 怎么看见和定量分析验证平台的时间呢
怎么看见和定量分析验证平台的时间呢

我们说的“提速”到底提的是什么时间?
1、验证仿真中的“3个时间”
在验证仿真过程中,我们脑中需要闪过至少3个概念:
cpu时间(cpu time)
仿真时间(simulation time)
他们都是什么呢?
1.墙上时钟时间(wall clock time):
顾名思义,它是“挂在墙上的时钟”的时间,这个时间也就是我们真实世界真正“走过的时间”。
你跑一个case,对于linux系统来说,就是一个或多个进程,而这个wall clock time,它是进程运行的时钟总量。它除了包括cpu真正的运行时间之外,还包括了如:
就绪时间:
进程具备运行条件,但是还没有CPU资源可用。例如你提交了一个case,但是半天提不上去跑不起来,可能因为其他人的case太多,导致机器满载了,等别人释放了之后你的case才真正获得cpu资源运行起来。
阻塞时间:
例如你的case已经跑起来了,发现某个vip lisence不够了,“卡”到那里了。
或者例如你编译运行过程中因为磁盘不太充足出现的卡顿现象等。
2.cpu时间(cpu time):
当进程运行起来之后,占用cpu进行计算花费的时间。同样是代码在cpu上运行,依据代码类别不同,cpu时间也分为用户cpu时间和系统cpu时间。
用户cpu时间是代码在用户态(User Mode)运行的时间。
系统cpu时间是代码在内核态(Kernel Mode)运行的时间。
我们可以简单理解:依据代码权限不同,用户态执行用户代码,内核态执行的是操作系统代码。这里不深入展开了,感兴趣的朋友可以查阅一些资料(为什么这里要多引申提一下这个概念,主要帮没有听过这些概念的朋友,在仿真性能分析报告中如果碰到相关词汇,至少可以有一个简单的感性认知)。
此外,从前面的wall clock time解释可以看出,比如你的case被阻塞了、挂起了是不占用cpu时间的,但是真实时间还是继续走的。有兄弟可能会问:“照这么说,wall clock time是不是肯定是大于cpu time?”
答案是:不一定。
如果是多核处理器机器上,cpu总时间是所有不同线程或进程cpu时间之和,此时wall clock time时间就会比cpu总时间小了。其实依据wall clock time和cpu总时间的关系,也把进程分为计算密集型(wall clock time小于cpu time,有多核并行的优势)和I/O密集型(wall clock time大于cpu time,没有多核优势,很多等待时间)。
举一个例子,如下截图,VCS软件对于verilog设计部分的编译过程中,允许通过-j选项指定并行数量。在选择合适的并行数量的情况下,相关部分编译的wall clock time就会小于cpu time哦~

