 深入理解计算机系统的数值类型
深入理解计算机系统的数值类型
前言
在日常编程中,数值类型(numeric types)是我们打交道最多的类型,可能没有之一。除了最熟悉的int,还有long、float、double等。正因太熟悉,我们往往不会深究它们的底层原理。因为平时的工作中,知道个大概,也够用了。
但,在某些业务场景下,比如金融业务,数值运算不准确会带来灾难性的后果。这时,你就必须清楚数值类型的二进制表示、截断、转型等原理,否则很难保证运算结果的正确性。
另外,数值类型也是一个容易被黑客攻击的点,考虑如下一段代码:
//C++
/*Declarationoflibraryfunctionmemcpy*/
void*memcpy(void*dest,void*src,size_tn);
/*Kernelmemoryregionholdinguser-accessibledata*/
#defineKSIZE1024
charkbuf[KSIZE];
/*Copyatmostmaxlenbytesfromkernelregiontouserbuffer*/
intcopy_from_kernel(void*user_dest,intmaxlen){
/*Bytecountlenisminimumofbuffersizeandmaxlen*/
intlen=KSIZE< maxlen ? KSIZE : maxlen;
memcpy(user_dest, kbuf, len);
returnlen;
}
如果你熟悉数值类型的原理,一定会敏锐察觉出第 10 行存在int到size_t的类型转换。在 64 位系统中,size_t通常被定义为unsigned long类型,如果攻击者在调用copy_from_kernel时,特意传入一个负数的maxlen,转型到memcpy中的n将会是一个很大的正数,从而导致了内存拷贝的越界!
数值类型是计算机编程的基础,用的很多,也很重要,理解它的底层原理,有助于写出正确的代码,避免一些意料之外的错误。
每个计算机系统都有固定的word size,也即常说的 xx 位,它也是指针的大小,跟虚拟内存相关,比如一个 w 位系统上的应用程序,最多能够访问byte 大小的虚拟内存。
最常用的是 32 位 和 64 位 系统,某些数值类型在它们之上会有些差异,比如 long 类型 在 32 位系统上是 32 bit 大小,在 64 位系统上是 64 bit 大小。考虑如今 64 位系统逐渐成为主流,本文会以它作为基础,进行数值类型的介绍。
整数
在计算机系统中,整数可以分成无符号(unsigned)整数 和有符号(signed)整数 两大类,这之下,按照类型表示的 bit 位大小,又可细分成 8 位的char/byte/int8、16 位的short/innt16、32 位的int/int32和 64 位的long/int64,它们的取值范围如下:
| 类型 | 最小值 | 最大值 |
|---|---|---|
[signed] char |
-128 | 127 |
unsigned char |
0 | 255 |
short |
-32,768 | 32,767 |
unsigned short |
0 | 65,535 |
int |
−2,147,483,648 | 2,147,483,647 |
unsigned int |
0 | 4,294,967,295 |
long |
−9,223,372,036,854,775,808 | −9,223,372,036,854,775,807 |
unsigned long |
0 | 18,446,744,073,709,551,615 |
死记这个表不容易,下面我们将试图从二进制编码层面去理解它。
二进制编码
整数在计算机系统上都是以二进制存储的,对于一个 w 位的整数,它的二进制表示写成这样:
其中,取值或。
无符号编码(Unsigned Encodings)
在二进制表示的基础上,无符号编码是这样:
比如,w = 4 场景下的一些例子:
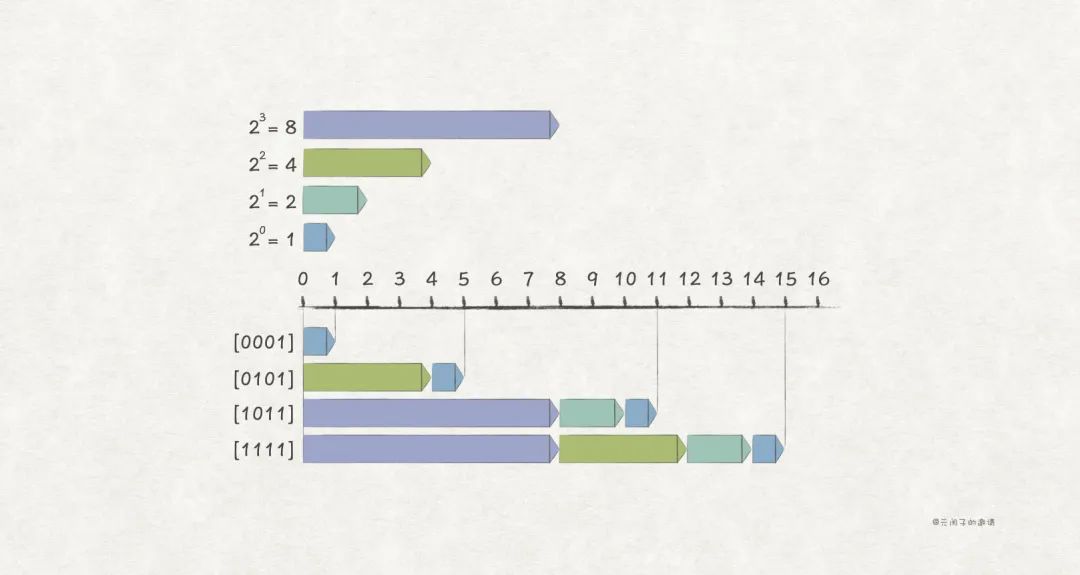
由上述可知,无符号编码无法表示负数,因此只能表示无符号整数。为了表示有符号整数,还要探寻另一种编码方式。
原码编码(True Form Encodings)
为了区分正数和负数,很容易想到使用一个 bit 位作为符号位,表示正数,表示负数。在无符号编码的基础上,使用最高位作为符号位,其他位含义不变,得出原码编码形式:
比如,w = 4 场景下的一些例子:
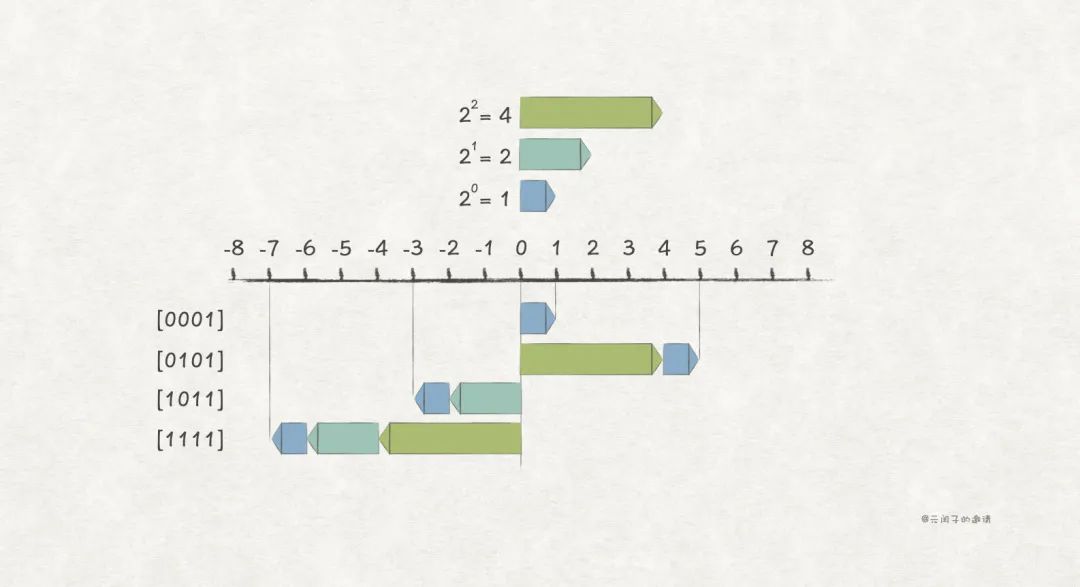
虽然原码编码方式简单直观,但它还存在两个问题:
(1)存在两种编码形式
原码编码方式下,存在两种编码形式,和。同一个整数值,却有两种编码,这对计算机系统来说没什么意义,反而是一种浪费。
(2)带负数的加法运算不正确
原码编码方式下,两个正数的加法没问题,一旦带上负数,结果就出错了:

所以,原码编码方式,注定不会被使用。
补码编码(Two's-complement Encodings)
