 Transformer的出现让专用AI芯片变得岌岌可危
Transformer的出现让专用AI芯片变得岌岌可危
本文将分析CNN,还有近期比较火的SwinTransformer以及存内计算对AI芯片发展趋势的影响,Transformer的出现让专用AI芯片变得岌岌可危,命悬一线。 所谓AI芯片算力一般指INT8精度下每秒运作次数,INT8位即整数8比特精度。AI芯片严格地说应该叫AI加速器,只是加速深度神经网络推理阶段的加速,主要就是卷积的加速。一般用于视觉目标识别分类,辅助驾驶或无人驾驶还有很多种运算类型,需要用到多种运算资源,标量整数运算通常由CPU完成,矢量浮点运算通常由GPU完成,标量、矢量运算算力和AI算力同样重要,三者是平起平坐的。AI算力远不能和燃油车的马力对标,两者相差甚远。 AI芯片的关键参数除了算力,还有芯片利用率或者叫模型利用率。AI芯片的算力只是峰值理论算力,实际算力与峰值算力之比就是芯片利用率。
图片来源:互联网
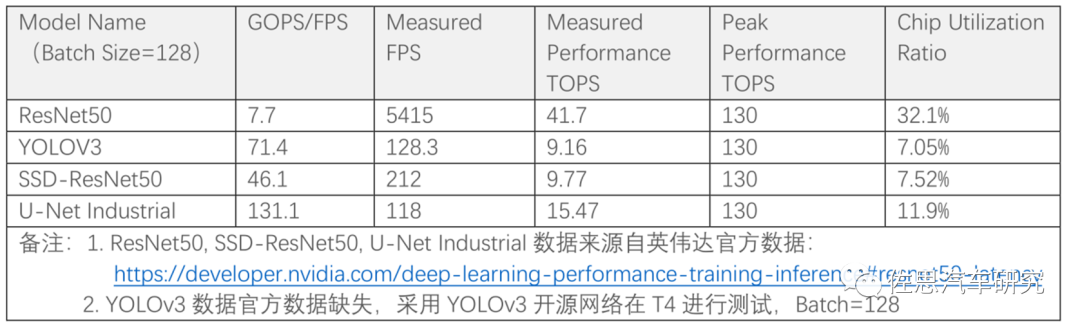
上表为英伟达旗舰人工智能加速器T4的芯片利用率,芯片的利用率很低,大部分情况下93%的算力都是闲置的,这好比一条生产线,93%的工人都无所事事,但工资还是要付的。实际上芯片利用率超过50%就是非常优秀,利用率低于10%是很常见的,极端情况只有1%,也就是说即使你用了4片英伟达顶级Orin,算力高达1000TOPS,实际算力可能只有10TOPS。 这也就是AI芯片主要的工作不是AI芯片本身,而是与之配套的软件优化,当然也可以反过来,为自己的算法模型定制一块AI芯片,如特斯拉。但应用面越窄,出货量就越低,摊在每颗芯片上的成本就越高,这反过来推高芯片价格,高价格进一步缩窄了市场,因此独立的AI芯片必须考虑尽可能适配多种算法模型。 这需要几方面的工作:
