 计算机视觉中的双目立体视觉和体积度量
计算机视觉中的双目立体视觉和体积度量
导读
一个双目立体视觉的常用应用场景的介绍,很基础。
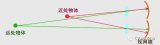
立体视觉
立体视觉意味着人工智能可以通过一对相机来感知图像的深度以及物体的距离。大多数三维相机模型都是基于立体视觉理论和技术的。两台摄像机之间设置一定的距离,这样它们就可以从不同的角度“看”物体。评估两个图像之间的对应关系,人工智能确定到目标的距离,分析,并建立目标的3D结构。
采用立体视觉,不需要红外传感器、声波定位仪、激光雷达等测距传感器,可大大降低了技术解决方案的成本。
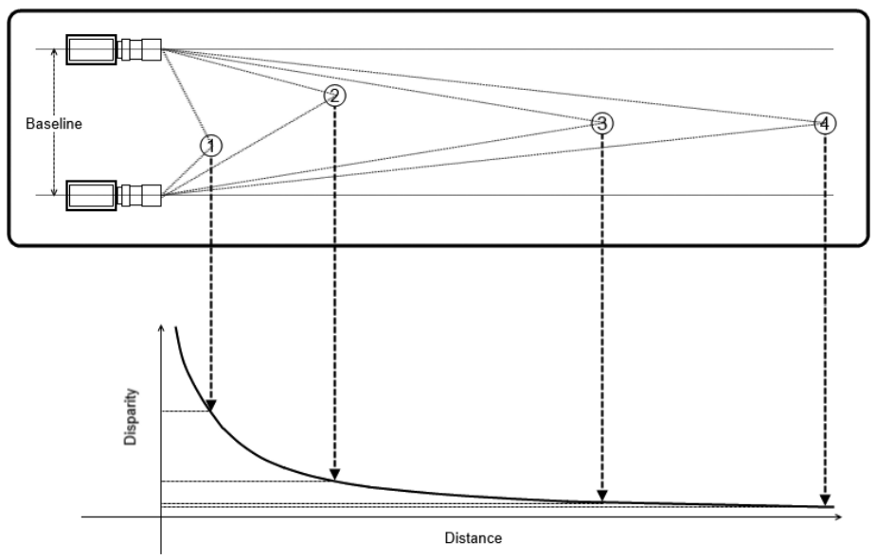
主要应用场景:
1、人体姿态和手势识别。
2、3D模型和3D场景的构建。
每个特定的场景都可以改动以解决特定的问题。因此,3D场景重建可以用来测量物体或产品的体积。
在实践中,立体视觉通过两台摄像机分四个阶段实现:
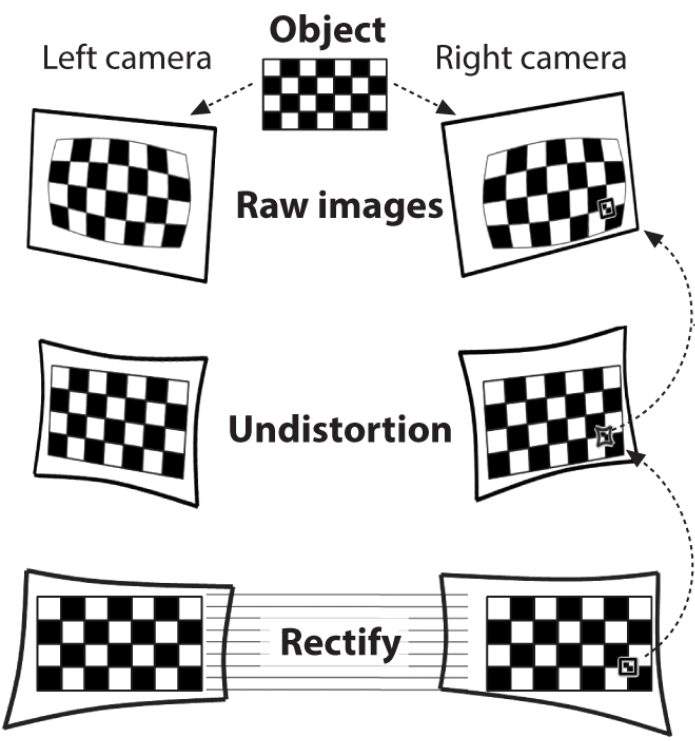
1、畸变校正 — 一种去除图像上透镜的径向和切向畸变的数学方法,以获得未失真的图像。
2、在校正过程中调整相机之间的角度和距离。结果是直线对齐和细化图像,即同一平面的两幅图像共面,其直线对齐方向相同,具有相同的y坐标。
3、点匹配过程 — 搜索左、右摄像头点之间的对应关系。在那之后,你会得到有一个视差图 —— 其中的值对应于左右摄像机同一点的图像x坐标的差异。
4、因此,有了相机的几何排列,我们产生了视差图的三角度量。这是重投影阶段,形成深度图,也就是想要的3D场景。
对于前两个阶段,你必须首先计算这一对相机的配置参数。这可以通过各种二值化的标定板自动完成,比如ArUco或ChArUco。这些标定板的主要优点是,即使是单个标定板也能提供足够的一致性来获得相机的姿势。此外,内部的二进制编码使它们特别可靠,因为它可以进行错误检测和纠正。你也可以使用标定板来确定相机下区域的几何形状。

