 基于填表方式的NER方法
基于填表方式的NER方法
现在很多基于填表方式的NER方法,在构造表中元素的时候,一般用的都是由相应span的head字和tail字的表征得到的,而本文在此基础上加入了从span中所有字的表征中抽取出来的特征,下面介绍一下具体怎么搞。
1. 论文出发点
中文没有天然的单词边界,所以中文的的NER比英文的还要难一些。这两年NER有一个很好的点子就是引入外部词典,显式的告诉模型哪些字的组合在中文中是一个词,从而给模型注入一些先验的字与字之间的关系,取得了很好的效果,比如Lattice LSTM、FLAT、LEBERT等。但这类方法都需要提供一个外部词典,外部词典的质量就尤为重要了。本文的想法就是「不依赖外部字典,让模型自己去学习实体内字与字之间的关联,以及实体之所以会是某一个类型的实体的规律」。为了实现这个想法, 本文提出了两个idea:
「探索实体内部的组成规律——“命名规律性”,用来增强实体的边界监测和类型预测。」
本文的作者们发现很多常规实体类型(LOC、ORG等)都有“「命名规律性」”,就是说「某个实体类型的mentions都有某种内部的构成模式,如果模型学习到了这种内部的构成结构,那么对于识别实体的边界以及预测实体的类型会有一定的帮助」。举个例子,比如以“公司”或者“银行”等词结尾的实体,一般就是ORG,再比如,图1中“尼日尔河流经尼日尔与尼日利亚”中就有一个规律,“XX+河”大部分情况下就是和地理位置相关的实体类型(LOC),虽然“流”字的右边是“经”也可以组成“流经”这个词,导致“流”字这里有边界模糊问题,但是如果模型可以学到“XX+河”这个命名规律,那么大概率还是会把"尼日尔河"作为一个实体识别出来的。

「利用上下文来缓解仅依赖命名规律性无法完全确定实体边界的问题」
有的时候仅依赖命名规律性,可能会造成一些冤假错案,这时候「可以通过上下文来缓解命名规律性对边界的决定性影响」,比如图1中“中国队员们在本次比赛中取得了优异成绩”中,XX+队是一个pattern的话,但实际上实体并不是“中国队”,这时候只利用命名规律性来判别实体边界和类型就会出问题,需要看上下文了。
可以看出,本文的方法是要在上两者之间取一个平衡。
2. RICON模型
本文提出的这个模型叫做「R」egularity-「I」nspired re「CO」gnition 「N」etwork (「RICON」),采用是「填表」的方式进行标注,也就是搞一个word-word表,表中每一个元素表示相应的span是什么类型的实体。
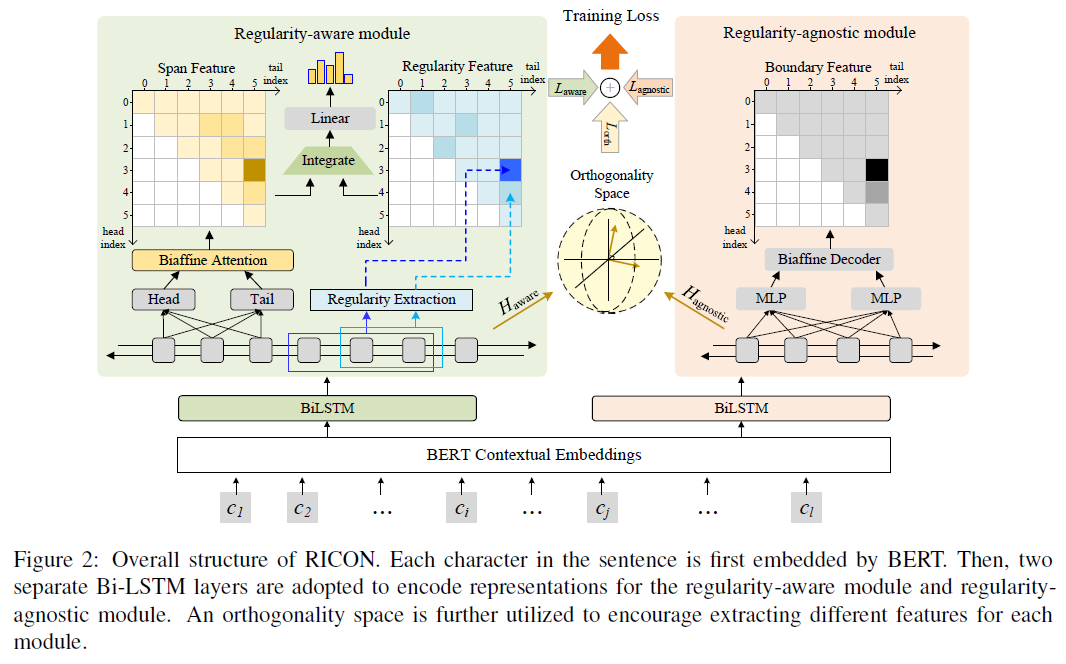
RICON模型结构
如上图所示,模型主要有两个模块:
「Regularity-aware Module(规律感知模块)」:这个模块负责分析span内部的规律,进而获取结合了规律的span表征,然后用于实体类型的预测;
「Regularity-agnostic Module (规律判断模块)」:这个模块主要获取span上下文的表征,然后用于判断这个实体到底是不是一个实体。
除此之外,模型使用了「BERT+BILSTM」做文本的表征和编码,还使用了「正交空间限制」(Orthogonality Space Restriction),来让上面两个模块编码不同的特征。下面具体介绍一下。
2.1 Embedding 和 Task-specific Encoder
给定一个有个字的句子:
