 有关晶体管运作的背景知识
有关晶体管运作的背景知识
在过去的 50 年中,影响最深远的技术成就可能是晶体管一如既往地稳步向更小迈进,使它们更紧密地结合在一起,并降低了它们的功耗。然而,自从 20 多年前笔者在英特尔开始职业生涯以来,我们就一直在听到警报——晶体管下降到无穷小的状态即将结束。然而,年复一年,出色的新创新继续推动半导体行业进一步发展。
在此过程中,我们的工程师不得不改变晶体管的架构,以便我们能在提高芯片性能的同时继续缩小面积和功耗。这也是推动我们将在20 世纪下半叶流行的“平面”晶体管设计在 2010 年代上半替换为3D 鳍形器件的原因。现在,FinFET也有一个结束日期,一个新的全方位 (GAA) 结构很快就会投入生产。
但我们必须看得更远,因为即使是这种新的晶体管架构(英特尔称之为 RibbonFET),我们缩小尺寸的能力也有其局限性。
那么,我们将在何时转向未来的缩放方式?我们将继续关注第三维度。我们已经创建了相互堆叠的实验设备,其提供的逻辑缩小了 30% 到 50%。至关重要的是,顶部和底部器件是两种互补类型,NMOS 和 PMOS,它们是过去几十年所有逻辑电路的基础。我们相信这种 3D 堆叠的互补金属氧化物半导体 (CMOS) 或 CFET(互补场效应晶体管)将是将摩尔定律延伸到下一个十年的关键。
晶体管的演变
持续创新是摩尔定律的重要基础,但每次改进都需要权衡取舍。要了解这些权衡以及它们如何不可避免地将我们引向 3D 堆叠 CMOS,您需要一些有关晶体管运作的背景知识。
每个金属氧化物半导体场效应晶体管或 MOSFET 都具有相同的一组基本部件:栅极叠层(gate stack)、沟道区(channel region)、源极(source)和漏极(drain)。源极和漏极经过化学掺杂,使它们要么富含移动电子(n型),要么缺乏它们(p型)。沟道区具有与源极和漏极相反的掺杂。
在 2011 年之前用于先进微处理器的平面版本晶体管中,MOSFET 的栅极堆叠位于沟道区正上方,旨在将电场投射到沟道区。向栅极(相对于源极)施加足够大的电压会在沟道区域中形成一层移动电荷载流子,从而允许电流在源极和漏极之间流动。
