 Spark的两种核心Shuffle详解
Spark的两种核心Shuffle详解
在 MapReduce 框架中, Shuffle 阶段是连接 Map 与 Reduce 之间的桥梁, Map 阶段通过 Shuffle 过程将数据输出到 Reduce 阶段中。由于 Shuffle 涉及磁盘的读写和网络 I/O,因此 Shuffle 性能的高低直接影响整个程序的性能。Spark 也有 Map 阶段和 Reduce 阶段,因此也会出现 Shuffle 。
Spark Shuffle
Spark Shuffle 分为两种:一种是基于 Hash 的 Shuffle;另一种是基于 Sort 的 Shuffle。先介绍下它们的发展历程,有助于我们更好的理解 Shuffle:
在 Spark 1.1 之前, Spark 中只实现了一种 Shuffle 方式,即基于 Hash 的 Shuffle 。在 Spark 1.1 版本中引入了基于 Sort 的 Shuffle 实现方式,并且 Spark 1.2 版本之后,默认的实现方式从基于 Hash 的 Shuffle 修改为基于 Sort 的 Shuffle 实现方式,即使用的 ShuffleManager 从默认的 hash 修改为 sort。在 Spark 2.0 版本中, Hash Shuffle 方式己经不再使用。
Spark 之所以一开始就提供基于 Hash 的 Shuffle 实现机制,其主要目的之一就是为了避免不需要的排序,大家想下 Hadoop 中的 MapReduce,是将 sort 作为固定步骤,有许多并不需要排序的任务,MapReduce 也会对其进行排序,造成了许多不必要的开销。
在基于 Hash 的 Shuffle 实现方式中,每个 Mapper 阶段的 Task 会为每个 Reduce 阶段的 Task生成一个文件,通常会产生大量的文件(即对应为 M*R 个中间文件,其中, M 表示 Mapper阶段的 Task 个数, R 表示 Reduce 阶段的 Task 个数) 伴随大量的随机磁盘 I/O 操作与大量的内存开销。
为了缓解上述问题,在 Spark 0.8.1 版本中为基于 Hash 的 Shuffle 实现引入了 ShuffleConsolidate 机制(即文件合并机制),将 Mapper 端生成的中间文件进行合并的处理机制。通过配置属性 spark.shuffie.consolidateFiles=true,减少中间生成的文件数量。通过文件合并,可以将中间文件的生成方式修改为每个执行单位为每个 Reduce阶段的 Task 生成一个文件。
