 语音AI简介
语音AI简介
人工智能( AI )已经将合成语音从单调的机器人呼叫和几十年前的 GPS 导航系统转变为智能手机和智能扬声器中虚拟助理的优美音调。
对于组织来说,为其特定行业和领域使用定制的最新语音 AI 技术从未如此容易。
语音 AI 正被用于 power 虚拟助理 ,扩展呼叫中心, 使数字化身人性化 , 增强 AR 体验 ,并通过自动化临床记录为患者提供无摩擦的医疗体验。
根据 Gartner Research ,到 2023 年,客户将倾向于使用语音接口启动 70% 的自助式客户互动 ( 2019 年为 40% )。对个性化和自动化体验的需求只会继续增长。
在这篇文章中,我将讨论语音 AI ,它是如何工作的,语音识别技术的好处,以及语音 AI 用例的示例。
什么是语音人工智能,其好处是什么?
语音 AI 将 AI 用于基于语音的技术:自动语音识别( ASR ),也称为语音对文本和文本对语音( TTS )。例如,虚拟会议中的自动实时字幕显示,以及向虚拟助理添加基于语音的界面。
Sim i 通常,基于语言的应用程序,如聊天机器人、文本分析和数字助理,将语音 AI 与自然语言处理( NLP )一起作为大型应用程序或系统的一部分。有关更多信息,请参阅 对话 AI 词汇表 。
语音 AI 有很多好处:
High availability :语音 AI 应用程序可以在人工代理时间内外响应客户呼叫,使联络中心能够更高效地运行。
Real-time insights: 实时记录被指定为以客户为中心的业务分析的输入,如情绪分析、客户体验分析和欺诈检测。
Instant scalability: 在高峰时,语音 AI 应用程序可以自动扩展,以处理客户的数万个请求。
Enhanced experiences :语音人工智能通过减少等待时间、快速解决客户查询并提供可定制语音界面的人性化交互,提高了客户满意度。
数字可访问性: 从语音到文本再到文本再到语音应用,语音 AI 工具正在帮助那些有阅读和听力障碍的人从生成的语音和书面文本中学习。
谁在使用语音 AI 以及如何使用?
今天,语音 AI 正在彻底改变世界上最大的行业,如金融、电信和统一通信即服务( UCaaS )。
从深度学习、基于语音的技术起步的公司以及扩展现有基于语音的 conversational AI 平台的成熟公司都受益于语音 AI 。
以下是语音 AI 提高效率和业务成果的一些具体示例。
呼叫中心转录
全球约有 1000 万呼叫中心代理 每天接听 20 亿个电话 。呼叫中心用例包括以下所有内容:
趋势分析
法规遵从性
实时安全或欺诈分析
实时情绪分析
实时翻译
例如,自动语音识别记录客户和呼叫中心代理之间的实时对话,以进行文本分析,然后用于为代理提供 快速解决客户查询 的实时建议。
临床记录
在医疗保健领域,语音 AI 应用程序改善了患者与医疗专业人员和理赔代表的联系。 ASR automates note-taking 在患者 – 医生对话和索赔代理信息提取期间。
虚拟助理
每个行业都有虚拟助理,可以增强用户体验。 ASR 用于为虚拟助手转录音频查询。然后,文本到语音
生成虚拟助理的合成语音。除了使交易情境人性化之外,虚拟助理还帮助视力受损者与非盲文文本、语音障碍者以及儿童进行互动。
语音 AI 是如何工作的?
语音 AI 使用自动语音识别和文本到语音技术为对话应用程序提供语音接口。典型的语音人工智能管道包括数据预处理阶段、神经网络模型训练和后处理。
在本节中,我将讨论 ASR 和 TTS 管道中的这些阶段。