于是,补码编码被发明,它也是建立在无符号编码的基础上,仍然取最高位为符号位,编码方式是这样:
它与无符号编码的唯一区别是,最高位的取值从变成了。
比如,w = 4 场景下的一些例子:
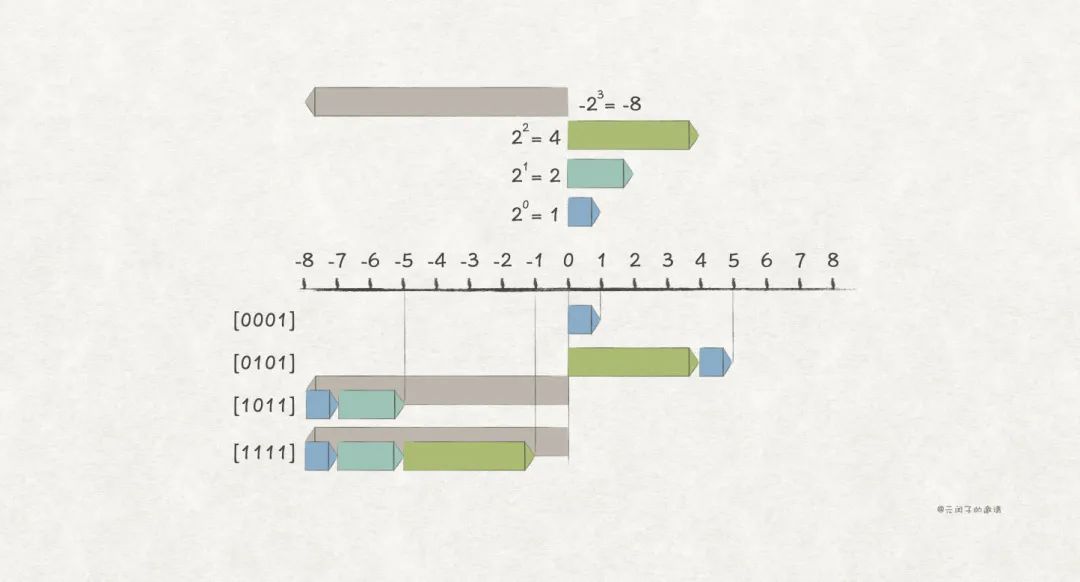
补码编码很巧妙地解决了原码编码的两个问题:
首先,0 在补码编码下只有一种编码形式,。
此外,带负数的加法运算,也正确了。
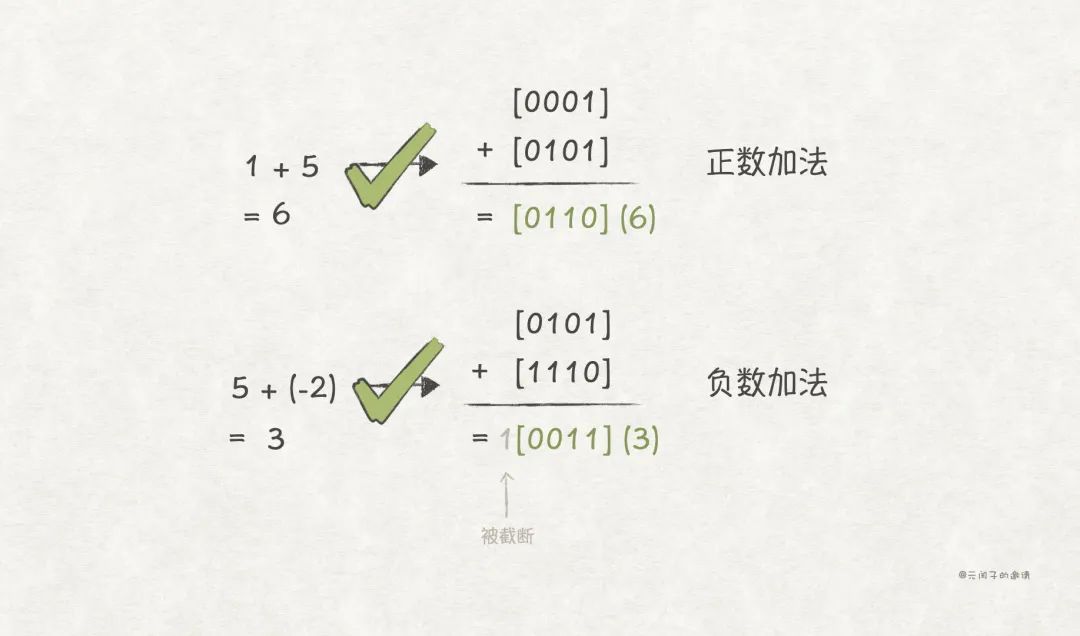
因为补码编码的简单和正确性,目前,几乎所有的计算机系统,都采用补码编码来表示有符号整数。
位运算
位运算主要包含取反、与、或、异或、移位等几种,我们在业务开发时用得比较少,但如果你有阅读开源代码的习惯,就会经常发现它们的踪迹。如果碰巧对位运算不熟悉,那么阅读这些代码,就同读天书一般。
取反(~)、与(&)、或(|)、异或(^)的规则比较简单:

移位运算,可以分成左移和右移两种,其中,右移又可分为逻辑右移和算术右移。
左移(<<)运算,是对二进制整数,向左移若干位,高位丢弃,低位补零。也即,对左移位,得到。
比如,对int i = -1左移 10 位,会得到i = -1024的结果:
//Java语言
publicstaticvoidmain(String[]args){
inti=-1;
System.out.println("Before<< , i's value is "+i);
System.out.println("i'sbinarystringis"+Integer.toBinaryString(i));
i<<= 10;
System.out.println("After<< , i's value is "+i);
System.out.println("i'sbinarystringis"+Integer.toBinaryString(i));
}
//输出结果:
Before<< , i'svalueis-1
i'sbinarystringis11111111111111111111111111111111
After<< , i'svalueis-1024
i'sbinarystringis11111111111111111111110000000000

在 C/C++ 中,两种右移操作符都是 >>,对无符号整数用的是逻辑右移,对有符号整数用的是算术右移;在 Java 中,逻辑右移的操作符是 >>>,算术右移的操作符是 >>。为了方便区分,下文统一用 Java 的表示方法。
逻辑右移(>>>)运算,是对二进制整数,向右移若干位,高位补零,低位丢弃。也即,对逻辑左移 k 位,得到。
比如,对int i = -1逻辑右移 10 位,会得到i = 4194303的结果:
//Java语言
publicstaticvoidmain(String[]args){
inti=-1;
System.out.println("Before>>>,i'svalueis"+i);
System.out.println("i'sbinarystringis"+Integer.toBinaryString(i));
i>>>=10;
System.out.println("After>>>,i'svalueis"+i);
System.out.println("i'sbinarystringis"+Integer.toBinaryString(i));
}
//输出结果:
Before>>>,i'svalueis-1
i'sbinarystringis11111111111111111111111111111111
After>>>,i'svalueis4194303
i'sbinarystringis1111111111111111111111

算术右移(>>)运算,是对二进制整数,向右移若干位,高位补符号位,低位丢弃。也即,对逻辑左移 k 位,得到。
比如,对int i = -1算术右移 10 位,仍会得到i = -1的结果:
//Java语言
publicstaticvoidmain(String[]args){
inti=-1;
System.out.println("Before>>,i'svalueis"+i);
System.out.println("i'sbinarystringis"+Integer.toBinaryString(i));
i>>=10;
System.out.println("After>>,i'svalueis"+i);
System.out.println("i'sbinarystringis"+Integer.toBinaryString(i));
}
//输出结果:
Before>>,i'svalueis-1
i'sbinarystringis11111111111111111111111111111111
After>>,i'svalueis-1
i'sbinarystringis11111111111111111111111111111111

目前为止,介绍移位运算的原理时,我们都默认 k < w,如果 k >= w 会怎样?
