 eBPF安全可观测性的前景展望
eBPF安全可观测性的前景展望
一、eBPF安全可观测性的前景展望
本次分享将从监控和可观测性、eBPF安全可观测性分析、内核安全可观测性展望三个方面展开。
1.监控(Monitoring)vs可观测性(Observability)
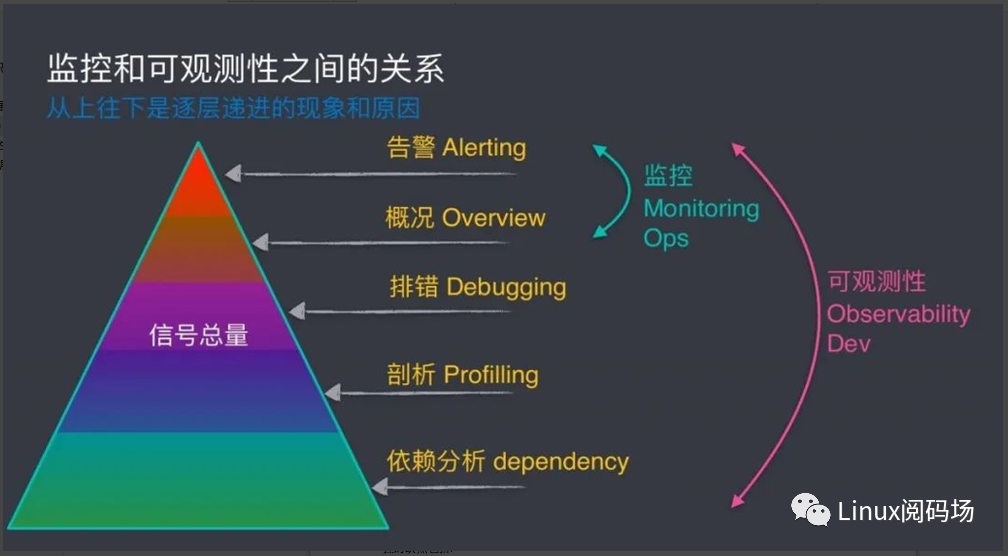
从上图可以看到,监控只是可观测性的冰山一角,而大部分都隐藏在水面之下的深层次问题无法简单通过监控解决。
目前监控也开始可视化,但绝大部分都是事先预定义参数,然后事后查看日志,进行分析。监控的缺点包括:
可扩展性差,需要修改代码和编译;验证周期长;数据来源窄等问题。
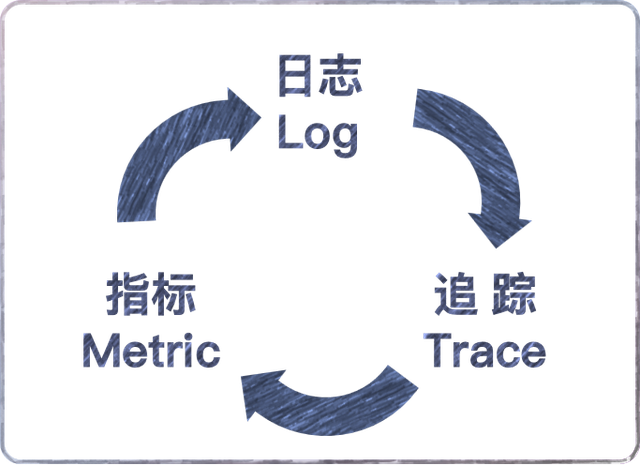
可观测性是通过主动定制度量的搜集和内核数据聚合,包括以下三种:
Logging
实时或者事后特定事件信息
分布式服务器集群的海量数据溯源图
离散信息整理各种异步信息
Tracing
数据源:提供数据来源
采集框架:往上对接数据源,采集解析发送数据,往下对用户态提供接口
前端交互:对接Tracing内核框架,直接与用户交互,负责采集配置和数据分析
Metrics(度量)这也是可观测性与监控最主要的区别
系统中某一类信息的统计聚合,比如CPU、内存、网络吞吐、硬盘 I/O、硬盘使用等情况。当度量值触发异常阈值时,系统可以发出告警信息或主动处理,比如杀死或隔离进程;
主要目的:监控(Monitoring)和预警(Alert)
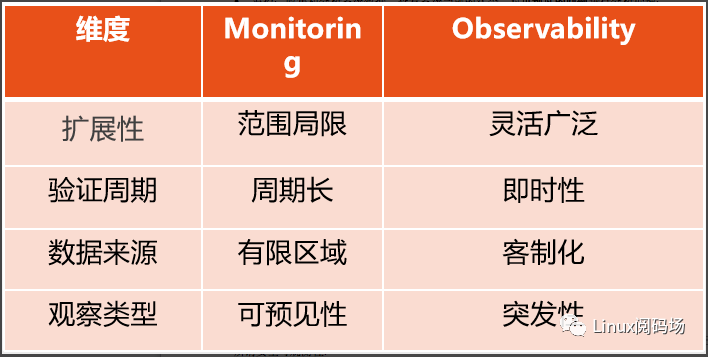
总结一下监控和观测的区别:
监控:收集和分析系统数据,查看系统当前的状态,对可预见的问题进行分析处理;
可观测性:通过观察系统并衡量系统的内部状态,从其外部输出的数据推断出来系统此时处于某种程度的度量,特别是我们所关心的场景和事件;
2.eBPF安全可观测性分析
先简单定义下什么是安全:安全指的是某种对象或者对象属性不受威胁的状态。
所谓安全可观测性:
通过观测整个系统,从低级别的内核可见性到跟踪文件访问、网络活动或能力(capability)变化,一直到应用层,涵盖了诸如对易受攻击的共享库的函数调用、跟踪进程执行或解析发出的 HTTP 请求。因此这里的安全是整体的概念。
