注意力层定义为:
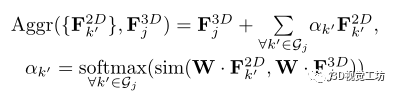
sim计算注意系数, 衡量描述符在聚合操作中的重要性。
受[32, 36]的启发,我们在聚合-注意力层之后进一步使用自注意力层和交叉注意力层来处理和转换聚合的三维描述符和查询的二维描述符。一组聚集-注意层、自注意层和交叉注意层构成了一个注意组。
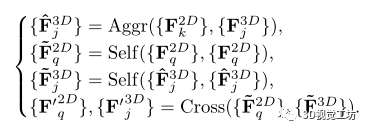

在选择了置信度阈值θ之后,C3D变成了一个置换矩阵M3D,它代表了2D-3D的匹配预测。有了M3D,物体在相机坐标中的姿态ξq可以通过RANSAC的PnP算法计算出来。
监督:监督信号Mgt 3D可以直接从训练集的SfM图中过滤的2D-3D对应关系中获得。损失函数L是由双SoftMax返回的置信度分数C3D的focal loss。
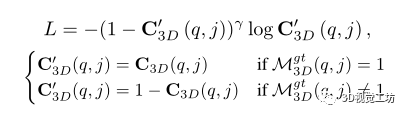
基于特征的在线姿势跟踪:上述姿势估计模块只接受稀疏的关键帧图像作为输入。为了在AR应用中获得稳定的物体姿态,我们进一步为OnePose配备了基于特征的姿态跟踪模块,该模块处理测试序列中的每一帧。与SLAM系统类似,姿势跟踪模块在线重建3D地图并维护其自身的关键帧池。在每个时间点,跟踪采用紧密耦合的方法,依靠预先建立的SfM地图和在线建立的三维地图来寻找二维三维对应关系并解决六维姿势问题。由于姿势跟踪模块在在线构建的地图中保留了测试序列的二维和三维信息,它可以比基于单帧的姿势估计模块更加稳定。姿势估计模块有助于在跟踪模块失败时进行恢复和重新初始化。我们在补充材料中提供了关于姿势跟踪模块的更多细节。
关于One-shot设定的附注:除了不使用CAD模型或额外的网络训练外,OnePose的单次拍摄设置与现有的实例或类别级姿态估计方法相比有很多优势。在映射阶段,OnePose将物体的简单视频扫描作为输入,并建立物体几何形状的特定实例三维表示。与CAD模型在实例级方法中的作用类似,物体的三维几何形状对于恢复具有度量尺度的物体姿势至关重要。在定位阶段,OnePose中学习到的局部特征匹配可以处理视角、光照和尺度的巨大变化,使该系统与类别级方法相比更加稳定和稳健。基于局部特征的管道还允许姿势估计模块与基于特征的跟踪模块自然耦合,以实现高效和稳定的姿势跟踪。
3.3. OnePose Dataset
由于没有现成的大规模数据集可以满足One-shot姿态估计的设定,我们收集了一个数据集,其中包括同一物体在不同位置的多次视频扫描。OnePose数据集包含150个物体的450多个视频序列。对于每个物体,都提供了多个视频记录,伴随着摄像机的姿势和三维边界框的注释。这些序列是在不同的背景环境下收集的,每个序列的平均记录长度为30秒,涵盖物体的所有视图。该数据集被随机分为训练集和验证集。对于验证集中的每个物体,我们指定一个映射序列用于建立SfM地图,并使用一个测试序列进行评估。
为了减少数据注释的人工劳动,我们提出了一种半自动的方法来同时收集和注释AR中的数据。具体来说,如图4所示,一个可调整的三维边界框被渲染到AR中的图像上。唯一的手工工作是调整三维边界框的旋转和粗糙尺寸。图4中显示了数据采集界面和后处理过程的可视化情况。
后处理的目的是减少ARKit对每个序列的姿势漂移误差,并确保各序列的姿势注释一致。为了实现这一目标,我们首先将序列与注释的边界盒对齐,并使用COLMAP进行捆绑调整(BA)。在BA中使用的特征匹配是用SuperGlue提取的。由于序列之间的背景不同,我们只在所有可匹配的图像对之间的前景(即在二维物体边界框内)提取匹配。关于我们的数据收集和处理管道的更多细节,请参考我们的补充材料。
四、实验
在这一节中,我们首先介绍了我们选择的基线方法和评估标准,以及在我们提出的OnePose数据集上的评估指标,然后在第4.2节中介绍了我们方法的实施细节。实验结果和消融研究分别在第4.3节和第4.4节详述。
4.1. 实验设置和基线
基线:我们将我们的方法与以下三类基线方法进行比较。1)在基于局部特征匹配的姿势估计方面,视觉定位方法与我们提出的方法最为相关。具体来说,我们用不同的关键点描述符(SIFT和SuperPoint)以及匹配器(Nearest Neighbour、SuperGlue[32])将我们的方法与HLoc[31]进行比较。2)实例级方法PVNet。3) 类别级方法Objectron]。据我们所知,Objectron是唯一一个以RGB图像为输入的类别级物体姿态估计方法。
评估方法:在所有的实验中,我们用所提出的方法进行每一帧的姿势估计,而不使用姿势跟踪模块,以进行公平的比较。对于我们的视觉定位基线和提议的方法,我们使用相同的视频扫描来建立定位的SfM图。请注意,用于大尺度场景的原始图像检索模块不能很好地泛化到物体上,因此我们从数据库图像中平等地抽出一个间隔相等的五张图像子集作为检索图像进行特征匹配。为了训练我们的实例级基线PVNet,我们使用3D盒角而不是CAD模型中抽样的语义点作为投票的关键点,并进一步提供辅助的掩码监督,这是训练PVNet所不可或缺的。由于类别级基线Objectron的数据要求很高,我们直接使用作者提供的模型,这些模型是在原始Objectron数据集上训练的。
衡量标准:对于评估指标,我们不能直接采用常用的ADD指标和2D投影指标,因为在我们的环境中没有CAD模型。
另一个常用的评估物体姿势质量的指标是中提出的5cm-5deg指标,如果误差低于5cm和5°,就认为预测的姿势是正确的。我们根据类似的定义,将标准进一步缩小到1cm-1deg和3cm-3deg,为增强现实应用中的姿势估计设定更严格的指标。我们以40厘米和25厘米为阈值,将物体按其直径分为三部分。当与实例级基线和类别级基线进行比较时,我们遵循原始论文中使用的指标。
4.2. 实施细节
在映射阶段,为了保持快速的映射速度,我们重用{ξi}并使用三角法来重建点云,而不需要通过捆绑调整来进一步优化相机的位置。在定位阶段,我们假设物体的二维边界框是已知的,在实践中可以很容易地从一个现成的二维物体检测器(如YOLOv5[3])中获得。为了减少姿势估计中可能出现的不匹配,在映射过程中只保留注释的三维边界框内的三维点,在定位过程中只保留检测的二维边界框内的二维特征。