比如,左移 w 位,结果会是吗:
//Java语言
publicstaticvoidmain(String[]args){
inti1=-1;
System.out.println("Before<< 31, i1's value is "+i1);
System.out.println("i1'sbinarystringis"+Integer.toBinaryString(i1));
i1<<= 31;
System.out.println("After<< 31, i1's value is "+i1);
System.out.println("i1'sbinarystringis"+Integer.toBinaryString(i1));
inti2=-1;
System.out.println("Before<< 32, i2's value is "+i2);
System.out.println("i2'sbinarystringis"+Integer.toBinaryString(i2));
i2<<= 32;
System.out.println("After<< 32, i2's value is "+i2);
System.out.println("i2'sbinarystringis"+Integer.toBinaryString(i2));
}
//输出结果:
Before<< 31,i1'svalueis-1
i1'sbinarystringis11111111111111111111111111111111
After<< 31,i1'svalueis-2147483648
i1'sbinarystringis10000000000000000000000000000000
Before<< 32,i2'svalueis-1
i2'sbinarystringis11111111111111111111111111111111
After<< 32,i2'svalueis-1
i2'sbinarystringis11111111111111111111111111111111

上述例子中,w = 32,我们发现k = 31时,结果还符合预期;当k = 32时,结果不是 0,而是 -1,也即相当于k = 0时的结果。
原因是这样,对w位整数x,当执行x << k时,实际执行的是x << (k % w)。所以,当i2 << 32时,实际是i2 << 32 % 32 = i2 << 0。
右移操作也遵循同样的规则,也即x >> k = x >> (k % w),x >>> k = x >>> (k % w)。
算术运算
整数的算术运算也不总符合我们的常识,比如下面这个例子:
//Java语言
publicstaticvoidmain(String[]args){
inti1=2147483647;
inti2=1;
System.out.printf("2147483647+1=%d
",i1+i2);
}
//输出结果:
2147483647+1=-2147483648
两个正数2147483647和1相加,实际运行结果却是一个负数-2147483648。原因是,运算结果超出了int类型的表示范围,我们把这种现象称作溢出。
接下来,我们将介绍整数类型常见的几种算术运算,包括当运算出现溢出时,计算机系统的处理方式。
加法
(1)无符号整数加法运算
对两个 w 位的无符号整数,有;如果仍用一个 w 位的整数表示相加结果,那么当结果在范围时,也即结果需要 w + 1 位表示时,运算就产生溢出了。
如果出现溢出,系统会对结果进行截断,只保留低 w 位。
比如,w = 4 场景下的一些例子:

因此,如果用表示 w 位无符号整数的加法运算,那么它有如下规则:
其中,溢出场景因为对结果的进行截断,舍去了位,所以结果需要减去。
(2)有符号整数加法运算
对两个 w 位的有符号整数,有;如果仍用一个 w 位的整数表示相加结果,那么当结果在和范围时,运算就产生溢出了。
比如,w = 4 场景下的一些例子:

由上述例子可知,两个 w 位的负数相加,即使结果需要 w + 1 位表示,也可能是正常场景。这取决于截断位 w 位后的最高位,为 1 则还属于正常场景,为 0 则属于溢出场景。
因此,如果用表示 w 位有符号整数的加法运算,那么它有如下规则:
- 正溢出场景下,原本,但按照补码编码方式,实际变成了,所以就有。
- 负溢出场景下,w 位一定是 0,原本,结果截断之后,实际变成了,所以就有。
为什么负溢出场景下,w 位一定是 0?
负溢出场景出现的条件是,也即 :
如果要使上述不等式成立,必然为 0.
前面很多公式,但记住这个就行,无符号整数和有符号整数的加法运算规则,本质都是一样的,可以拆解成 4 步:
- 先计算出真实加法运算的结果值。
- 对结果值用 w + 1 位二进制表示。
- 再将 w + 1 位的二进制结果截断,保留低 w 位。
- 将截断后的 w 位二进制值转换回十进制整数,得到最终结果。无符号整数用无符号编码,有符号整数用补码编码。
取反
取反,也即求相反数,给定一个整数,那么它的相反数,也即满足。
(1)无符号整数的取反
对一个 w 位的无符号整数,对它取反,也即找到一个整数,使得:
- 当,那么很容易得出;
- 当 x > 0,只有在溢出场景才会存在的可能。由前文可知,无符号整数加法溢出场景下,时,有,。
因此,如果用表示 w 位无符号整数的取反运算,那么它有如下规则:
比如,w = 8 场景下的例子:
//C++
intmain(){
uint8_ti1=0;
uint8_ti2=-i1;
printf("i1=%u
",i1);
printf("-i1=%u
",i2);
uint8_ti3=100;
uint8_ti4=-i3;
printf("i3=%u
",i3);
printf("-i3=%u
",i4);
printf("2^8-i3=256-%u=%u
",i3,256-i3);
return0;
}
//输出结果
i1=0
-i1=0
i3=100
-i3=156
2^8-i3=256-100=156
(2)有符号整数的取反
对一个 w 位的有符号整数,对它取反,也即找到一个整数,使得:
- 当,很容易得出,因为此时,仍是有效的范围。
- 当,因为已经不再有效范围内,所以只能是溢出场景。而,截断为 w 之后,刚好为 0。所以,此时。
因此,如果用表示 w 位有符号整数的取反运算,那么它有如下规则:
比如,w = 8 场景下的例子:
//C++
intmain(){