执行单位对应为:每个 Mapper 端的 Cores 数/每个 Task分配的 Cores 数(默认为 1) 。最终可以将文件个数从 M*R 修改为 E*C/T*R,其中,E 表示 Executors 个数, C 表示可用 Cores 个数, T 表示 Task 分配的 Cores 数。
Spark1.1 版本引入了 Sort Shuffle:
基于 Hash 的 Shuffle 的实现方式中,生成的中间结果文件的个数都会依赖于 Reduce 阶段的 Task 个数,即 Reduce 端的并行度,因此文件数仍然不可控,无法真正解决问题。为了更好地解决问题,在 Spark1.1 版本引入了基于 Sort 的 Shuffle 实现方式,并且在 Spark 1.2 版本之后,默认的实现方式也从基于 Hash 的 Shuffle,修改为基于 Sort 的 Shuffle 实现方式,即使用的 ShuffleManager 从默认的 hash 修改为 sort。
在基于 Sort 的 Shuffle 中,每个 Mapper 阶段的 Task 不会为每 Reduce 阶段的 Task 生成一个单独的文件,而是全部写到一个数据(Data)文件中,同时生成一个索引(Index)文件, Reduce 阶段的各个 Task 可以通过该索引文件获取相关的数据。避免产生大量文件的直接收益就是降低随机磁盘 I/0 与内存的开销。最终生成的文件个数减少到 2*M ,其中 M 表示 Mapper 阶段的 Task 个数,每个 Mapper 阶段的 Task 分别生成两个文件(1 个数据文件、 1 个索引文件),最终的文件个数为 M 个数据文件与 M 个索引文件。因此,最终文件个数是 2*M 个。
从 Spark 1.4 版本开始,在 Shuffle 过程中也引入了基于 Tungsten-Sort 的 Shuffie 实现方式,通 Tungsten 项目所做的优化,可以极大提高 Spark 在数据处理上的性能。(Tungsten 翻译为中文是钨丝)
注:在一些特定的应用场景下,采用基于 Hash 实现 Shuffle 机制的性能会超过基于 Sort 的 Shuffle 实现机制。
一张图了解下 Spark Shuffle 的迭代历史:
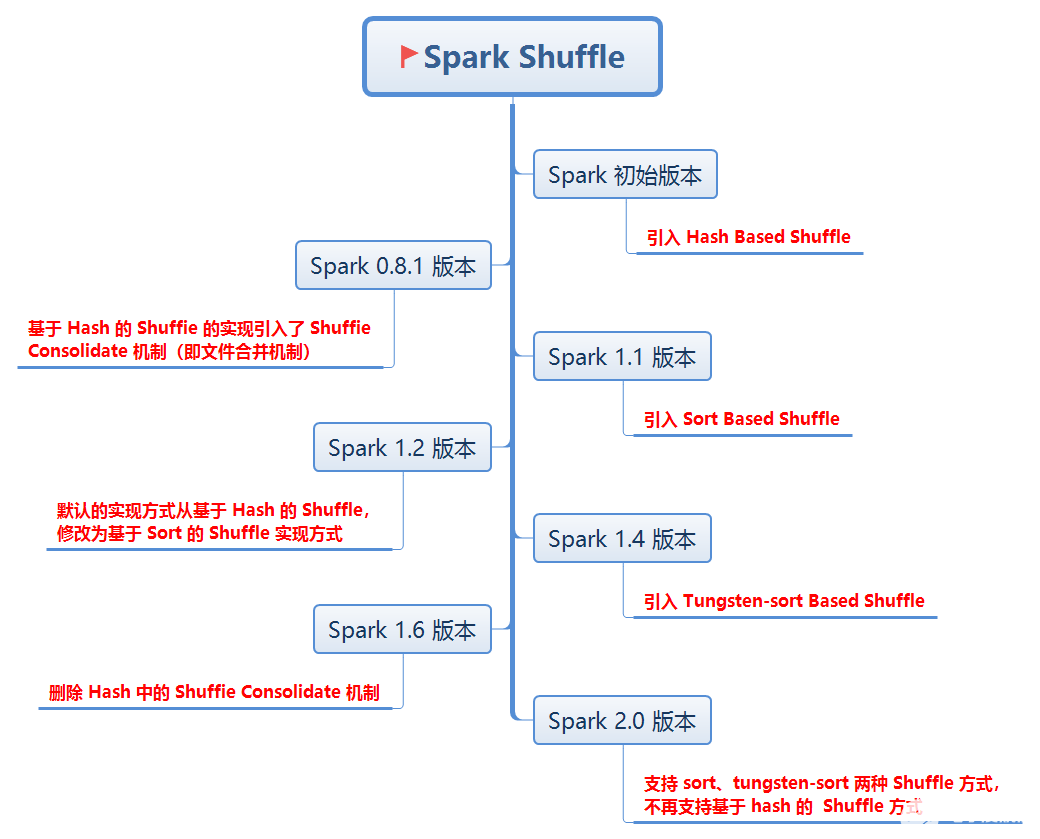
Spark Shuffle 迭代历史
为什么 Spark 最终还是放弃了 HashShuffle ,使用了 Sorted-Based Shuffle?