提供对各种内核子系统的可观测性,涵盖了命名空间逃逸、Capabilities 和特权升级、文件系统和数据访问、HTTP、DNS、TLS 和 TCP 等协议的网络活动,以及系统调用层的事件,以审计系统调用和跟踪进程执行。
从日志、跟踪及度量三个维度检查相关输出,进而来衡量系统内部安全状态的能⼒。
eBPF的安全可观测性表现为对内核来说其存在感极低但观测能力却异常强大(药效好,副作用小):
程序沙箱化:通过eBPF验证器保护内核稳定运行。
侵入性低:无须修改内核代码,且无须停止程序运行。
透明化:从内核中透明搜集数据,保证企业最重要的数据资产。
可配置:Cilium等自定义乃至自动化配置策略,更新灵活性高,过滤条件丰富。
快速检测:在内核中直接处理各种事件,不需要回传用户态,使得异常检测方便和快速。
其中的程序沙箱话离不开更安全的eBPF Verifier(其中最重要的是边界检查):
拥有加载eBPF程序的流程所需的特权
无crash或其他异常导致系统崩溃的情况
程序可以正常结束,无死循环
检查内存越界
检查寄存器溢出
eBPF的可观测性应用场景主要有以下三类:
1.云原生容器的安全可观测性
这也是传统BPF基于网络应用场景的进一步发展:
随着云网边端的急速发展,人们的目光越发的聚焦在目前最火热的云原生场景上。Falco、Tracee、Tetragon、Datadog-agent、KubeArmor是现阶段云原生场景下比较流行的几款运行时防护方案。
这些方案主要是基于eBPF挂载内核函数并编写过滤策略,在内核层出现异常攻击时触发预置的策略,无需再返回用户层而直接发出告警甚至阻断。
以预防的方式在整个操作系统中执行安全策略,而不是对事件异步地做出反应。除了能够为多个层级的访问控制指定允许列表外,还能够自动检测特权和 Capabilities 升级或命名空间提权(容器逃逸),并自动终止受影响的进程。
安全策略可以通过 Kubernetes(CRD)、JSON API 或 Open Policy Agent(OPA)等系统注入。
2.应用层安全可观测方案
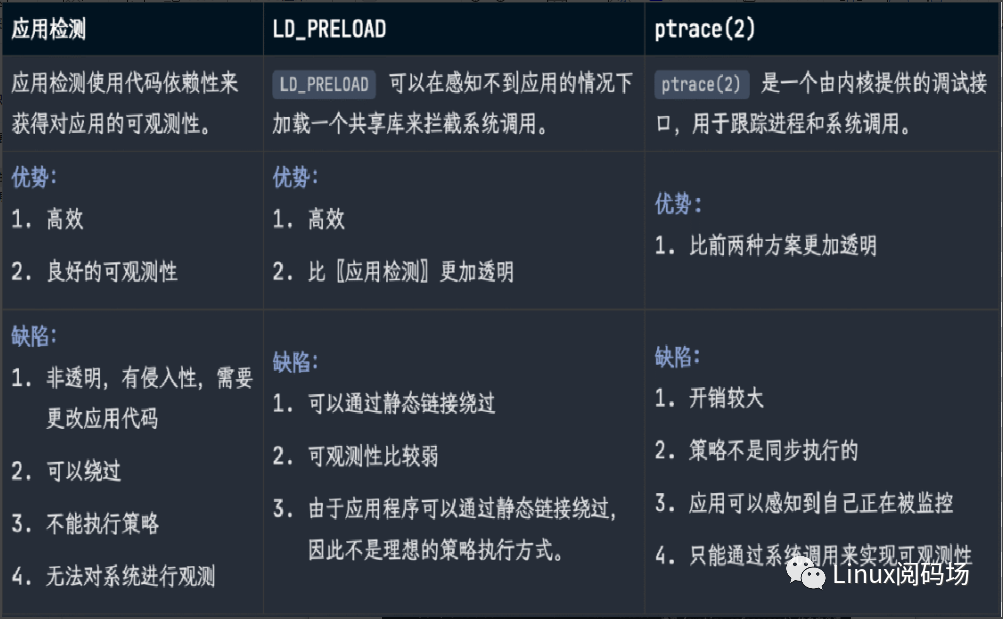
3.内核层安全可观测方案

3.内核安全可观测性展望
下面从传统内核安全、Android内核安全、KRSI等几个方面展开讨论。