int8_ti1=-128;
int8_ti2=-i1;
printf("i1=%d
",i1);
printf("-i1=%d
",i2);
int8_ti3=100;
int8_ti4=-i3;
printf("i3=%d
",i3);
printf("-i3=%d
",i4);
return0;
}
//输出结果
i1=-128
-i1=-128
i3=100
-i3=-100
乘法
前面介绍加法时说过,无符号整数和有符号整数的加法运算都可以拆成 4 步,这对乘法运算也适用。
对于无符号整数,那么,即无符号整数的乘法运算结果最多需要 2w 位来表示。
比如,w = 8 时,无符号整数的例子:
//C++
intmain(){
uint8_ti1=100;
uint8_ti2=2;
uint8_ti3=i1*i2;
printf("normal:i1*i2=%d*%d=%d
",i1,i2,i3);
uint8_ti4=100;
uint8_ti5=3;
uint8_ti6=i4*i5;
printf("overflow:i4*i5=%d*%d=%d
",i4,i5,i6);
return0;
}
//输出结果
normal:i1*i2=100*2=200
overflow:i4*i5=100*3=44
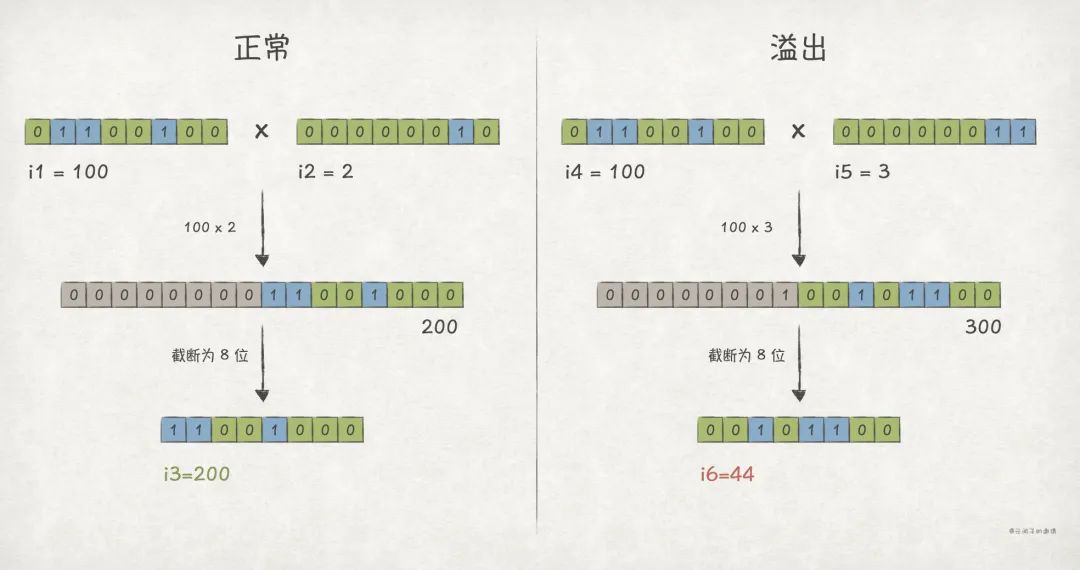
对于有符号整数,那么,即有符号整数的乘法运算结果最多也需要 2w 位来表示。
比如,w = 8 时,有符号整数的例子:
//C++
intmain(){
int8_ti1=-50;
int8_ti2=2;
int8_ti3=i1*i2;
printf("normal:i1*i2=%d*%d=%d
",i1,i2,i3);
int8_ti4=-128;
int8_ti5=127;
int8_ti6=i4*i5;
printf("overflow:i4*i5=%d*%d=%d
",i4,i5,i6);
return0;
}
//输出结果
normal:i1*i2=-50*2=-100
overflow:i4*i5=-128*127=-128

大部分机器上,乘法运算消耗 3 ~ 10 个 CPU 时钟周期,而加法运算和位运算只消耗 1 个时钟周期,所以,追求极致性能的程序都会想办法通过加法运算和位运算来替代乘法运算。
如果不考虑截断,对左移 k 位,会得到:
也即,对左移 k 位 相当于乘以。
如果考虑截断,就会存在溢出场景,对于 w 位的整数,左移 k 位效果也等同于或。
比如,w = 8 时,无符号整数的例子:
//C++
intmain(){
uint8_ti1=100;
uint8_ti2=4;
uint8_ti3=i1*i2;
printf("i1*i2=%d*%d=%d
",i1,i2,i3);
uint8_tk=2;
uint8_ti4=i1<< k;
printf("i1<< k = %d << %d = %d
",i1,k,i4);
return0;
}
//输出结果
i1*i2=100*4=144
i1<< k = 100<< 2=144
有符号整数的例子:
//C++
intmain(){
int8_ti1=-50;
int8_ti2=4;
int8_ti3=i1*i2;
printf("i1*i2=%d*%d=%d
",i1,i2,i3);
int8_tk=2;
int8_ti4=i1<< k;
printf("i1<< k = %d << %d = %d
",i1,k,i4);
return0;
}
//输出结果
i1*i2=-50*4=56
i1<< k = -50<< 2=56
那么,对于与任意常数 K 的相乘,有没可能转换为移位操作?
任意常数 K,可以表示成的形式,也即,由一系列连续的 0 和 连续的 1 组成,比如 14 可以表示成。
假设只存在一个连续的 1 序列,从高到低, 位于 n 到 m 位,比如 14 中,n = 3,m = 1,那么:
比如,就可以表示成或者:
//C++
intmain(){
int8_tx=5;
int8_tK=14;
printf("x*14=%d
",x*K);
printf("(x<<3) + (x<<2) + (x<<1) = %d
",(x<<3)+(x<<2)+(x<<1));
printf("(x<<4) - (x<<1) = %d
",(x<<4)-(x<<1));
return0;
}
//输出结果
x*14=70
(x<<3)+(x<<2)+(x<<1)=70
(x<<4)-(x<<1)=70
同理,当 K 的二进制表示,存在多个连续的 1 序列时,也成立。
除法
除法运算比乘法运算更慢,通常需要 30 个 CPU 时钟以上。同理,也可以转换成右移运算,注意结果的取整:
//C++
intmain(){
int8_tx=-50;
int8_tK=4;
printf("x/4=%d
",x/K);
printf("x>>2=%d
",x>>2);
printf("(x+(1<<2))>>2=%d
",(x+(1<<2))>>2);
uint8_ty=50;
uint8_tZ=4;
printf("y/4=%d
",y/Z);
printf("y>>>2=%d
",y>>2);
printf("(y+(1<<2))>>>2=%d
",(y+(1<<2))>>2);
return0;
}
//输出结果
x/4=-12
x>>2=-13
(x+(1<<2))>>2=-12
y/4=12
y>>>2=12
(y+(1<<2))>>>2=13
浮点数
考虑如下一段代码:
//Java
publicclassExample{
publicstaticvoidmain(String[]args){
inti=12345;
floatf=12345.0F;
System.out.printf("binarystrofi:%s
",int2BinaryStr(i));
System.out.printf("binarystroff:%s
",float2BinaryStr(f));
}
//将int转为32位的二进制表示
privatestaticStringint2BinaryStr(inti){
Stringstr=Integer.toBinaryString(i);
for(intlen=str.length();len< 32;len++){
str="0"+str;
}
returnstr;
}
//将float转为32位的二进制表示