4.3. 评价结果
与视觉定位基线的比较:我们将我们的方法与具有不同特征提取器和匹配器的视觉定位基线进行比较,结果见表1。HLoc(SPP+SPG)是带有基于学习的特征提取器(SuperPoint)和匹配器(SuperGlue)的基线,在所有三个变体中,它与我们的方法最相似。与HLoc(SPP+SPG)相比,我们的方法性能相当或略好,而HLoc(SPP+SPG)的运行时间是我们方法的十倍。我们相信,这种改进来自于我们的方法能够有选择地从多个图像中聚合上下文,这得益于我们的GATs设计,而不是只关注被匹配的两个图像。

与实例级基线PVNet的比较:所提出的方法与PVNet[26]在OnePose数据集的选定对象上进行了5cm-5deg的比较,结果如表2所示。为了获得用于训练PVNet的分割掩码,我们需要额外应用密集的三维重建,并渲染重建的网格以获得数据序列上的掩码。这个过程很耗时,而且由于三维重建的质量问题,大大限制了我们对物体的选择。我们的方法实现了比PVNet高得多的精度,这表明了我们方法的优越性。PVNet依赖于记忆从图像斑块到特定物体关键点的映射。如果不对密集覆盖所有可能视图的大规模合成图像(用CAD模型渲染)进行预训练,PVNet的性能将急剧下降。
相反,我们的方法能够利用学到的局部特征,这些特征相对来说是视点不变的,因此在保持精度的同时,可以推广到未见过的视图。