当我们缩小经典的平面晶体管时,一个被设备物理学家称之为“短沟道效应”的东西引起了大家的广泛关注。从基本上说,这是因为源极和漏极之间的距离变得如此之小,以至于电流会在不应该的情况下通过沟道泄漏,这主要归因于栅电极难以耗尽电荷载流子的沟道。为了解决这个问题,业界转向了一种完全不同的晶体管架构—— FinFET。它将栅极包裹在三个侧面的沟道周围,以提供更好的静电控制。
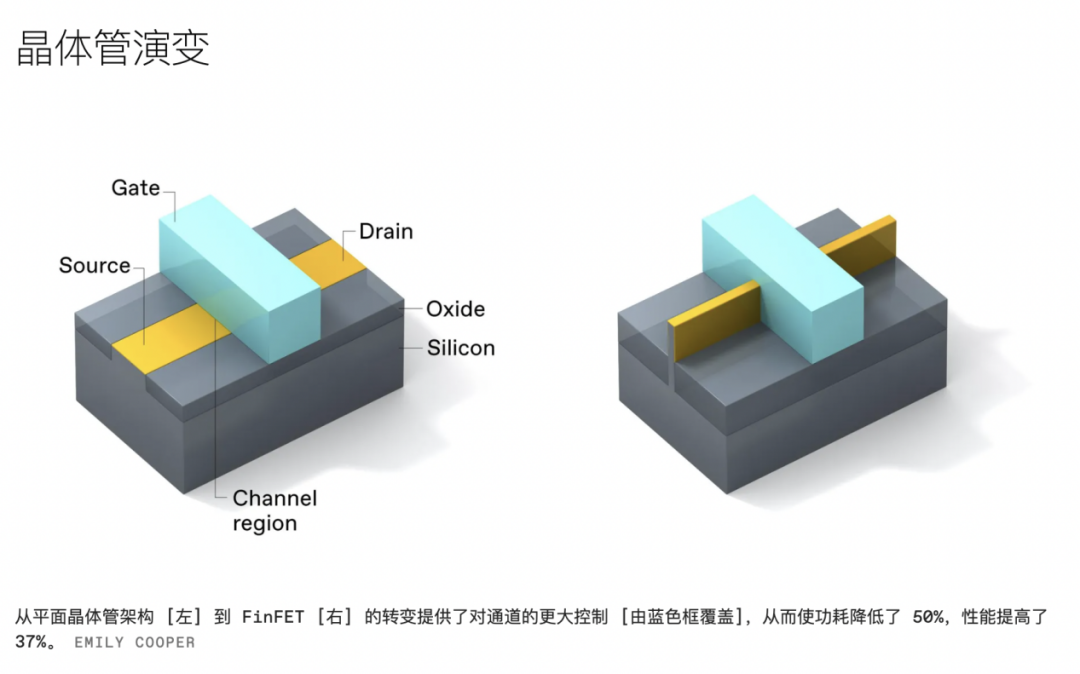
英特尔于 2011 年推出的22 纳米节点上引进了其 FinFET,并将其用于第三代酷睿处理器的生产,从那时起,该晶体管架构一直是摩尔定律的主力。使用 FinFET,我们还可以在更低的电压下运行,并且仍然具有更少的泄漏,在与上一代平面架构相同的性能水平下将功耗降低了约 50%。FinFET 的切换速度也更快,性能提升了 37%。而且由于“Fin”的两个垂直侧都发生了传导,因此与仅沿一个表面传导的平面器件相比,该器件可以通过给定的硅区域驱动更多的电流。
然而,我们在转向 FinFET 时确实失去了一些东西。在平面器件中,晶体管的宽度由光刻定义,因此它是一个高度灵活的参数。但在 FinFET 中,晶体管宽度以离散增量(discrete increments)的形式出现——一次添加一个鳍——这一特性通常被称为鳍量化(fin quantization)。尽管 FinFET 可能很灵活,但鳍量化仍然是一个重要的设计约束。围绕它的设计规则以及增加更多鳍片以提高性能的愿望增加了逻辑单元的整体面积,并使将单个晶体管变成完整逻辑电路的互连堆栈复杂化。它还增加了晶体管的电容,从而降低了它的一些开关速度。因此,虽然 FinFET 作为行业主力为我们提供了很好的服务,但仍需要一种新的、更精细的方法。
在 RibbonFET 中,栅极环绕晶体管沟道区域以增强对电荷载流子的控制。新结构还可以实现更好的性能和更精细的优化。
上述需求就推动了FinFET面世11年后,新晶体管架构RibbonFET的产生。在其中,栅极完全围绕沟道,对沟道内的电荷载流子提供更严格的控制,这些沟道现在由纳米级硅带形成。使用这些纳米带(也称为纳米片),我们可以再次使用光刻技术根据需要改变晶体管的宽度。
去除量化约束后,我们可以为应用生成适当大小的宽度。这让我们能够平衡功率、性能和成本。更重要的是,通过堆叠和并行操作的Ribbon,该设备可以驱动更多电流,在不增加设备面积的情况下提高性能。
