 2PFLOPS,存算一体迎来新的卷王
2PFLOPS,存算一体迎来新的卷王
存算一体技术作为当下内存厂商和不少AI芯片公司都在全力钻研的方向,已经有了不少成果展示,下一代智能存储的产品均已呼之欲出了。但新技术的新生期就是这样,不断有新的初创企业冒头,不断有新的架构和路线面世,而今年的HotChips34上,就有这么两个存算一体技术的分享,在现有的存算一体生态上做出了创新,再度为这条赛道上的激烈竞争添油加醋。
1PB/s带宽的千核RISC-V AI推理加速器
存算一体技术需要解决的,往往都是AI运算上的问题,比如训练和推理等等,所以不少做存算一体公司与AI芯片公司并无二致。而AI推理的出现为芯片设计者提出了三大关键挑战,一是不断提升的算力和功耗要求,不说是存算一体芯片了,GPU、FPGA、ASIC等AI加速器都在往这个方向卷;二是神经网络的格局一直在变化,现有的芯片可能缺乏跟上节奏的扩展性和灵活性;第三则是推理精度的缺失,在某些业务中精度的缺失可能只是意味着亏损,但在ADAS这样的应用中,就很有可能危及人身安全。
加拿大本土AI初创公司Untether AI就打算从计算的角度来解决AI推理问题,早在2020年他们就推出了runAI200这款加速器芯片,不过该芯片基于台积电16nm工艺,集成了200MB的SRAM,算力最高也只有500 TOPS(INT8),显然不能满足高性能的AI推理需求,但他们的思路却从一开始就和其他存算一体公司不同。
我们常见的存算一体技术无疑就是近存计算和存内计算这两种,前者基于冯诺依曼架构,主要还是完成加快数据转移的过程,后者通过模拟技术来完成乘法累加运算,再利用数字处理器来完成其他运算。
Untether AI却提出了存间计算(At-MemoryComputation),将双向的计算逻辑单元放在SRAM之间。如此一来不仅能提供大规模并行却又简短的直接连接,也能提供独立优化过的内存,提升效率和带宽,根据Untether AI所说,存间计算恰好能够解决AI加速的痛点。
1PB/s带宽的千核RISC-V AI推理加速器
存算一体技术需要解决的,往往都是AI运算上的问题,比如训练和推理等等,所以不少做存算一体公司与AI芯片公司并无二致。而AI推理的出现为芯片设计者提出了三大关键挑战,一是不断提升的算力和功耗要求,不说是存算一体芯片了,GPU、FPGA、ASIC等AI加速器都在往这个方向卷;二是神经网络的格局一直在变化,现有的芯片可能缺乏跟上节奏的扩展性和灵活性;第三则是推理精度的缺失,在某些业务中精度的缺失可能只是意味着亏损,但在ADAS这样的应用中,就很有可能危及人身安全。
加拿大本土AI初创公司Untether AI就打算从计算的角度来解决AI推理问题,早在2020年他们就推出了runAI200这款加速器芯片,不过该芯片基于台积电16nm工艺,集成了200MB的SRAM,算力最高也只有500 TOPS(INT8),显然不能满足高性能的AI推理需求,但他们的思路却从一开始就和其他存算一体公司不同。
我们常见的存算一体技术无疑就是近存计算和存内计算这两种,前者基于冯诺依曼架构,主要还是完成加快数据转移的过程,后者通过模拟技术来完成乘法累加运算,再利用数字处理器来完成其他运算。