首先主流的神经网络模型自然要支持;
其次是压缩模型的规模并优化,将浮点转换为定点;
最后是提供编码器Compiler,将模型映射为二进制指令序列。
早期的AI运算完全依赖GPU,以致于早期的神经网络框架如Caffee、TensorFlow、mxnet都必须考虑在GPU上优化,简单地说就是都得适应GPU的编码器CUDA,这也是英伟达为何如此强的原因,它无需优化,因为早期的神经网络就是为GPU订做的。CUDA为英伟达筑起了高高的城墙,你要做AI运算,不兼容CUDA是不可能的,所有的程序员都已经用习惯了CUDA。但要兼容CUDA,CUDA的核心是不开源的,无论你如何优化,都不如英伟达的原生CUDA更优。车载领域好一点,可以效仿特斯拉。 卷积运算就是乘积累加,Cn=A×B+Cn-1,A是输入矩阵,简单理解就是一副图像,用像素数字矩阵来表示一副图像,B是权重模型,就是深度学习搜集训练数据,经过几千万人民币的数据中心训练出的算法模型,也可以看做是一种特殊的滤波器,右边的C是上一次乘积的结果。左边的C就是本次计算的输出结果。卷积运算后经过全连接层输出,画出Bounding Box并识别。用代码表示如下。

图片来源:互联网
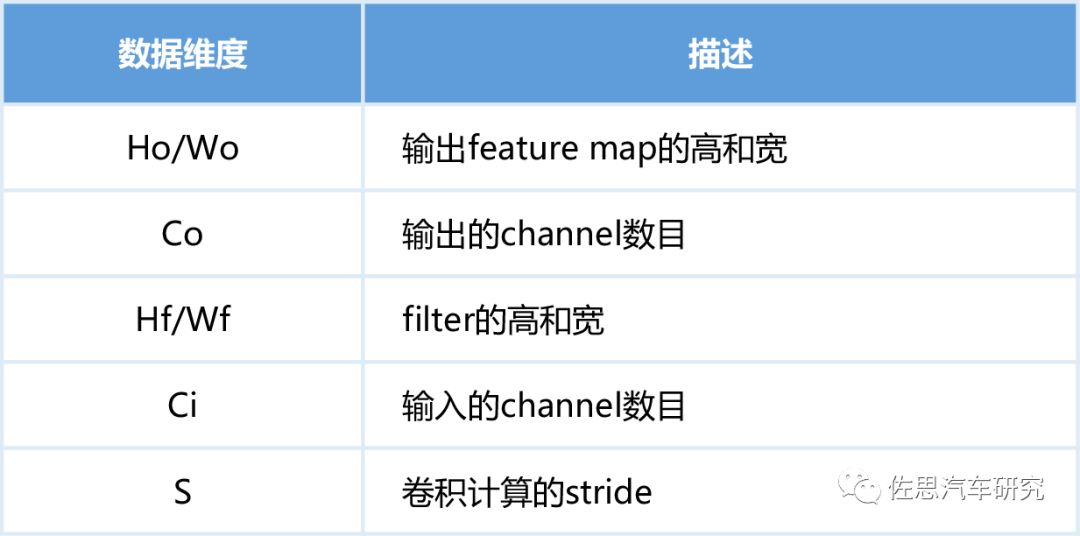
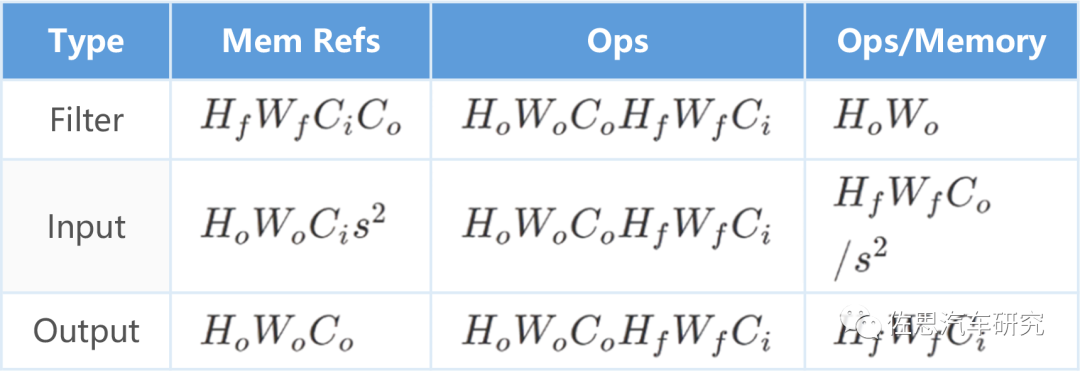
