 使用NVIDIA Flare 2.1测试新型分布式应用程序
使用NVIDIA Flare 2.1测试新型分布式应用程序
NVIDIA FLARE ( NVIDIA Federated Learning Application Runtime Environment , NVIDIA 联邦学习应用程序运行时环境)是一个用于协作计算的开源 Python SDK 。 FLARE 设计有一个组件化体系结构,允许研究人员和数据科学家将机器学习、深度学习或一般计算工作流调整为联合范式,以实现安全、隐私保护的多方协作。
此体系结构提供了用于安全地配置联合、建立安全通信以及定义和编排分布式计算工作流的组件。 FLARE 在一个可扩展的 API 中提供了这些组件,该 API 允许定制以适应现有的工作流或轻松试验新的分布式应用程序。

图 1 :高级 NVIDIA FLARE 体系结构
图 1 显示了具有基础 API 组件的高级 FLARE 体系结构,包括用于保护隐私和安全管理平台的工具。在此基础之上是联邦学习应用程序的构建块,以及一组联邦工作流和学习算法。
除了核心 FLARE 堆栈之外,还有一些工具,这些工具允许使用 FL Sim ulator 进行实验和概念验证( POC )开发,以及一组用于部署和管理生产工作流的工具。
在这篇文章中,我将重点介绍如何开始使用简单的 POC ,并概述从 POC 过渡到安全的生产部署的过程。我还强调了从本地 POC 迁移到分布式部署时的一些注意事项。
NVIDIA FLARE 入门
为了帮助您开始使用 NVIDIA FLARE ,我将介绍该平台的基本知识,并重点介绍版本 2.1 中的一些功能,这些功能可以帮助您将概念验证引入生产联合学习工作流。
安装
开始使用 NVIDIA FLARE 的最简单方法是在 Quickstart 中所述的 Python 虚拟环境中。
只需几个简单的命令,就可以准备一个 FLARE 工作区,该工作区支持独立服务器和客户端的本地部署。此本地部署可用于运行 FLARE 应用程序,就像它们在安全的分布式部署上运行一样,无需配置和部署开销。
$ sudo apt update $ sudo apt install python3-venv $ python3 -m venv nvflare-env $ source nvflare-env/bin/activate (nvflare-env) $ python3 -m pip install -U pip setuptools (nvflare-env) $ python3 -m pip install nvflare
准备 POC 工作区
安装了 nvflare pip 包后,您现在可以访问 poc 命令。执行此命令时所需的唯一参数是所需的客户端数。
(nvflare-env) $ poc -h usage: poc [-h] [-n NUM_CLIENTS] optional arguments: -h, --help show this help message and exit -n NUM_CLIENTS, --num_clients NUM_CLIENTS number of client folders to create
执行此命令后,例如,对于两个客户端执行poc -n 2,您将拥有一个 POC 工作区,其中包含每个参与者的文件夹:管理客户端、服务器和站点客户端。
(nvflare-env) $ tree -d poc poc ├── admin │ └── startup ├── server │ └── startup ├── site-1 │ └── startup └── site-2 └── startup
每个文件夹都包含启动和连接联合所需的配置和脚本。默认情况下,服务器配置为在本地主机上运行,站点客户端和管理客户端分别在端口 8002 和 8003 上连接。您可以在后台运行服务器和客户端,例如:
(nvflare-env) $ for i in poc/{server,site-1,site-2}; do \ ./$i/startup/start.sh; \
done
服务器和客户端进程将状态消息发送到标准输出,并记录到它们自己的poc/{server,site-?}/log.txt文件。如前所示启动时,此标准输出是交错的。您可以在单独的终端中启动每个端口,以防止这种交叉输出。
部署 FLARE 应用程序
连接服务器和站点客户端后,可以使用管理客户端管理整个联合。在深入管理客户端之前,请从 NVIDIA FLARE GitHub 存储库中设置一个示例。
(nvflare-env) $ git clone https://github.com/NVIDIA/NVFlare.git (nvflare-env) $ mkdir -p poc/admin/transfer (nvflare-env) $ cp -r NVFlare/examples/hello-pt-tb poc/admin/transfer/
这会将Hello PyTorch with Tensorboard Streaming示例复制到管理客户端的传输目录中,将其暂存以部署到服务器和站点客户端。有关更多信息,请参阅快速启动( PyTorch with TensorBoard).
