 FS-NER 的关键挑战
FS-NER 的关键挑战
小样本 NER 需要从很少的实例和外部资源中获取有效信息。本文提出了一个自描述机制,可以通过使用全局概念集(universal concept set)描述实体类型(types)和提及(mentions)来有效利用实例和外部资源的知识。
具体来讲,我们设计了自描述网络(SDNet),一个 Seq2Seq 的生成模型可以使用概念来全局地描述提及,自动将新的实体类型映射到概念中,然后对实体进行识别。SDNet 在一个大规模语料中预训练,在 8 个 benchmarks 上进行实验,实验结果表明,SDNet 取得了很有竞争力的效果,并且在 6 个 benchmarks 上达到了 SOTA。
Intro
小样本 NER(FS-NER)的目标是通过很少的样本来识别出属于新实体类的实体提及。FS-NER 面临两个主要的挑战:
1. limited information challenge:少量样本所包含的语义信息有限。
2. knowledge mismatch challenge:使用外部的知识直接与新任务进行匹配可能有各种偏差甚至产生冲突。
具体来说,在 Wikipedia,OntoNotes 和 WNUT17 中,“America” 的标注分别为 “geographic entity”、“GPE” 和 “location”。因此,如何有效利用少量数据并且准确迁移外部知识是 FS-NER 的关键挑战。
为此,作者提出了自描述机制,其主要思想是将所有的实体类型描述为同一个概念集,类型和概念之间的映射是可以建模和学习的,这种方式可以解决知识不匹配的问题。同时,因为这种映射是全局的,对于少量新实体类样本来说,只需要将这部分数据用来构建新实体类型和概念之间的映射,也解决了信息不足的问题。
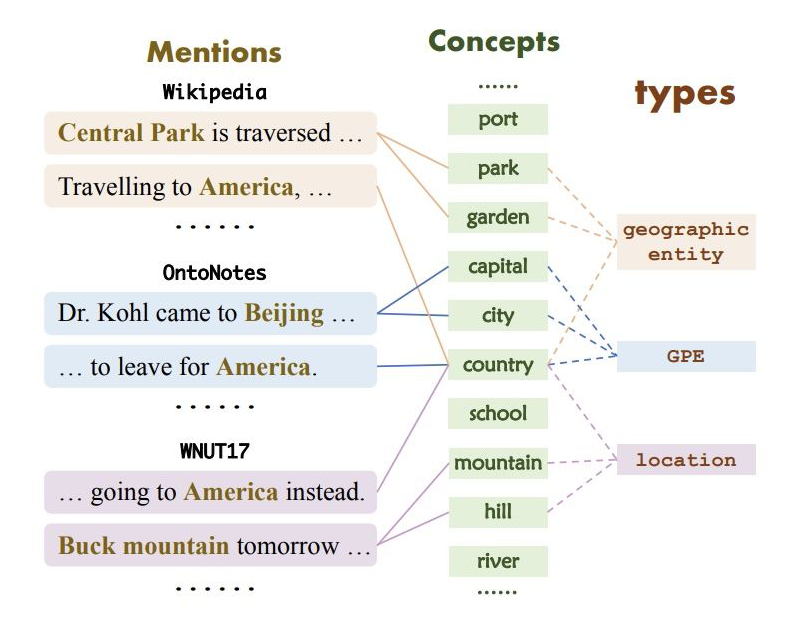
▲ 实体类型、提及和概念映射示例
基于以上想法,我们提出了一个自描述网络——SDNet,是一个 Seq2Seq 的生成模型,可以全局的使用概念来描述提及,自动将新实体类型映射到概念集,并且能够识别实体。
具体来讲,为了获取一个提及的语义,SDNet 生成一个全局的概念集作为描述。例如:生成 {capital,city} 对于句子“Dr。Kohl came to [Beijing].”。为了映射实体类型和概念,SDNet 将属于同一实体类型的提及映射到这些提及所对应的概念中。例如:对于 [Beijing] 和 [America] 两个属于 GPE 类型的提及,将 GPE 这一类型映射到 {country,capital,city}。