这些计算中有大量相同的数据存取,如下表。
图片来源:互联网
每一次运算都需要频繁读取内存,很多是重复读取,这非常耗费时间和功率,显然是一种浪费,AI芯片的核心工作就是提高数据的复用率。 AI芯片分为两大流派,一是分块矩阵的One Shot流派,也有称之为GEMM通用矩阵乘法加速器,典型代表是英伟达、华为。二是如脉动阵列的数据流流派,典型代表是谷歌、特斯拉。还有些非主流的主要用于FPGA的Spatial,FFT快速傅里叶变换。
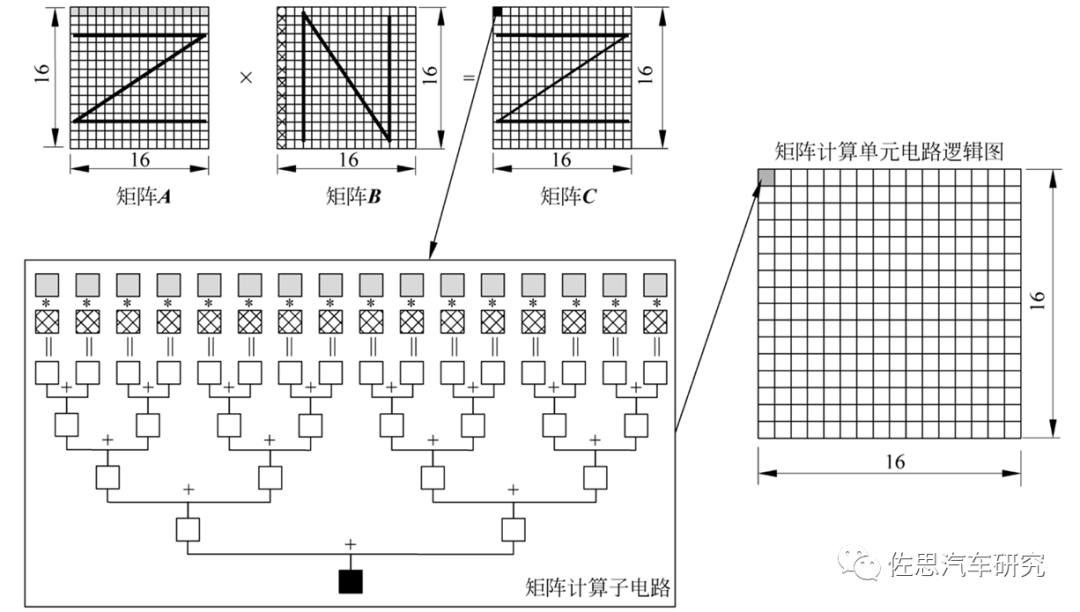
华为AI芯片电路逻辑
图片来源:互联网
以华为为例,其将矩阵A按行存放在输入缓冲区中,同时将矩阵B按列存放在输入缓冲区中,通过矩阵计算单元计算后得到的结果矩阵C按行存放在输出缓冲区中。在矩阵相乘运算中,矩阵C的第一元素由矩阵A的第一行的16个元素和矩阵B的第一列的16个元素由矩阵计算单元子电路进行16次乘法和15次加法运算得出。矩阵计算单元中共有256个矩阵计算子电路,可以由一条指令并行完成矩阵C的256个元素计算。 由于矩阵计算单元的容量有限,往往不能一次存放下整个矩阵,所以也需要对矩阵进行分块并采用分步计算的方式。将矩阵A和矩阵B都等分成同样大小的块,每一块都可以是一个16×16的子矩阵,排不满的地方可以通过补零实现。首先求C1结果子矩阵,需要分两步计算:第一步将A1和B1搬移到矩阵计算单元中,并算出A1×B1的中间结果;第二步将A2和B2搬移到矩阵计算单元中,再次计算A2×B2 ,并把计算结果累加到上一次A1×B1的中间结果,这样才完成结果子矩阵C1的计算,之后将C1写入输出缓冲区。