英特尔认为 RibbonFET 是在合理功率下实现更高性能的最佳选择,他们将在 2024 年推出的Intel 20A制造工艺上引入这个晶体管架构,伴随而来的还有如英特尔的背面供电技术 PowerVia等创新。
堆叠式 CMOS
平面、FinFET 和 RibbonFET 晶体管的一个共同点是它们都使用 CMOS 技术,如上所述,该技术由n型 (NMOS) 和p型 (PMOS) 晶体管组成。CMOS 逻辑在 1980 年代成为主流,因为它消耗的电流明显少于替代技术,特别是仅 NMOS 电路。更少的电流也导致更高的工作频率和更高的晶体管密度。
迄今为止,所有 CMOS 技术都将标准 NMOS 和 PMOS 晶体管对并排放置。但在 2019 年 IEEE 国际电子器件会议 (IEDM)的主题演讲中,英特尔介绍了将 NMOS 晶体管置于 PMOS 晶体管之上的 3D 堆叠晶体管的概念。次年,在 IEDM 2020 上,英特尔展示了第一个使用这种 3D 技术的逻辑电路的设计—— inverter。结合适当的互连,3D 堆叠 CMOS 方法有效地将 inverter占位面积减半,使面积密度增加一倍,进一步突破摩尔定律的极限。
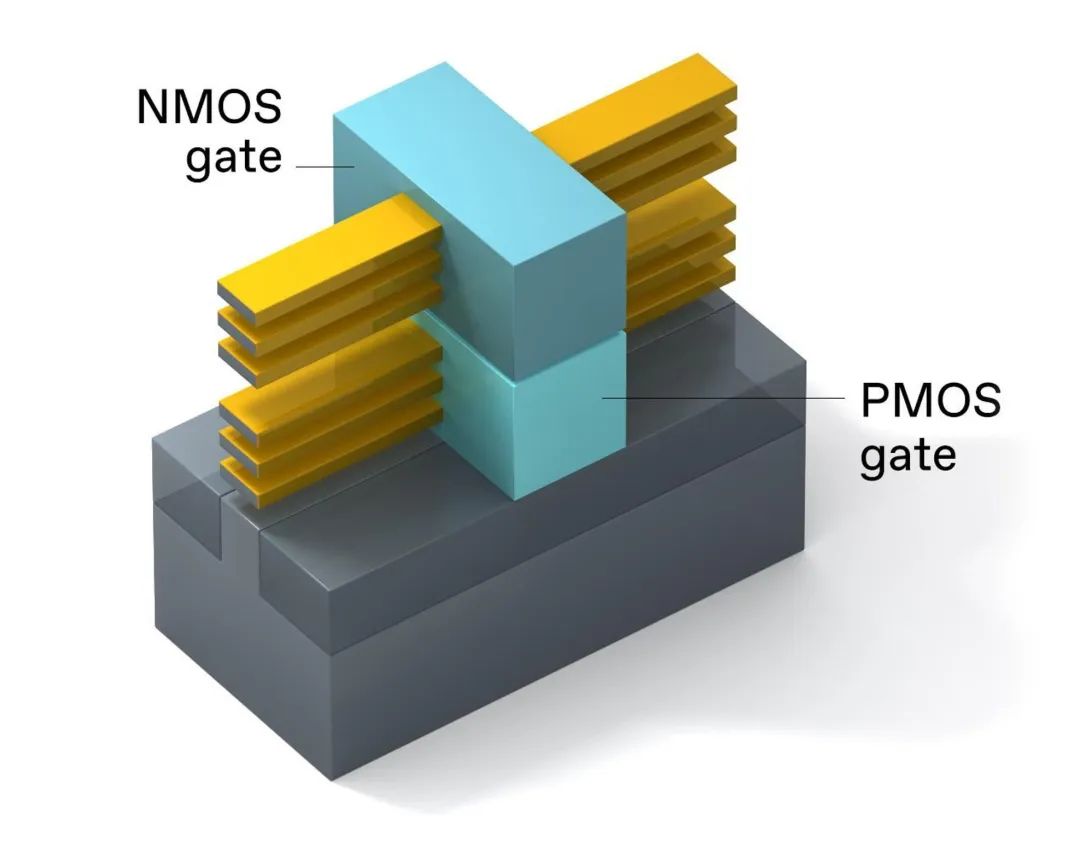
3D 堆叠 CMOS 将 PMOS 器件置于 NMOS 器件之上,其占用空间与单个 RibbonFET 相同。NMOS 和 PMOS 栅极使用不同的金属。
利用 3D 堆叠的潜在优势意味着解决许多工艺集成挑战,其中一些挑战将扩展 CMOS 制造的极限。
英特尔使用所谓的自对准工艺(self-aligned )构建了 3D 堆叠 CMOS inverter,其中两个晶体管都在一个制造步骤中构建。这意味着通过外延(晶体沉积)构建 n型和p型源极和漏极,并为两个晶体管添加不同的金属栅极。通过结合源漏和双金属栅工艺,英特尔能够创建不同导电类型的硅纳米带(p型和n型)来组成堆叠的 CMOS 晶体管对。该设计还让我们可以调整器件的阈值电压——晶体管开始开关的电压——分别针对顶部和底部纳米带。

在 CMOS 逻辑中,NMOS 和 PMOS 器件通常并排放置在芯片上。早期的原型将 NMOS 器件堆叠在 PMOS 器件之上,从而压缩了电路尺寸
英特尔是如何做到这一切的?