我们可以从 Spark 最根本要优化和迫切要解决的问题中找到答案,使用 HashShuffle 的 Spark 在 Shuffle 时产生大量的文件。当数据量越来越多时,产生的文件量是不可控的,这严重制约了 Spark 的性能及扩展能力,所以 Spark 必须要解决这个问题,减少 Mapper 端 ShuffleWriter 产生的文件数量,这样便可以让 Spark 从几百台集群的规模瞬间变成可以支持几千台,甚至几万台集群的规模。
但使用 Sorted-Based Shuffle 就完美了吗,答案是否定的,Sorted-Based Shuffle 也有缺点,其缺点反而是它排序的特性,它强制要求数据在 Mapper 端必须先进行排序,所以导致它排序的速度有点慢。好在出现了 Tungsten-Sort Shuffle ,它对排序算法进行了改进,优化了排序的速度。Tungsten-SortShuffle 已经并入了 Sorted-Based Shuffle,Spark 的引擎会自动识别程序需要的是 Sorted-BasedShuffle,还是 Tungsten-Sort Shuffle。
下面详细剖析每个 Shuffle 的底层执行原理:
一、Hash Shuffle 解析
以下的讨论都假设每个 Executor 有 1 个 cpu core。
1. HashShuffleManager
shuffle write 阶段,主要就是在一个 stage 结束计算之后,为了下一个 stage 可以执行 shuffle 类的算子(比如 reduceByKey),而将每个 task 处理的数据按 key 进行“划分”。所谓“划分”,就是对相同的 key 执行 hash 算法,从而将相同 key 都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游 stage 的一个 task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
下一个 stage 的 task 有多少个,当前 stage 的每个 task 就要创建多少份磁盘文件。比如下一个 stage 总共有 100 个 task,那么当前 stage 的每个 task 都要创建 100 份磁盘文件。如果当前 stage 有 50 个 task,总共有 10 个 Executor,每个 Executor 执行 5 个 task,那么每个 Executor 上总共就要创建 500 个磁盘文件,所有 Executor 上会创建 5000 个磁盘文件。由此可见,未经优化的 shuffle write 操作所产生的磁盘文件的数量是极其惊人的。
shuffle read 阶段,通常就是一个 stage 刚开始时要做的事情。此时该 stage 的每一个 task 就需要将上一个 stage 的计算结果中的所有相同 key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行 key 的聚合或连接等操作。由于 shuffle write 的过程中,map task 给下游 stage 的每个 reduce task 都创建了一个磁盘文件,因此 shuffle read 的过程中,每个 reduce task 只要从上游 stage 的所有 map task 所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read 的拉取过程是一边拉取一边进行聚合的。每个 shuffle read task 都会有一个自己的 buffer 缓冲,每次都只能拉取与 buffer 缓冲相同大小的数据,然后通过内存中的一个 Map 进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到 buffer 缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