在部署之前,还需要安装一些必备组件。
(nvflare-env) $ python3 -m pip install torch torchvision tensorboard
现在您已经准备好了应用程序,可以启动管理客户端了。
(nvflare-env) $ ./poc/admin/startup/fl_admin.sh Waiting for token from successful login... Got primary SP localhost:8002:8003 from overseer. Host: localhost Admin_port: 8003 SSID: ebc6125d-0a 56-4688-9b08-355fe9e4d61a login_result: OK token: d50b9006-ec21-11ec-bc73-ad74be5b77a4 Type ? to list commands; type "? cmdName" to show usage of a command. >
连接后,管理客户端可用于检查服务器和客户端的状态、管理应用程序和提交作业。
对于本例,提交hello-pt-tb应用程序以执行。
> submit_job hello-pt-tb Submitted job: 303ffa9c-54ae-4ed6-bfe3-2712bc5eba40
此时,您将看到作业提交确认和作业 ID ,以及服务器和客户端终端上的状态更新,这些更新显示了执行培训时服务器控制器和客户端执行器的进度。
您可以使用list_jobs命令检查作业的状态。作业完成后,使用download_job命令从服务器下载作业结果。
> download_job 303ffa9c-54ae-4ed6-bfe3-2712bc5eba40 Download to dir poc/admin/startup/../transfer
然后,可以使用下载的作业目录作为 TensorBoard 日志目录来启动 TensorBoard 。
(nvflare-env) $ tensorboard \ --logdir=poc/admin/transfer
这将使用从客户端流到服务器并保存在服务器运行目录中的日志启动本地 TensorBoard 服务器。您可以打开 http://localhost:6006 的浏览器以可视化运行。
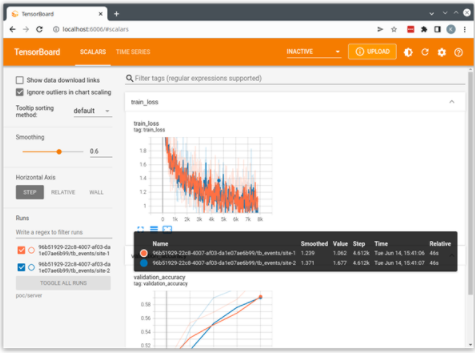
图 2 :来自的张力板输出示例 hello-pt-tb application
NVIDIA FLARE 提供的 example applications 均设计为使用此 POC 模式,可以作为开发自定义应用程序的起点。
一些示例,如 CIFAR10 example ,定义了端到端工作流,突出显示 NVIDIA FLARE 中可用的不同功能和算法,并使用 POC 模式,以及下一节讨论的安全资源调配。
从概念验证转移到生产
NVIDIA FLARE v2.1 引入了一些新的概念和功能,旨在实现强健的生产联合学习,其中最明显的两个是高可用性和对多作业执行的支持。
高可用性( HA ) 支持多个 FL 服务器,并在当前活动服务器不可用时自动激活备份服务器。这由联合体中的一个新实体监管者管理,监管者负责监控所有参与者的状态,并在需要时协调到备份服务器的切换。
Multi-job execution 通过允许并发运行,支持基于资源的多作业执行,前提是满足作业所需的资源。
具有高可用性的安全部署
上一节介绍了 FLARE 的 POC 模式,其中禁用了安全功能以简化本地测试和实验。
为了演示生产部署的高可用性,请再次从 POC 模式中使用的单一系统部署开始,并在 OpenProvision API 中引入 provisioning 的概念。
Sim NVIDIA FLARE 提供了provision命令来驱动 OpenProvision API 。provision命令读取项目。配置安全部署中使用的参与者和组件的 yml 文件。此命令可以在没有参数的情况下使用,以创建 sample project.yml 的副本作为起点。
对于这篇文章,继续使用与上一节中配置的相同的nvflare-venv Python 虚拟环境。
(nvflare-env) $ provision No project.yml found in current folder. Is it OK to generate one for you? (y/N) y project.yml was created. Please edit it to fit your FL configuration.