对于实体识别,SDNet 使用 concept-enriched 的前缀 prompt 的方式直接在一个句子中生成出所有的实体。例如:在 “France is beautiful.” 这句话中通过生成出 “France is GPE.” 来识别实体,构建一个前缀 prompt“[EG] GPE:{country,capital,city}”。因为概念是全局的,所以我们可以在 SDNet上使用大规模语料库预训练,并且可以很容易的使用 web 资源,具体来说,我们通过使用 wikipedia 锚词到 wikidata items 之间的连接构建了包含 56M 个句子,31K 个概念的数据集。
本文的主要贡献总结如下:
1. 我们提出了自描述机制来解决 FS-NER 问题,可以有效解决信息限制和知识不匹配的挑战通过使用一个全局的概念集描述实体类型和提及;
2. 我们提出 SDNet,一个可以全局的使用概念描述提及,自动映射新实体类型和概念并且识别实体的 Seq2Seq 生成模型;
3. 我们在一个大规模的公开数据集上预训练 SDNet,对 FS-NER 提供了全局信息并且对未来 NER 的研究有益。
Method
模型整体流程包含两部分:
1. Mention describing:生成提及的概念描述;
2. Entity generation:生成属于新实体类的提及。
模型结构图如下:
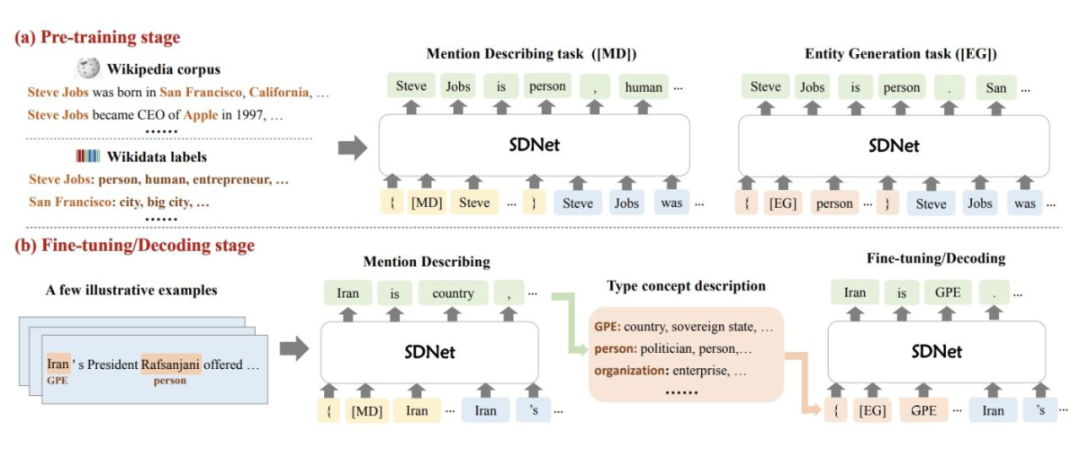
▲ 模型结构
2.1 Self-describing Networks
SDNet 可以完成两个生成任务,就是上文提到的 mention describing 和 entity generation,分别使用了不同的提示 P 并且生成不同的输出 Y。具体形式如下图所示:
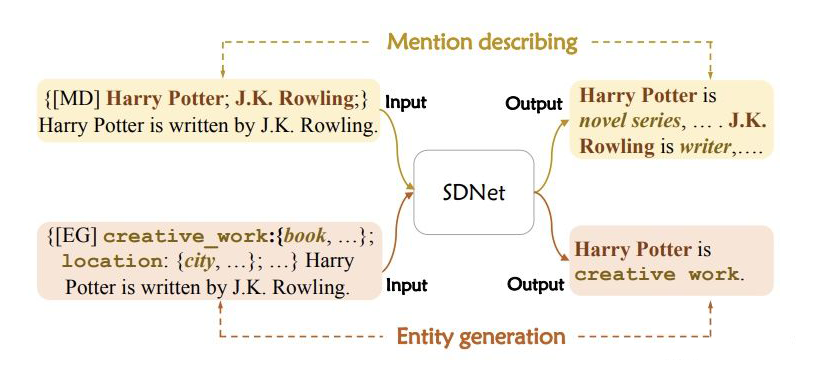
▲mention describing和entity generation示例
对于 mention describing,提示模板由一个标识 [MD] 和一个目标实体提及组成;对于 entity generation,提示模板由标识 [EG] 和一个新实体类型和其对应的描述组成。上述两个过程是一组对称的过程:一个是给定实体提及,获取其概念描述;另一个是识别包含特定概念的实体。
2.2 Entity Recognition via Entity Generation