自对准 3D CMOS 制造始于硅晶片。在这个晶圆上,英特尔沉积了硅和硅锗的重复层,这种结构称为超晶格(superlattice)。然后,英特尔使用光刻图案切割部分超晶格并留下鳍状结构。超晶格晶体为后来发生的事情提供了强大的支撑结构。
接下来,英特尔将一块“虚拟”(dummy)多晶硅沉积在器件栅极将进入的超晶格部分的顶部,以保护它们免受该制程的下一步影响。该步骤称为垂直堆叠双源/漏极工艺(vertically stacked dual source/drain process),在顶部纳米带(未来的 NMOS 器件)的两端生长掺磷硅( phosphorous-doped silicon),同时在底部纳米带(未来的 PMOS 器件)上选择性地生长掺硼硅锗(boron-doped silicon germanium)。在这个步骤之后,英特尔在源极和漏极周围沉积电介质,以将它们彼此电隔离,然后将晶圆抛光至完美的平整度。
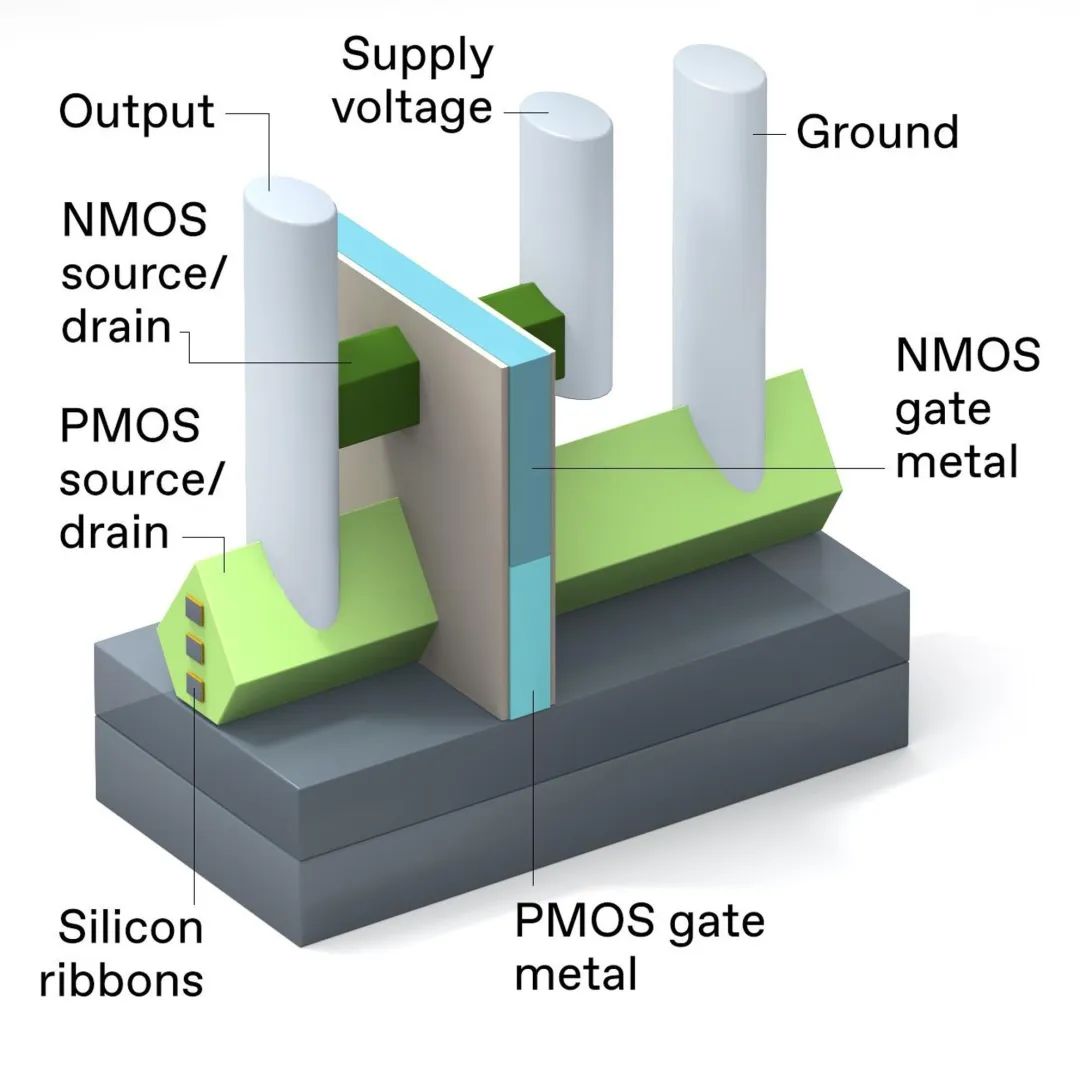
3D堆叠inverter的侧视图显示了其连接的复杂性
最后,构建栅极。
首先,我们移除我们之前放置的那个虚拟门,露出硅纳米带。接下来我们只蚀刻掉硅锗,释放出一叠平行的硅纳米带,这将是晶体管的沟道区。然后,我们在纳米带的所有侧面涂上一层薄薄的绝缘体,该绝缘体具有高介电常数。纳米带沟道是如此之小,并且以这样一种方式定位,以至于我们无法像使用平面晶体管那样有效地化学掺杂它们。相反,我们使用称为功函数(work function)的金属栅极(metal gates)特性来赋予相同的效果。我们用一种金属围绕底部纳米带以形成 p掺杂通道,用另一种金属围绕顶部纳米带形成n-掺杂通道。这样,栅叠层就完成了,两个晶体管也完成了。