图 3 :。对话 AI 应用的语音接口
自动语音识别
为了让机器能够听到并与人类对话,它们需要一种将声音转换为代码的通用媒介。设备或应用程序如何通过声音“看到”世界?
ASR pipeline 将包含语音的给定原始音频文件处理并转录为相应的文本,同时最小化称为 字错误率 ( WER )的度量。
WER 用于测量和比较不同类型的语音识别系统和算法的性能。它是由错误数除以正在转录的剪辑中的单词数来计算的。
ASR 管道必须完成一系列任务,包括特征提取、声学建模以及语言建模。
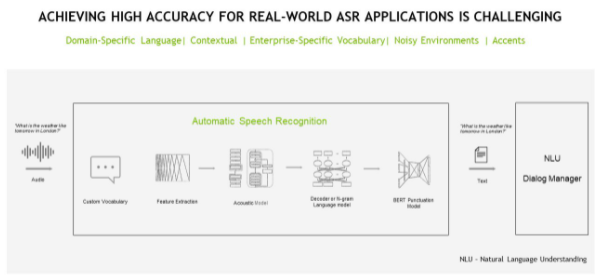
图 4 :。 ASR 管道
特征提取任务涉及将原始模拟音频信号转换为频谱图,频谱图是表示信号在不同频率下随时间变化的响度的视觉图表,类似于热图。转换过程的一部分涉及传统的信号预处理技术,如 standardization 和 windowing 。
然后使用 Acoustic modeling 来建模音频信号与语言中语音单位之间的关系。它将音频片段映射到最可能不同的语音单元和相应的字符。
ASR 管道中的最后一项任务涉及语言建模。 language model 添加了上下文表示并更正了声学模型的错误。换句话说,当您拥有声学模型中的字符时,您可以将这些字符转换为单词序列,这些单词可以进一步处理为短语和句子。
历史上,这一系列任务是使用生成方法执行的,该方法要求使用语言模型、发音模型和声学模型将发音转换为音频波形。然后,可以使用 高斯混合模型 或 隐马尔可夫模型 来尝试查找最可能与音频波形中的声音匹配的单词。
这种统计方法在实施和部署的时间和精力上不太准确,而且更加密集。当试图确保音频数据的每个时间步与字符的正确输出相匹配时,尤其如此。
然而,端到端的深度学习模型,如 连接主义时间分类 ( CTC )模型和 注意序列到序列模型 ,可以直接从音频信号生成转录本,并且具有较低的 WER 。
换言之, Jasper 、 QuartzNet 和 Citrinet 等基于深度学习的模型使公司能够创建成本更低、功能更强大、更精确的语音 AI 应用程序。
文本到语音
TTS 或 speech synthesis 管道负责将文本转换为自然发音的语音,这种语音是人工生成的,具有类似人类的语调和清晰的发音。
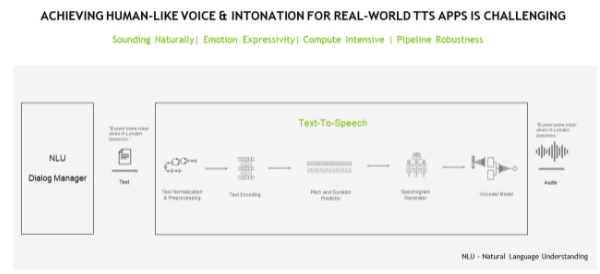
图 5 :。 TTS 管道
TTS 管道可能必须完成许多不同的任务,包括文本分析、 linguistic analysis 和波形生成。
在 text analysis 阶段,原始文本(带有符号、缩写等)被转换为完整的单词和句子,扩展缩写,并分析表达式。输出被传递到语言分析中,以精炼语调、持续时间,并以其他方式理解语法结构。结果,产生 spectrogram 或 mel 频谱图以转换为连续的类人音频。
我之前介绍的方法是一个典型的两步过程,需要一个合成网络和一个 vocoder 网络。这是两个独立的网络,用于从文本生成频谱图(使用 Tacotron architecture 或 FastPitch )和从频谱图或其他中间表示(如 WaveGlow 或 HiFiGAN )生成音频的后续目的。
除了两阶段方法外, TTS 管道的另一个可能实现涉及使用端到端的深度学习模型,该模型使用单个模型直接从文本生成音频。神经网络直接从文本 – 音频对中训练,不依赖中间表示。