具体来讲,entity generation 的输入提示为
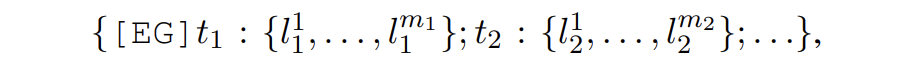
其中 t 是实体类型,l 是实体类型对应的概念。SDNet 会生成如下形式的输出:
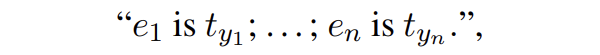
这里就相当于获取了每个实体对应的实体类型:
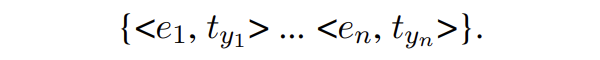
可以看出,SDNet 可以实时进行控制,通过使用不同的 prompts。例如:给一个句子 “Harry Potter is written by J.K. Rowling.”,如果想要识别 person 类,提示模板采用 {[EG] person: {actor, writer}},如果想要识别 creative work 类,则模板采用 {[EG] creative work: {book, music}} 即可。
2.3 Type Description Construction via Mention Describing
Mention Describing
给定一个句子 X,包含新类的实体提及{e1, e2, ...},使用的提示模板为:
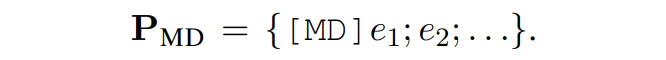
SDNet 会产生如下形式的输出:
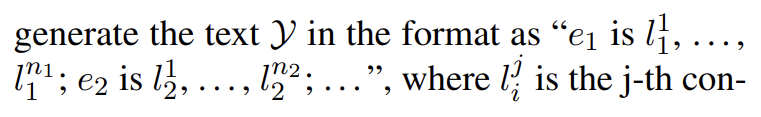
这一步会生成每个实体提及的概念。
Type Description Construction
SDNet 会将属于同一实体类型的提及生成的概念,融合成一个概念集合 C,将这个概念集合 C 作为类型 t 的描述。
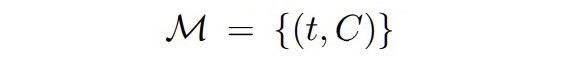
Filtering Strategy
由于下游任务含有大量新的实体类型,SDNet 对于其中某些类型没有足够的知识来描述,如果强制进行生成会导致一些不准确的描述。本文提出一个过滤策略解决这个问题。具体来讲,SDNet 会对那些不确定的样本生成 other 这一描述。我们会计算生成 other 描述的概率,如果对于一个样本生成的 other 超过 0.5,则会去除掉类型描述,在 P_EG 模板中直接使用类型。
Learning
接下来说明 SDNet 如何进行预训练和微调。
3.1 SDNet Pre-training
本文使用 wikipedia 和 wikidata 数据来构建数据集。
