 稠密向量检索的Query深度交互的文档多视角表征
稠密向量检索的Query深度交互的文档多视角表征
今天给大家带来一篇北航和微软出品的稠密向量检索模型Dual-Cross-Encoder,结合Query生成和对比学习技术,将文档与生成的不同伪query进行深度交互学习构建文档的不同视角的表征向量,再与Query向量进行稠密向量检索。
Paper:https://arxiv.org/pdf/2208.04232.pdf Github:https://github.com/jordane95/dual-cross-encoder
介绍
目前,稠密向量检索已经在信息检索中起着至关重要的地位,相较于传统的BM25,它可以更好地获取问题与文档之间的语义信息。针对query和document的相关性评分主要有Dual-Encoder和Cross-Encoder两种框架:
Cross-Encoder,由于计算量太大,无法在召回阶段使用;
Dual-Encoder,由于query和document没有相互,并且无法很好地表现长文档中的多主题内容。
一些研究(Poly-Encoder、ColBERT等)致力于用后期交互体系结构,权衡模型的速度与效果,但「无法直接使用ANN进行排序」。与之前的工作不同,我们主要使用生成的query来学习查询通知的文档表示。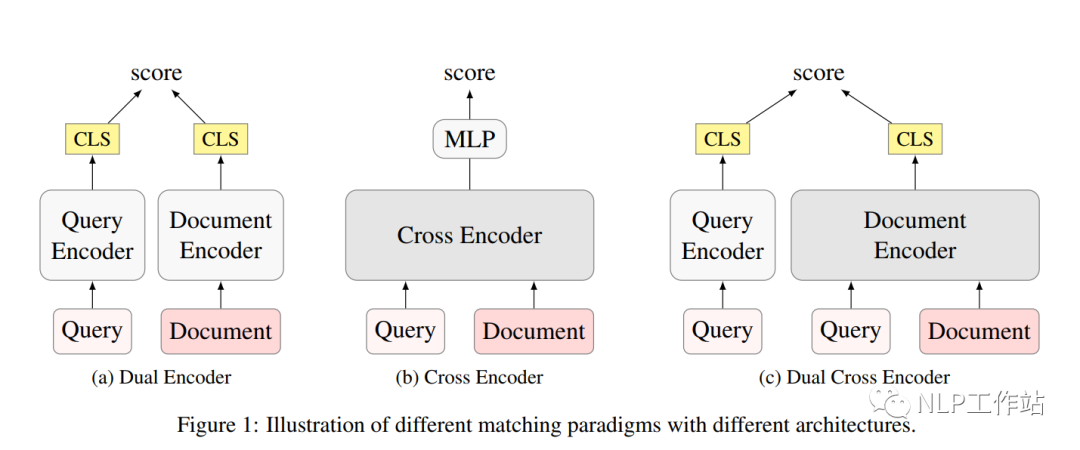 我们提出了一种新的稠密检索模型,使用生成的伪query与每个文档进行深度交互编码,以获得融合query信息的多视角文档表示,并单独编码query向量,使得该模型不仅像普通的Dual-Encoder模型一样具有很高的推理效率,而且在文档编码中与query深度交互,提供多视角表示,以更好地匹配不同的查询query。
我们提出了一种新的稠密检索模型,使用生成的伪query与每个文档进行深度交互编码,以获得融合query信息的多视角文档表示,并单独编码query向量,使得该模型不仅像普通的Dual-Encoder模型一样具有很高的推理效率,而且在文档编码中与query深度交互,提供多视角表示,以更好地匹配不同的查询query。
Dual-Cross-Encoder模型
Dual-Cross-Encoder中,文档编码器部分为Cross-Encoder,而问题编码器与文档编码器之间的模式相当于Dual-Encoder。具体来说,问题编码器为
文档编码器为
它们之间相似性是通过点积来衡量的,
注意,来自问题编码器和文档编码器的query是不相同的,因为只能访问到训练集中的文档的标准query,并且手动编写整个语料库中的每个文档可能出现的query是不现实的。
因此,使用T5模型,依赖doc2query技术为每个文档生成若干伪query,并在解码时采用Top-K方式,保证query的多样性。
模型训练
采用对比学习的方式训练模型,而对比学习的宗旨就是拉近相似数据,推开不相似数据,有效地学习数据表征。
将query信息融合到文档表示中后,重新定义正例和负例,对于给定,四种形式的正负例,为、、和。