这个过程可能看起来很复杂,但它比替代技术更好——一种称为顺序 3D 堆叠(sequential 3D stacking )CMOS 的技术。采用这种方法,NMOS 器件和 PMOS 器件构建在不同的晶圆上,将两者粘合,然后将 PMOS 层转移到 NMOS 晶圆上。相比之下,自对准 3D 工艺需要更少的制造步骤并更严格地控制制造成本,这是英特尔在研究中展示并在 IEDM 2019 上报告的技术。
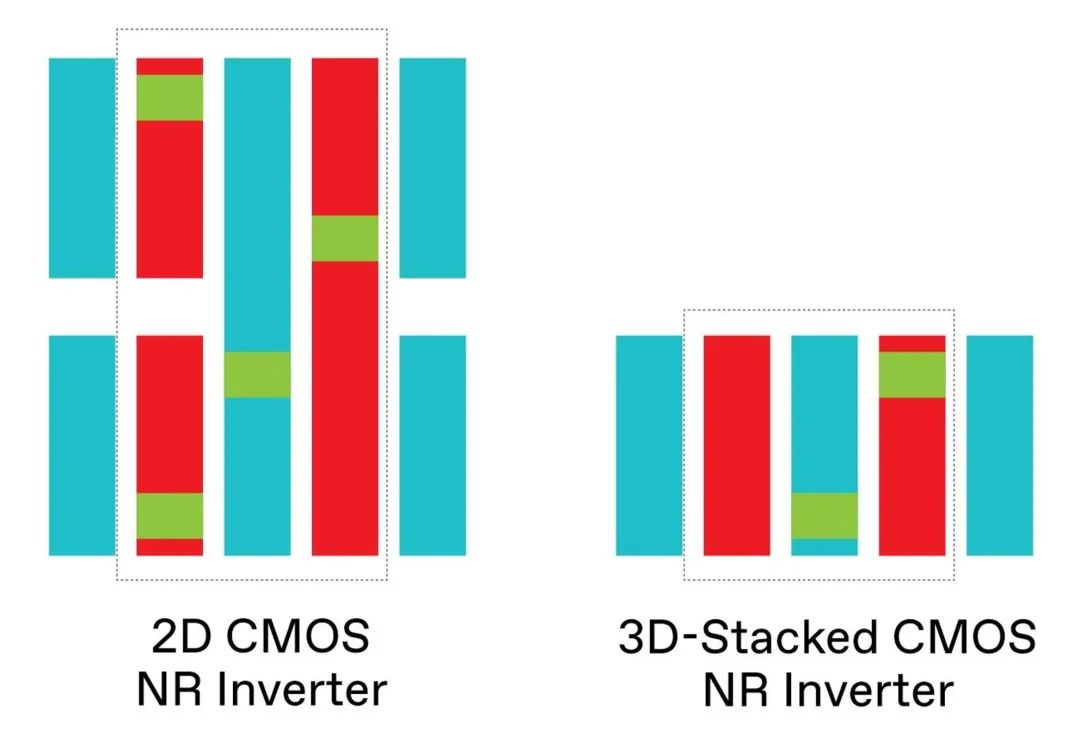
通过在 PMOS 晶体管上堆叠 NMOS,3D 堆叠有效地将每平方毫米的 CMOS 晶体管密度翻倍,尽管实际密度取决于所涉及的逻辑单元的复杂性。inverter单元从上方显示,指示源极和漏极互连 [红色]、栅极互连 [蓝色] 和垂直连接 [绿色]
重要的是,自对准方法还避免了键合两个硅片时可能发生的未对准问题。尽管如此,正在探索顺序 3D 堆叠以促进硅与非硅沟道材料(例如锗和 III-V 半导体材料)的集成。当英特尔希望能将光电子和其他功能紧密集成在单个芯片上时,这些方法和材料可能会变得相关。
新的自对准 CMOS 工艺及其创建的 3D 堆叠 CMOS 运行良好,似乎有很大的进一步小型化空间。在这个早期阶段,这是非常令人鼓舞的。具有 75 nm 栅极长度的器件展示了具有出色器件可扩展性和高导通电流的低泄漏。另一个有希望的迹象:英特尔已经制造出两组堆叠器件之间的最小距离仅为 55 nm的晶圆。虽然其获得的器件性能结果本身并没有记录,但它们确实与构建在相同硅片上且具有相同处理的单个非堆叠控制器件相比较。
