 容器进程调度时是该优先考虑CPU资源还是内存资源
容器进程调度时是该优先考虑CPU资源还是内存资源
问题是这样的:有 A B 两台服务器,其中 A 服务器 cpu 快满了,内存很空闲。另外一台 B 服务器 cpu 很空闲,但内存快满了。现在 k8s 有一个新的任务要调度,请问应该选择哪台服务器?这其实是现在非常火的 k8s 的经典应用场景。
有的同学看到这个问题后的第一个想法是应该先评估一下新任务是计算密集型的业务还是 io 密集型的。然后再决定往哪个机器上调度。这么思考倒是也不能算错,只不过是没有抓到问题的关键点上。
这个问题的关键点是在于要思考一下调度到某个机器上可能会出现什么问题。
1. 调度到 CPU 比较满的 A 服务器
假设我们调度到 CPU 比较满的 A 机器上会出现什么状况呢?因为 CPU 资源是分时来调度的,每个进程都会得到一些时间片进行执行。所以 A 机器上不管 CPU 有多忙,再加一个的进程来运行话其实影响无非就是所有的进程都运行的更慢了一些。再换个说法,就是 CPU 资源是可以超卖的,是属于可压缩资源。
这里提一下,部分读者反馈说自己的云虚机在 CPU 飙升到 100% 的时候,云厂商为了保护主机,直接宕机。这种情况在各大公司的 IDC 机房内不太可能出现,所以这种情况咱们暂时不考虑。
2. 调度到内存比较满的 B 服务器
再假设我们调度到内存比较满的 B 机器上会出现什么状况呢?不知道你有没有遭遇过线上进程被 oom kill 掉的场景。这种情况下就是当机器物理内存不是很充足的时候,如果申请的内存过大,操作系统就可能会挑选在运行的一些进程将其杀掉。
这里稍微展开说一下,操作系统选择要杀掉的进程也不一定是内存消耗最多的服务。而是会综合内存消耗和进程的 oom_score_adj(可配置) 值来进行选择。在一些在离线混部的服务器上,往往会将在线服务进程的被杀的优先级调的低一些,离线服务进程的被杀优先级调高。这样充分保障在线服务的稳定运行。
先不考虑在离线混部的情况,假设都是在线服务,那么无论哪一个服务的进程被 Linux 给 oom kill掉影响都是非常大的。还得重新调度,而且还有可能影响服务的稳定性,以及接口的正确返回。
这里有的同学可能会说,Linux 上不是支持将内存 swap 到磁盘上吗?但其实在线上服务器中,由于磁盘的性能比内存低太多了,所以大部分的线上服务器都不会开启 swap 这个特性。因为服务的内存一旦被 swap 到内存,即使是能运行,性能也会有急剧的下降。所以一般不怎么会开启。
结论
所以对比来看,新任务在调度的时候应该优先选择 A 服务器,因为它的空闲内存比较多,不太可能出现进程被杀死的情况。虽然它的 CPU 比较满,但所有的服务仍然可以运行。
在实际中,k8s 的 API Server接受客户端提交Pod对象创建请求后的操作过程中,有一个重要的步骤就是由调度器程序kube-scheduler从当前集群中选择一个可用的最佳节点来接收并运行它。
当然实际中 k8s 的调度策略不是这么简单的,系统默认的 kube-scheduler 调度器外还有直接指定Node主机名、节点亲和性、Pod亲和性、nodeSelector 等等调度策略。
就单拿系统默认的 kube-scheduler 调度器来说的话,还会综合考虑单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局域性、负载间的干扰等等这些因素对可调度节点打分,然后选出其中得分最高的 Node 来运行 Pod。
审核编辑:刘清
-
cpu
+关注
关注
68文章
10850浏览量
211518 -
服务器
+关注
关注
12文章
9109浏览量
85310 -
操作系统
+关注
关注
37文章
6794浏览量
123275 -
Linux系统
+关注
关注
4文章
593浏览量
27387 -
SWAP
+关注
关注
0文章
51浏览量
12820
发布评论请先 登录
相关推荐
深入解析Linux程序与进程

虚拟内存溢出该怎么处理 虚拟内存在服务器中的应用

android系统使用appe播放audio资源,相关进程被kill之后appe无法再次打开的原因?
云服务器的购买资源和扩容资源的区别和联系
深入探讨Linux的进程调度器

鸿蒙开发接口资源调度:【@ohos.workScheduler (延迟任务调度)】
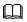
HarmonyOS跨进程通信—IPC与RPC通信开发
线程是什么的基本单位 进程与线程的本质区别
鸿蒙原生应用/元服务开发-延迟任务说明(一)
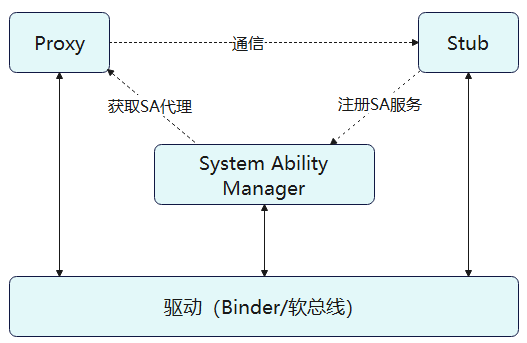
线程、进程、多线程、多进程和多任务之间有何关系?
mcu线程和进程的区别是什么
DshanMCU-R128s2启动与资源划分





 工商网监
工商网监
评论