难负例:负文档从通过BM25排名靠前的文档中随机抽取得来。难负例可以使模型学习到更细粒度的信息,如负文档通常与query有关,但不能准确回答,并且还阻止模型只学习来自query端的匹配信号,而忽略文档端信息。
批次内负例:可以提高训练效率,使模型学习到主题层次的辨别能力。
训练阶段,使用数据增强的方式,将生成的query视为伪标注数据,首先在这些噪声数据上,进行模型训练,视作一个热身阶段;然后在真实标注的高质量训练集上进行模型微调。
模型推理
创建索引
对语料库进行编码,以获得具有query深度交互的多视图文档表示。将表示为第个文档的第个视图,
其中,表示Query生成模型。
检索
当进行检索时,使用问题编码器对其进行编码,获取上下文表征向量。对文档进行多视角向量编码,并将其问题与文档中不同视角相关性得分的最大值(max-pooling)作为问题与文档的相关性得分。
支持直接使用ANN进行排序。
实现细节
在8块32GB V100上进行模型训练,采用bert-base-uncase初始化所有编码器,query最大长度为16,文档最大长度为128,每个样本的正例和负例数量对比为1:7。训练的Batch-Size大小为32,学习率为5e−6,warmup10%的步数。
结果
从下表中可以看出,相较于DPR Dual-Encoder,具有显著提高,证明了方法的有效性;并媲美Col-Bert模型,同时更高效。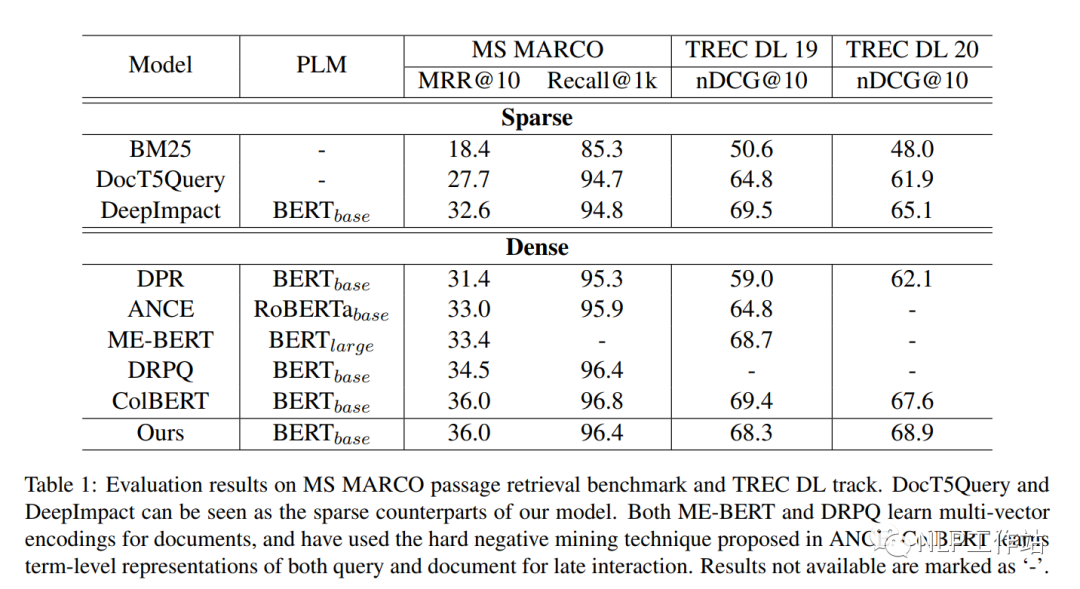 从下图可以看出,query生成质量与检索呈正相关。
从下图可以看出,query生成质量与检索呈正相关。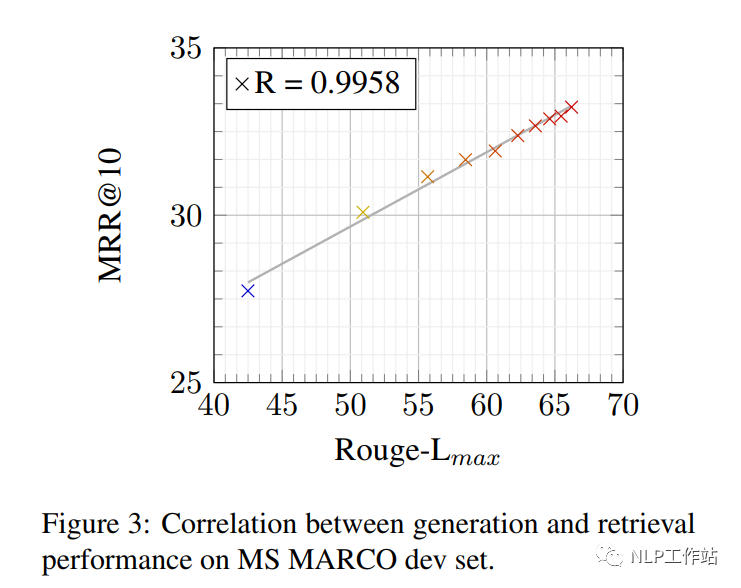
总结
挺有意思一篇文章,通过伪query来表征不同视角的文档,并且支持ANN排序。现在越来越多的长文档表征论文从多个不同视角出发,单一向量确实很难表达出多种差异较大的信息,甚至训练中会导致趋同。
-
编码器
+关注
关注
45文章
3688浏览量
135466 -
框架
+关注
关注
0文章
403浏览量
17566 -
Query
+关注
关注
0文章
11浏览量
9396 -
模型
+关注
关注
1文章
3389浏览量
49348
原文标题:Dual-Cross-Encoder:面向稠密向量检索的Query深度交互的文档多视角表征
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于模糊聚类表征的音频例子检索及相关反馈
基于多尺度HOG的草图检索
基于最小重构误差向量图像检索算法
基于视角相容性的多视角数据缺失补全
基于多类支持向量机的深度视频帧内编码快速算法

基于双峰高斯分布的深度哈希检索算法

稠密检索模型在zero-shot场景下的泛化能力
通过Token实现多视角文档向量表征的构建
机器学习多模态落地存在哪些挑战

UniVL-DR: 多模态稠密向量检索模型






 工商网监
工商网监
评论