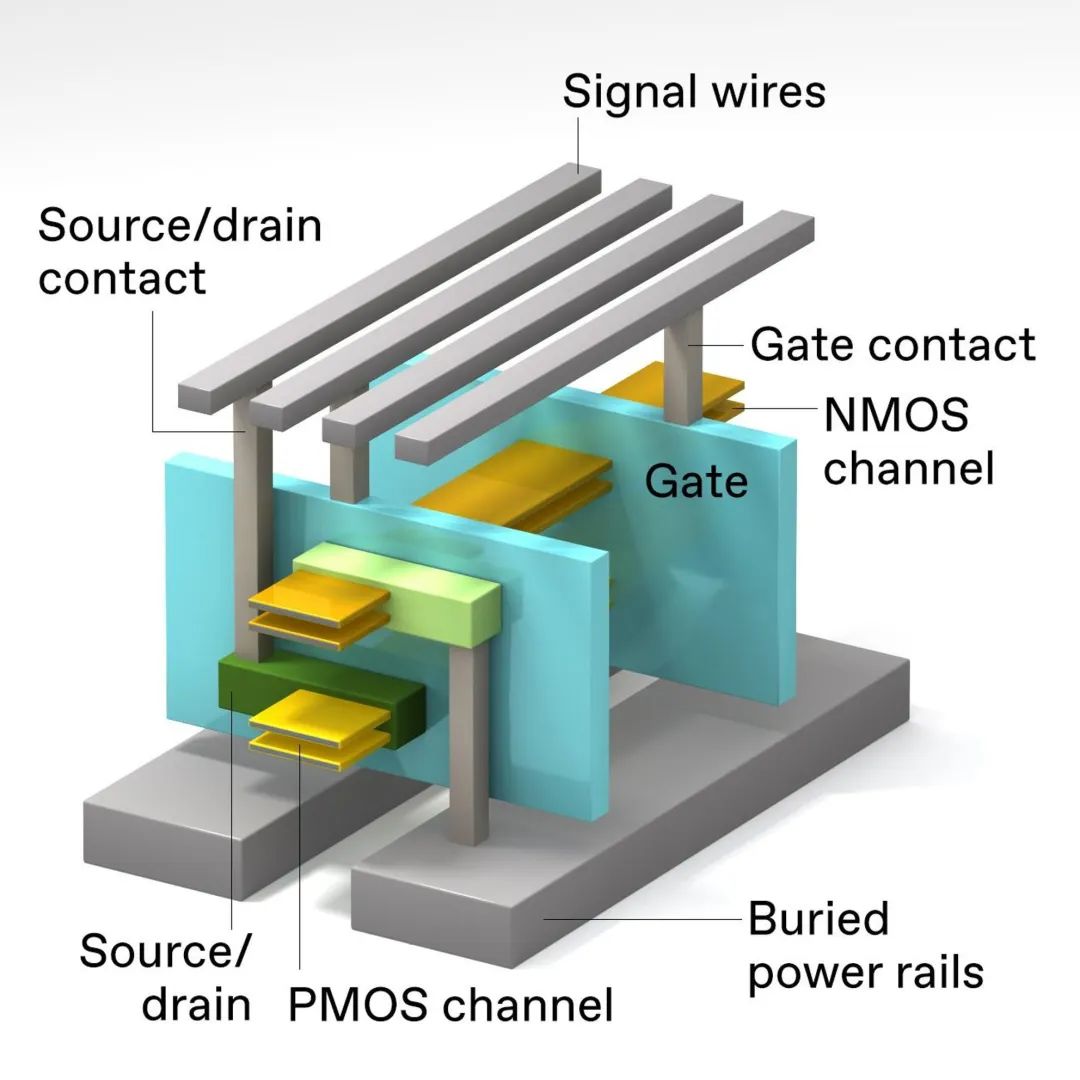
对 3D 堆叠 CMOS 进行所有需要的连接是一项挑战。需要从设备堆栈下方进行电源连接。在此设计中,NMOS 器件 [顶部] 和 PMOS 器件 [底部] 具有单独的源极/漏极触点,但两个器件都有一个共同的栅极
在工艺集成和实验工作的同时,英特尔正在进行许多理论、模拟和设计研究,以期深入了解如何最好地使用 3D CMOS。通过这些,英特尔发现了晶体管设计中的一些关键考虑因素。值得注意的是,我们现在知道我们需要优化 NMOS 和 PMOS 之间的垂直间距——因为如果太短会增加寄生电容,但如果太长会增加两个器件之间互连的电阻。任何一种极端都会导致更慢的电路消耗更多功率。
许多设计研究(例如美国 TEL 研究中心在 IEDM 2021上提出的一项研究)专注于在 3D CMOS 的有限空间内提供所有必要的互连,并且这样做不会显著增加它们构成的逻辑单元的面积。TEL 研究表明,在寻找最佳互连选项方面存在许多创新机会。该研究还强调,3D 堆叠 CMOS 将需要在设备上方和下方都有互连。这种方案,称为埋地电源轨,采用为逻辑单元供电但不传输数据的互连,并将它们移至晶体管下方的硅片上。英特尔的 PowerVIA 技术正是这样做的,计划于 2024 年推出,因此将在使 3D 堆叠 CMOS 商业化方面发挥关键作用。
摩尔定律的未来