先过BERT,取得每一个字的上下文表征;
然后分别过两个独立的BiLSTM,将每个字的前后向的hidden_state拼接起来,分别获取句子的char序列的aware-specific representation 和agnostic-specific representation。会被送入规律感知模块,会被送入规律判断模块。,其中d是LSTM的unit的数量。
2.2 规律感知模块 Regularity-aware Module
这个模块主要是负责分析span内部的规律,进而获取结合了规律的span表征,然后用于实体类型的预测。想要获取「结合了规律的span的表征」,本文采用的方式是分而治之:如下图所示「找到span的内部规律特征——Regularity Feature,以及span的特征——Span Feature,然后把二者结合起来去做实体类型的分类」。
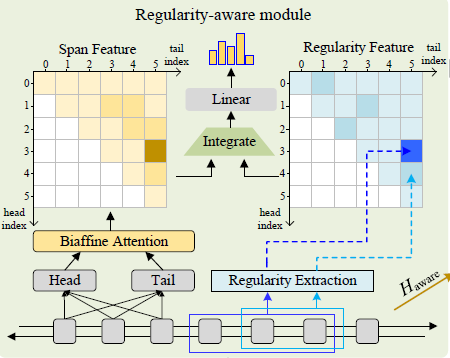
规律感知模块
Span Feature的获取
我们先来看几种填表类型NER方法中span特征的生成以及实体类型分类的方式:
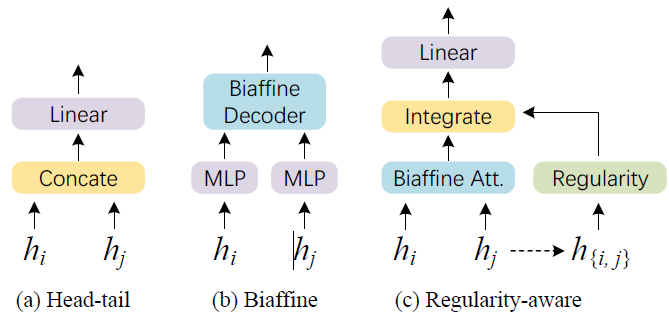
Head-Tail拼接做span表征,然后用线性分类器分类,如上图(a),但这种就有点简单;
Biaffine 分类器的方式(《Named Entity Recognition as Dependency Parsing》),如上图(b),将head和tail的表征分别过不同的MLP,然后用双仿射解码器去做实体类别的分类,达到了SOTA;
第三种是本文中提出的,Regularity-aware表征过线性分类器,我们稍后会介绍;
这里我再加一种,就是我上一篇介绍的W2NER中用的方式:CLN+空洞卷积;
本文在获取Span Feature的时候「主要用的是Biaffine方式的变种」,表内的每个位置所表示的span(第个字是span的head,第个字是span的tail)的特征为:
其中,分别是head和tail字的表征。是一个 的张量, 是一个 的矩阵,那么 就是一个维度是的向量。
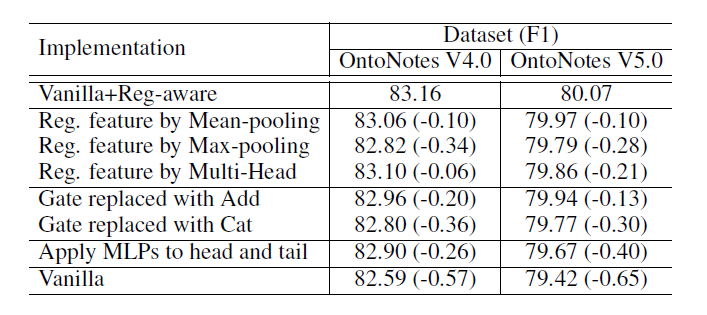
这里大家可以看到本文用的Biaffine方式没有用它前面的那俩MLP,原因是MLP会把头尾投影到不同的空间里面,效果不好,论文也通过实验证实了用MLP效果相较于不用,有所下降(下表中Apply MLPs to head and tail)。
Regularity Feature的获取
上面提的几种span特征生成方式都用的是span的头和尾,而想要分析span内部的规律,仅用头和尾那是肯定不够的,所以在本篇论文里面,「用了span内的所有字,用一个线性attention来计算每个字的权重,然后对字的表征进行加权求和得到span内部的规律性特征」。此外,对于长度是1的span,也就是单字span,就用它自己的表征作为这个span的规律性特征。

当然,关于这个规律怎么抽取,论文中也做了一些其他的尝试,简单的有max pooling/ mean pooling,复杂的有multi-head self-attention,但效果都不是很好(详见上面的“不同实验方案的对比表”),并且文中表示这是未来的一个可探索的方向。
这里我说一下我关于这种规律性特征抽取方式的一些想法(可能不对哈):
❝