端到端方法降低了复杂性,因为它减少了网络之间的错误传播,减少了对单独培训管道的需要,并最大限度地降低了手动注释持续时间信息的成本。
传统的 TTS 方法也倾向于产生更多机器人和不自然的声音,影响用户参与,尤其是面向消费者的应用程序和服务。
构建语音 AI 系统的挑战
成功的语音 AI 应用程序必须启用以下功能。
获取最先进的模型
从头开始创建训练有素、准确的深度学习模型既昂贵又耗时。
通过在前沿模型发布后立即提供对其的访问,即使是数据和资源受限的公司也可以在其产品和服务中使用高度精确、经过预训练的模型和 transfer learning 。
要在全球或任何行业或领域部署,必须对模型进行定制,以适应多种语言(世界上 6500 种口语的一小部分)、方言、口音和上下文。一些域使用 特定术语和技术术语 。
实时性能
由多个深度学习模型组成的管道必须以毫秒为单位运行推断,以实现实时交互,精确到 300 毫秒,因为大多数用户在 100 毫秒左右开始注意到 滞后和通信故障 ,在此之前,对话或体验开始感觉不自然。
灵活且可扩展的部署
公司需要不同的部署模式,甚至可能需要混合使用云、内部部署和边缘部署。成功的系统支持扩展到需求波动的数十万并发用户。
数据所有权和隐私
公司应该能够为其行业和领域实施适当的安全实践,例如在本地或组织的云中进行安全数据处理。例如,可能要求遵守 HIPAA 或其他法规的医疗保健公司限制数据访问和数据处理。
语音 AI 的未来
由于计算基础设施、语音 AI 算法的进步,对远程服务的需求增加,以及现有和新兴行业令人兴奋的新用例,基于语音 AI 的产品和服务现在有了一个强大的生态系统和基础设施。
当前的语音 AI 应用程序在推动业务成果方面功能强大,但下一代语音 AI 应用程序必须能够处理多语言、多领域和多用户对话。
能够成功地将语音 AI 技术集成到其核心运营中的组织将具备良好的能力,能够根据尚未列出的用例扩展其服务和产品。
关于作者
MikikoBazeley 是 Mailchimp 的高级 ML 操作和平台工程师。她拥有丰富的工程师、数据科学家和数据分析师经验,为初创公司和高增长公司利用机器学习和数据开发面向消费者和企业的产品。她积极贡献有关开发 ML 产品的最佳实践的内容,并在数据科学职业生涯中发言和指导非传统候选人。
审核编辑:郭婷
-
AI
+关注
关注
87文章
31133浏览量
269460 -
机器学习
+关注
关注
66文章
8425浏览量
132770 -
深度学习
+关注
关注
73文章
5507浏览量
121276
发布评论请先 登录
相关推荐
HarmonyOS NEXT 应用开发练习:AI智能语音播报
解锁个性化语音交互新时代:九芯智能语音云平台,让创意声音触手可及!
汤姆猫发布AI语音情感陪伴机器人研发进展
大联大推出基于MediaTek Genio 130与ChatGPT的AI语音助理方案
AI潮流下的办公“神器”选择,沸蛇AI语音鼠标真正实现效率翻倍


基于瑞萨电子Reality AI Tools工具的语音反欺骗应用示例

杭州国芯微AIoT产品系列及方案列表
SoundHound AI语音助手赋能欧洲汽车,引领智能驾驶新风尚
启英泰伦CI13LC系列:打造AI语音芯片性价比之王!

聆思CSK6视觉语音大模型AI开发板入门资源合集(硬件资料、大模型语音/多模态交互/英语评测SDK合集)


AI语音与机器视觉开发应用系统






 工商网监
工商网监
评论