借助 RibbonFET 和 3D CMOS,英特尔有一条将摩尔定律延伸到 2024 年之后的清晰道路。在2005 年的一次采访中,在被要求反思什么成就了他的定律的时候,戈登摩尔承认“不时惊讶于我们如何能够取得进展。在此过程中,有好几次,我以为我们已经走到了终点,事情逐渐减少,但我们的创意工程师想出了解决办法。”
随着向 FinFET 的转变、随之而来的优化,以及现在 RibbonFET 的发展以及最终 3D 堆叠 CMOS 的发展,以及围绕它们的无数封装改进的支持,我们认为 Moore 先生会再次感到惊讶。
审核编辑 :李倩
-
CMOS
+关注
关注
58文章
5708浏览量
235384 -
摩尔定律
+关注
关注
4文章
634浏览量
78986 -
晶体管
+关注
关注
77文章
9679浏览量
138050
原文标题:3D堆叠CMOS,晶体管的未来
文章出处:【微信号:AMTBBS,微信公众号:世界先进制造技术论坛】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
晶体管与场效应管的区别 晶体管的封装类型及其特点
晶体管的输出特性是什么
NMOS晶体管和PMOS晶体管的区别
CMOS晶体管和MOSFET晶体管的区别
晶体管处于放大状态的条件是什么
芯片晶体管的深度和宽度有关系吗
芯片中的晶体管是怎么工作的
什么是NPN晶体管?NPN晶体管的工作原理和结构
PNP晶体管符号和结构 晶体管测试仪电路图
如何提高晶体管的开关速度,让晶体管快如闪电

什么是达林顿晶体管?达林顿晶体管的基本电路





 工商网监
工商网监
评论