由于输出缓冲区容量也有限,所以需要尽快将C1子矩阵写入内存中,便于留出空间接收下一个结果子矩阵C2。 分块矩阵的好处是只计算了微内核,速度很快,比较灵活,编译器好设计,增加算力也很简单,只要增加MAC的数量即可。成本低,消耗的SRAM容量小。
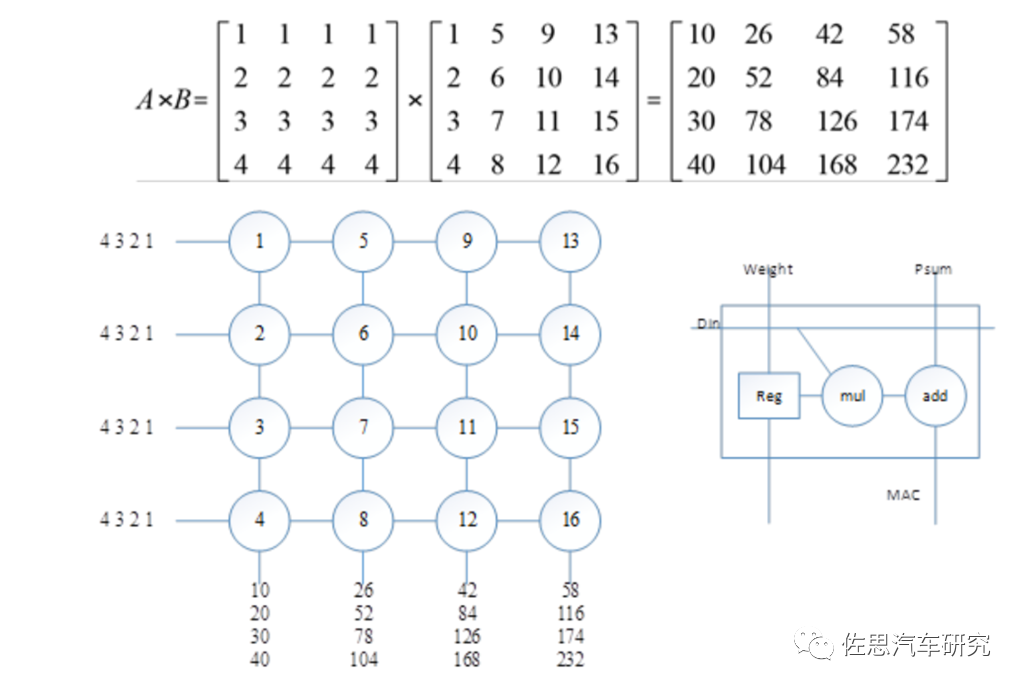
图片来源:互联网
上图为一个典型的脉动阵列,右侧是一个乘加单元即PE单元的内部结构,其内部有一个寄存器,在TPU内对应存储Weight,此处存储矩阵B。左图是一个4×4的乘加阵列,假设矩阵B已经被加载到乘加阵列内部;显然,乘加阵列中每一列计算四个数的乘法并将其加在一起,即得到矩阵乘法的一个输出结果。依次输入矩阵A的四行,可以得到矩阵乘法的结果。PE单元在特斯拉FSD中就是96*96个PE单元。
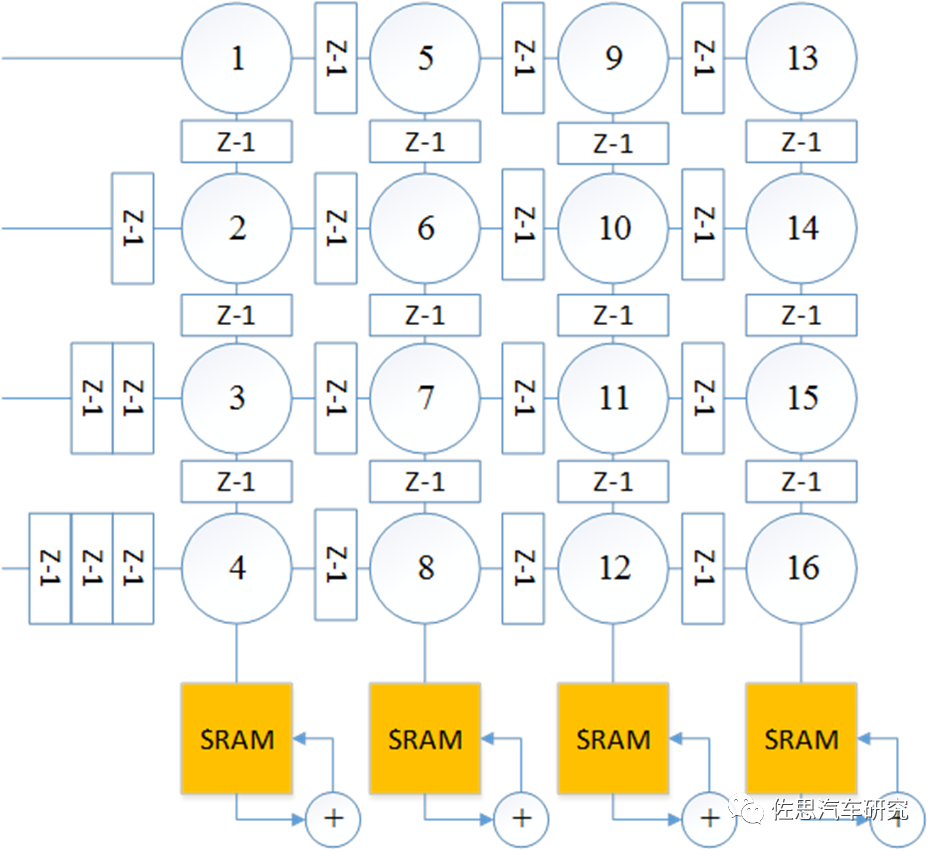
图片来源:互联网
不过最后还要添加累加器,需要多个SRAM加入。 脉动式优点是流水线式,不依赖一次一次的指令,一次指令即可启动。吞吐量很高。算力做到1000TOPS易如反掌,单PE占硅片面积小。但是其编译器难度高,灵活度低,要做到高算力,需要大量SRAM,这反过来推高成本。 在实际应用当中,情况会比较复杂,完整的深度学习模型都太大,而内存是很耗费成本的,因此,模型都必须要压缩和优化,常见的压缩有两种,一种是Depthwise Convolution,还包括了Depthwise Separable Convolution。另一种是Pointwise Convolution。Depthwise层,只改变feature map的大小,不改变通道数。而Pointwise层则相反,只改变通道数,不改变大小。这样将常规卷积的做法(改变大小和通道数)拆分成两步走。