传统内核安全方案存在着诸多需要解决的问题:
正如Linus Torvalds曾经说过的,大多数安全问题都是bug造成的,而bug又是软件开发过程的一部分,是软件就有bug。
至于是安全还是非安全漏洞bug,内核社区的做法就是尽可能多的测试,找出更多潜在漏洞这样近似于黑名单的做法。
内核代码提交走的流程比较繁琐,应用到具体内核版本上,又存在周期长以及版本适配的问题,所以导致内核在安全方面发展的速度明显慢于其他模块。同时,随着智能化、数字化、云化的飞速发展,全球基于Linux系统的设备数以百亿计,而这些设备的安全保障主要取决于主线内核的安全性和健壮性,当某一内核LTS版本被发有漏洞,这样相关的机器都会面临被攻破利用的局面,损失难以估量。
嵌入式领域的Android内核安全:
现如今,世界上越来越多的智能终端包括手机、TV、SmartBox和IoT、汽车、多媒体设备等等,均深度使用Android系统,而Android的底层正是Linux内核,这也让Linux内核的安全性对Android产生重大影响。
由于历史原因,Google在Android内核开源的问题上,理念和Linux内核社区不是十分的匹配,这也导致了Android对内核做了大量的针对性修改,但是无法合入到Upstream上。这也导致了Android内核在安全侧有部分不同于Linux内核,侧重点也存在不同。
在操作系统级别,Android平台不仅提供Linux内核的安全功能,而且还提供安全的进程间通信 (IPC)机制,以便在不同进程中运行的应用之间安全通信。操作系统级别的这些安全功能旨在确保即使是原生代码也要受应用沙盒的限制。无论相应代码是自带应用行为导致的结果,还是利用应用漏洞导致的结果,系统都能防止违规应用危害其他应用、Android 系统或设备本身。
Android内核安全特性:
HWAddressSanitizer(硬件支持的内存检测工具)
KASAN
Top-byte Ignore
KCFI(流控完整性校验)
ShadowCallStack(堆栈保护)
目前工作的关注重点是内核安全可观测性利器-KRSI:
KRSI (Kernel Runtime Security Instrumentation)的原型通过LSM (Linux security module)形式实现,可以将eBPF program挂载到kernel的security hook(安全挂钩点)上。内核的安全性主要包括两个方面:Signals和Mitigations,这两者密不可分。
Signals:意味着系统有一些异常活动的迹象、事件
Mitigations:在检测到异常行为之后所采取的告警或阻断措施
KRSI基于LSM来实现,这也就使其能够进行访问控制策略的决策,但这不是KRSI的工作重心,主要是为了全面监视系统行为,以便检测攻击(最重要的应用场景,但目前主要还是只做检测居多,因为贸然做阻断处理可能会比较危险)。从这种角度来看,KRSI可以说是内核审计机制的扩展,使用eBPF来提供比目前内核审计子系统更高级别的可配置性。
KRSI工具可以看作是eBPF和LSM的强强联合:KRSI = eBPF + LSM
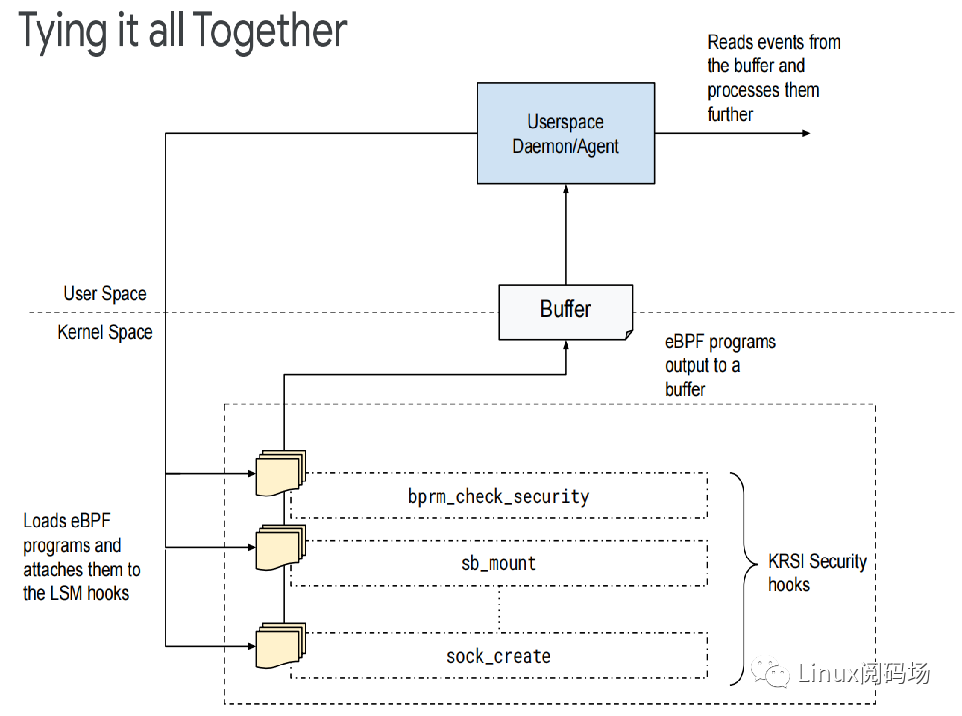
1.KRSI允许适当的特权用户将BPF程序挂载到LSM子系统提供的数百个钩子中的任何一个上面。
2.为了简化这个步骤,KRSI在/sys/kernel/security/bpf下面导出了一个新的文件系统层次结构——每个钩子对应一个文件。
3.可以使用bpf()系统调用将BPF程序(新的BPF_PROG_TYPE_LSM 类型)挂载到这些钩子上,并且可以有多个程序挂载到任何给定的钩子。
4.每当触发一个安全钩子时,将依次调用所有挂载的BPF程序,只要任一BPF程序返回错误状态,那么请求的操作将被拒绝。
5.KRSI能够从函数级别做阻断操作,相比进程具有更细粒度,危险程度也会小得多。
后续计划
内核安全问题是个非常复杂的话题,牵一发而动全身,防御机制、加固配置、漏洞利用等等挑战性的技术。在进行加固防御的过程中,又会产生性能或者系统稳定性相关的影响。
从eBPF + LSM的角度可以更加可视化、数据丰富的观测内核安全情况,进而在内核Livepatch、漏洞检测以及防御提权相关攻击手段上,有着进一步的发展空间。
二、Linux进程调度与性能优化
本次分享将从进程调度概念、进程调度框架、进程调度算法和性能优化四个方面展开。
1.进程调度概念
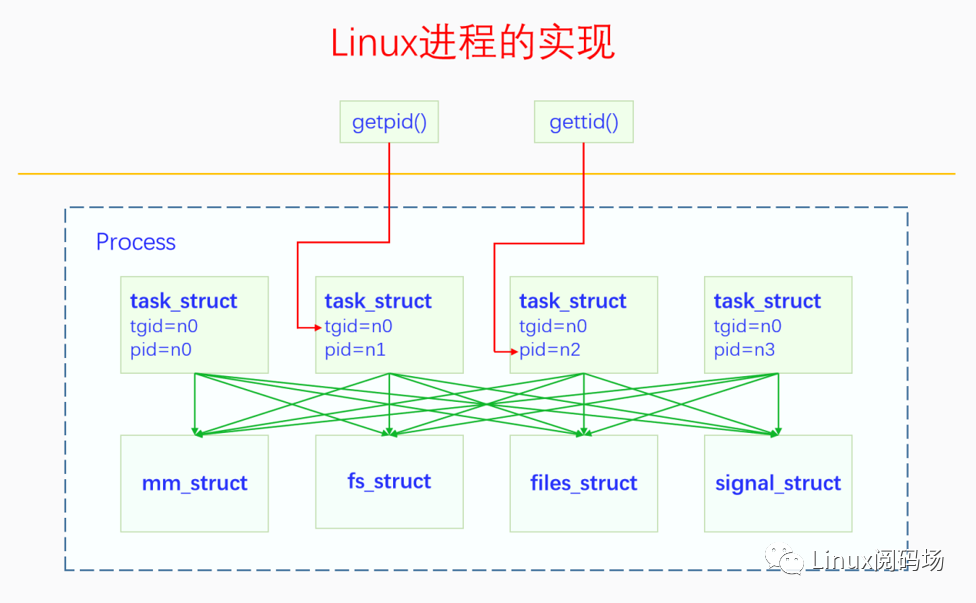