HashShuffleManager 工作原理如下图所示:
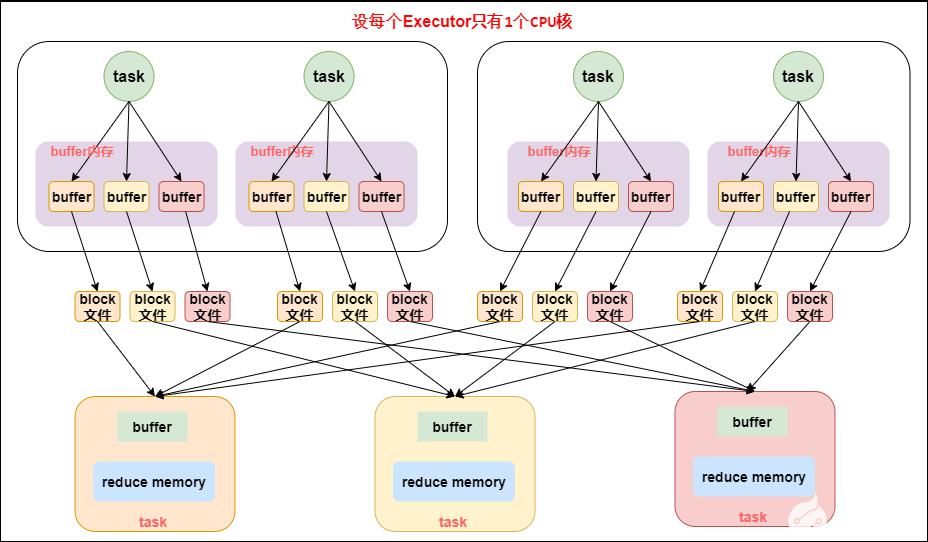
未优化的HashShuffleManager工作原理
2. 优化的 HashShuffleManager
为了优化 HashShuffleManager 我们可以设置一个参数:spark.shuffle.consolidateFiles,该参数默认值为 false,将其设置为 true 即可开启优化机制,通常来说,如果我们使用 HashShuffleManager,那么都建议开启这个选项。
开启 consolidate 机制之后,在 shuffle write 过程中,task 就不是为下游 stage 的每个 task 创建一个磁盘文件了,此时会出现shuffleFileGroup的概念,每个 shuffleFileGroup 会对应一批磁盘文件,磁盘文件的数量与下游 stage 的 task 数量是相同的。一个 Executor 上有多少个 cpu core,就可以并行执行多少个 task。而第一批并行执行的每个 task 都会创建一个 shuffleFileGroup,并将数据写入对应的磁盘文件内。
当 Executor 的 cpu core 执行完一批 task,接着执行下一批 task 时,下一批 task 就会复用之前已有的 shuffleFileGroup,包括其中的磁盘文件,也就是说,此时 task 会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate 机制允许不同的 task 复用同一批磁盘文件,这样就可以有效将多个 task 的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升 shuffle write 的性能。
假设第二个 stage 有 100 个 task,第一个 stage 有 50 个 task,总共还是有 10 个 Executor(Executor CPU 个数为 1),每个 Executor 执行 5 个 task。那么原本使用未经优化的 HashShuffleManager 时,每个 Executor 会产生 500 个磁盘文件,所有 Executor 会产生 5000 个磁盘文件的。但是此时经过优化之后,每个 Executor 创建的磁盘文件的数量的计算公式为:cpu core的数量 * 下一个stage的task数量,也就是说,每个 Executor 此时只会创建 100 个磁盘文件,所有 Executor 只会创建 1000 个磁盘文件。
这个功能优点明显,但为什么 Spark 一直没有在基于 Hash Shuffle 的实现中将功能设置为默认选项呢,官方给出的说法是这个功能还欠稳定。
优化后的 HashShuffleManager 工作原理如下图所示:
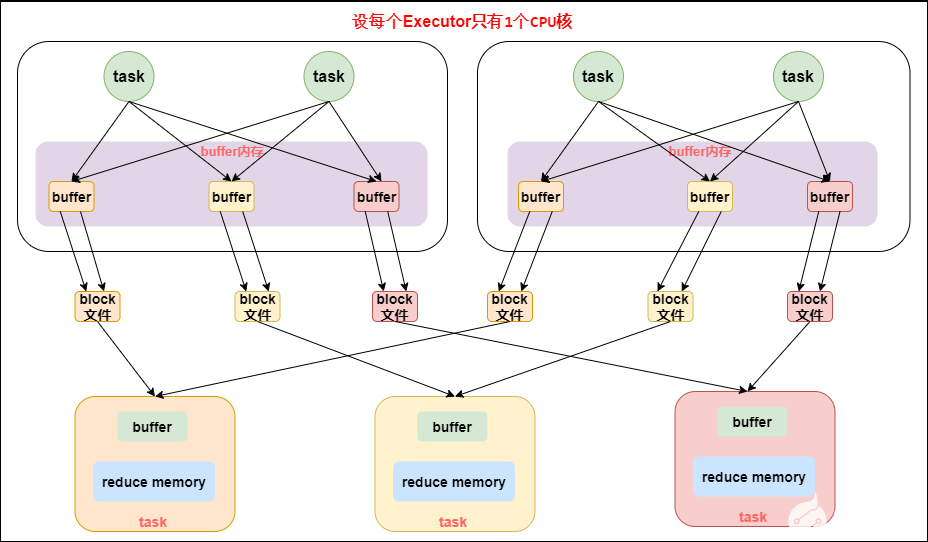
优化后的HashShuffleManager工作原理
基于 Hash 的 Shuffle 机制的优缺点
优点:
可以省略不必要的排序开销。
避免了排序所需的内存开销。
缺点:
生产的文件过多,会对文件系统造成压力。
大量小文件的随机读写带来一定的磁盘开销。
数据块写入时所需的缓存空间也会随之增加,对内存造成压力。
二、SortShuffle 解析
SortShuffleManager 的运行机制主要分成三种:
普通运行机制;
bypass 运行机制,当 shuffle read task 的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为 200),就会启用 bypass 机制;
Tungsten Sort 运行机制,开启此运行机制需设置配置项 spark.shuffle.manager=tungsten-sort。开启此项配置也不能保证就一定采用此运行机制(后面会解释)。
