 EAST模型结构
EAST模型结构
EAST模型
EAST( An Efficient and Accurate Scene Text Detector)是标题的英文首字母缩写,模型出自旷视科技。相比其他几种场景文字检测模型,表现开挂。在ICDAR 2015数据集上表现优异,见下图:

可以看到红色点标记EAST模型的速度与性能超过之前的模型。EAST模型是一个全卷积神经网络(FCN)它会预测每个像素是否是TEXT或者WORDS,对比之前的一些卷积神经网络剔除了区域候选、文本格式化等操作,简洁明了,后续操作只需要根据阈值进行过滤以及通过非最大抑制(NMS)得到最终的文本区域即可,EAST模型结构如下:
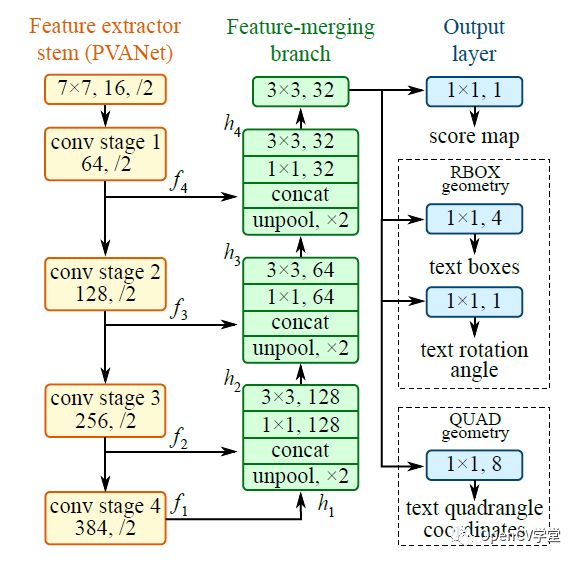
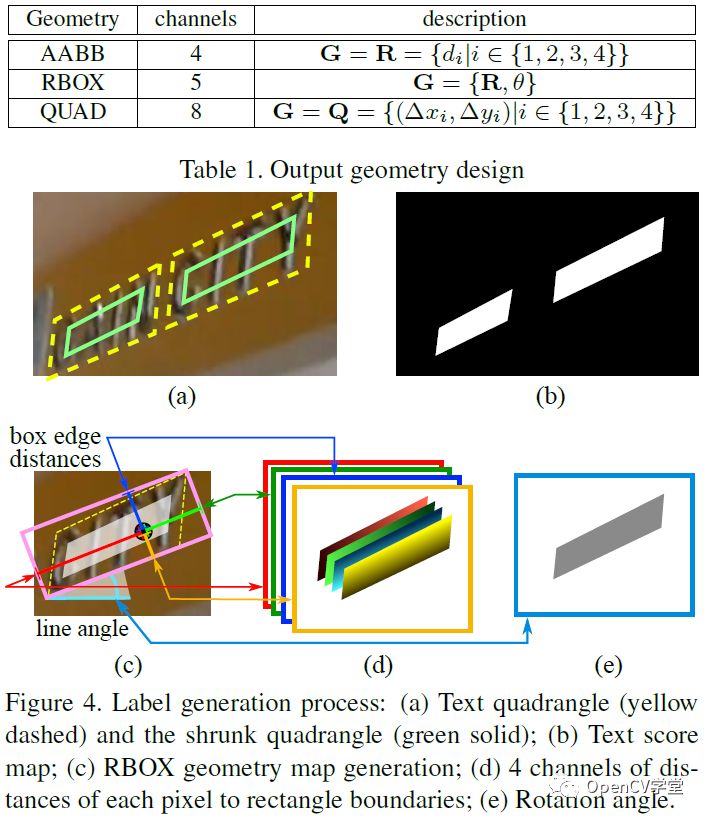
其中stem网络是一个基于ImageNet预训练的卷积神经网络(CNN)比如VGG-16,剩下的分别是通过卷积不断降低尺度大小,再通过不同层的反卷积进行合并,这个有点像UNet图像分割网络,最后输出层,通过1x1的卷积分别得到score、RBOX、QUAD,输出参数的解释如下:
OpenCV DNN使用
OpenCV4.0 的深度神经网络(DNN)模块能力大大加强,不仅支持常见的图像分类、对象检测、图像分割网络,还实现了自定义层与通用网络模型支持,同时提供了非最大抑制相关API支持,使用起来十分方便。EAST模型的tensorflow代码实现参见如下:
https://github.com/argman/EAST
下载预训练模型,生成pb文件,OpenCV DNN中导入tensorflow模型的API如下:
Netcv::readNet( constString&model, constString&config="", constString&framework="" ) model表示模型路径 config表示配置文件,缺省为空 framework表示框架,缺省为空,根据导入模型自己决定
OpenCV DNN已经实现非最大抑制算法,支持的API调用如下:
voidcv::NMSBoxes( conststd::vector< Rect >&bboxes, conststd::vector< float >&scores, constfloatscore_threshold, constfloatnms_threshold, std::vector< int >&indices, constfloateta=1.f, constinttop_k=0 ) Bboxes表示输入的boxes Score表示每个box得分 score_threshold表示score的阈值 nms_threshold表示非最大抑制阈值 indices表示输出的结果,是每个box的索引index数组 eta表示自适应的阈值nms阈值方式 top_k表示前多少个,为0表示忽略
代码实现
首先加载模型,然后打开摄像头,完成实时检测,C++的代码如下:
#include> #include usingnamespacecv; usingnamespacecv::dnn; voiddecode(constMat&scores,constMat&geometry,floatscoreThresh, std::vector &detections,std::vector &confidences); intmain(intargc,char**argv) { floatconfThreshold=0.5; floatnmsThreshold=0.4; intinpWidth=320; intinpHeight=320; Stringmodel="D:/python/cv_demo/ocr_demo/frozen_east_text_detection.pb"; //Loadnetwork. Netnet=readNet(model); //Openacamerastream. VideoCapturecap(0); staticconststd::stringkWinName="EAST:AnEfficientandAccurateSceneTextDetector"; namedWindow(kWinName,WINDOW_AUTOSIZE); std::vector