privatestaticStringfloat2BinaryStr(floatf){
returnint2BinaryStr(Float.floatToRawIntBits(f));
}
}
我们将整数i = 12345和 浮点数f = 12345.0转成二进制表示,结果如下:
binarystrofi:00000000000000000011000000111001
binarystroff:01000110010000001110010000000000
虽然从十进制上看,值都是 12345,但是两种类型的二进制表示却差别很大,说明,计算机系统对整数和浮点数的处理是两套不同的机制。
大部分编程语言支持的整数最大是 64 位,但很多场景下,我们需要更大的取值范围,或者是小数运算,这些都是 64 位整数无法满足的场景。为了解决这些,计算机系统引入了浮点数(Floating Point)类型。
浮点数类型可以分为 32 位单精度 float/float32 类型和 64 位双精度 double/float64 类型,取值范围如下:
| 类型 | 最小值 | 最大值 |
|---|---|---|
| float | -3.40282347E+38 | 3.40282347E+38 |
| double | -1.79769313486231570E+308 | 1.79769313486231570E+308 |
虽然浮点数的取值范围很广,但它只能精确表示其中一小部分,其他都是近似表示。
下面,我们将深入介绍浮点数的二进制表示和近似规则。
简单浮点数编码
对于十进制数,可以表示成,其中,以小数点为界,左边为整数部分,右边为小数部分,那么:
比如,。
同理,对于二进制数,也可以表示成,同样以小数点分割整数和小数部分,那么:
比如,。
计算机系统的这种编码方式,注定只能表示形式的数,其他的,只能近似表示。
比如,无法精确表示 0.2:
| 二进制表示 | 分数 | 十进制表示 |
|---|---|---|
| 0.0 | 0/2 | 0.0 |
| 0.01 | 1/4 | 0.25 |
| 0.010 | 2/8 | 0.25 |
| 0.0011 | 3/16 | 0.1875 |
| 0.00110 | 6/32 | 0.1875 |
| 0.001101 | 13/64 | 0.203125 |
| 0.0011010 | 26/128 | 0.203125 |
| 0.00110011 | 51/256 | 0.19921875 |
浮点数除了表示小数之外,还须表示大数,按照这种二进制编码思路,如果要表示,需要 102 位,受限于计算机系统的编码长度,这显然不能接受。
其实,对形式的数,我们只须存储 M 和 E 即可,再来一个符号位 s,即可表示这种形式的数:。
对 w 位浮点数,可以用 1 位表示 s,用 k 位表示 E,用 n 位表示 M,那么就有 w = 1 + k + n:
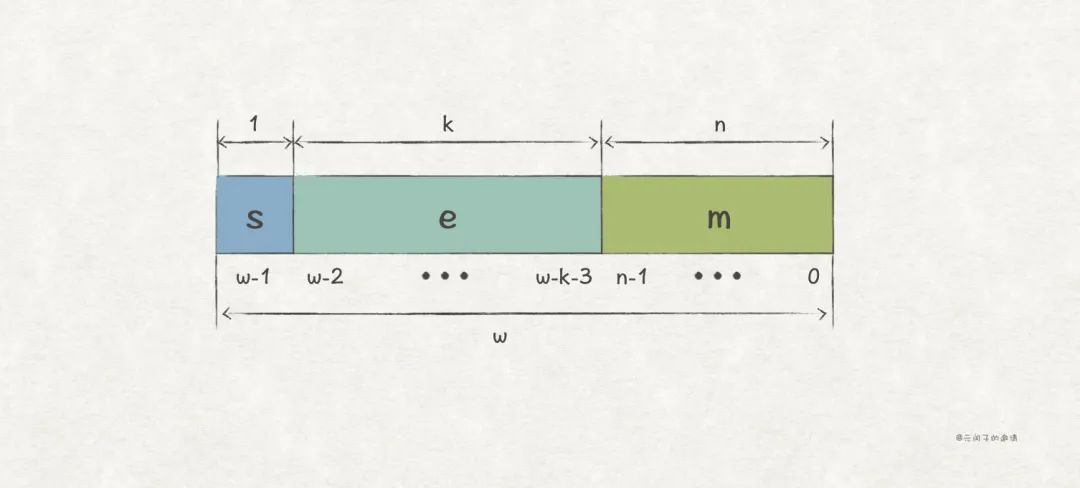
(1)s 的编码
用 0 表示正数,1 表示负数。
(2)E 的编码
二进制表示为,因为 E 可以是正,也可以是负,因此,可以直接用补码进行编码。
比如,k = 4 时,E 的取值是这样的:
| e | E |
|---|---|
| 0000 | 0 |
| 0001 | 1 |
| ... | |
| 0111 | 7 |
| 1000 | -8 |
| 1001 | -7 |
| ... | |
| 1111 | -1 |
但是,这样从到并不是递增的趋势。另一种方法是,对 e 用无符号编码,令,其中,。比如,k = 4 时,,那么 E 的取值是这样的:
| e | Bias | E |
|---|---|---|
| 0000 | 7 | -7 |
| 0001 | 7 | -6 |
| ... | ||
| 0111 | 7 | 0 |
| 1000 | 7 | 1 |
| 1001 | 7 | 2 |
| ... | ||
| 1111 | 7 | 8 |
(3)M 的编码
二进制表示为,M 不涉及负数,因此可以只用最高位表示整数,其他表示小数,即。比如,当 n = 3 时,M 的取值如下:
| m | M | 十进制 |
|---|---|---|
| 000 | 0.00 | 0.00 (0/4) |
| 001 | 0.01 | 0.25 (1/4) |
| 010 | 0.10 | 0.5 (2/4) |
| 011 | 0.11 | 0.75 (3/4) |
| 100 | 1.00 | 1.00 (4/4) |
| 101 | 1.01 | 1.25 (5/4) |
| 110 | 1.10 | 1.5 (6/4) |
| 111 | 1.11 | 1.75 (7/4) |
但是,这种编码方式会导致 0 有很多种表示。比如 w = 8,k = 4,n = 3 时,因为,所以、、等的浮点数值都是 0。
可以这么改动,令,当时,;当时,:
| e | m | M | 十进制 |
|---|---|---|---|
| 0000 | 000 | 0.000 | 0.000 (0/8) |
| 0000 | 001 | 0.001 | 0.125 (1/8) |
| ... | |||
| 0000 | 111 | 0.111 | 0.875 (7/8) |
| 0001 | 000 | 1.000 | 1.000 (8/8) |
| 0001 | 1.001 | 1.125 (9/8) | |
| ... |
这样,既解决了 0 的表示问题,又让 M 的精度更大了。
IEEE 浮点数编码
上述这些编码方法,就是 IEEE 754 Floating-Point Representation 标准中定义的浮点数编码方式的基本思路,标准会在此基础上做了一些调整,比如新增了 Infinity 和 NaN 的表示。
IEEE 标准将浮点数分成单精度和双精度两种,分别用 32 位和 64 位表示,它们的 k 值和 n 值都不同:

在此基础上,根据 e 的取值不同,又分为 3 种场景,Denormalized Values、Normalized Values、Special Values:
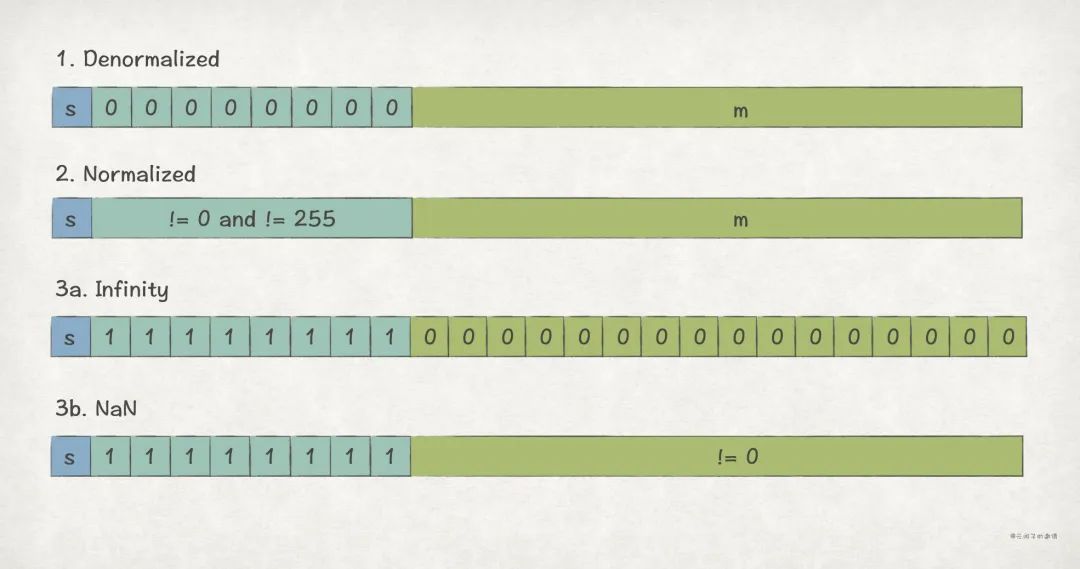
(1)Denormalized Values
此场景下,e 取值为全 0,用来表示 0 值,以及接近 0 的小数。
在的表示下,,。
为什么 ,而不是 E = -Bias?