最初的Linux只有进程,task_struct相当于进程控制块(PCB),后来出现了线程,task_struct就开始对应线程。Linux没有从概念上直接区分两者,如果不同的task_struct间共享资源,它们属于同一进程中的线程,否则就属于不同的进程。
这里要注意,用户态中的进程和线程与内核态间的映射关系:用户态函数getpid()得到的是内核中的tgid;用户态函数gettid()得到的是内核中的pid。
Posix支持一级调度和二级调度两种模式,二级调度会先调度进程,然后才是进程中的线程。而Linux选择的是直接调度线程的一级调度,效率会比二级调度高。
Linux进程调度体系如下图:
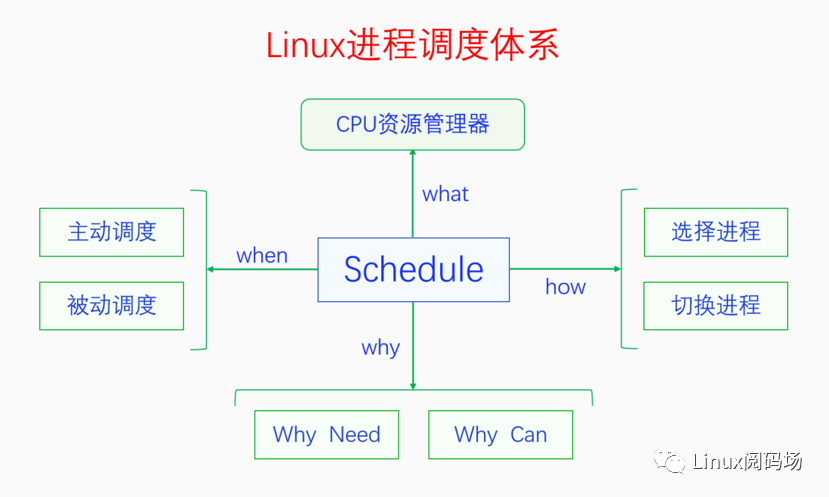
CPU资源管理器(what):调度器(scheduler)就是CPU资源管理器,因为操作系统的重要作用之一是管理各种系统资源,而CPU是其中最重要的资源。常用直接共享型资源的管理方法有时分、空分、独占等,IO一般是独占资源,内存支持空分管理,而CPU只支持时分,因此这种时分管理方法就是进程调度。
为什么要及为什么能调度(why):
为什么要调度:宏观并行,微观串行,支持多任务的协作与抢占。最初是协作,后来为了防止个别进程长期霸占CPU,引入了抢占机制。
为什么能调度:包括主动调度和被动调度,线程上下文可切换。
调度时机(when):
主动调度:通过主动调用sched_yield的自愿性主动调度,以及进程由于等待资源而阻塞的非自愿性主动调度。
被动调度:
触发点:设置 TIF_NEED_RESCHED 标志,主要是时钟中断和唤醒抢占。
执行点:检查 TIF_NEED_RESCHED 标志 和 满足preempt_count == 0的条件。
主要包括以下四种场景:
系统调用完成返回用户空间
完成返回用户空间
中断完成返回内核空间
出禁用抢占临界区
如何进行调度(how):调用pick_next_task()选择下一个调度进程和通过context_switch切换进程(上下文:内存空间,寄存器和栈)。
下面按时间顺序简单介绍一下linux调度器的发展历史:
传统Unix调度器:区分IO密集型和CPU密集型,但全局只有一个未排序的运行队列,多CPU会有竞争,而且调度选择需要遍历整个队列,复杂度为O(n)。