outs; std::vector outNames(2); outNames[0]="feature_fusion/Conv_7/Sigmoid"; outNames[1]="feature_fusion/concat_3"; Matframe,blob; while(waitKey(1)< 0) { cap >>frame; if(frame.empty()) { waitKey(); break; } blobFromImage(frame,blob,1.0,Size(inpWidth,inpHeight),Scalar(123.68,116.78,103.94),true,false); net.setInput(blob); net.forward(outs,outNames); Matscores=outs[0]; Matgeometry=outs[1]; //Decodepredictedboundingboxes. std::vector boxes; std::vector confidences; decode(scores,geometry,confThreshold,boxes,confidences); //Applynon-maximumsuppressionprocedure. std::vector indices; NMSBoxes(boxes,confidences,confThreshold,nmsThreshold,indices); //Renderdetections. Point2fratio((float)frame.cols/inpWidth,(float)frame.rows/inpHeight); for(size_ti=0;i< indices.size(); ++i) { RotatedRect& box = boxes[indices[i]]; Point2f vertices[4]; box.points(vertices); for (int j = 0; j < 4; ++j) { vertices[j].x *= ratio.x; vertices[j].y *= ratio.y; } for (int j = 0; j < 4; ++j) line(frame, vertices[j], vertices[(j + 1) % 4], Scalar(0, 255, 0), 1); } // Put efficiency information. std::vector layersTimes; doublefreq=getTickFrequency()/1000; doublet=net.getPerfProfile(layersTimes)/freq; std::stringlabel=format("Inferencetime:%.2fms",t); putText(frame,label,Point(0,15),FONT_HERSHEY_SIMPLEX,0.5,Scalar(0,255,0)); imshow(kWinName,frame); } return0; } voiddecode(constMat&scores,constMat&geometry,floatscoreThresh, std::vector &detections,std::vector &confidences) { detections.clear(); CV_Assert(scores.dims==4);CV_Assert(geometry.dims==4);CV_Assert(scores.size[0]==1); CV_Assert(geometry.size[0]==1);CV_Assert(scores.size[1]==1);CV_Assert(geometry.size[1]==5); CV_Assert(scores.size[2]==geometry.size[2]);CV_Assert(scores.size[3]==geometry.size[3]); constintheight=scores.size[2]; constintwidth=scores.size[3]; for(inty=0;y< height; ++y) { const