根据前文分析,应该有 E = e - Bias,但 Denormalized Values 中,确是 E = 1 - Bias,而不是 E = 0 - Bias。
这主要考虑到,从 Denormalized Values 到 Normalized Values 的平滑过度,让 Largest Denormalized Value 和 Smallest Normalized Value 更接近。后面的举例可以看到。
这里,0 分为了 -0.0 和 +0.0,在一些科学计算场景下,它们会表示不同的含义。比如,。
(2) Normalized Values
此场景下,e 取值不是全 0,也不是全 1,是最常见的场景。
在的表示下,,。
(3)Special Values
此场景下,e 取值为全 1,用来表示 Infinity 和 NaN。
- m 取值全 0,表示 Infinity:1)s = 0 时,为;2)s = 1 时,为。
- m 取值不是全 0,表示 NaN(Not a Number),比如或者。
比如,w = 8,k = 4(此时,),n = 3 时,IEEE 标准浮点数的编码例子如下:
| 场景 | 二进制 | e | E | m | M | 十进制 | ||
|---|---|---|---|---|---|---|---|---|
| Denormalized | 0 0000 000 | 0 | -6 | 1/64 | 0/8 | 0/8 | 0/512 | 0.0 |
| 0 0000 001 | 0 | -6 | 1/64 | 1/8 | 1/8 | 1/512 | 0.001953 | |
| ... | ||||||||
| 0 0000 111 | 0 | -6 | 1/64 | 7/8 | 7/8 | 7/512 | 0.013672 | |
| Normalized | 0 0001 000 | 1 | -6 | 1/64 | 0/8 | 8/8 | 8/512 | 0.015625 |
| 0 0001 001 | 1 | -6 | 1/64 | 1/8 | 9/8 | 9/512 | 0.017578 | |
| ... | ||||||||
| 0 1110 111 | 14 | 7 | 128 | 7/8 | 15/8 | 1920/8 | 240.0 | |
| Infinity | 0 1111 000 | - | - | - | - | - | - | |
| NaN | 0 1111 001 | - | - | - | - | - | - | NaN |
| ... | NaN |
从上表可以看出,因为 Denormalized 场景下令 E = 1 - Bias,从 Denormalized 到 Normalized 的过度,也即 7/512 到 8/512,更平滑了。如果令 E = - Bias,则是从 7/1024 到 8/512,跨度太大。
到这里,我们已经深入介绍了 IEEE 浮点数编码格式,回到本节最开始的例子,如何从int i = 12345的二进制表示,推断出float f = 12345.0的二进制表示?
- 首先,12345 整数的二进制表示为,也可以表示成,对应到的形式,可以确认 s = 0,E = 13,M = 1.1000000111001。
- 另外,12345 属于 Normalized 场景,而 float 类型中 k = 8,有,,得出 e = 140,按 k 位无符号编码表示为。
- 同理,由,float 类型中,n = 23,所以,得出 m 的二进制表示为,注意,低位补零。
- 最后将 s、e、m 按照 float 单精度的编码格式组合起来,就是,也即 12345.0 的二进制编码。
近似规则(Rounding)
前面说过,浮点数只能表示形式的数,其他的,只能近似表示。
近似规则,我们最熟悉的是 “四舍五入”,比如,要保留 2 位小数,那么 1.234、1.235、1.236 近似之后分别是 1.23、1.24、1.24。
IEEE 浮点数标准中,并没采用 “四舍五入” 法,定义了如下 4 种近似规则:
- Round-to-even,往更近的方向靠,如果向上和向下的距离一样,则往偶数的方向靠。
- Round-toward-zero,往 0 的方向靠。
- Round-down,往更小的方向靠。
- Round-up,往更大的方向靠。
比如,下面的例子,需要近似为整数:
| 规则 | 1.40 | 1.60 | 1.50 | 2.50 | -1.50 |
|---|---|---|---|---|---|
| Round-to-even | 1 | 2 | 2 | 2 | -2 |
| Round-toward-zero | 1 | 1 | 1 | 2 | -1 |
| Round-down | 1 | 1 | -2 | ||
| Round-up | 2 | 2 | 3 | -1 |
这些规则对二进制也生效,比如,Round-to-even 规则,在二进制中,0 代表偶数,1 表示奇数。下面例子中,需要按照 Round-to-even 近似保留 2 位小数:
| 二进制(十进制) | 向下 | 中点 | 向上 | Round-to-even |
|---|---|---|---|---|
| 10.00011 (67/32) | 10.00 (64/32) | 68/32 | 10.01 (72/32) | 10.00 (64/32) |
| 10.00110 (70/32) | 10.00 (64/32) | 68/32 | 10.01 (72/32) | 10.01 (72/32) |
| 10.11100 (23/8) | 10.11 (22/8) | 23/8 | 11.00 (24/8) | 11.00 (24/8) |
| 10.10100 (21/8) | 10.10 (20/8) | 21/8 | 10.11 (22/8) | 10.10 (20/8) |
上述例子中,前 2 个按照就近原则近似;后 2 个处于中点位置,往偶数方向靠。
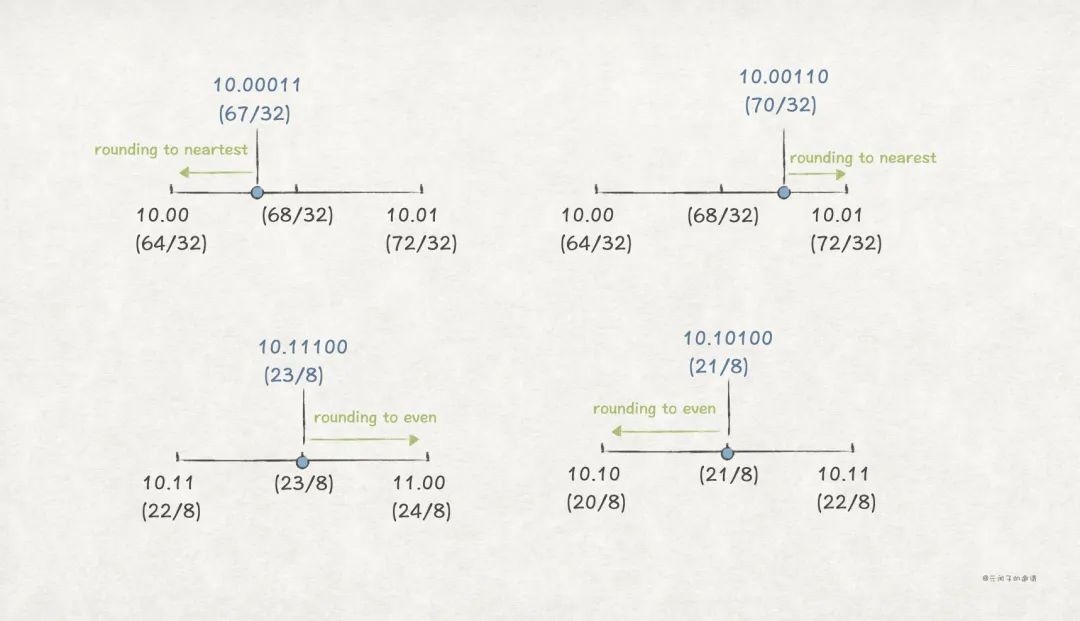
注意,IEEE 标准规定 Round-to-even 为默认的近似规则。
浮点数运算
浮点数的运算规则比较简单,令指代后一类的运算符,x 和 y 为浮点数类型,那么的运算结果为,也即对真实计算结果进行近似。
注意,算术运算的结合律、分配率在浮点数运算下是不生效的,比如:
//Java
publicstaticvoidmain(String[]args){
//结合律不满足示例
floatf1=3.14F;
floatf2=1e10F;
floatf3=(f1+f2)-f2;
floatf4=f1+(f2-f2);
System.out.printf("(3.14+1e10)-1e10=%f
",f3);
System.out.printf("3.14+(1e10-1e10)=%f
",f4);
//分配律不满足示例