O(1)调度器:运行队列从全局变成每个CPU一个,链表分成活动和过期两个数组,引入位图,复杂度降为为O(1)。
SD调度器:考虑到会因为个别进程的伪装而造成的实际调度不公平,不再区分IO和CPU密集型,未合入内核。
RSDL调度器:组时间配额,有点像Cgroup,但未合入内核。
CFS(完全公平调度器):从SD/RSDL中吸取了完全公平的思想,目前内核主流调度器。
可以从以下几个方面来评价调度器:
1.响应性:存在大量人机交互的PC和手机要重视响应。
2.吞吐量:服务器更关心吞吐量,而提高响应性会增加进程切换的评论,也就会降低吞吐量。所以响应和吞吐是一对矛盾。
3.公平性:相对公平,实际和理论的运行时间应该相符。
4.适应性:也就是可扩展性。
5.节能性:智能手机的需求,需要通过调度均衡来省电。
2.进程调度框架
如下图所示,Linux一共有5个调度类:(stop和idle每个CPU一个)
stop:无调度策略,用户空间不可用,内核用来处理线程迁移等优先级极高的事情。
idle:无调度策略,用户空间不可用,无其他进程调用时才调用idle进程。
deadline:硬实时,要在确定时延内完成调度。
realtime:软实时,尽力而为保证实时性。
time-share:按优先级分配时间片。

调度类之间的关系:除非资源限制,优先调度高优先级进程。但要注意,Linux考虑到在恶劣环境下,普通进程应该仍有被调度的机会,会默认预留有5%的带宽给普通进程。
如下图所示,从用户空间到内核空间,进程优先级会发生转换:
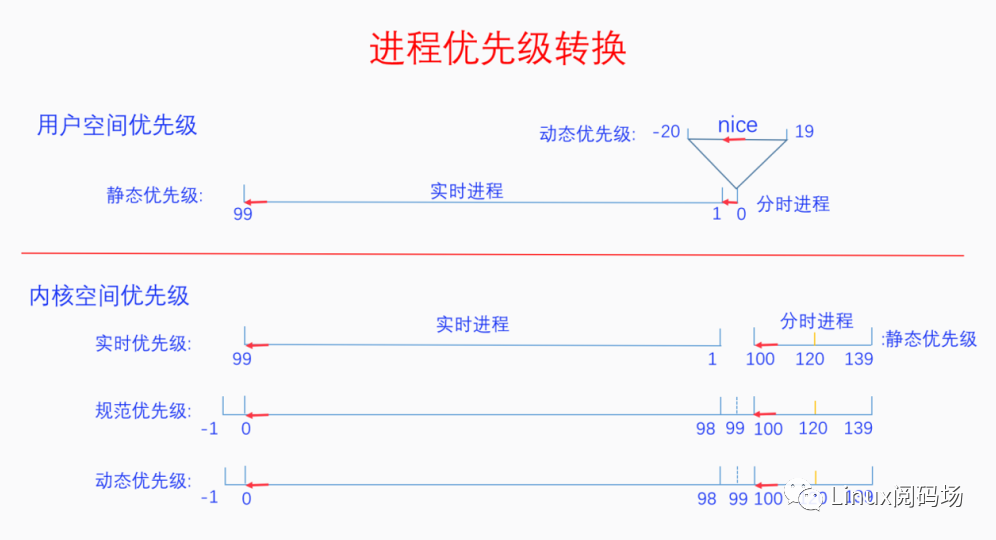
用户空间优先级:分为1~99优先级从低到高的实时进程,以及nice值-20~19动态优先级从高到低的分时进程。
映射到内核空间优先级分为三步:
1.实时优先级:实时进程不变,分时进程从动态优先级映射为100~139静态优先级由高到低。
2.规范优先级:实时进程映射为-1~98优先级由高到低,99为空,分时进程静态优先级不变。
3.动态优先级:可以看到动态优先级几乎等于规范优先级,只有在解决优先级反转问题时采用优先级继承策略时才会变化,此时会体现为动态优先级。
注意:-1和-2分别对应deadline和stop的逻辑优先级。
那如何进行进程切换呢?