float* scoresData = scores.ptr (0,0,y); constfloat*x0_data=geometry.ptr (0,0,y); constfloat*x1_data=geometry.ptr (0,1,y); constfloat*x2_data=geometry.ptr (0,2,y); constfloat*x3_data=geometry.ptr (0,3,y); constfloat*anglesData=geometry.ptr (0,4,y); for(intx=0;x< width; ++x) { float score = scoresData[x]; if (score < scoreThresh) continue; // Decode a prediction. // Multiple by 4 because feature maps are 4 time less than input image. float offsetX = x * 4.0f, offsetY = y * 4.0f; float angle = anglesData[x]; float cosA = std::cos(angle); float sinA = std::sin(angle); float h = x0_data[x] + x2_data[x]; float w = x1_data[x] + x3_data[x]; Point2f offset(offsetX + cosA * x1_data[x] + sinA * x2_data[x], offsetY - sinA * x1_data[x] + cosA * x2_data[x]); Point2f p1 = Point2f(-sinA * h, -cosA * h) + offset; Point2f p3 = Point2f(-cosA * w, sinA * w) + offset; RotatedRect r(0.5f * (p1 + p3), Size2f(w, h), -angle * 180.0f / (float)CV_PI); detections.push_back(r); confidences.push_back(score); } } }
python的代码实现如下:
if__name__=="__main__":
text_detector=TextAreaDetector("D:/python/cv_demo/ocr_demo/frozen_east_text_detection.pb")
frame=cv.imread("D:/txt.png")
start=time.time()
text_detector.detect(frame)
end=time.time()
print("[INFO]textdetectiontook{:.4f}seconds".format(end-start))
#showtheoutputimage
cv.imshow("TextDetection",frame)
cv.waitKey(0)
cap=cv.VideoCapture(0)
whileTrue:
ret,frame=cap.read()
ifretisnotTrue:
break
text_detector.detect(frame)
cv.imshow("easttextdetectdemo",frame)
c=cv.waitKey(5)
ifc==27:
break
cv.destroyAllWindows()
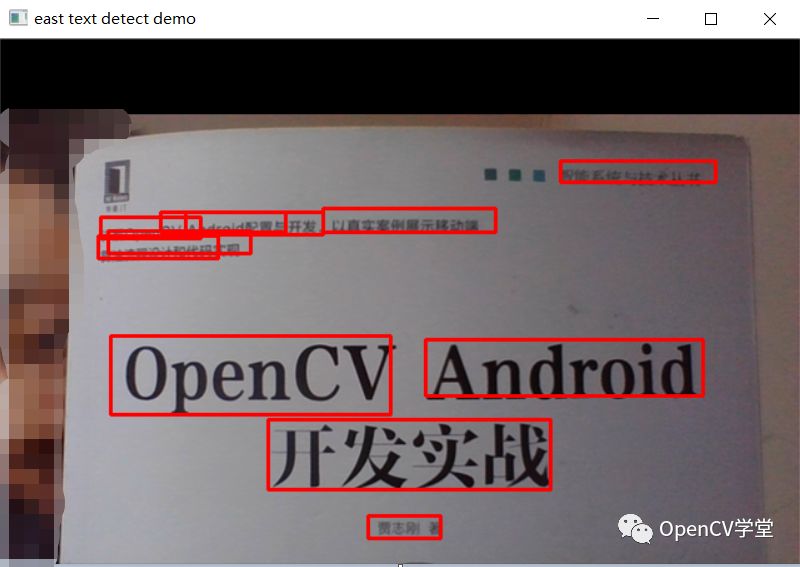
运行结果
图书封面 – 图像检测
视频场景中文字检测
手写文本检测
-
神经网络
+关注
关注
42文章
4772浏览量
100793 -
EAST
+关注
关注
0文章
21浏览量
9513 -
网络模型
+关注
关注
0文章
44浏览量
8432
原文标题:OpenCV4.x的EAST场景文字检测
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论