floatf5=1e20F;
floatf6=f5*(f5-f5);
floatf7=f5*f5-f5*f5;
System.out.printf("1e20*(1e20-1e20)=%f
",f6);
System.out.printf("1e20*1e20-1e20*1e20=%f
",f7);
}
//输出结果
(3.14+1e10)-1e10=0.000000
3.14+(1e10-1e10)=3.140000
1e20*(1e20-1e20)=0.000000
1e20*1e20-1e20*1e20=NaN
结合律例子中,(3.14+1e10)-1e10结果是 0,因为 3.14 在近似时,精度丢失了,也即3.14+1e10=1e10;类似,分配律例子中,1e20*1e20的结果超出了 float 类型的表示范围,得到Infinity,而Infinity - Infinity的结果是NaN。
注意,**浮点数运算结果,如果超出了浮点数表示范围,会得到Infinity/-Infinity**。这与整数运算的溢出机制有所区别。
数值类型转换
数值类型间的转换,可以分成 2 类:宽转换(Widening Conversion)和窄转换(Narrowing Conversion)。
宽转换指往表示范围更广的类型转换,比如从 int 到 long、从 long 到 float;窄转换则相反。
整型间转换
(1)宽转换
整型间的宽转换不会产生溢出,无符号整数场景,高位补零;有符号整数场景,高位补符号位。
//C++
intmain(){
int8_ti1=100;
cout<< "int8_ti1:"<< bitset<8>(i1)<< endl;
cout<< "int16_ti1:"<< bitset<16>((int16_t)i1)<< endl;
int8_ti2=-100;
cout<< "int8_ti2:"<< bitset<8>(i2)<< endl;
cout<< "int16_ti2:"<< bitset<16>((int16_t)i2)<< endl;
uint8_ti3=200;
cout<< "uint8_ti3:"<< bitset<8>(i3)<< endl;
cout<< "uint16_ti3:"<< bitset<16>((uint16_t)i3)<< endl;
return0;
}
//输出结果
int8_ti1:01100100
int16_ti1:0000000001100100
int8_ti2:10011100
int16_ti2:1111111110011100
uint8_ti3:11001000
uint16_ti3:0000000011001000
(2)窄转换
整型间的窄转换直接进行高位截断,只保留低 n 位。比如 16 位的int16转换为 8 位的int8,直接保留int16类型值的低 8 位作为转换结果。
//C++
intmain(){
int16_ti1=200;
cout<< "int16_ti1:"<< bitset<16>(i1)<< endl;
cout<< "int8_ti1:"<< bitset<8>((int8_t)i1)<< endl;
int16_ti2=-200;
cout<< "int16_ti2:"<< bitset<16>(i2)<< endl;
cout<< "int8_ti2:"<< bitset<8>((int8_t)i2)<< endl;
uint16_ti3=300;
cout<< "uint16_ti3:"<< bitset<16>(i3)<< endl;
cout<< "uint8_ti3:"<< bitset<8>((uint8_t)i3)<< endl;
return0;
}
//输出结果
int16_ti1:0000000011001000
int8_ti1:11001000
int16_ti2:1111111100111000
int8_ti2:00111000
uint16_ti3:0000000100101100
uint8_ti3:00101100
(3)无符号整数与有符号整数间的转换
无符号整数与有符号整数间的转换规则是:
-
如果两者二进制位数一致,比如
int8到uint8的转换,则二进制数值不变,只是改变编码方式; -
如果位数不一致,比如
int16到uint8的转换,则二进制数值,先按照宽转换或窄转换规则转换,再改变编码方式。
//C++
intmain(){
uint8_ti1=200;
cout<< "uint8_ti1,decimal:"<< +i1 << ",binary:"<< bitset<8>(i1)<< endl;
cout<< "int8_ti1,decimal:"<< +(int8_t)i1<< ",binary:"<< bitset<8>((int8_t)i1)<< endl;
int16_ti2=-300;
cout<< "int16_ti2,decimal:"<< +i2 << ",binary:"<< bitset<16>(i2)<< endl;
cout<< "uint8_ti2,decimal:"<< +(uint8_t)i2<< ",binary:"<< bitset<8>((uint8_t)i2)<< endl;
return0;
}
//输出结果
uint8_ti1,decimal:200,binary:11001000
int8_ti1,decimal:-56,binary:11001000
int16_ti2,decimal:-300,binary:1111111011010100
uint8_ti2,decimal:212,binary:11010100
整数与浮点数间转型
(1)宽转换
整型到浮点数类型的转换这一方向,为宽转换:
- 如果浮点数的精度,能够表示整数,则正常转换。
- 如果浮点数精度,无法表示整数,则需要近似,会导致精度丢失。
//Java
publicstaticvoidmain(String[]args){
inti1=1234567;
System.out.printf("inti1:%d,floati1:",i1);
System.out.println((float)i1);
inti2=123456789;
System.out.printf("inti2:%d,floati2:",i2);
System.out.println((float)i2);
}
//输出结果
inti1:1234567,floati1:1234567.0
inti2:123456789,floati2:1.23456792E8
上述例子中,i2=123456789超过float类型能够表示的精度,所以为近似后的结果1.23456792E8。
那么,为什么123456789会近似为1.23456792E8?
要解释该问题,首先要把它们转换成二进制表示:
publicstaticvoidmain(String[]args){
...