切换用户空间:不同进程的用户空间不同,需要切换。
切换内核栈:不同进程共享内核空间,但需要切换内核栈。进程切换就像火车切换轨道,换道后,车上的人感觉火车没变,但是因为轨道变了,行程也就跟着变了。线程的执行过程就是函数调用树的深度优先遍历,进程的切换点是__schedule函数,该函数前半部分在进程A的调用栈上执行,后半部分就跑到进程B的调用栈上执行了,返回则在新进程上执行。
3.进程调度算法
CFS调度器定义:通过引入虚拟运行时间vruntime(realtime / weight),每次选择vruntime最小的进程(红黑树来管理)来调度,在真实硬件上模拟理想多任务处理器。
枯燥的定义不太容易理解的话,下面我们通过一个与实际生活比较贴近的例子来解释CFS调度模型。
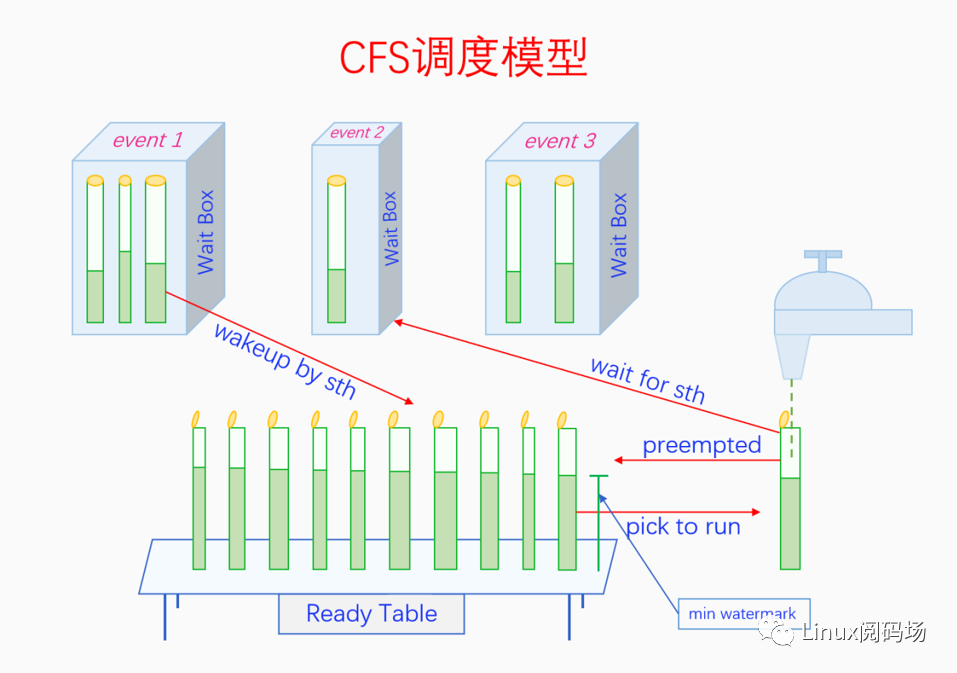
请仔细观察上图,图中事物与进程调度的映射关系如下:
水杯:表示进程,盖子打开的水杯表示进程处于就绪和执行状态,其中Ready Table上的水杯都是就绪态进程,水龙头下的水杯是运行态进程。盖子闭合的表示阻塞态的进程,它们都在不同的Wait Box中。
水杯的粗细:表示不同的优先级。
watermark:表示虚拟运行时间vruntime,min watermark会被pick to run。
Ready Table:表示可运行队列rq。
Wait Box:表示不同Event对应的等待队列,如果只能由对应的Event唤醒的话,就属于不可中断的深睡眠,否则就是也可由signal唤醒的可中断浅睡眠。
水龙头:表示CPU,水龙头中放出来的水就是CPU时间。
操作pick to run的手:表示调度算法,如果调度过于频繁,那杯子接的水就少,水龙头的水掉地上浪费了(响应好但性能差);反之调度周期长的话,杯子接的水太多会造成不平均(性能好但响应差)。权衡下来既不能接太少,最小值就是调度粒度;也不能接太多,最大值就是时间片。
这里需要特别注意的几点:
1.进程的状态
注意区别进程的5种状态中的运行态和就绪态,所有就绪态进程都位于cpu的运行队列中,而每个cpu上当前只有一个运行态进程。可以看到下面的代码分别通过on_rq和on_cpu来确定进程是runnable的就绪态还是running的运行态。对应上面的例子,桌子上的开口水杯表示就绪(on_rq),水龙头下的开口水杯表示运行(on_cpu)。

2.优先级与权重
CFS中的nice值会提前转换为权重,nice的范围是 [-20 -- 19],为了使得两个相邻的权重的占比差为10%,将以nice 0 为基准转化为1024,整个数列是以1.25为公比的等比数列。将原来的等差数列转为等比数列,因为调度策略的绝对值不重要,相对值(比例)才重要。
3.调度周期
调度周期 = 调度粒度 * 就绪和运行进程的数量,对应上面的例子就是所有开盖玻璃杯数量(桌子上和水龙头下的)与调度粒度的乘积,等于调度周期(所有杯子都接了一次水)。最小调度周期等于最小粒度乘以数量,如果计算算出来的时间片小于最小调度周期,内核就会让时间片直接等于最小调度周期。
4.调度延迟
调度延迟是另一个概念,对应上面的例子就是从开口玻璃杯放到到桌子上开始计算,到送到水龙头下接水的时间。但要注意,Linux中的调度延迟却不这个意思,内核代码体现的调度延迟是最小调度周期,也就是调度周期的最小值。