Entity Mention Collection
对于 SDNet 的预训练,我们需要收集
1. 首先,从 wikidata 中构建实体字典。我们将 wikidata 中每个 item 作为实体并且使用 “instance of”、“subclass of” 和 “occupation” 三个属性值作为其对应的实体类型。我们使用所有的实体类型,除去那些实例少于 5 个的。对于那些类型名长度超过 3 个 token 的,采用其 head word 作为最终的实体类型来简化。通过这种方式,我们收集了 31K 个类型;
2. 其次我们使用其在 wikipedia 中的锚文本和其条目页面的前 3 个频繁出现的名词短语来收集每个实体的提及。然后对于每一个提及,通过将其连接到 wikidata 中 item 的类型来识别实体类型。如果 wikidata 的 item 没有实体类型,则给其分配 other。对于每一个百科页,将文本分割成句子,并且将没有实体的句子过滤掉。最终我们构建出了含有 56M 个实例的数据集。
Type Description Building
文本将上述获取的实体类型作为概念,对于给定的一个实体类型,使用与其共同出现的实体类型作为其描述。举例来说,Person 类可以描述为 {businessman, CEO, musician, pianist} 通过以下两个实例 “Steve Jobs:{person, businessman, CEO}” 和 “Beethoven:{person, musician, pianist}”。通过这种方式生成每个实体类型的描述概念集。因为有些类型的概念集特别大,因此本文为每个实体随机采样不超过 10 个概念作为概念集合。
Pretraining via Mention Describing and Entity Generation
给定一个句子 X 以及它的提及-类型元组:
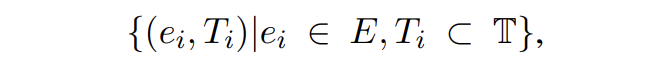
我们从 E 中采样一些目标提及 E' 输入到模板 P_MD 中生成它的对应概念。对于实体生成,从正类型和负类型中采样类型集输入到模板 P_EG 中生成提及对应的实体类型。模型损失如下:
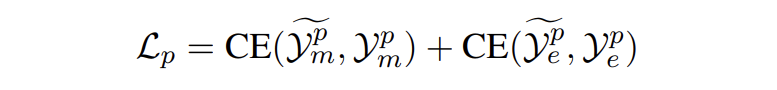
▲ 交叉熵损失
3.2 Entity Recognition Fine-tuning
微调阶段给定一个样本三元组
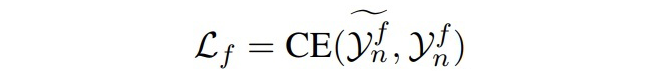