Untether AI却提出了存间计算(At-MemoryComputation),将双向的计算逻辑单元放在SRAM之间。如此一来不仅能提供大规模并行却又简短的直接连接,也能提供独立优化过的内存,提升效率和带宽,根据Untether AI所说,存间计算恰好能够解决AI加速的痛点。
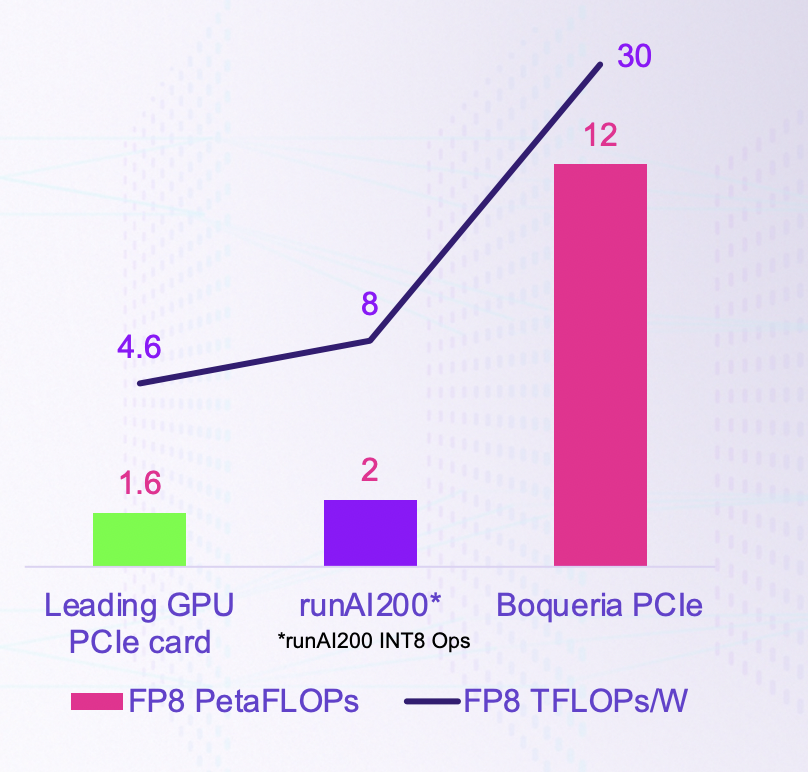
Boqueria与竞品的对比/ Untether AI
为此,Untether AI推出了Boqueria,一个算力高达2PFLOPS、能效比高达30TFLOPS/W的存间计算AI推理加速器芯片。Boqueria基于台积电7nm打造,频率高达1.35GHz,集成了729个存储体、238MB的片上SRAM和1458个RISC-V核心,SRAM内存带宽可以达到1PB/s。
每个存储体中包含2个RISC-V核心,各管理4个行控制器。行控制器之间独立运行,每个行控制器控制64个SIMD处理单元,用于完成矩阵向量乘法运算。这些处理单元支持INT4、INT8、FP8和BF16这四种常见数据格式,而且依Untether AI看来,FP8是精度、吞吐量和能效平衡上最好的一个,更不用说Untether AI在处理单元上加入了零检测,进一步拉高了能效比。
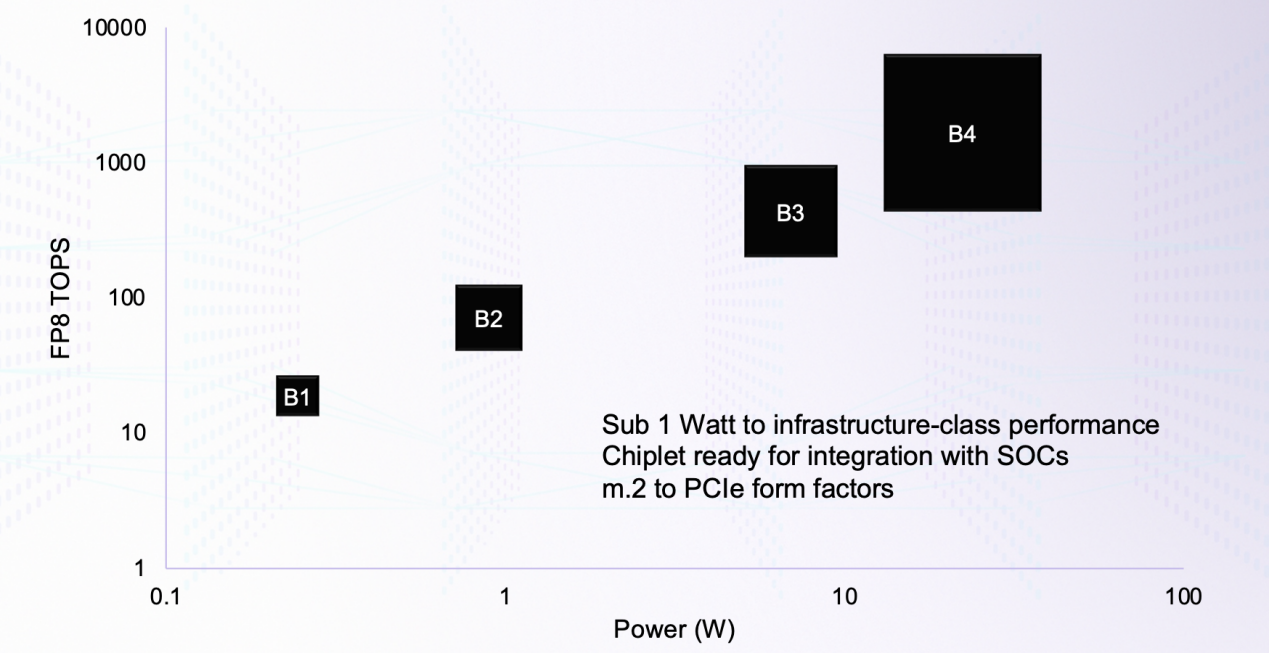
Boqueria架构不同规模下的功耗与算力对比/ Untether AI
Boqueria上的RISC-V核心由Untether AI自己客制化的,本身基于RV32EMC指令集的同时,还加入了20多条专用于存间计算和推理加速的指令。Boqueria的另一大优势,就是它极具扩展性的架构。最小的结构可以做到1W以下,也可以将其做成Chiplet集成在其他SoC中,或者是再大一点的M.2卡、PCIe5.0卡等。要想追求最高的性能,可以做成集成6个Boqueria芯片的PCIe5.0卡,SRAM容量可达1.4GB,LPDDR5 DRAM容量可达192GB,FP8算力可达12PFLOPS,更不用说除了芯片到芯片之间的通信外,Boqueria也支持PCIe卡之间的通信。
神经形态存内计算处理器
韩国科学技术院的研究团队在本届HotChips上展示了一种新型的存算一体处理器,结合了时下两大新技术,神经形态和存内计算。传统的存内计算处理器由于在矩阵乘法上的优势,可以为深度学习解决最大的计算问题。可这个计算结果的准确性很大程度取决于处理器上DAC和ADC的精度。
可DAC和ADC的精度越高,模拟计算的结果也就越精确,也使得处理器的硬件开销变高,无论是功耗还是面积都是如此,甚至有可能抵消存内计算原本的硬件优势。在整个处理器的功耗中,高精度的ADC甚至可能会占据一半以上的功耗,甚至超过驱动器和控制器的总和。
不仅如此,在真实应用中由于低稀疏度,其能效比也远不如纸面数据那么理想,比如面对CIFAR-10或ImageNet等数据集时,其能效比甚至可能会缩水到十分之一,彻底毁掉了存内计算处理器在算力和能耗上的双重优势。
于是韩国科学技术院团队考虑用二进制脉冲信号的事件驱动运算来生成输入稀疏,并将卷积神经网络转换成脉冲神经网络,从而剔除ADC/DAC,并引入了四大特性。比如用最高有效位WordSkipping和早停法来减少位线活动,从而降低各种模式下的功耗,并用混合模式的神经元放电和电压折叠技术,将该处理器的动态电压范围提高至3倍。