4.性能优化
单个进程的性能优化:
对于单个进程来说,可以通过下面的系统调用来改变进程(线程)的调度策略和优先级,只有特权进程才能调高自己的调度策略或者优先级。一般不要轻易地把进程设置为实时进程或者提高其优先级,除非有充足的理由。
系统响应性与吞吐量的优化:
系统的响应性和吞吐量是一对矛盾,很多时候我们要根据具体的情况来对系统进行配置。CONFIG_PREEMPT:是否开启内核抢占,开启可增加响应性,不开启可增加吞吐量。一般服务器系统不会开启,桌面和移动系统会开启。
定时器tick频率HZ:
定时器tick的频率HZ,对系统的响应性和吞吐量也有很大的影响,HZ取值较大,系统响应性好,但是吞吐量会降低,HZ取值较小,吞吐量会增大,但是响应性会降低。
避免实时进程过度占用CPU:
为此内核提供了一对参数,可以设置一个运行周期内,实时进程最多只能用多少CPU时间,这样就可以给普通进程留下一些执行时间。这两个参数对应的文件是:
/proc/sys/kernel/sched_rt_period_us/proc/sys/kernel/sched_rt_runtime_us
可以通过cat和echo来查看和设置具体的值,单位是微妙默认值分别是1000000,950000,也就是说在每一秒内实时进程最多运行0.95s,会给普通进程保留0.5s。当然如果此时没有普通进程,实时进程还是可以使用100%的CPU时间的。如果我们不希望实时进程使用过多的CPU时间的话,可以修改这个值。
子进程是否优先运行的问题:
默认情况下父进程与刚fork出来的子进程,谁会先得到执行是不确定的。如果在我们的环境中经常会fork子进程,并且我们总是希望子进程比父进程先得到执行,那么我们可以将/proc/sys/kernel/sched_child_runs_first值设为1。
-
数据
+关注
关注
8文章
7134浏览量
89467 -
监控
+关注
关注
6文章
2233浏览量
55324 -
服务器
+关注
关注
12文章
9295浏览量
85938 -
代码
+关注
关注
30文章
4823浏览量
68953
原文标题:PODS2022: eBPF安全可观测性的前景展望&Linux进程调度与性能优化速记(Day2)
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
openEuler 倡议建立 eBPF 软件发布标准
基于拓扑分割的网络可观测性分析方法
如何将可观测性策略与APM工具结合起来
介绍eBPF针对可观测场景的应用
六大顶级、开源的数据可观测性工具
eBPF,何以称得上是革命性的内核技术?

华为云应用运维管理平台获评中国信通院可观测性评估先进级
使用APM无法实现真正可观测性的原因
如何构建APISIX基于DeepFlow的统一可观测性能力呢?
华为云发布全栈可观测平台 AOM,以 AI 赋能应用运维可观测

【质量视角】可观测性背景下的质量保障思路
破局新生丨基调听云可观测性与应用安全技术研讨会在平潭圆满举办

eBPF技术实践之virtio-net网卡队列可观测





 工商网监
工商网监
评论