公式中的 是一个可训练的参数向量,看公式会与所有字的表征向量相乘,分别得到一个标量数字,那我可不可以认为这个就是「代表着某种神秘的实体规律」,与字的表征做內积,结果越大,那这个字与实体规律越契合,然后用这个得到的內积标量在span的局部内用softmax做权重的计算,将命中规律的字在span中突显出来。
怎么说呢,给我的感觉就是通过这种方式并没有很透彻的分析span内部的规律,只是将句子中命中了实体规律(也不管命中的是不是同一种实体规律)的字在它所在的span中给凸显出来(比如最开头举例的XX+河的模式中的“河”字,以及中国队员中的XX+队的“队”字),也就是说它只考虑了规律,其他基本没考虑。哦当然,我这个想法是没考虑前面的BERT+BILSTM,因为BERT+BILSTM并不是这篇论文的核心创新点。我认为这也是上面作者们会认为过分强调“命名规律性”会导致会对边界造成不好影响的一个原因吧。所以这个抽取出来的特征不能单独作为span的表征,需要用分而治之的思路,结合Biaffine-based span Feature来判断边界,还又单独加了一个“规律判断模块”来根据上下文判断这个规律到底是不是一个真正的规律。
这里再开一个小小的脑洞,如果想要探索span的内部规律,更直观的想法是让span内部的字之间发生交互,我们首先生成一个word-word table,其中每个位置是他们两两交互的表征,比如用CLN,然后用大小为[1, 1], [2, 2], …, [L, L]的卷积核去提取span的表征,卷积核只在对角线上滑动(比如需要获取span(3, 5)的表征,那么就用一个大小为3*3的卷积核提取特征,这个卷积核刚好覆盖住table中的(3, 3), (3, 4), (3, 5), (4, 3), (4, 4), (4, 5), (5, 3), (5, 4), (5, 5)这几个全部都是这个span内的字两两交互的位置),卷积核抽取的特征(再加点非线性变换)作为它右上角的元素表示的span的表征,感觉是不是也可以直接作为结合了span内部规律的span表征了呢?但是文本是变长的,那不能规定所有尺寸的卷积核吧?这个处理起来也不太好处理,这个方案有没有大佬觉得有搞头的~
❞
整合Span Feature和Regularity Feature
「利用门控机制整合Span Feature和Regularity Feature」,获取整合了规律性特征的span表征,具体就是这俩Feature拼接,然后线性映射,然后过sigmoid获取span特征的权重,Regularity特征的权重自然就是了,然后加权求和得到span表征:
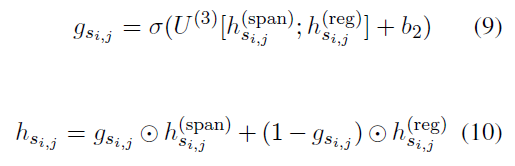
关于这部分,作者们也尝试了将Span Feature和Regularity Feature拼接或者相加作为span表征的方式,但效果均不如用门控机制好。
分类器和Loss Function
分类器:对span表征用一个线性分类器预测每个span的类型
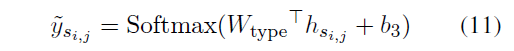
Loss Function用的是CE
case study
关于这个模块的效果,我们来看一个例子,如下图所示,“波罗的海”,如果用vanilla方法(BERT+BILSTM+本模块中的Span Feature部分)预测成了GPE,而Vanilla+Reg-aware方法(BERT+BiLSTM+本模块)就可以预测正确为LOC,且门控机制给Regularity Feature的打分是0.83。