为了安全部署,必须首先配置联合体中的参与者。您可以修改示例文件project.yml的participants部分,以创建一个简单的本地部署,如下所示。来自默认项目的更改。 yml 文件以粗体文本显示。
participants: # change overseer.example.com to the FQDN of the overseer - name: overseer type: overseer org: nvidia protocol: https api_root: /api/v1 port: 8443 # change example.com to the FQDN of the server - name: server1 type: server org: nvidia fed_learn_port: 8002 admin_port: 8003 # enable_byoc loads python codes in app. Default is false. enable_byoc: true components: <<: *svr_comps - name: server2 type: server org: nvidia fed_learn_port: 9002 admin_port: 9003 # enable_byoc loads python codes in app. Default is false. enable_byoc: true components: <<: *svr_comps - name: site-1 type: client org: nvidia enable_byoc: true components: <<: *cln_comps - name: site-2 type: client org: nvidia enable_byoc: true components: <<: *cln_comps # You can also override one component with a different one resource_manager: # This id is reserved by system. Do not change it. path: nvflare.app_common.resource_managers.list_resource_manager.ListResourceManager args: resources: gpu: [0, 1] - name: admin@nvidia.com type: admin org: nvidia roles: - super
定义参与者有几个要点:
-
每个参与者的名称必须唯一。就监管者和服务器而言,所有服务器和客户端都必须能够解析这些名称,可以是完全限定的域名,也可以是使用
/etc/hosts的主机名(后面会有更多介绍)。 - 对于本地部署,服务器必须为 FL 和 admin 使用唯一的端口。如果服务器在单独的系统上运行,则分布式部署不需要此功能。
-
参与者应将
enable_byoc: true设置为允许在/custom文件夹中部署带有代码的应用程序,如示例应用程序中所示。
project.yml文件的其余部分配置了定义 FLARE 工作区的builder modules。现在可以将这些保留在默认配置中,但在从安全的本地部署转移到真正的分布式部署时需要考虑一些问题。
修改后的项目。 yml ,您现在可以为参与者提供安全的启动工具包。
(nvflare-env) $ provision -p project.yml Project yaml file: project.yml. Generated results can be found under workspace/example_project/prod_00. Builder's wip folder removed. $ tree -d workspace/ workspace/ └── example_project ├── prod_00 │ ├── admin@nvidia.com │ │ └── startup │ ├── overseer │ │ └── startup │ ├── server1 │ │ └── startup │ ├── server2 │ │ └── startup │ ├── site-1 │ │ └── startup │ └── site-2 │ └── startup ├── resources └── state
与 POC 模式一样,资源调配会生成一个工作区,其中包含每个参与者的启动工具包以及每个参与者的 zip 文件。 zip 文件可用于在分布式部署中轻松分发启动工具包。每个工具包都包含 POC 模式下的配置和启动脚本,并添加了一组共享证书,用于在参与者之间建立身份和安全通信。
在安全资源调配中,对这些启动工具包进行签名以确保它们未被修改。查看 server1 的启动工具包,您可以看到这些附加组件。
(nvflare-env) $ tree workspace/example_project/prod_00/server1 workspace/example_project/prod_00/server1 └── startup ├── authorization.json ├── fed_server.json ├── log.config ├── readme.txt ├── rootCA.pem ├── server.crt ├── server.key ├── server.pfx ├── signature.json ├── start.sh ├── stop_fl.sh └── sub_start.sh
要连接参与者,所有服务器和客户端必须能够解析project.yml中定义的名称处的服务器和监管者。对于分布式部署,这可能是一个完全限定的域名。
您还可以在每个服务器和客户端系统上使用/etc/hosts将服务器和监管者名称映射到其 IP 地址。对于此本地部署,请使用/etc/hosts重载环回接口。例如,以下代码示例为监督者和两个服务器添加了条目:
(nvflare-env) $ cat /etc/hosts 127.0.0.1 localhost 127.0.0.1 overseer 127.0.0.1 server1 127.0.0.1 server2