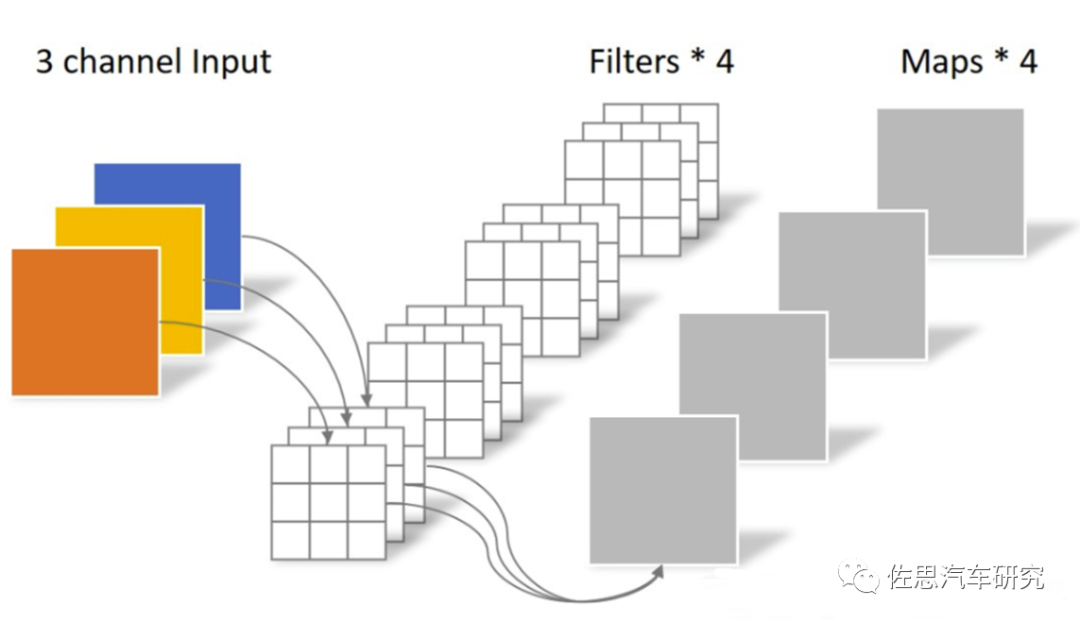
图片来源:互联网
常规卷积,4组(3,3,3)的卷积核进行卷积,等于108。
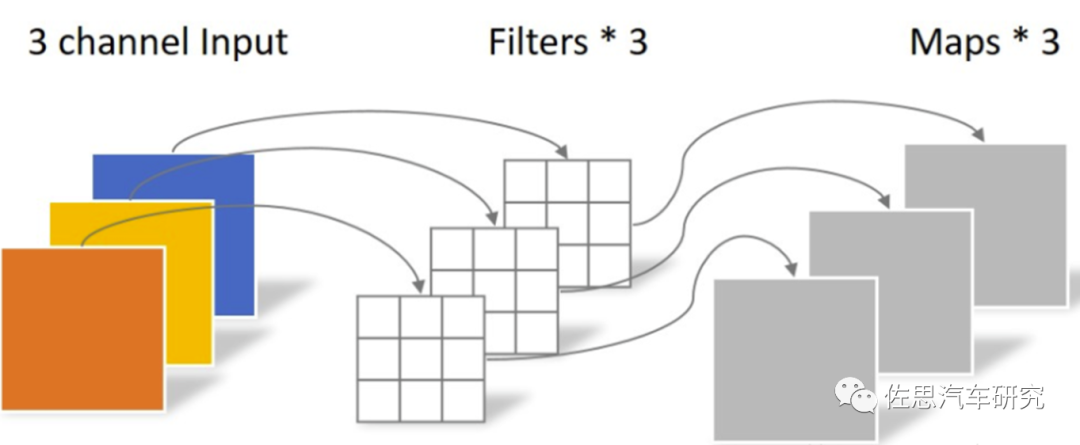
图片来源:互联网
Depthwise卷积,分成了两步走,第一步是3*3*3,第二步是1*1*3*4,合计是39,压缩了很多。 谷歌TPU v1的算力计算是700MHz*256*256*2=92Top/s@int8,之所以乘2是因为还有个加法累积。高通AI100的最大算力计算是16*8192*2*1600MHz=419Top/s@int8,高通是16核,每个核心是8192个阵列,最高运行频率1.6GHz,最低估计是500MHz。
性能最大化对应的模型要求
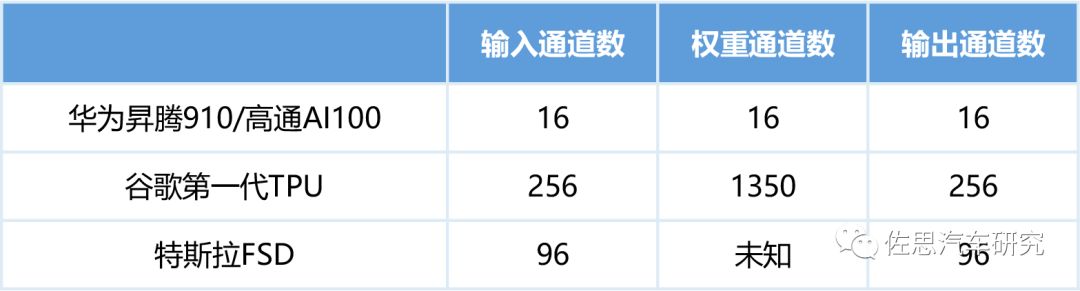
图片来源:互联网
对谷歌TPU v1来说,其最优性能是输入为256,而不少Depthwise是3*3,其利用率为9/256,即3.5%。对高通AI100来说,如果算法模型输入通道是256,那么效率会降低至16/256,即6.3%。显然对于精简算法模型,TPU非常不适合。对于精简模型来说,高通AI100非常不适合。 以上这些都是针对CNN的,目前图像领域的AI芯片也都是针对CNN的。近期大火的Swin Transformer则与之不同。