1. 普通运行机制
在该模式下,数据会先写入一个内存数据结构中,此时根据不同的 shuffle 算子,可能选用不同的数据结构。如果是 reduceByKey 这种聚合类的 shuffle 算子,那么会选用 Map 数据结构,一边通过 Map 进行聚合,一边写入内存;如果是 join 这种普通的 shuffle 算子,那么会选用 Array 数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据 key 对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的 batch 数量是 10000 条,也就是说,排序好的数据,会以每批 1 万条数据的形式分批写入磁盘文件。写入磁盘文件是通过 Java 的 BufferedOutputStream 实现的。BufferedOutputStream 是 Java 的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘 IO 次数,提升性能。
一个 task 将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是merge 过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个 task 就只对应一个磁盘文件,也就意味着该 task 为下游 stage 的 task 准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个 task 的数据在文件中的 start offset 与 end offset。
SortShuffleManager 由于有一个磁盘文件 merge 的过程,因此大大减少了文件数量。比如第一个 stage 有 50 个 task,总共有 10 个 Executor,每个 Executor 执行 5 个 task,而第二个 stage 有 100 个 task。由于每个 task 最终只有一个磁盘文件,因此此时每个 Executor 上只有 5 个磁盘文件,所有 Executor 只有 50 个磁盘文件。
普通运行机制的 SortShuffleManager 工作原理如下图所示:
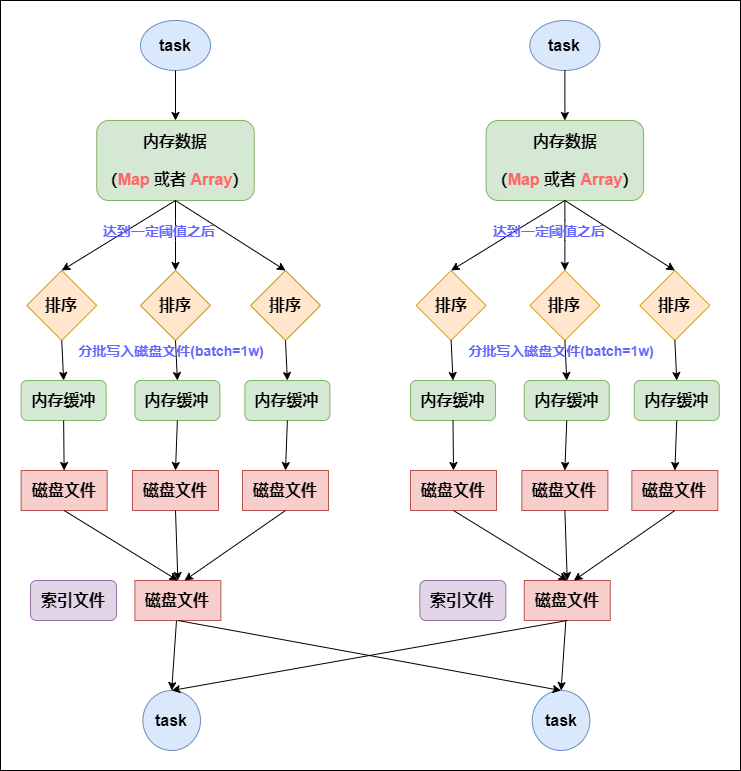
普通运行机制的SortShuffleManager工作原理
2. bypass 运行机制
Reducer 端任务数比较少的情况下,基于 Hash Shuffle 实现机制明显比基于 Sort Shuffle 实现机制要快,因此基于 Sort Shuffle 实现机制提供了一个带 Hash 风格的回退方案,就是 bypass 运行机制。对于 Reducer 端任务数少于配置属性spark.shuffle.sort.bypassMergeThreshold设置的个数时,使用带 Hash 风格的回退计划。
bypass 运行机制的触发条件如下:
shuffle map task 数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。不是聚合类的 shuffle 算子。
此时,每个 task 会为每个下游 task 都创建一个临时磁盘文件,并将数据按 key 进行 hash 然后根据 key 的 hash 值,将 key 写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的 HashShuffleManager 是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager 来说,shuffle read 的性能会更好。