传统存内计算架构与神经形态存内计算架构对比/ 韩国科学技术院
如此一来,他们打造出了一个高能效的神经形态存内计算架构,存内计算减少内存访问和多字线驱动的优势依然保留,但脉冲神经网络的加入,却消除了高精度ADC的需求。他们根据这一架构打造出了一个基于28nm工艺的存内计算芯片,总存储大小只有32KB,频率也只有200MHz,却可以在100到200mW的系统功耗下,实现最高310.4 TOPS/W的高能效比。考虑到这一研究本身也是由三星赞助,这一思路未来很有可能被用于三星的MRAM存内计算芯片中去,届时才会考虑使用更优的工艺来实现更高的性能,并做到更大的容量。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
内存
+关注
关注
8文章
3028浏览量
74075 -
AI
+关注
关注
87文章
30946浏览量
269186 -
存算一体
+关注
关注
0文章
102浏览量
4302
发布评论请先 登录
相关推荐
开源芯片系列讲座第24期:基于SRAM存算的高效计算架构
鹭岛论坛开源芯片系列讲座第24期「基于SRAM存算的高效计算架构」明晚(27日)20:00精彩开播期待与您云相聚,共襄学术盛宴!|直播信息报告题目基于SRAM存算的高效计算架构报告简介

直播预约 |开源芯片系列讲座第24期:SRAM存算一体:赋能高能效RISC-V计算
鹭岛论坛开源芯片系列讲座第24期「SRAM存算一体:赋能高能效RISC-V计算」11月27日(周三)20:00精彩开播期待与您云相聚,共襄学术盛宴!|直播信息报告题目SRAM存
存算一体化与边缘计算:重新定义智能计算的未来
随着数据量爆炸式增长和智能化应用的普及,计算与存储的高效整合逐渐成为科技行业关注的重点。数据存储和处理需求的快速增长推动了对计算架构的重新设计,“存算一体化”技术应运而生。同时,随着物联网、5G网络