2021年由微软亚洲研究院开源的SwinTransformer的横扫计算机视觉,从图像分类的ViT,到目标检测的DETR,再到图像分割的SETR以及3D人体姿态的METRO,大有压倒CNN的态势。但其原生Self-Attention的计算复杂度问题一直没有得到解决,Self-Attention需要对输入的所有N个token计算N的二次方大小的相互关系矩阵,考虑到视觉信息本来就是二维(图像)甚至三维(视频),分辨率稍微高一点就会暴增运算量,目前所有视觉类AI芯片都完全无法胜任。
Swin Transformer的模型结构
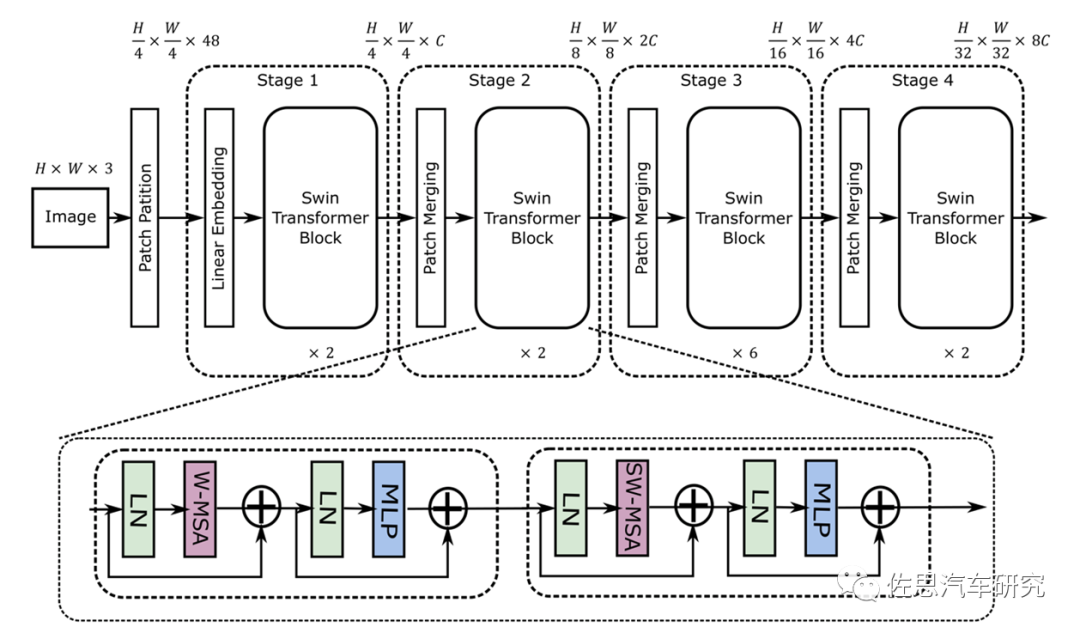
图片来源:互联网
从图上就能看出其采用了4*4卷积矩阵,而CNN是3*3,这就意味着目前的AI芯片有至少33%的效率下降。再者就是其是矢量与矩阵的乘法,这会带来一定的浮点矢量运算。 假设高和宽都为112,窗口大小为7,C为128,那么未优化的浮点计算是4*112*112*128*128+2*112*112*112*112*128=41GFLOP/s。大部分AI芯片如特斯拉的FSD和谷歌的TPU,未考虑这种浮点运算。不过华为和高通都考虑到了,英伟达就更不用说了,GPU天生就是针对浮点运算的。看起来41GFLOP/s不高,但如果没有专用浮点运算处理器,效率也会急速下降。
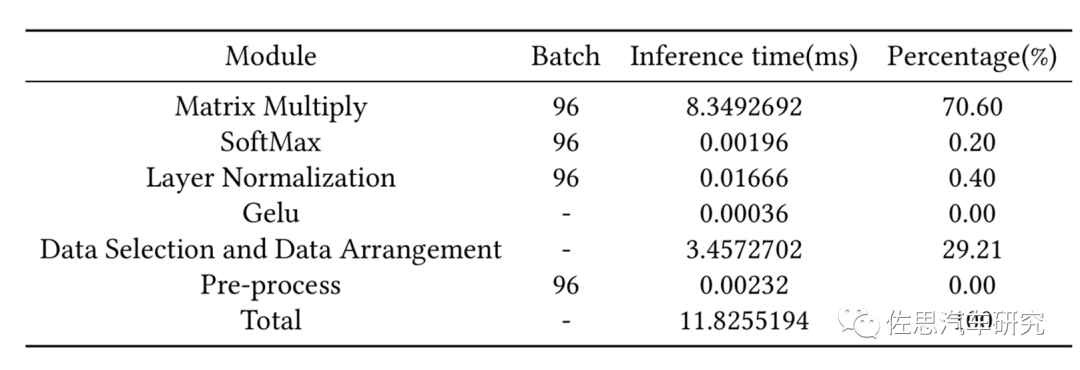
图片来源:互联网
与CNN不同,Swin Transformer的数据选择与布置占了29%的时间,矩阵乘法占了71%,而CNN中,矩阵乘法至少占95%。