体积度量
为了度量体积,你还需要进行下面的步骤:
1、对一组连续的帧进行累积,这将增加错误恢复的弹性,用于对3D场景进行平均或细化。
2、只在场景中选择产品定义的点。这是通过使用颜色分割、模板匹配或神经网络语义分割来实现的。最快的方法是颜色分割。该方法的缺点是将设置绑定到特定的产品上,如果背景颜色和对象不是很清楚,可能会产生不好的结果。如果GPU优化是可能的,那么使用U形卷积神经网络如U-net和高级U-net,或全卷积神经网络会有较高的性能和分割精度。
3、对一个由产品定义的3D点组成的场景进行聚类。每个簇是一个对象。


4、为每个簇形成一个凸多边形,消除3d场景对象的边缘缺陷
5、使用线性插值恢复缺失的3D点
6、通过基于场景的几何聚类区域积分来计算单个对象的体积。
7、最后,计算所有物体的总体积。
审核编辑 :李倩
-
立体视觉
+关注
关注
0文章
36浏览量
9774 -
计算机视觉
+关注
关注
8文章
1696浏览量
45930 -
自动驾驶
+关注
关注
783文章
13696浏览量
166168
原文标题:计算机视觉中的双目立体视觉和体积度量
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
计算机视觉有哪些优缺点
计算机视觉的工作原理和应用
机器人视觉与计算机视觉的区别与联系
计算机视觉与人工智能的关系是什么
计算机视觉与智能感知是干嘛的
机器视觉与计算机视觉的区别
计算机视觉的主要研究方向
计算机视觉的十大算法


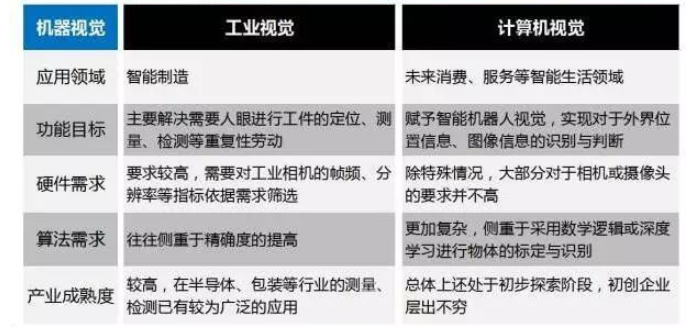
工业视觉与计算机视觉的区别
双目立体视觉是什么样的技术?





 工商网监
工商网监
评论