存算一体架构创新助力国产大算力AI芯片腾飞
在湾芯展SEMiBAY2024《AI芯片与高性能计算(HPC)应用论坛》上,亿铸科技高级副总裁徐芳发表了题为《存算一体架构创新助力国产大算力AI芯片腾飞》的演讲。
科技新突破:首款支持多模态存算一体AI芯片成功问世
存算一体介质,通过存储单元和计算单元的深度融合,采用22nm成熟工艺制程,有效把控制造成本。与传统架构下的AI芯片相比,该款芯片在算力、能效比,功耗等方面都具有明显的优势。芯片采用AI
发表于 09-26 13:51
•411次阅读

后摩智能首款存算一体智驾芯片获评突出创新产品奖
近日,2024年6月29日,由深圳市汽车电子行业协会主办的「第十三届国际汽车电子产业峰会暨2023年度汽车电子科学技术奖颁奖典礼」在深圳宝安隆重举行。后摩智能首款存算一体智驾芯片——后摩鸿途®️H30 获评「突出创新产品奖」。
苹芯科技引领存算一体技术革新 PIMCHIP系列芯片重塑AI计算新格局
智能芯片国产化再传利好,8月8日,国际领先的存算一体芯片开拓者——苹芯科技在北京召开 “存算于芯 智启未来——2024 苹芯科技产品发布会”
发表于 08-08 17:21
•267次阅读

后摩智能推出边端大模型AI芯片M30,展现出存算一体架构优势
电子发烧友网报道(文/李弯弯)近日,后摩智能推出基于存算一体架构的边端大模型AI芯片——后摩漫界™️M30,最高算力100TOPS,典型功耗12W。为了进
知存科技助力AI应用落地:WTMDK2101-ZT1评估板实地评测与性能揭秘
突破正迎合市场需求,使存算一体技术迎来了产业化的拐点。新兴企业在探索新技术应用和大算力布局方面更具前瞻性。随着技术和应用的不断成熟,这些企业
发表于 05-16 16:38
探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究
本文深入探讨了基于SRAM和MRAM的存算一体技术在计算领域的应用和发展。首先,介绍了基于SRAM的存内逻辑计算技术,包括其原理、优势以及在神经网络领域的应用。其次,详细讨论了基于MR

知存科技携手北大共建存算一体化技术实验室,推动AI创新
揭牌仪式结束后,王绍迪在北大集成电路学院举办的“未名·芯”论坛上做了主题演讲,分享了他对于多模态大模型时代存内计算发展的见解。他强调了存算一体
北京大学-知存科技存算一体联合实验室揭牌,开启知存科技产学研融合战略新升级
5月5日,“北京大学-知存科技存算一体技术联合实验室”在北京大学微纳电子大厦正式揭牌,北京大学集成电路学院院长蔡一茂、北京大学集成电路学院副

什么是通感算一体化?通感算一体化的应用场景
通感算一体化可广泛应用于智能家居、智慧城市、智慧交通、医疗健康等方面。文档君为大家搜集了一些典型的应用场景。 智能家居 通感算一体化利用基站
发表于 01-18 16:12
•1.1w次阅读

存算一体芯片如何支持Transformer等不同模型?
后摩智能致力于打造通用人工智能芯片,自主研发的存算一体芯片在支持各类模型方面表现突出,包括YOLO系列网络、BEV系列网络、点云系列网络等。
SRAM存算一体芯片的研究现状和发展趋势
人工智能时代对计算芯片的算力和能效都提出了极高要求。存算一体芯片技术被认为是有望解决处理器芯片“存储墙”瓶颈,大幅提升人工智能算力能效和





 工商网监
工商网监
评论