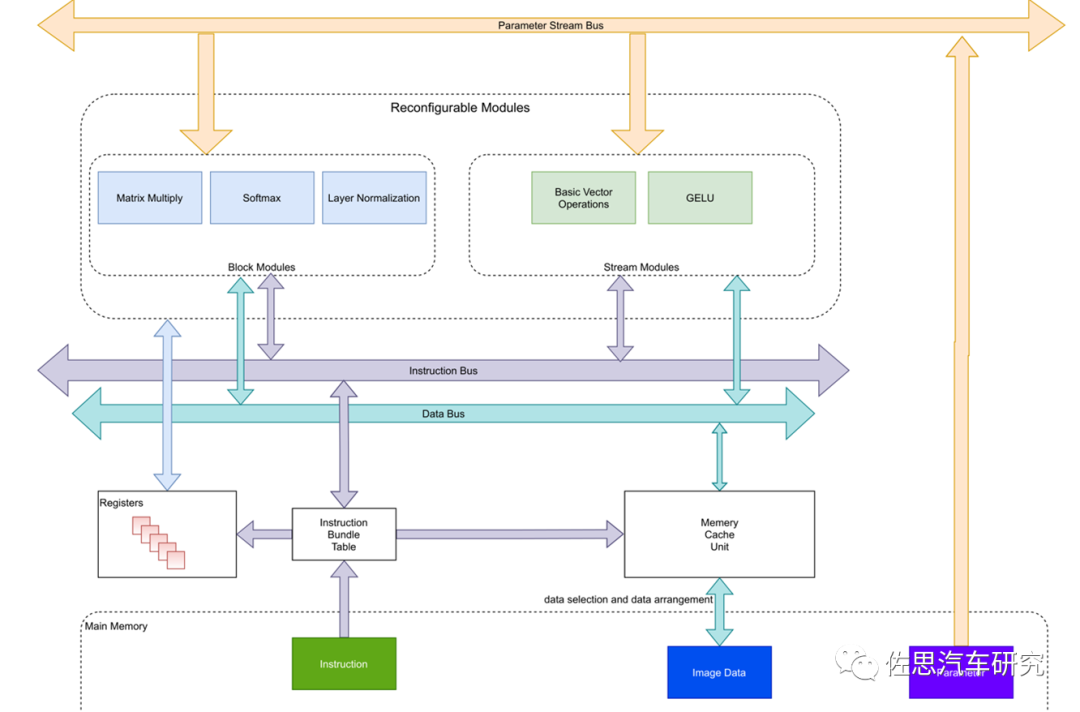
图片来源:互联网
针对Swin Transformer的AI芯片最好将区块模型与数据流模型分开,指令集与数据集当然也最好分开。
图片来源:互联网
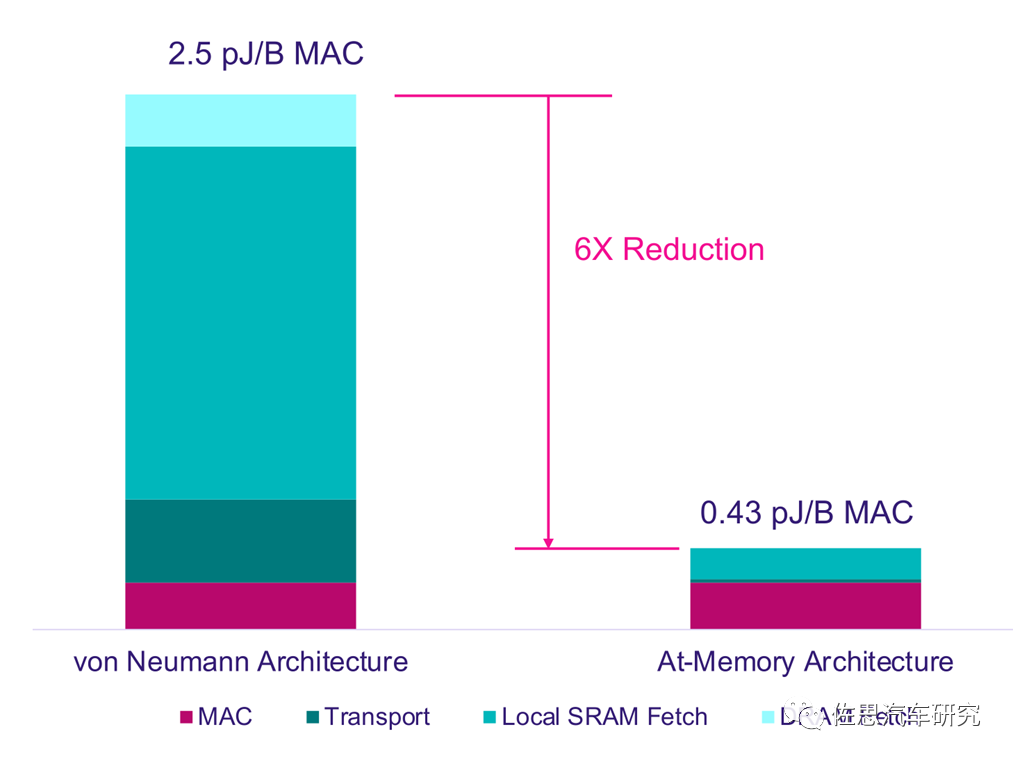
针对Swin Transformer,理论上最好的选择是存内计算也叫存算一体,上图是存内计算架构与传统AI芯片的冯诺依曼架构的功耗对比,存内计算架构在同样算力的情况下,只有冯诺依曼架构1/6的功耗。
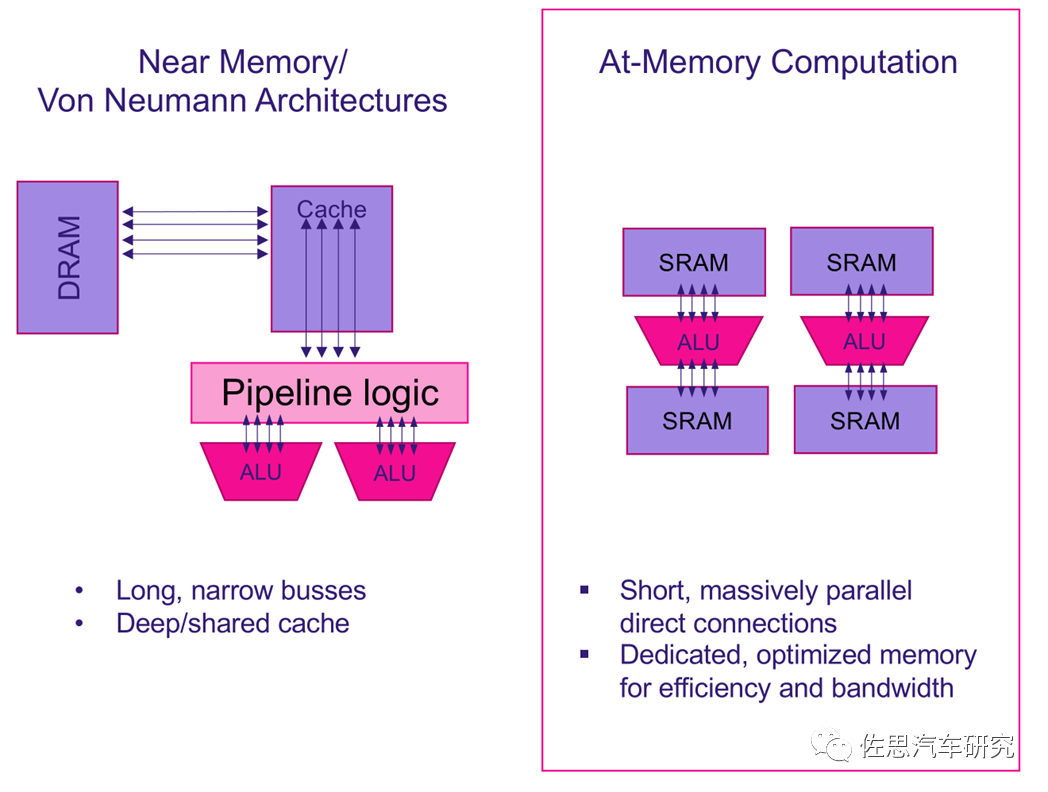
冯诺依曼架构与存内计算架构对比
图片来源:互联网
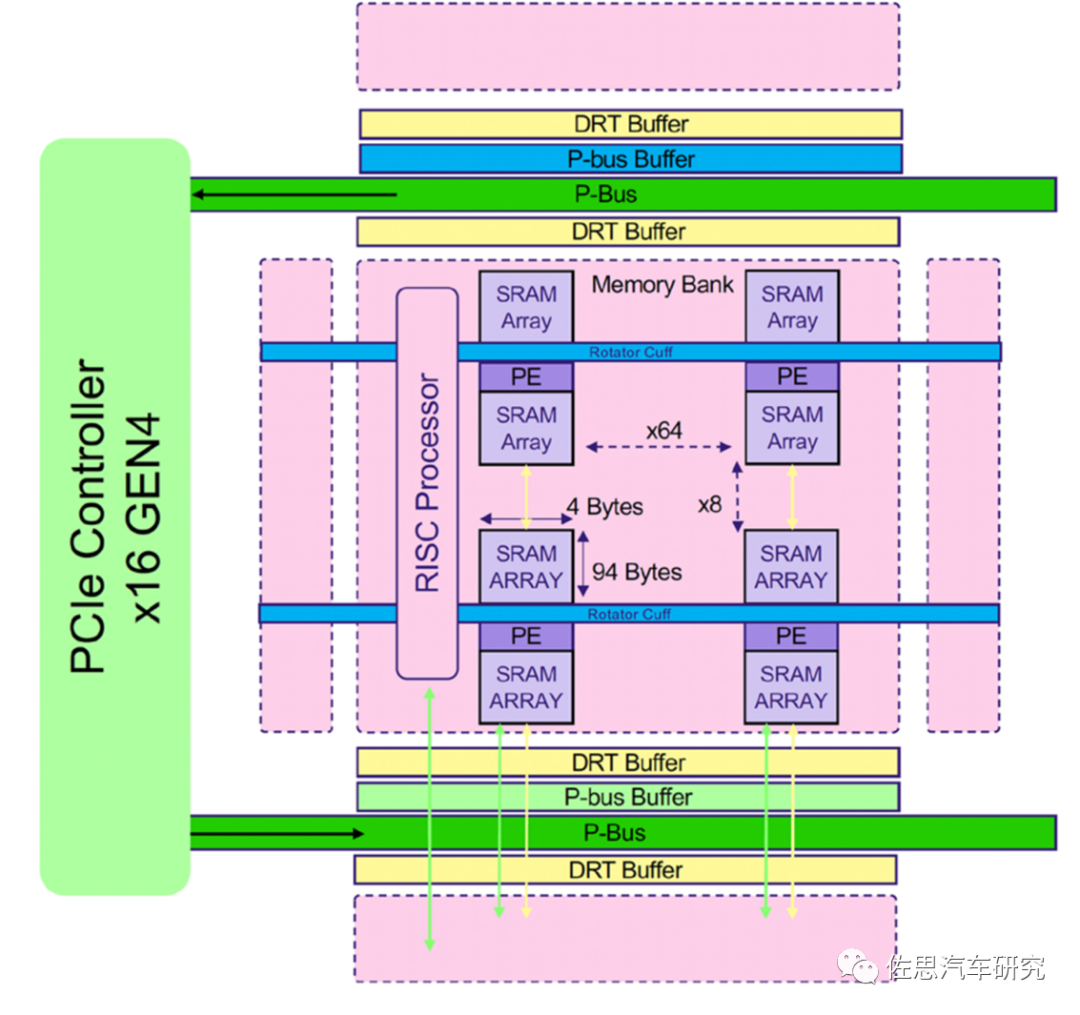
典型的存内计算架构芯片
图片来源:互联网
不过目前存内计算离实用距离还非常遥远:
第一,内存行业由三星、美光和SK Hynix三家占了90%的市场,行业门槛极高,这三家极力保持内存价格稳定。
第二,目前AI模型都是越来越大,用存内计算存储大容量AI模型成本极高。三星的存内计算芯片测试用的是二十年前的MNIST手写字符识别,这种AI模型是kb级别的。而自动驾驶用的至少也是10MB以上。
第三,精度很低,当前存内计算研究的一个重点方法是使用电阻式RAM(ReRAM)实现位线电流检测。由于电压范围,噪声和PVT的变化,模拟位线电流检测和ADC的精度受到限制,即使精度低到1比特也难以实现,而辅助驾驶目前是8比特。
第四,电阻式RAM可靠性不高。经常更新权重模型,可能导致故障。