Regularity-aware Module起效的case
2.3 规律判断模块 Regularity-agnostic Module
作者们认为regularity-aware module让模型很严格的按规律去预测实体类型,可能会导致precision的增长,但是正如上文中介绍的例子,太严格遵守规律,可能会导致对边界判定出问题,所以他们加了这个模块。在这个模块中不考虑span内的具体形式,而是更注重上下文,所以他们选择了位于边界处的头和尾字下手,他们的「目标是:用head 和 tail feature来判断这个span是否是一个entity」(所以是BILSTM发威了么)。
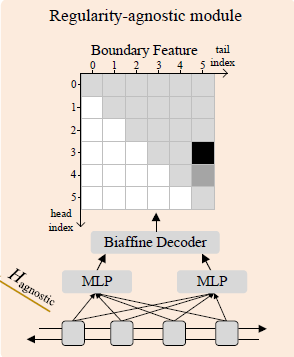
Regularity-agnostic Module
对agnostic-specific representation,分别过两个MLP(一个head MLP,一个tail MLP),得到head表征和tail表征。
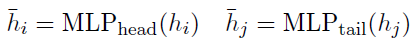
然后依然是组一个的表格,然后每个表格内的元素表示第个字为head,第个字为tail的span是一个entity的概率,计算方式是双仿射解码,然后过sigmoid:
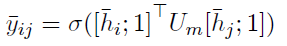
Loss Function用的是BCE
case study
关于这个模块的效果,我们也来看一个例子,如下图所示,仅用Regularity-aware Module会导致“XX+公司”这个规则被命中,从而预测错误,而加上这个模块后缓解了这一问题。

Regularity-agnostic Module起效的case
2.4 Orthogonality Space Restriction
上面的两个模块,规律感知模块感知规律,规律判断模块并不考虑任何规律,那么自然希望这俩模块学习到的是不同的特征。所以为了鼓励这俩模块别学同样的特征,作者们在Task-specific Encoder,也就是最开头的那俩BILSTM的后面,构造了一个正交空间,争取让这俩模块编码input embedding的不同方面。
具体就是用最开头那俩BiLSTM的输出进行矩阵乘法,然后用Frobenius范数的平方(F-范数)作为loss。

公式中的 就是F-范数的平方,F-范数其实就是矩阵中每个元素的平方和的开方,类似于向量的L2范数,它用来衡量矩阵大小(到原点(零矩阵)的距离),看定义是不小于零的。所以上面论文里的公式应该没有那个负号吧,作者是不是打错了。我理解其实这个模块就是希望aware所在的空间和agnostic所在的空间是两个正交子空间,一个子空间中的任意一个向量与另一个子空间中的任意一个向量都是正交的,內积是0,那么两个矩阵相乘的这个自然是希望它的大小(F-范数)是冲着零去的。
2.5 训练和推断
最终loss
其中是三个超参数,论文的实验中分别设定为1、1、0.5。
推断
推断的时候直接使用regularity-aware module去预测每个span的实体类型,如果碰到重叠的结果,比如,则他们选择分数更高的那个。也就是说Regularity-agnostic Module其实是个辅助模块咯。