3.仿真时间(Simulation time)
仿真时间是仿真器维护的时间,就是我们波形中看到的那个多少ns多少ps那个时间,它显然不是仿真过程中真实的时间。这个时间是为了表示实际电路的运行时间,给电路仿真建模用的一个“数字”。
我们知道SystemVerilog是在值的更新、计算等一个个离散事件的相互触发“推着”往前走的(推着走的单位就是也就是我们之前讲过的global time precision,也就是timeslot)。
所以仿真时间长短和运行时间长短、仿真速度没什么关系,主要是看“步子”有多少。在其他所有因素都一样的情况下,谁的事件少、推的步子少谁仿真的速度也就更快。
再举个例子:`timescale 1ns/1ps 和`timescale 10ns/10ps,它们的time unit和time precision都同时扩大了10倍,但它们的比值是一样的,即“步子”数量是一样的。在其他背景完全一样的相同仿真单位度量情况下(这里指的不带具体单位,如,#1;前者代表运行1ns后者表示运行10ns),仿真速度是一样的。
Tips:我们说平台提速到底要提哪个时间?
刚才Jerry给大家抛出了验证仿真的“3个时间”,我们回到本系列文章“验证仿真提速”主题,抛出一下最底层的问题:我们追求“提速”,根本目标是想要减少哪个时间?
没错,我们追求的最根本目标是减少墙上时钟时间(wall clock time),即我们需要的是减少自己浪费的真实世界的时间,多跑几轮case或者早点跑出结果早下班。如果你费尽心思减少cpu time、仿真时间,最后wall clock time没有降下来对于我们有个毛线意义??虽然如前面有提到这3个时间有相关性,但是希望大家心中一定要明确我们的根本目标。
2、怎么看见和定量分析验证平台的时间?
有了前面的认知铺垫,我们回到实战。如何定量分析验证平台的时间和资源,我们以VCS工具为例(其他家工具大家自行探索),一般可以有两种抓取性能信息的方式,一种是以“轻量级”的方式输出编译和运行仿真过程中的性能汇总信息,一种是相对“重量级”的方式进一步详细分析仿真运行性能信息。第二种为什么说比较“重量级”呢?主要原因是它本身就会造成很大的时间消耗。我们都简要介绍一下:
1.以“轻量级”的方式输出编译和运行仿真过程中的性能汇总信息。
增加vcs编译选项: -reportstats
增加simv仿真选项:-reportstats
工具将会直接把编译和运行的汇总性能报告直接打印在屏幕上,我们示意性跑出来的一组截图如下:
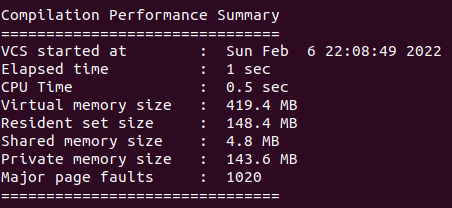
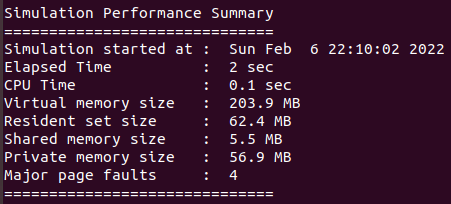
上面的主要细节vcs手册解释原文如下:
• VCS start time
• Elapsed real time: wall clock time from VCS start to VCS end
• CPU time: Accumulated user time + system time from all
processes spawned from VCS
• Peak virtual memory size summarized from all the contributing
processes at specific time points
• Sum of resident set size from all the contributing processes at
specific time points
• Sum of shared memory from all the contributing processes at
specific time points
• Sum of private memory from all the contributing processes at
specific time points
• Major fault accumulated from all processes spawned from VCS
我们本篇主要关心时间,有了前文的铺垫相信这里可以看得比较清楚了。
从上面的解释可知:Elapsed real time就是编译或运行阶段的墙上时钟时间(wall clock time),cpu time是vcs产生所有进程的用户cpu时间和系统cpu时间总和。
顺便,从这个举例的截图报告也可以明显看出wall clock time大于cpu time,没有任何多核优势,属于I/O密集型。
这里提一个点,我们前面讨论3种时间的时候可以了解到:即使是跑同样的case,用同样的种子,跑出来的时间统计信息也一定会因为磁盘状态等原因而不同。所以对于测试某种手段是否减少了总时间花费,是否有收益(尤其是不太明显的手段),单纯的通过前后两次跑同样的case,对比统计结果是不足以判别的,如果不是明显的提速手段,可能会出现使用后wall clock time和cpu time反而比使用前花费更多时间。但是如果基于相同的服务器等因素的状态,或基于统计的方式多次测试评估,就可以看出总体速度的提升趋势。
2.以相对“重量级”的方式进一步详细分析仿真运行的性能信息。
增加vcs编译选项 -lca -simprofile
增加simv仿真选项 -simprofile time
(这个仿真选项后面除了跟time观测仿真时间信息还可以加:如mem收集服务器内存消耗信息等,当然也可以如time+mem同时收集) 这些选项加了之后,工具会生成如下带“profile”关键词的文件和文件夹,我们主要看profileReport.html文件。

html文件打开后会发现分左右两个区域,通过左边区域可以控制出现在右边区域你想要看到的性能信息,示意图如下:

Jerry通过time+mem的选项,随意跑了一个case,相关的summary示意图如下:
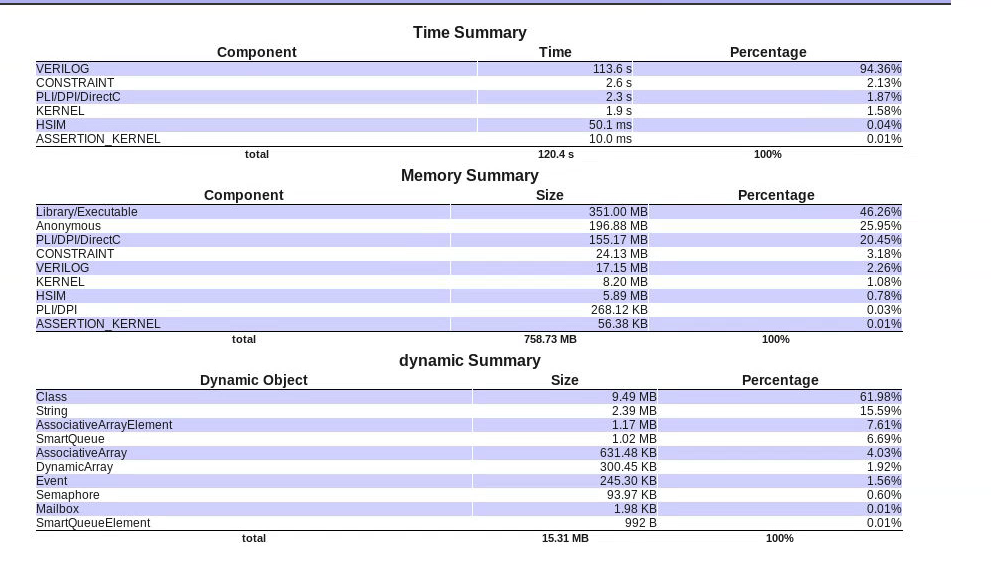
我们还是关心time,主要贴下time的相关copmponent的含义(下面有的条目在上图例子中不涉及,别的case也许就会有):
•CONSTRAINT
The CPU time needed to solve and simulate the SystemVerilog constraint blocks.
•KERNEL
The CPU time needed by the VCS kernel. This CPU time is separate from the CPU time needed to simulated your Verilog or SystemVerilog, VHDL, SystemC, or C or C++ code for your design and testbench.
•VERILOG
The CPU time needed by VCS to simulate this example’s SystemVerilog code, which is a program block. For Verilog and SystemVerilog there are sub-components.
•DEBUG
The CPU time needed by VCS to simulate this example with the debugging capabilities of Verdi and the UCLI or to write a simulation history VCD or FSDB file.
•Value Change Dumping
The CPU time needed by VCS to write a simulation history VCD or VPD file.
•VHDL
For VCS only, the CPU time needed to simulate the VHDL code design.
•PLI/DPI/DirectC
The CPU time needed by VCS to simulate the C/C++ in a PLI, DPI, or DirectC application.
•HSIM (Hybrid Simulation)
This is about the CPU time used by HSOPT (Hybrid Simulation Optimization). The HSIM bucket indicates the CPU time consumption of design constructs that are optimized by HSOPT. It has become prominent in GLS design/RTL. The HSIM cost is more with GLS design because most constructs are optimized by HSOPT. But it cannot be zero because there are some global HSIM activities.
•COVERAGE
The CPU time needed for functional coverage (testbench and assertion coverage). Code coverage is not part of this component.
•SystemC
The CPU time needed for SystemC simulation.
通过调节前面提到html左边区域选项,还可以看到更多的信息,如进一步查看仿真过程中rtl和tb各个模块层级花费的时间信息,这里就不多赘述了,其他的玩法大家感兴趣可以自己研究。
这种“重量级”的方式,虽然会拖慢仿真时间,但一个优势是收集的信息更加详细,可以更直观的看到各部分资源消耗百分比,更好的协助我们找到消耗时间的性能瓶颈,提供优化方向和缩小优化范围。
结语
我们今天围绕“时间”这个主题,首先讨论了验证仿真中的“3个时间”建立了基础认知,接着明确了平台提速到底要提哪个时间?最后以vcs工具举例了怎么收集和分析相关信息。
审核编辑:刘清
-
cpu
+关注
关注
68文章
11343浏览量
226052 -
时钟
+关注
关注
11文章
2000浏览量
135320 -
多核处理器
+关注
关注
0文章
110浏览量
20838
原文标题:验证仿真提速系列--认识“时间”与平台速度定量分析
文章出处:【微信号:处芯积律,微信公众号:处芯积律】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
热重分析仪在纤维材料的测试应用

RDMA设计35:基于 SV 的验证平台
高压放大器在激励低频可重构磁电天线中的应用

仿真分析仪表放大器共模抑制比
普发真空GSD 350在线质谱仪在关键领域的应用价值
机器视觉系统中工业相机的常用术语解读

倾佳电子宽禁带时代下的效率优化:SiC MOSFET桥式拓扑中同步整流技术的必然性与精确定量分析

电能质量分析软件可以提供哪些数据分析功能?
ATA-7010高压放大器:开启低频可重构磁电天线激励的新篇章

NVMe高速传输之摆脱XDMA设计23:UVM验证平台
基于共聚焦显微镜原位观测的石英玻璃划痕诱导微磨损的定量分析

3D 共聚焦显微镜 | 芯片制造光刻工艺的表征应用
NVMe高速传输之摆脱XDMA设计18:UVM验证平台
开芯院采用芯华章P2E硬件验证平台加速RISC-V验证




评论