因为监管者和服务器都使用唯一的端口,所以您可以在本地 127.0.0.1 界面上安全地运行所有端口。
与上一节一样,您可以循环访问参与者集,以执行启动工具包中包含的start.sh脚本,以连接监管者、服务器和站点客户端。
(nvflare-env) $ export WORKSPACE=workspace/example_project/prod_00/
(nvflare-env) $ for i in $WORKSPACE/{overseer,server1,server2,site-1,site-2}; do \ ./$i/startup/start.sh & \
done
从这里开始,使用管理客户端部署应用程序的过程与在 POC 模式下相同,但有一个重要的更改。在安全资源调配中,管理客户端会提示输入用户名。在此示例中,用户名为admin@nvidia.com,如project.yml中所配置。
安全、分布式部署的注意事项
在前面的部分中,我讨论了 POC 模式和在单个系统上的安全部署。这种单一系统部署消除了真正安全的分布式部署的许多复杂性。在单个系统上,您可以享受共享环境、共享文件系统和本地网络的好处。分布式系统上的生产 FLARE 工作流必须解决这些问题。
一致的环境
联盟中的每个参与者都需要 NVIDIA FLARE 运行时,以及服务器和客户端工作流中实现的任何依赖项。这很容易在具有 Python 虚拟环境的本地部署中实现。
当运行分布式时,环境不容易约束。解决这个问题的一种方法是在容器中运行。对于前面的示例,您可以创建一个简单的 Dockerfile 来捕获依赖项。
ARG PYTORCH_IMAGE=nvcr.io/nvidia/pytorch:22.04-py3
FROM ${PYTORCH_IMAGE} RUN python3 -m pip install -U pip
RUN python3 -m pip install -U setuptools
RUN python3 -m pip install torch torchvision tensorboard nvflare WORKDIR /workspace/
RUN git clone https://github.com/NVIDIA/NVFlare.git
sample project.yml文件中引用的 WorkspaceBuilder 包含一个用于定义 Docker 映像的变量:
# when docker_image is set to a Docker image name, # docker.sh is generated on server/client/admin docker_image: nvflare-pyt:latest
当在 WorkspaceBuilder 配置中定义了docker_image时,设置会在每个启动工具包中生成一个docker.sh脚本。
假设此示例 Dockerfile 已在标记为 n vflare-pyt:latest的每个服务器、客户端和管理系统上构建,则可以使用docker.sh脚本启动容器。这将启动容器,其中映射了启动工具包并准备运行。当然,这需要 Docker 以及服务器和客户端主机系统上的适当权限和网络配置。
另一种选择是提供要求。 txt 文件,如许多联机示例所示,可以在运行分布式启动工具包之前将其安装在nvflare-venv虚拟环境中。
分布式系统
在到目前为止讨论的 POC 和安全部署环境中,我们假设了一个单一的系统,您可以在其中利用本地共享文件系统,并且通信仅限于本地网络接口。
在分布式系统上运行时,必须解决这些简化问题以建立联邦系统。图 3 显示了具有高可用性的分布式部署所需的组件,包括管理客户端、监管者、服务器和客户端系统之间的关系。
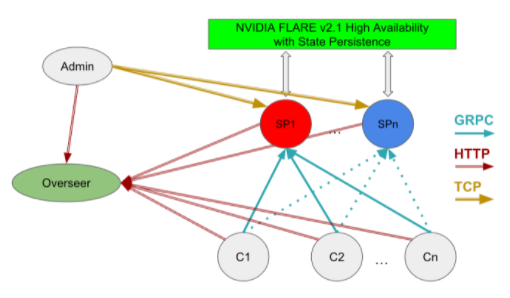
图 3 : NVIDIA FLARE 高可用性部署( HA )
在此模型中,您必须考虑以下因素:
Network: 客户端系统必须能够在其完全限定的域名或通过将 IP 地址映射到主机名来解析监督者和服务提供商。
Storage: 服务器系统必须能够访问共享存储,以便于从活动(热)服务提供商处进行切换,如project.yml文件snapshot_persistor中所定义。
向每位参与者分发配置或启动工具包
应用程序配置和客户端数据集的位置
如前一节所述,可以通过在容器化环境中运行来解决其中的一些问题,其中启动工具包和数据集可以安装在每个系统上的一致路径上。
分布式部署的其他方面取决于主机系统和网络的本地环境,必须单独解决。
总结
NVIDIA FLARE v2.1 提供了一套强大的工具,使研究人员或开发人员能够将联合学习概念引入到实际的生产工作流中。
这里讨论的部署场景基于我们自己构建 FLARE 平台的经验,以及我们早期采用者将联合学习工作流引入生产的经验。希望这些可以作为开发您自己的联邦应用程序的起点。
关于作者
Kris Kersten 是 NVIDIA 的解决方案架构师,专注于 AI ,致力于扩展 ML 和 DL 解决方案,以解决当今医疗领域最紧迫的问题。在加入 NVIDIA 之前, Kris 曾在 Cray 超级计算机公司工作,研究从低级缓存基准测试到大规模并行模拟的硬件和软件性能特征。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5041浏览量
103323 -
机器学习
+关注
关注
66文章
8428浏览量
132827 -
深度学习
+关注
关注
73文章
5508浏览量
121322
发布评论请先 登录
相关推荐
基于ptp的分布式系统设计
分布式、域控及SOA架构车身功能测试方案
HarmonyOS Next 应用元服务开发-分布式数据对象迁移数据权限与基础数据
分布式通信的原理和实现高效分布式通信背后的技术NVLink的演进

分布式光纤测温是什么?应用领域是?
分布式输电线路故障定位中的分布式是指什么

基于分布式计算的AR光波导中测试图像的仿真
鸿蒙开发接口数据管理:【@ohos.data.distributedData (分布式数据管理)】

分布式能源是什么意思?分布式能源有什么优势?
HarmonyOS开发实例:【分布式数据服务】
HarmonyOS实战案例:【分布式账本】
Docker在JMeter分布式测试中的作用





 工商网监
工商网监
评论