3. 实验与分析
3.1 数据集
文中实验用了如下几个数据集:
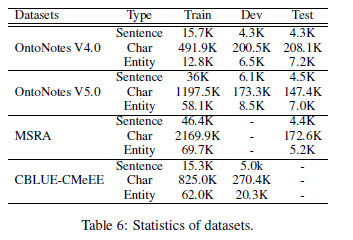
3.2 效果
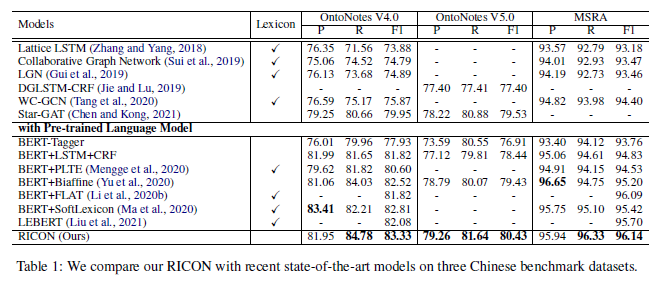
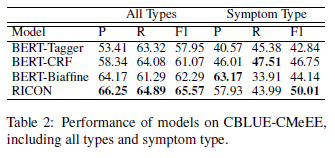
可以看到,本文提出的RICON在多个数据集上F1均达到了SOTA,效果还是不错的,总的来说Recall涨幅还挺大的。
消融实验
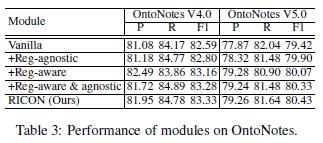
消融实验
Vanilla:就是只有规律性感知模块的Span Feature部分,其他的都没有
+Reg-agnostic:Vanilla加上规律判断模块(判断每个span到底是不是一个实体),f1略有增长
+Reg-aware:Vanilla加上规律感知模块中的Regularity Feature部分,发现Precision提升了,但recall下降了,但是整体F1有显著增长,说明加了感知模块以后,确实增强了实体类型的预测,但是同时导致一些本该是实体的span被漏掉了。
但其实我很想看看BERT+BiLSTM+Regularity Feature部分的效果
+Reg-aware & agnostic:两个模块都加上,效果有进一步提升,相较于+Reg-aware,Recall提升了很多,说明猜疑部分可以加强边界的判定。
最后RICON是上一个实验再加上正交空间限制,效果又进一步有提升。
分析
论文中提出的RICON,作者认为他们探索的规律性其实是一个「latent adaptive lexicon」,比之前的一些融入了Lexicon的方法效果要好一些。
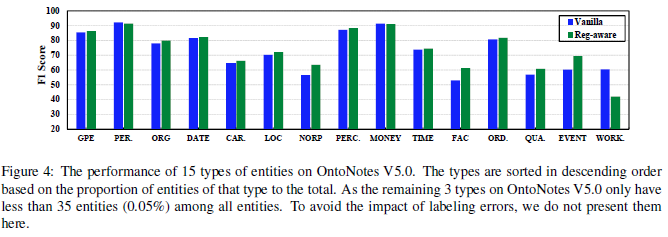
文中有+Reg-aware的方法与Vanilla方法在单个实体上做了对比,如下图,发现在GPE、ORG、DATE等有明显命名规律性的实体上,+Reg-aware方法有提高,而在PERSON等没啥命名规律性的实体上,就有下滑。此外对于MONEY这种有规律性的,居然也下滑了,原因是因为训练集里都是“数字+dollar”,但测试集里都是只有数字(通过+Reg-agnostic模块来缓解)。说明了“命名规律性”特征的抽取确实有用,而且「这个模型其实也可以用来做“命名规律性”强弱的判别」。
-
编码
+关注
关注
6文章
942浏览量
54822 -
模型
+关注
关注
1文章
3239浏览量
48829 -
Span
+关注
关注
0文章
5浏览量
8396
原文标题:NAACL2022 | 华为提出NER SOTA—RICON
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
SM1P步进电机控制器中文填表编程思想
如何用寄存器的方法来操作RGB灯
光学传感器的系统NER模拟

广东省数字政府填表报数管理系统正式发布上线
一些NER的英文数据集推荐
NLP:如何在只有词典的情况下提升NER落地效果
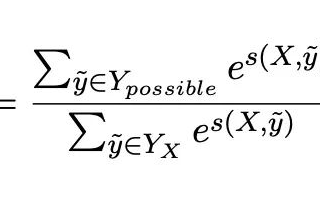
一种单独适配于NER的数据增强方法
如何解决NER覆盖和不连续问题
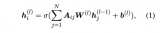





 工商网监
工商网监
评论