System.out.println("inti2:"+int2BinaryStr(i2));
System.out.println("floati2:"+float2BinaryStr((float)i2));
}
//输出结果
inti2:00000111010110111100110100010101
floati2:01001100111010110111100110100011
接下来,我们根据 IEEE 浮点数的编码规则,尝试将int i2转换成float i2:
-
int i2的二进制,可以写成,对应到的形式,可以确认 s = 0,E = 26,M = 1.11010110111100110100010101。 - float 类型中 k = 8,有,,得出 e = 153,按 k 位无符号编码表示为。
- 同理,由,但由于 float 类型的 n = 23,而 m 一共有 26 位,因此需要按照 round-to-even 规则,对 0.11010110111100110100010101进行近似,保留 23 位小数,得到 0.11010110111100110100011,所以 m 为
-
最后,将 s、e、m 按照 float 单精度的编码格式组合起来,就是,转换成十进制,就是
1.23456792E8。
(2)窄转换
浮点数类型到整型的转换这一方向,为窄转换:
- 如果浮点数的整数部分,能够用整型表示,则直接舍去小数,保留整数部分。
- 如果超出了整型范围,则结果为该整型的最大/最小值。
//Java
publicstaticvoidmain(String[]args){
floatf1=12345.123F;
System.out.print("floatf1:");
System.out.print(f1);
System.out.printf(",intf1:%d
",(int)f1);
floatf2=1.2345E20F;
System.out.print("floatf2:");
System.out.print(f2);
System.out.printf(",intf2:%d
",(int)f2);
floatf3=-1.2345E20F;
System.out.print("floatf3:");
System.out.print(f3);
System.out.printf(",intf3:%d
",(int)f3);
}
//输出结果
floatf1:12345.123,intf1:12345
floatf2:1.2345E20,intf2:2147483647
floatf3:-1.2345E20,intf3:-2147483648
浮点数间转型
(1)宽转换
单精度float到 双精度double为宽转换,不会出现精度丢失的问题。
对于,规则如下:
- s 保持不变。
-
在 E 保持不变的前提下,因为
float的 k = 8,而double的 k = 11,所以两者的 e 会有所不同。 -
在 M 保持不变的前提下,
float的 n = 23,而double的 n =52,所以 m 需要低位补 52 - 23 = 29 个 0。
//Java
publicstaticvoidmain(String[]args){
floatf1=1.2345E20F;
System.out.print("floatf1:");
System.out.print(f1);
System.out.print(",doublef1:");
System.out.println((double)f1);
System.out.println("floatf1:"+float2BinaryStr(f1));
System.out.println("doublef1:"+double2BinaryStr((double)f1));
}
//输出结果
floatf1:1.2345E20,doublef1:1.2344999897320129E20
floatf1:01100000110101100010011011010000
doublef1:0100010000011010110001001101101000000000000000000000000000000000

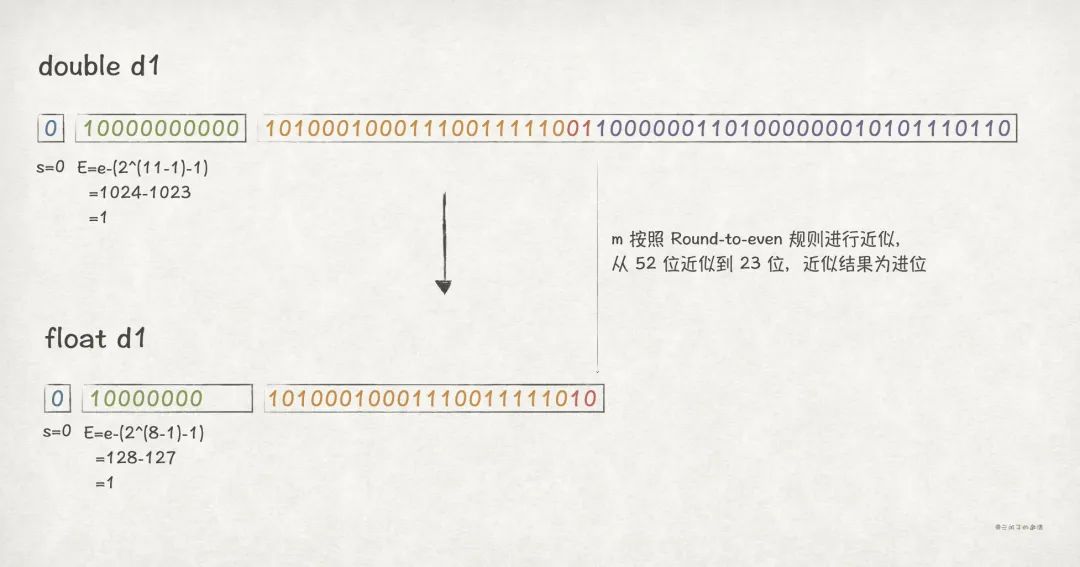
(2)窄转换
double到float为窄转换,会存在精度丢失问题。
如果double值超出了float的表示范围,则转换结果为Infinity:
//Java
publicstaticvoidmain(String[]args){
doubled1=1E200;
System.out.print("doubled1:");
System.out.println(d1);
System.out.print("floatd1:");
System.out.println((float)d1);
doubled2=-1E200;
System.out.print("doubled2:");
System.out.println(d2);
System.out.print("floatd2:");
System.out.println((float)d2);
}
//输出结果
doubled1:1.0E200
floatd1:Infinity
doubled2:-1.0E200
floatd2:-Infinity
如果double值还在float的表示范围内,则按照如下转换规则:
- s 保持不变。
-
在 E 保持不变的前提下,因为
float的 k = 8,而double的 k = 11,所以两者的 e 会有所不同。 -
对于 M,因为
float的 n = 23,而double的 n = 52,所以转换到 float 之后,需要进行截断,只保留高 23 位。
//Java
publicstaticvoidmain(String[]args){
doubled1=3.267393471324506;
System.out.print("doubled1:");
System.out.println(d1);
System.out.print("floatd1:");
System.out.println((float)d1);
System.out.println("doubled1:"+double2BinaryStr(d1));
System.out.println("floatd1:"+float2BinaryStr((float)d1));
}
//输出结果
doubled1:3.267393471324506
floatd1:3.2673936
doubled1:0100000000001010001000111001111100110000001101000000010101110110
floatd1:01000000010100010001110011111010
最后
本文花了很长的篇幅,深入介绍了计算机系统对数值类型的编码、运算、转换的底层原理。
数值类型间的转换是最容易出现隐藏 bug 的地方,特别是无符号整数与有符号整数之间的转换。所以,很多现代的编程语言,如 Java、Go 等都不再支持无符号整数,根除了该隐患。
另外,浮点数的编码方式,注定它只能精确表示一小部分的数值范围,大部分都是近似,所以才有了不能用等号来比较两个浮点数的说法。
数值类型虽然很基础,但使用时一定要多加小心。希望本文能够加深你对数值类型的理解,让你写出更健壮的程序。
文章配图
可以在用Keynote画出手绘风格的配图中找到文章的绘图方法。
参考
[1]Computer Systems: A Programmer's Perspective (3rd edition), Randal E. Bryant .etc
[2]The Java Language Specification (Java SE 18 Edition), James Gosling .etc
[3]IEEE Standard 754 Floating-Point Representation, IEEE
[4]漫话:为什么计算机用补码存储数据?, 漫话编程
审核编辑 :李倩
-
二进制
+关注
关注
2文章
795浏览量
41714 -
计算机系统
+关注
关注
0文章
289浏览量
24158 -
数值
+关注
关注
0文章
80浏览量
14384 -
代码
+关注
关注
30文章
4815浏览量
68852
原文标题:深入理解计算机系统的数值类型
文章出处:【微信号:yuanrunzi,微信公众号:元闰子的邀请】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
信号继电器在计算机系统中的应用
存储器在微型计算机系统中的作用
微处理器如何控制计算机系统
简述微型计算机系统的组成
计算机系统的组成和功能
计算机系统中的关键组件有哪些
内存容量与类型如何影响计算机性能
自然语言处理技术在计算机系统中的应用
计算机控制器的结构和功能
计算机系统由什么两部分组成 计算机系统的层次结构
计算机系统如何应对大模型时代的挑战与机遇






 工商网监
工商网监
评论