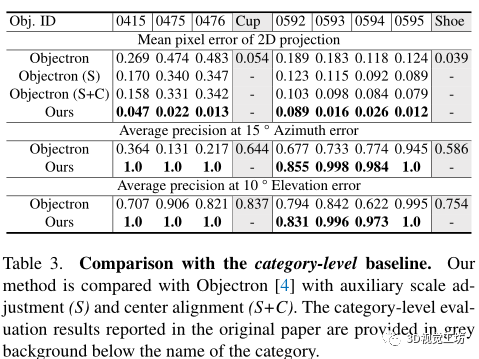
与类别级基线Objectron的比较:我们将我们的方法与Objectron在鞋类和杯类的所有物体上用原论文中使用的指标进行比较,结果见表。3. 对于二维投影的平均像素误差,Objectron在我们的数据集上的结果与Objectron数据集上两个类别的报告结果相差甚远。这是因为Objectron数据集和我们的数据集之间的地面真实注释存在偏差。为了进行公平的比较,我们进一步对Objectron的预测结果进行了缩放和中心对齐操作,以缓解这一差距,并在表3中分别提供了Objectron(S)和Objectron(S+C)的结果。
尽管Objectron的性能确实得到了提升,并且与原始论文中报告的结果相当,但我们的方法却以很大的幅度超过了它。我们的方法在方位角误差和仰角误差的平均精度上明显优于Objectron,特别是对于杯子类的物体,其形状和外观在不同的实例之间可能有很大的差异。这些实验说明了类别级方法对新物体实例的概括能力是有限的。
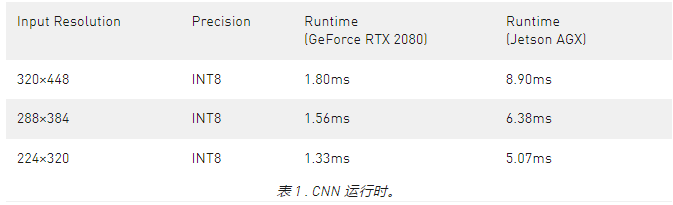
运行时间分析:我们在表1中报告了我们的视觉定位基线和我们的方法的运行时间。1. 运行时间包括使用SuperPoint对查询图像进行特征提取,以及不使用2D检测和PnP的2D-3D匹配过程。我们的方法比HLoc(SPP+SPG)的运行时间快10倍。所有的实验都在NVIDIA TITAN RTX GPU上进行。
五、结论
在本文中,我们提出了OnePose用于一次性物体姿态估计。与现有的实例级或类别级方法不同,OnePose不依赖于CAD模型,可以处理任意类别的物体,而不需要进行针对实例或类别的网络训练。与基于定位的基线方法、实例级基线方法PVNet和类别级基线方法Objectron相比,OnePose实现了更好的姿势估计精度和更快的推理速度。我们还认为,我们对基于定位的设置的重新审视(即单次物体姿态估计)对AR来说更实用,对社区也更有价值。
局限性:我们的方法的局限性来自于依赖局部特征匹配的姿势估计的性质。我们的方法在应用于无纹理物体时可能会失败。尽管我们的方法通过注意力机制得到了加强,但我们的方法仍然难以处理视频扫描和测试序列中的图像之间的极端尺度变化。
本审核编辑:郭婷
-
3D
+关注
关注
9文章
2875浏览量
107481 -
CAD
+关注
关注
17文章
1090浏览量
72446
原文标题:OnePose: 无CAD模型的one-shot物体姿态估计(CVPR 2022)
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于PoseDiffusion相机姿态估计方法

【爱芯派 Pro 开发板试用体验】人体姿态估计模型部署前期准备
采用CAD技术对飞机燃油测量进行姿态误差修正
3D姿态估计 时序卷积+半监督训练
基于深度学习的二维人体姿态估计方法

基于编解码残差的人体姿态估计方法
移动和嵌入式人体姿态估计

用NVIDIA迁移学习工具箱如何训练二维姿态估计模型
iNeRF对RGB图像进行类别级别的物体姿态估计
无需实例或类级别3D模型的对新颖物体的6D姿态追踪
基于MMPose的姿态估计配置案例

一个用于6D姿态估计和跟踪的统一基础模型
使用爱芯派Pro开发板部署人体姿态估计模型






 工商网监
工商网监
评论