而该机制与普通 SortShuffleManager 运行机制的不同在于:第一,磁盘写机制不同;第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write 过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
bypass 运行机制的 SortShuffleManager 工作原理如下图所示:
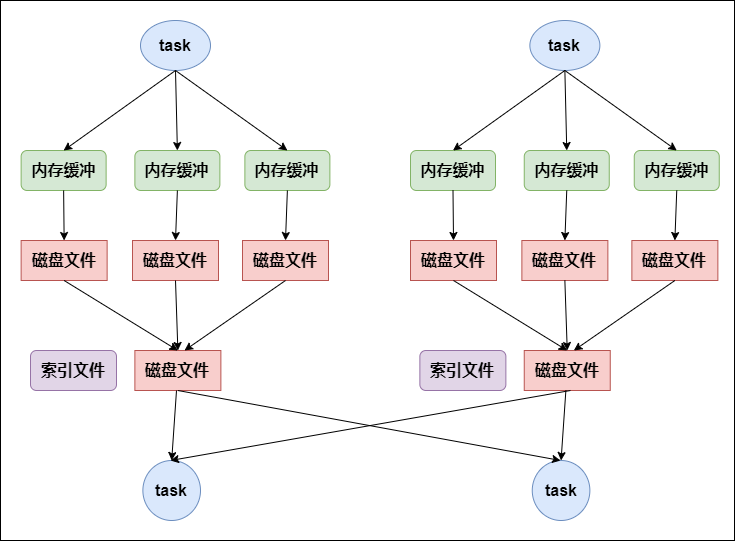
bypass运行机制的SortShuffleManager工作原理
3. Tungsten Sort Shuffle 运行机制
Tungsten Sort 是对普通 Sort 的一种优化,Tungsten Sort 会进行排序,但排序的不是内容本身,而是内容序列化后字节数组的指针(元数据),把数据的排序转变为了指针数组的排序,实现了直接对序列化后的二进制数据进行排序。由于直接基于二进制数据进行操作,所以在这里面没有序列化和反序列化的过程。内存的消耗大大降低,相应的,会极大的减少的 GC 的开销。
Spark 提供了配置属性,用于选择具体的 Shuffle 实现机制,但需要说明的是,虽然默认情况下 Spark 默认开启的是基于 SortShuffle 实现机制,但实际上,参考 Shuffle 的框架内核部分可知基于 SortShuffle 的实现机制与基于 Tungsten Sort Shuffle 实现机制都是使用 SortShuffleManager,而内部使用的具体的实现机制,是通过提供的两个方法进行判断的:
对应非基于 Tungsten Sort 时,通过 SortShuffleWriter.shouldBypassMergeSort 方法判断是否需要回退到 Hash 风格的 Shuffle 实现机制,当该方法返回的条件不满足时,则通过 SortShuffleManager.canUseSerializedShuffle 方法判断是否需要采用基于 Tungsten Sort Shuffle 实现机制,而当这两个方法返回都为 false,即都不满足对应的条件时,会自动采用普通运行机制。
因此,当设置了 spark.shuffle.manager=tungsten-sort 时,也不能保证就一定采用基于 Tungsten Sort 的 Shuffle 实现机制。
要实现 Tungsten Sort Shuffle 机制需要满足以下条件:
Shuffle 依赖中不带聚合操作或没有对输出进行排序的要求。
Shuffle 的序列化器支持序列化值的重定位(当前仅支持 KryoSerializer Spark SQL 框架自定义的序列化器)。
Shuffle 过程中的输出分区个数少于 16777216 个。
实际上,使用过程中还有其他一些限制,如引入 Page 形式的内存管理模型后,内部单条记录的长度不能超过 128 MB (具体内存模型可以参考 PackedRecordPointer 类)。另外,分区个数的限制也是该内存模型导致的。
所以,目前使用基于 Tungsten Sort Shuffle 实现机制条件还是比较苛刻的。
-
二进制
+关注
关注
2文章
795浏览量
41643 -
磁盘
+关注
关注
1文章
375浏览量
25201 -
SPARK
+关注
关注
1文章
105浏览量
19893
发布评论请先 登录
相关推荐
详解Zynq的两种启动模式

山西嵌入式系统课程| Spark与Hadoop计算模型之Spark比Hadoop更...
两种典型的ADRC算法介绍
苹果音乐播放器走到尽头:关闭iPod Nano和Shuffle两条产品线
苹果宣布停售iPod nano/shuffle iPod nano/shuffle全回顾:伤心到讲不出再见

详解PMSM中常用的两种坐标变换
NVIDIA 携手腾讯开发和优化 Spark UCX 实现性能跃升





 工商网监
工商网监
评论