▲EG过程的损失
Experiments
4.1 主实验
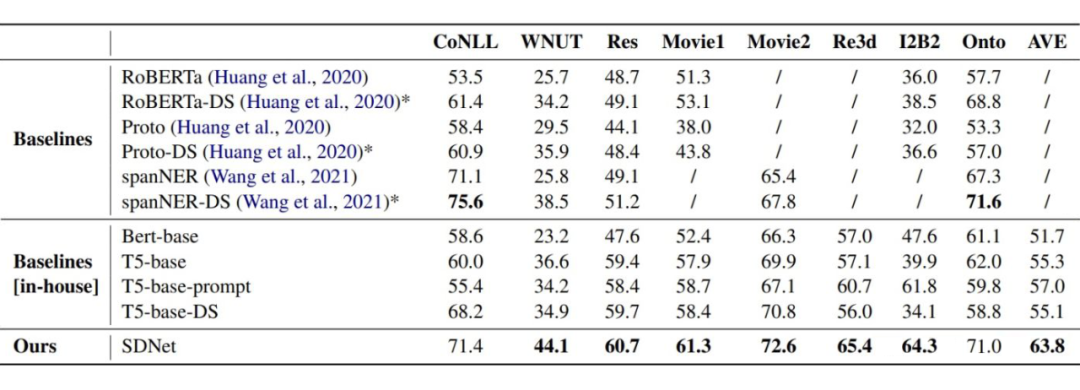
▲ 主实验,评价指标采用 micro-F1
实验结果可以看出,在 6 个 benchmark 中 SDNet 达到了 SOTA。作者也分析了在 Res 这一 benchmark 上与 T5 表现接近的原因,因为 Res 与 wikipedia 数据有巨大的领域漂移,导致模型经常生成 other。
4.2 样本数的影响
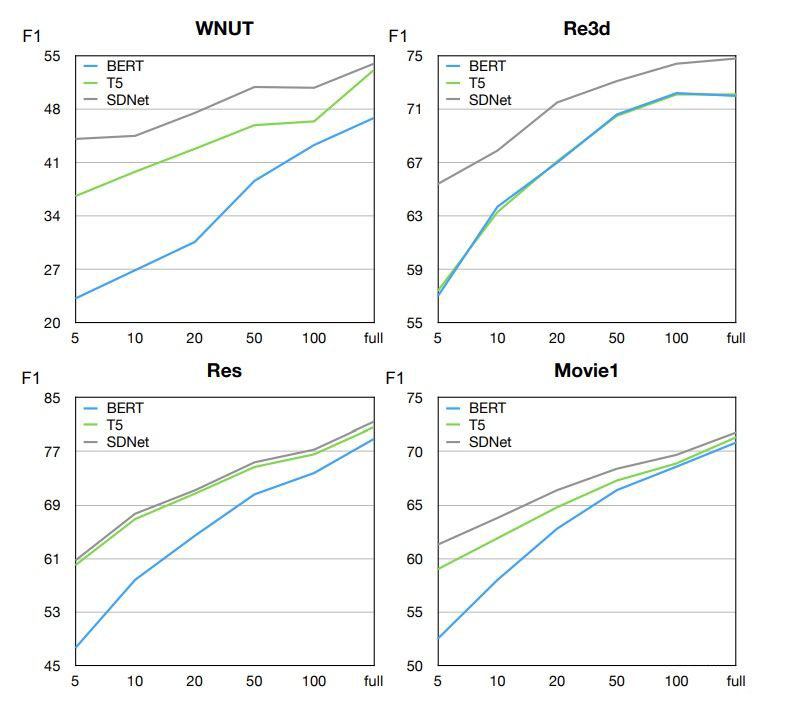
▲ 样本数的影响
实验结果可以看出,SDNet 在任何样本数设置下都有更好的表现。作者认为,基于生成的模型要比基于分类的模型有更好的表现,因为生成模型可以利用标签的 utterance 更有效的获取实体类型的语义。
4.3 消融实验
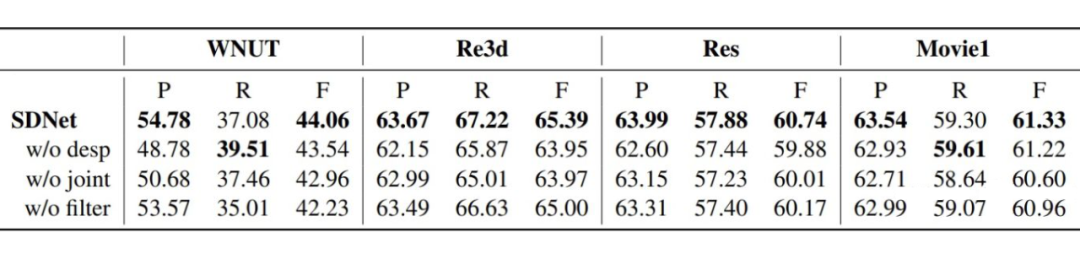
(1)w/o desp:在EG过程直接使用实体类型,而不加入全局的概念描述,例如:
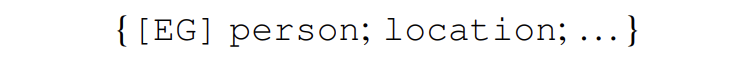
(2)w/o joint:将 MD 和 EG 过程分为两个单独的过程分开训练。
(3)w/o filter:不进行过滤策略。
4.4 零样本实验
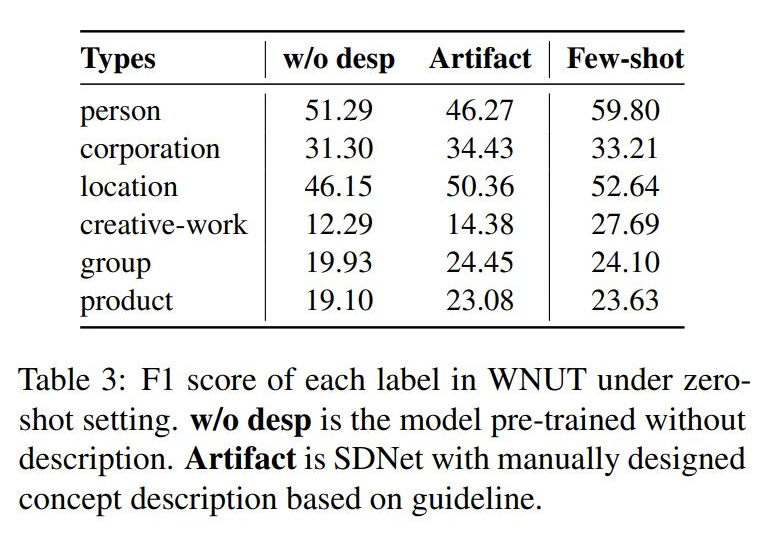
4.4 EG模板的影响

总结
本文一大优点是为 FS-NER 引用外部知识提供了一个新的思路,本文的预训练模型也可以直接做迁移。
不足之处在于在与 Wikipedia 之间存在巨大的领域漂移的情况下,模型会生成大量 other 从而严重影响效果。在维基百科中可能存在大量人名地名等常见实体,而在一些实际问题中,可能存在很多不常见的实体,模型可能很难对这些实体做到很好的描述。
-
数据
+关注
关注
8文章
7017浏览量
89010 -
模型
+关注
关注
1文章
3241浏览量
48833
原文标题:ACL2022 | 自描述网络的小样本命名实体识别
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
光学传感器的系统NER模拟

一些NER的英文数据集推荐
一种单独适配于NER的数据增强方法
如何解决NER覆盖和不连续问题
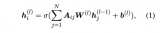







 工商网监
工商网监
评论