最后,存内计算的工具链基本为零。最乐观的估计,存内计算实用化也要5年以上,且是用在很小规模计算,如AIoT领域,自动驾驶领域十年内都不可能见到存内计算。即使存内计算实用化,恐怕也是内存三巨头最有优势。
Transformer的出现让专用AI芯片变得非常危险,难保未来不出现别的技术,而适用面很窄的AI专用芯片会完全丧失市场,通用性比较强的CPU或GPU还是永葆青春,至于算力,与算法模型高度捆绑,但捆绑太紧,市场肯定很小,且生命周期可能很短。 声明:本文仅代表作者个人观点。
审核编辑 :李倩
-
神经网络
+关注
关注
42文章
4776浏览量
100935 -
AI芯片
+关注
关注
17文章
1897浏览量
35118 -
算力
+关注
关注
1文章
999浏览量
14876
原文标题:Transformer挑战CNN,AI芯片需要改变
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
盘点2023年国产厂商推出ASIL-D芯片新品
transformer专用ASIC芯片Sohu说明

恒玄科技研发AI眼镜专用芯片
TB1801线性车灯专用芯片可完美替代LAN1165E

AI芯片的混合精度计算与灵活可扩展
新思科技解读是什么让AI芯片设计与众不同?
只能跑Transformer的AI芯片,却号称全球最快?
AI初创公司Etched获1.2亿美元A轮融资,加速专用AI芯片研发

安霸发布两款用于车队远程监控及信息处理系统的最新一代AI芯片
risc-v多核芯片在AI方面的应用







 工商网监
工商网监
评论